前言
过去几年中,深度学习已成为人工智能许多成功的基础,包括计算机视觉中的各种应用、强化学习。随着许多最新技术的帮助,包括残差连接和批量归一化,可以在强大的GPU或TPU集群上轻松训练数千层的非常深的模型。例如,使用数百万图像的流行图像识别基准测试可以在不到十分钟的时间内训练出ResNet模型;训练强大的BERT语言理解模型不需要超过一个半小时。大规模的深度模型取得了压倒性的成功,但是巨大的计算复杂度和大量的存储要求使得在实时应用中部署它们成为了一大挑战,尤其是在资源有限的设备上,比如视频监控和自动驾驶汽车。
为了开发高效的深度模型,近期的工作通常关注于以下两方面:1)深度模型的高效构建块,包括MobileNets和ShuffleNets中的深度可分离卷积;以及模型压缩和加速技术(Cheng等人,2018)。
详细可以看这篇论文:Cheng, Y., Wang, D., Zhou, P. & Zhang, T. (2018).Model compression and acceleration for deep neural networks: The principles, progress, and challenges.IEEE Signal Proc Mag 35(1): 126–136.
其中模型的压缩技术详细可以看这篇文章模型压缩技术综述
本文的主要分享关于知识蒸馏相关的技术原理。
在深度学习中的应用。由于大型深度神经网络在处理大规模数据方面具有优异的性能,因此在真实场景中被广泛使用。但是,由于移动设备和嵌入式系统的计算能力和内存受限,将深度模型部署到这些设备上仍然是一个巨大的挑战。
为了解决这个问题,学者们提出了模型压缩(model compression)的方法,将大型模型的信息转移到小型模型中进行训练,从而在不显著降低准确率的情况下获得更小的模型。而知识蒸馏则是一种特定的模型压缩方法,通过将大型教师模型的知识转移到小型学生模型中来训练后者,以获得竞争力甚至更好的性能。在知识蒸馏中,通常使用一个大型教师模型来指导一个小型学生模型的训练,学生模型通过模仿教师模型的行为来学习。而如何将教师模型的知识转移到学生模型中,则是知识蒸馏的关键问题。一般而言,知识蒸馏系统由三个关键组成部分构成:知识、蒸馏算法和教师-学生架构。在知识蒸馏中,教师-学生架构是核心,它包括一个教师模型和一个学生模型,如下图所示
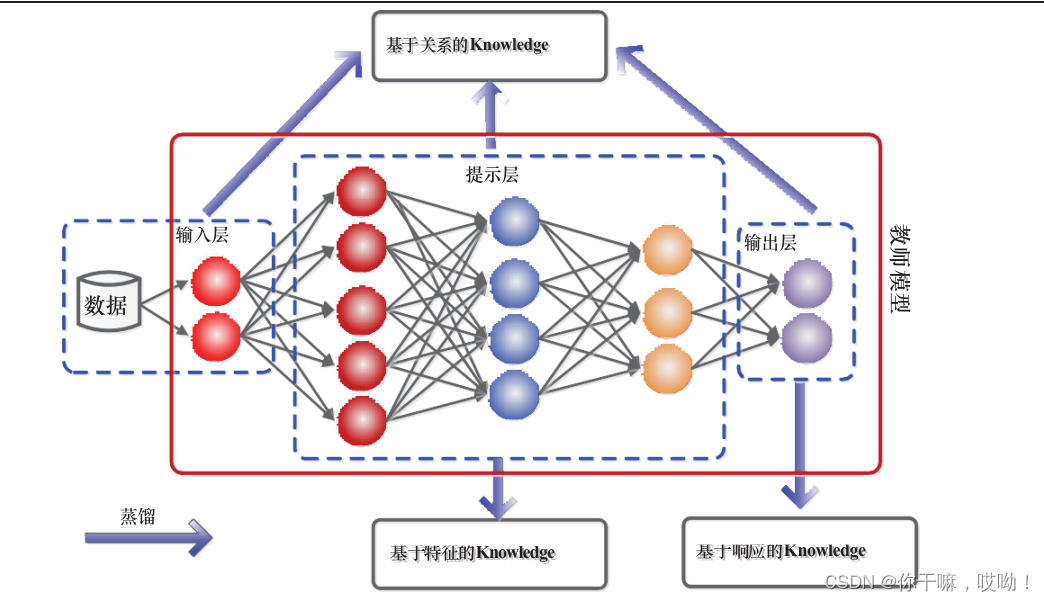
知识蒸馏系统由三个关键组件组成:知识、蒸馏算法和师生体系结构
我们的人工智能模型,已经逐渐往人的思维,社会形态演变了,所以很多知识算法都是可以从社会中找到共性的,比如知识蒸馏,就好比老师(老师懂得很多学生不懂的知识,这个就是大模型)传授给学生知识(老师只需要把这本学科的知识给学生就行了)
