使用深度学习在眼底照中检测糖网并分类(综述)
Deep learning for diabetic retinopathy detection and classification based on fundus images: A review

IF = 6.698/Q1
文章目录
先验知识/知识拓展
-
糖网是眼病里面研究较多的,也是研究相对清楚的疾病。现在虽然眼病有很多,但是很多机制还是待挖掘的。
-
糖网的早期微动脉瘤可以在视网膜上观察到,这是由于周细胞的变性和丢失引起的,导致毛细血管壁的扩张
-
早期对糖网的分级使用的标准是ETDRS,但是在临床上没有证明他的准确性和便捷实用性
-
一般糖网的病灶分割主要包括对渗出物,微动脉瘤和出血点的分割
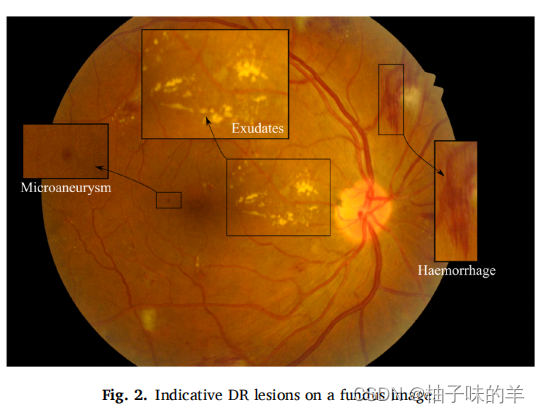
-
原来:文献中所谓的神经网络ANN就是简单的一层input, 一层隐层和一层output(由于只有一层隐层也叫前馈神经网络),而DNN是指至少有两层隐层的网络
-
借文章的内容和大家分享糖网的公用数据集(此处仅提供name)
-
分类
- Kaggle EyePACS
- Kaggle APTOS 2019
- Messidor & messidor 2
- IDRiD
- DDR
-
分割
- E-ophtha
- DiaRetDB1
- DRiDB
- ROC
-
文章结构
- 摘要
- introduction
- 糖网
- 深度学习
- 糖网数据集
- 预处理
- 糖网分类
- 糖网病灶分割和检测
- 深度学习模型在诊断中的应用
- discussion
- conclusion
文章结果
全面的汇总了深度学习在眼底照中检测糖网和分割糖网病灶中的每个步骤。文章涉及到的方面很多,包括当下研究中使用频次高的数据集,预处理过程,如何提高model性能,以及深度学习模型在疾病分类中的使用以及病灶定位中的应用。此外还总结了现在诊断中使用到的模型,还做了前景分析用于未来的研究
1. introduction
- 最早的一篇使用深度学习进行糖网分类和检测病灶的文章在2016年就发布了
方法
1. 眼底图像一般的分析pipeline
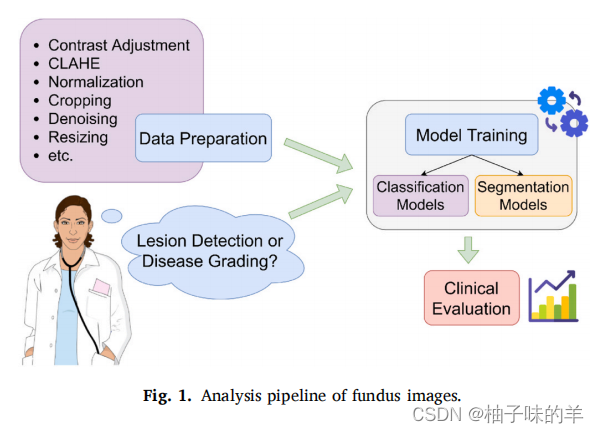
2.传统的卷积神经网络(CNN)和UNet的比较
- UNet的参数量相对较少,运行速率会比传统CNN快
- UNet考虑到上下文路径信息和对称路径信息
- UNet相较于传统CNN需要跟少的数据量——正和医学数据的意(大量数据对外不公开)
3. 注意力机制
注意力机制从第一次提出后,不断被研究者改进,以此来提高模型的性能和鲁棒性
4. 生成网络(GAN)
生成网络一般包括两个部分,生成器和辨别其,生成器是根据原始输入图像的分布生成新的候选数据,辨别器根据原始图像的TRUE分布判断生成器生成的数据是否为TRUE。生成网络的适用场景包括:超分辨率重建和图像画风转变(根据一张图片生成另一种不同风格的图片)等
5. 迁移学习
由于医学图像涉及患者隐私和伦理问题,虽然虽然应该存在很多医学图像数据,但是公开使用的数据量非常少,不可能做到ImageNet那种规格,所以在医学领域,想要说模型的稳健性或者说准确性一般是很难达到的,因为数据量的不足尝尝会出现过拟合现象。
想要从头训练一个模型,如果模型的参数量在单位级为万时还好,但是当模型参数过多时,从头开式训练需要很大的时间成本,此外还要不断地调整参数,所以一般大家都使用迁移学习的思想,使用大佬训练好的权重作为预训练权重对自己的模型进行微调,这样会相对更加高效。
