基于Ubuntu的Hive搭配
目录
一、实验环境
1、实验内容
本实验从零开始,一步步搭建完成 Hive,并在 Hive 上进行数据统计分析。
2、实验环境说明
- Ubuntu 14.04
- JDK 1.8.0_171
- Hadoop 2.7.6
- Hive 1.2.2
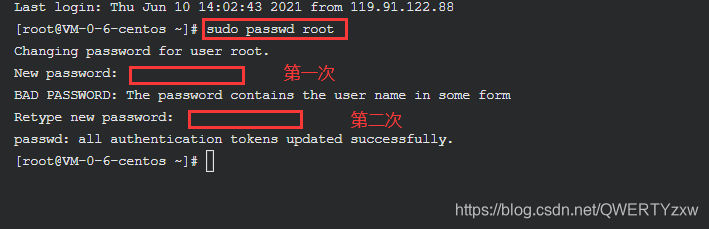
3、激活root用户
为了方便实验,云实验室云主机需要切换到 root 用户
sudo passwd root
将 root 用户的密码设置为 root@123 ,输入两次,完成密码的设置
切换至 root 用户
su root
输入之前设置的密码 root@123
二、JDK部署
1、jdk配置
①下载JDK
wget --no-check-certificate -c --header "Cookie: oraclelicense=accept-securebackup-cookie" https://download.oracle.com/otn/java/jdk/8u291-b10/d7fc238d0cbf4b0dac67be84580cfb4b/jdk-8u291-linux-aarch64.tar.gz