从老师传授学生知识这个过程,就可以分析出,其中包含的几个要素:什么知识,传授的方式,学校的师生配置架构。
文章内容参考论文:Knowledge Distillation: A Survey,感兴趣的可以跳转阅读。
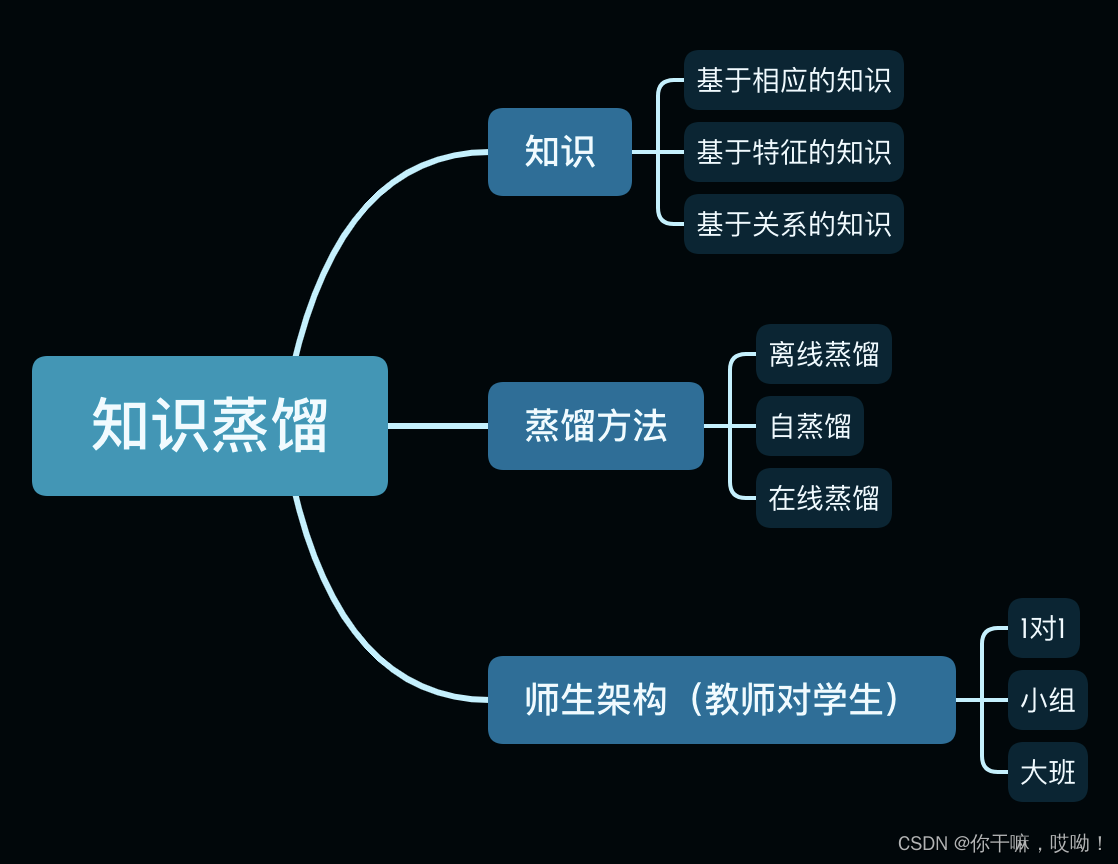
知识
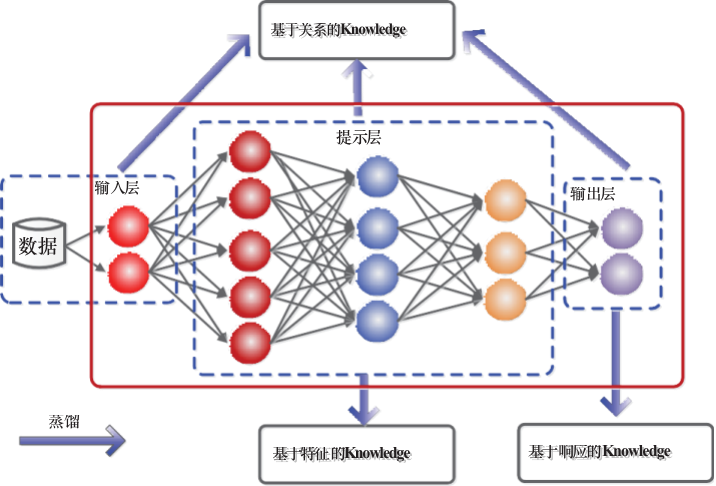
知识蒸馏中,知识类型、蒸馏策略和教师-学生架构在学生学习中起着关键作用。本节中,我们关注于不同类型的知识用于知识蒸馏。传统的知识蒸馏使用大型深度模型的 logits 作为教师知识(logits是指在神经网络中最后一层计算结果的输出。在分类任务中,logits通常是一个向量,每个元素对应一个类别的得分)
也可以使用中间层的激活、神经元或特征来指导学生模型的学习。此外,不同激活、神经元或样本对之间的关系也包含了由教师模型学习到的丰富信息。教师模型的参数(或层之间的连接)也包含另一种知识。我们将不同形式的知识讨论为响应式知识、特征式知识和关系式知识。
基于响应的知识

算法思想
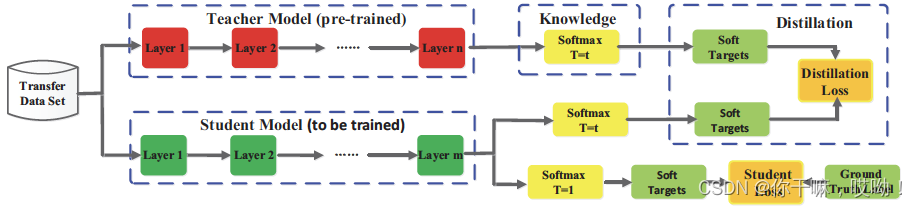
它的主要思想是直接模仿教师模型的最终预测结果,通过优化损失函数让学生模型的输出与教师模型相匹配,以实现模型压缩和提高性能的目的。
在基于神经响应的知识蒸馏中,损失函数的计算以教师模型最后一个全连接层的输出结果为基础,利用logits(逻辑回归函数的输出结果)的差异来计算蒸馏损失。
给定一个由深度模型的最后一个全连接层输出的logits向量z,响应性知识蒸馏的损失可以表示为:
L R e s D ( z t , z s ) = L R ( z t , z s ) L_{ResD}(z_t, z_s) = L_R(z_t, z_s) LResD(zt,zs)=LR(zt,zs)
其中, L R ( . ) L_R(.) LR(.)表示logits的差异损失, z t z_t zt和 z s z_s zs分别是教师和学生的logits。
在图像分类中,最流行的响应性知识蒸馏是软目标(soft targets:是指由教师模型(teacher model)预测的每个类别的概率分布,这些概率分布被用作辅助训练学生模型(student model)),可以使用softmax函数来估计。
对于soft targets,可以通过softmax函数来计算,公式如下:
p ( z i , T ) = e x p ( z i / T ) ∑ j e x p ( z j / T ) p(z_i, T) = \frac{exp(z_i/T)}{\sum_j exp(z_j/T)} p(zi,T)=∑jexp(zj/T)exp(zi/T)