虽然大佬和我们的研究目的,数据特征相差很大,但是不影响我们使用他训练好的权重。就比如大佬是做车,人,猫,狗等多种事物的分类,我们的目的是对各种细胞进行分类。但是本质都是先学习不用类别事物的关键特征,然后根据这些特征进行分类。我们使用他的预训练权重是使用他提取特征的方式,并不是说就是他的特征,因为数据量本身是不同的,只是使用了他学习的过程,这样讲,应该明白吧。就是用大佬的学习方法来学习我们的特征,嗯,就是这样。
6.集成学习
原来集成学习指的是发掘多个模型的优点,使得集成后的模型的效能大于他们单独使用的效能。(就是1+1+1+…+1 > 1,不过一般应该不会有这么多1)。还有几种常见的集成学习使用的集成策略
- 多数投票
- 平均投票:通常用在回归问题上
- bagging:在训练的过程中每个模型使用的是整个训练数据的一部分,他们的输出最终使用多数投票、平均投票或者其他策略整合
- stacking:一个模型的输出作为另一个模型的输入进行
- boosting:合并基于以前训练过的模型和性能不加的模型的性能错误进行多次训练。然后根据单个模型的预测性能计算出预测的加权平均值
7. 其他
- 多任务
- 多模态:多模态学习主要见于生物学、病理学和放射学领域,其中将多个成像和非成像来源(如MRI、CT、分子和临床数据)相结合进行数据分析。每个数据模态首先由其专用模型进行处理,然后利用融合的特征对公共模型进行训练。
- 主动学习:是在数据的一个小标记子集上训练模型的过程,对数据的其余未标记子集进行预测,根据给定的策略对它们进行优先级排序,并根据优先级评分查询用户的一部分未标记数据的地面真实标签。然后在数据的新标记子集上对模型进行训练。主动学习主要适用于标记数据量较多的情况,并且应该优先考虑标记数据。

8.图像预处理
- 对比度增强
- 去除噪音和标准化
- 颜色信息:不同通道处理
- 裁剪和resize:两种策略(一种是裁剪中间的圆形,另一种是裁剪最大的外接正方形)
9.现在使用在糖网上的方法
- 通常使用的DL方法
- 迁移学习
- 集成学习模型
10.模型提升的方法
- 有人提出使用多任务对渗出物和微动脉瘤分割,还提出使用针对“膜结构”的方法——mask R-CNN
- 有人使用一种轻量级的encoder-decoder的分割网络,参数量是一般网络的十分之一
- 在病灶分割的过程中使用多尺度
- 深度学习和机器学习相结合,深度学习提取特征,机器学习分类器
- 整张图会丧失很多图像的细节信息,使用patch
- 在分割模型中使用软label(概率值),得到每个pixel的概率后,为了避免冗余的边界及分割后的符号周围杂乱的像素,有人提出使用心态学上的知识:开,闭和腐蚀的方法
- 在分割的时候增加注意力机制
- 基于GAN网络:可以产生类似的数据,增大数据集,解决数据集不平衡的问题
总结
1. 文章优点
- 可能是以review的角度在写,文章写的可以说非常详尽了。举个例子:卷积层一般作为特征提取的部分,而剩下的部分作为分类部分
- 毫不吝啬的说,看了很多综述,但是这篇真的非常值得大家下载阅读,非常有营养,我觉得我看一天都不过分。我会上传原文到资源,需要自取!
2. 文章不足
- 目前我的菜鸡水平,没有觉得不好!
可借鉴点/学习点?
- 文章中说到,针对与糖网的分类使用较小的卷积层,会有更好的效果,因为无论是出血点、渗出物还是微动脉瘤都很小
- 在集成学习中,一般基础的model表现的性能越强,在后面的集成学习之后的性能也越强
- 一方面是写作方面值得借鉴和学习的点,如果写综述,这篇文章的写作手法以及涉及到的点非常值得学习,很充实,从过去,现在和未来出发,数据,方法都涉及到了。面面俱到的一篇review
- 另一方面是model的资源型阅读,看看别人都是怎么使用和结合的,不能总把自己拘束在一个狭小的领域,应该多看看别人怎么做,万一自己用得到呢?