②解压缩 JDK 安装包
tar xzvf jdk-8u291-linux-aarch64.tar.gz -C /usr/local

进入Oracle官网下载JDK
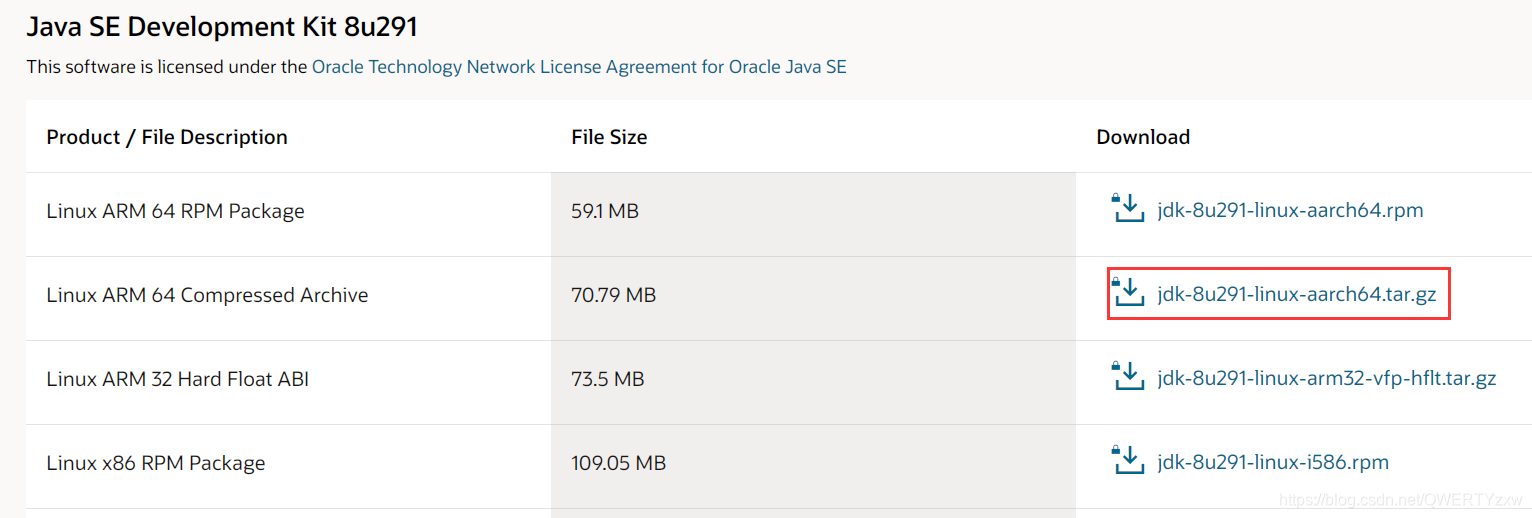
接收相关协议,开始下载

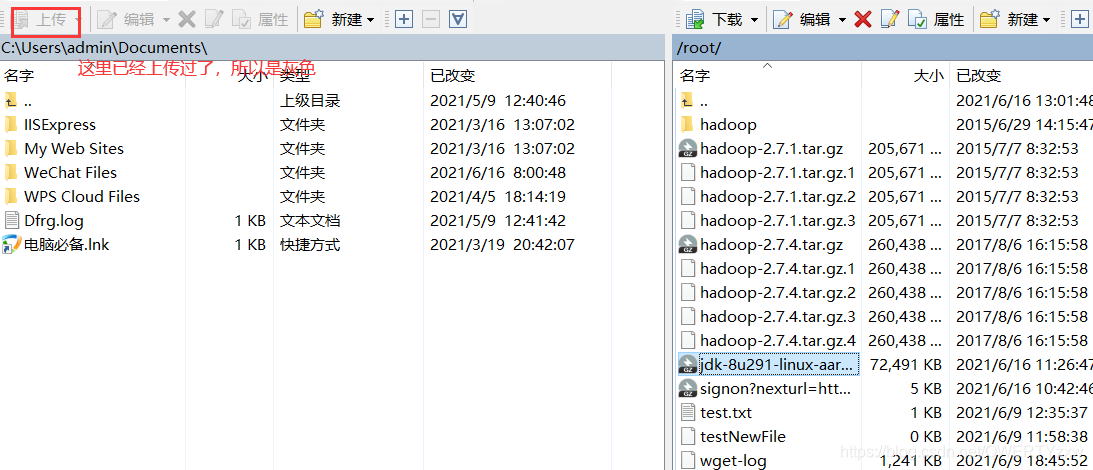
下载安装winscp,百度即可下载安装。