其中, z i z_i zi是第 i i i个类别的logit, T T T是温度系数,用于控制每个soft target的重要性。通常,KL散度被用于 L R ( p ( z t , T ) , p ( z s , T ) ) L_R(p(z_t, T), p(z_s, T)) LR(p(zt,T),p(zs,T))的计算。公式如下所示:
L K D = α T 2 ∑ i = 1 N p i ∗ log p i q i L_{KD}=\alpha T^{2}\sum_{i=1}^{N}p_{i}*\log\frac{p_{i}}{q_{i}} LKD=αT2i=1∑Npi∗logqipi
其中, p i p_{i} pi表示学生网络的输出概率分布, q i q_{i} qi表示教师网络的输出概率分布, T T T是温度参数, α \alpha α是用于平衡知识蒸馏和交叉熵损失的权重系数。
具体损失函数计算方法是:
- 首先输入一个样本,经过教师网络和学生网络分别计算出对应的输出概率分布 p p p 和 q q q。
- 然后将两个概率分布分别代入上述公式中,得到对应的损失值。
- 最后将所有样本的损失值求和并除以样本数量,得到平均损失值,作为优化器的反向传播梯度。
- 通过反复迭代优化损失函数,可以使得学生网络的输出更加接近教师网络的输出,从而实现知识蒸馏的效果。
用教师模型的输出的值,做为学生模型的真实值,用这个真实值结合学生预测的值,做损失函数。
为了更好的理解这个软目标概率分布,下面提供了一个python示例,通过示列来展示温度参数是如何影响软目标(预测目标的概率分布)的:
import numpy as np
def softmax(logits, temperature=1.0):
"""
计算softmax函数
:param logits: 输入的logits向量
:param temperature: softmax函数温度参数
:return: 计算后的softmax向量
"""
exp_logits = np.exp(logits / temperature)
return exp_logits / np.sum(exp_logits)
# 定义一个简单的分类任务,假设共有3个类别
num_classes = 3
# 假设teacher模型的logits为[2.0, 1.0, 0.5]
teacher_logits = np.array([2.0, 1.0, 0.5])
# 用softmax函数计算teacher模型的软目标
# 假设温度参数T=1.0
soft_targets_T1 = softmax(teacher_logits, temperature=1.0)
print("teacher模型的软目标分布(温度T=1.0):", soft_targets_T1)
# 假设温度参数T=2.0
soft_targets_T2 = softmax(teacher_logits, temperature=2.0)
print("teacher模型的软目标分布(温度T=2.0):", soft_targets_T2)
结果
teacher模型的软目标分布(温度T=0.5): [0.84379473 0.1141952 0.04201007]
teacher模型的软目标分布(温度T=1.0): [0.62853172 0.2312239 0.14024438]
teacher模型的软目标分布(温度T=2.0): [0.48102426 0.29175596 0.22721977]
通过修改T,来改变预测结果的分布,这T,在diffusion生成图片中也是一个道理,通过改变T来使每次生成的图片不一样(分布不一样)。
基于特征的知识
深度神经网络擅长学习多层次的特征表示,这被称为表示学习。
因此,最后一层的输出以及中间层的输出,即特征映射,都可以用作知识来监督学生模型的训练。具体来说,来自中间层的基于特征的知识是响应式知识的一个很好的扩展,特别是对于训练更薄、更深的网络。
算法思想
主要思想同基于响应知识类似,但这里匹配的不是输出层而是教师和学生的特征激活层。受此启发,出现了其他各种方法,比如以间接匹配特征层(例如通过注意力图、因子等方式)。
最近,还有一些研究提出了更先进的方法来进行知识转移,例如通过隐藏神经元的激活边界进行知识转移。与响应式知识一起使用中间层的参数共享也被用作教师知识。为了匹配教师和学生之间的语义,还提出了一种跨层知识蒸馏的方法,通过注意力分配自适应地为每个学生层分配适当的教师层。
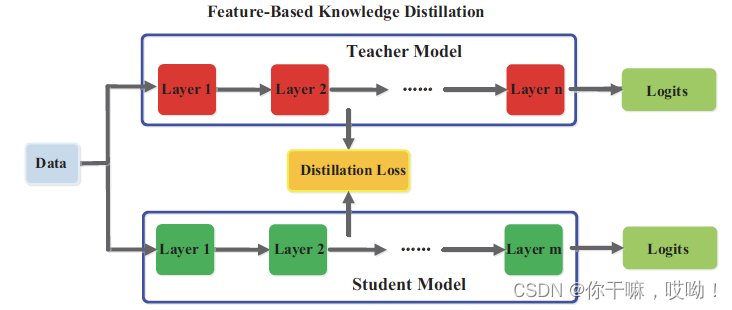
在特征知识蒸馏中,通常将中间层的特征图作为知识来辅导学生模型的训练。公式如下:
L F e a D ( f t ( x ) , f s ( x ) ) = L F ( Φ t ( f t ( x ) , Φ s ( f s ( x ) ) ) ) LFea_D(f_t(x),f_s(x))=\mathcal{L}_F(\Phi_t(f_t(x),\Phi_s(f_s(x)))) LFeaD(ft(x),fs(x))=LF(Φt(ft(x),Φs(fs(x))))
f t ( x ) f_t(x) ft(x) 和 f s ( x ) f_s(x) fs(x) 分别为教师和学生模型中间层的特征图,LFea表示相似度函数,用于匹配教师和学生模型的特征图。不同的相似度函数可以用来计算特征图的距离,如L2(欧式距离)、L1(曼哈顿距离)、LCE(交叉熵损失)和LMMD(最大平均差异度损失)等。
在特征知识蒸馏过程中,需要解决从教师模型选择提示层和从学生模型选择指导层的问题,并且由于提示层和指导层的大小差异较大,如何正确匹配教师和学生模型的特征表示也需要探索。