使用实验创建的用户root,密码root@123进行站点连接
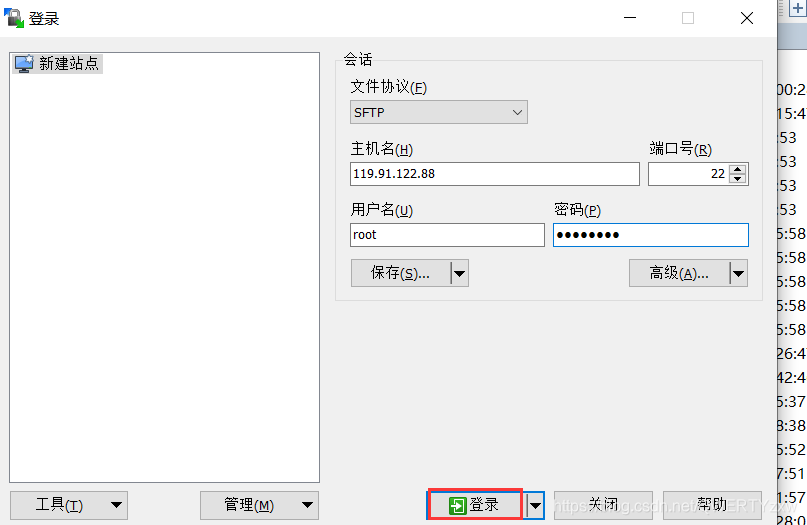
点击登录,建立如示会话
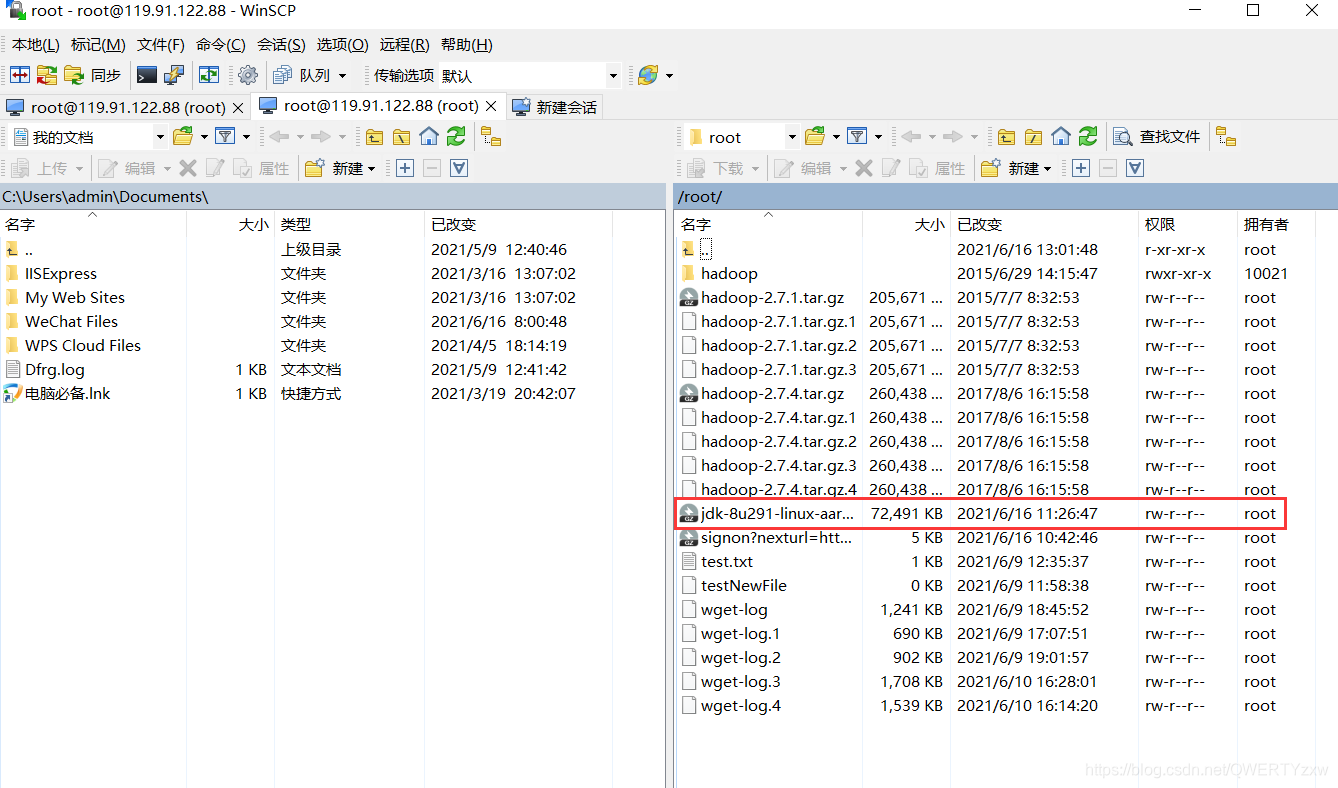
选中方框中的文件,点击上传
终端使用解压命令
tar xzvf jdk-8u291-linux-aarch64.tar.gz -C /usr/local