举个例子来说,假设我们有一个教师模型,它可以将一张人脸图像分为眼睛、鼻子、嘴巴等部位的特征图,而我们希望训练一个小型的学生模型来完成相同的任务。我们可以使用教师模型的中间层特征图作为知识,帮助学生模型学习到更多的有用信息。在特征知识蒸馏过程中,我们需要计算教师和学生模型中间层特征图之间的相似度,并将其作为损失函数的一部分来优化学生模型。同时,由于教师模型和学生模型的特征图可能不具有相同的形状,因此我们需要进行一些转换操作,如缩放、填充等。
基于关系的知识
知识蒸馏响应和特征知识蒸馏使用了教师模型中特定层的输出。
而关系知识蒸馏则进一步探索了不同层或数据样本之间的关系。
例如,通过计算两个层之间的 Gram 矩阵,可以总结出对应特征映射之间的关系,用这些相关性作为蒸馏的知识。同时,学生模型也会模仿教师模型中的多个层之间的互动流,以便更好地蒸馏知识。
在这些方法中,不同类型的蒸馏损失函数被用于测量学生模型与教师模型中不同特征映射之间的差异,例如L2距离、L1距离、交叉熵损失和最大均值差异损失。
关系知识的知识蒸馏损失函数可以表示为:
L R e l D ( f t , f s ) = L R 1 t ( f t ^ , f t ~ ) , L R 1 s ( f s ^ , f s ~ ) \mathcal{L}_{RelD}(f_t,f_s)=\mathcal{L}_{R1}^{t}(\hat{f_t}, \tilde{f_t}), \mathcal{L}_{R1}^{s}(\hat{f_s}, \tilde{f_s}) LRelD(ft,fs)=LR1t(ft^,ft~),LR1s(fs^,fs~)
其中, f t f_t ft和 f s f_s fs分别表示教师模型和学生模型的特征图, f t ^ \hat{f_t} ft^和 f t ~ \tilde{f_t} ft~表示从教师模型中选择的特征图对, f s ^ \hat{f_s} fs^和 f s ~ \tilde{f_s} fs~表示从学生模型中选择的特征图对。 L R 1 L_{R1} LR1表示教师和学生特征图之间的相关性函数。
基于关系的知识包括数据样本之间的关系和特征之间的关系。实例关系图是一种基于实例关系的知识转移方法。它通过学习数据样本之间的关系来传递知识,其中包括数据样本的特征、实例之间的关系以及特征空间的变换。
实例关系图的计算原理:
首先将数据样本的特征提取出来,
然后计算数据样本之间的相似度或距离,然后将数据样本之间的关系表示为一个图形,其中每个节点代表一个数据样本,节点之间的连线表示它们之间的关系。
实例关系图知识转移的损失函数公式如下:
L I R G ( s , t ) = L C E ( s ( x ) , t ( x ) ) + α L I R ( s , t ) + β L T ( s , t ) \mathcal{L}_{IRG}(s,t)=\mathcal{L}_{CE}(s(x),t(x))+α\mathcal{L}_{IR}(s,t)+βL_T(s,t) LIRG(s,t)=LCE(s(x),t(x))+αLIR(s,t)+βLT(s,t)