可以看到成功解压了。
2、修改JDK目录名
为了方便之后的环境变量的配置,修改一下 JDK 的目录名进入 /usr/local 目录
cd /usr/local

使用命令 mv 修改目录名
mv jdk1.8.0_291 jdk

3、配置环境变量
使用 vim 命令打开 /etc/profile 文件
vim /etc/profile
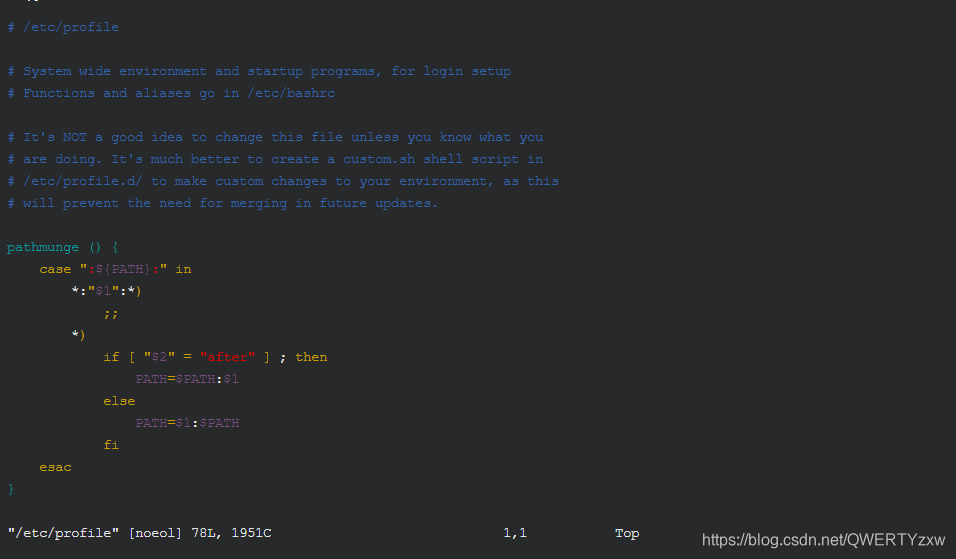
进入编辑模式,在文件最后输入以下信息
export JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin:
export CLASS_PATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
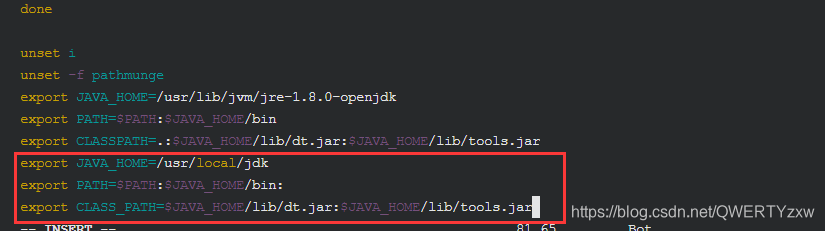
保存退出。(i进入编辑模式,Esc退出编辑模式,shift+:wq退出)
使用 source 命令使环境变量生效
source /etc/profile

三、Hadoop部署
1、下载Hadoop
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.6/

使用 tar 解包(无法解压,使用上述方法上传到云服务器)
tar xzvf hadoop-2.7.6.tar.gz -C /usr/local
2、修改Hadoop目录名
进入 /usr/local 目录
cd /usr/local

使用命令 mv 修改目录名
mv hadoop-2.7.6 hadoop

3、配置环境变量
使用 vim 命令打开 /etc/profile 文件
vim /etc/profile
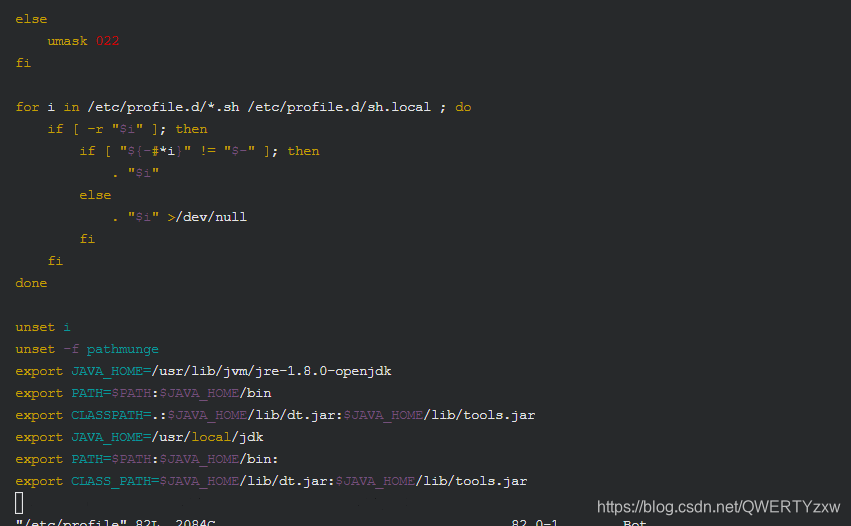
进入编辑模式,在JAVA_HOME后面追加如下信息
export HADOOP_HOME=/usr/local/hadoop
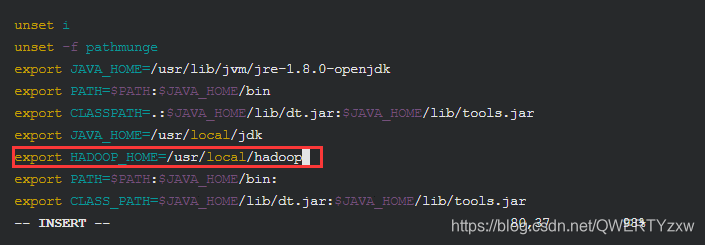
在PATH后面增加如下信息
export PATH=$PATH:$JAVA_HOME/bin:
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:

保存退出。
使用 source 命令
source /etc/profile

4、配置Hadoop环境变量
使用 vim 命令打开 /usr/local/hadoop/etc/hadoop/hadoop-env.sh 文件
vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
进入编辑模式,将里面的export JAVA_HOME=${JAVA_HOME}修改成如下信息
export JAVA_HOME=/usr/local/jdk
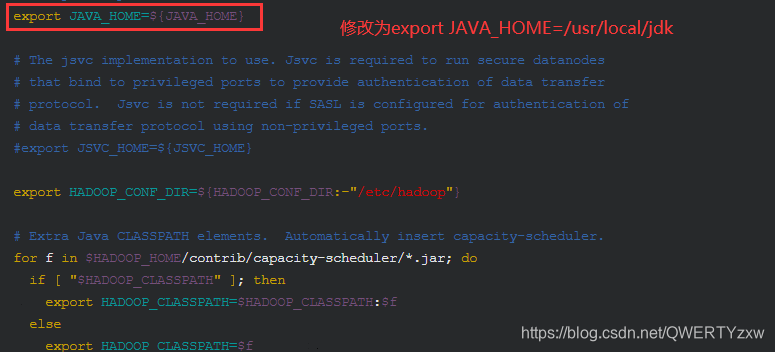
保存退出。
四、配置伪分布式Hadoop系统
1、配置ssh免密登录
在 hadooptest 主机上生成 SSH 的 key
ssh-keygen -t rsa
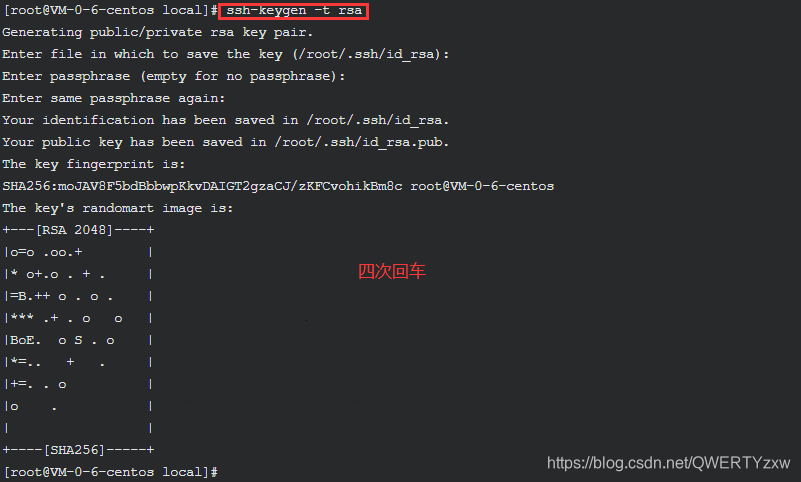
配置本机的免密登录
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