其中 L C E \mathcal{L}_{CE} LCE 是交叉熵损失函数,用于衡量模型预测与真实标签之间的差距; L I R \mathcal{L}_{IR} LIR 是实例关系图(Instance Relationship Graph)损失函数,用于保持模型在学习特征表示时数据实例之间的相似性关系; L T \mathcal{L}_T LT 是转移损失函数,用于保持模型在跨层次学习特征表示时的一致性。其中,实例关系图损失函数 L I R \mathcal{L}_{IR} LIR 的计算原理已在之前的问题中进行了阐述。转移损失函数 L T \mathcal{L}_T LT 可以使用多种方法实现,如使用特征层之间的 L1 或 L2 范数,或使用两个特征层之间的 Gram 矩阵作为距离衡量标准等。
蒸馏方式
在本节中,我们将讨论教师和学生模型的蒸馏方案(即训练方案)。
根据教师模型是否与学生模型同时更新,知识蒸馏的学习方案可以直接分为三类:离线蒸馏、在线蒸馏和自蒸馏。,如下图所示,红色表示为不更新,黄色为要更新。
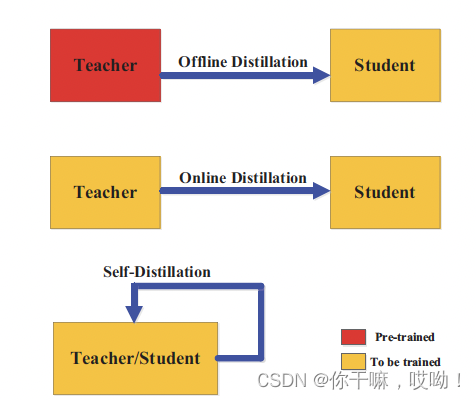
离线蒸馏
离线蒸馏是先在一组训练样本上训练一个大型教师模型,然后将知识以logits或中间特征的形式传递给学生模型,以指导学生模型的训练。通常离线蒸馏分为两个阶段,即先训练教师模型,再对学生模型进行蒸馏。离线蒸馏的优点是简单易行,易于实现。
但是,教师模型的结构和与学生模型的关系往往被忽略。离线蒸馏的方法主要集中在改进不同部分的知识传递,包括设计知识和匹配特征或分布匹配的损失函数。这些方法虽然容易实现,但是需要大量的计算和时间,因为教师模型往往是一个复杂的高容量模型。
离线蒸馏方法通常包括以下三个步骤:
- 使用教师模型在大型数据集上进行训练,生成一个已经预测出正确答案的软标签。软标签是一种概率分布,它表明了每个类别的概率。
- 使用软标签和原始的训练数据对学生模型进行训练。在这个过程中,学生模型会尽力去匹配教师模型的输出,以便能够更好地学习到其知识。
- 使用原始的训练数据对学生模型进行微调,以便使其更好地适应原始数据集的特征。
离线蒸馏的核心思想是将教师模型的知识转移到学生模型中,以提高学生模型的性能和泛化能力。通过使用软标签和教师模型的预测结果来训练学生模型,可以让学生模型更好地学习到教师模型的知识。此外,离线蒸馏可以通过调整软标签的温度参数来控制知识的传递程度。温度参数越高,软标签中的概率分布越平滑,知识的传递程度也就越平滑。
在线蒸馏
在线蒸馏是指同时训练教师和学生模型,在学生模型训练的同时,教师模型也在不断更新。
在线蒸馏(Online Distillation)是知识蒸馏的一种形式,与传统的离线蒸馏(Offline Distillation)相对应。相比于离线蒸馏,在线蒸馏的特点是在训练过程中,同时更新教师模型和学生模型,使得学生模型可以快速地学习教师模型的知识。在线蒸馏可以解决离线蒸馏中的一些问题,特别是当教师模型的规模较大,性能较好时,离线蒸馏的效果可能会受到限制。在线蒸馏方法的主要思想是在训练中利用教师模型的预测结果和真实标签来更新学生模型的权重。
自蒸馏
自蒸馏(self-distillation)是一种无需使用外部教师模型的知识蒸馏技术,它可以利用同一个大型教师模型的不同层来指导小型学生模型的训练。与离线蒸馏和在线蒸馏不同,自蒸馏只需要一个模型并且不需要训练多个模型。自蒸馏技术可以提高模型的泛化能力、减少过拟合、加速模型的训练和推理等。
自蒸馏的原理是利用教师模型的高层特征来指导学生模型的训练。通常情况下,教师模型拥有更多的层数和更大的模型容量,可以提供更丰富的信息,而较浅的学生模型通常会受到过拟合和欠拟合的影响,无法学到足够的信息。因此,自蒸馏通过将教师模型的特征作为目标来训练学生模型,从而使得学生模型可以学到教师模型的知识。
教师学生架构
知识蒸馏教师学生架构是一种教学方法,其中老师将自己的知识和经验传授给学生,而学生通过吸收老师的知识和经验来提高自己的能力和技能。这种教学方法有多种不同的架构,下面是其中几种常见的:
- 一对一教学架构:这种架构中,老师和学生之间进行一对一的交流和教学。这种方法可以确保老师对每个学生的学习情况有充分的了解,同时也可以让学生在一个更加个性化的环境中学习。然而,这种架构需要较多的时间和精力投入。
- 小组教学架构:这种架构中,老师将学生分成小组,并让他们一起学习和探讨。这种方法可以激发学生的团队合作和沟通能力,同时也可以让学生从小组成员中互相学习和借鉴。但是,这种架构需要老师在管理和指导学生的过程中花费更多的时间和精力。
- 大班教学架构:这种架构中,老师在一个大班中教授知识和技能。这种方法可以让学生在更加开放和多元化的环境中学习,同时也可以节约教学资源和老师的时间。但是,在这种架构中,老师可能无法满足每个学生的个性化需求,同时学生之间的竞争可能会影响学习效果。
这架构不就是纯粹的学校的班级架构吗,难道说人工智能算法发现是按照人的学习发展,社会发展轨迹分析的?
无论是哪种教学架构,知识蒸馏的特点是老师将自己的知识和经验传授给学生,帮助他们提高能力和技能。这种教学方法的优点是可以提高学生的学习效率和学习成果,同时也可以让老师将自己的知识和经验传承下去。然而,这种教学方法也存在一些挑战,比如需要老师有足够的经验和知识来指导学生,同时需要学生拥有一定的自学能力和动力来吸收老师的知识和经验。
如果是模仿人类的学习过程,感觉是存在有老师对学生,多对一的,类似于富二代高价辅导班嘛,这种学生更优秀吧,那如果放到模型里,训练出这个模型,肯定是比目前的模型强的