2、修改相应文件信息
①修改 core-site.xml 文件
vim /usr/local/hadoop/etc/hadoop/core-site.xml
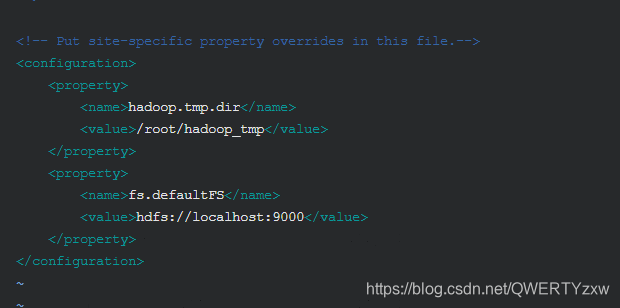
进入编辑模式,在 与 标签之间输入如下信息
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop_tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
②修改master文件
进入 /usr/local/hadoop/etc/hadoop 目录
cd /usr/local/hadoop/etc/hadoop

新建master文件
vim master
进入编辑模式,输入如下内容
localhost

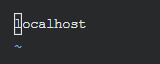
③修改 slaves 文件
打开slaves文件
vim slaves
进入编辑模式,将默认主机名修改为如下内容
localhost
④格式化hdfs
hdfs namenode -format

3、启动服务
start-all.sh

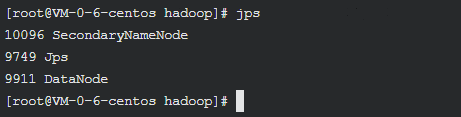
检查服务是否开启
jps
五、部署Hive
1、下载hive与解压
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-1.2.2/apache-hive-1.2.2-bin.tar.gz

使用 tar 解包
tar xzvf apache-hive-1.2.2-bin.tar.gz -C /usr/local
2、修改hive目录名
进入 /usr/local 目录
cd /usr/local

使用命令 mv 修改目录名
mv apache-hive-1.2.2-bin hive

3、hive使用
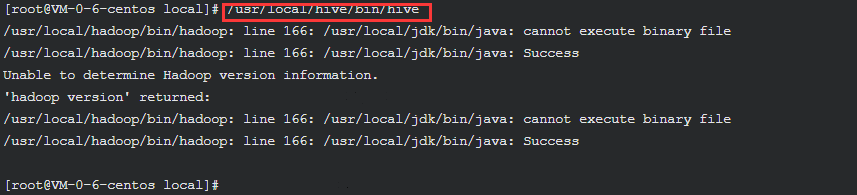
启动hive
/usr/local/hive/bin/hive
显示数据库
show databases;
use default;
创建表
create table test(id int,name string,address string)
row format delimited
fields terminated by ',';
此时,Hive 在 hdfs 中建立了一个目录 /user/hive/warehouse/test ,我们需要把数据放到这个目录下,就可以进行数据分析了。
退出 Hive
quit

4、测试实例
创建测试文件
vim userinfo.data
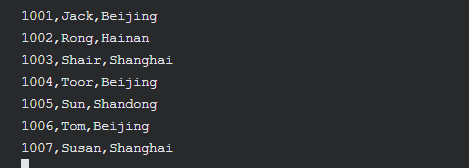
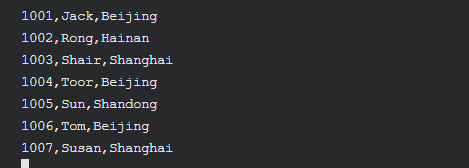
进入编辑模式,输入如下内容
1001,Jack,Beijing
1002,Rong,Hainan
1003,Shair,Shanghai
1004,Toor,Beijing
1005,Sun,Shandong
1006,Tom,Beijing
1007,Susan,Shanghai
上传文件至 hdfs
hadoop fs -put userinfo.data /user/hive/warehouse/test

5、hive进行数据分析
进入hive
/usr/local/hive/bin/hive

在 hive> 提示符下,输入如下命令
use default;
select address,count(*) as count from test group by address;
可以看到,Hive 将输入的 SQL 语句转变成 map-reduce 程序,进行数据的统计分析,并输出统计结果。