最近我在学习正则表达式, (.*?) 是个非常实用的匹配符,可以匹配两个词之间的字符串,比如:
re.search('Intro(.*?)end', text)[1]可以截取到 Intro 和 end 之间的文字。随着深入使用正则表达式,发现了它的弊端:只能在一行文字内搜索,遇到断行、换行、多个段落的文字时,这一招就无效了,举个例子:我去年写的一篇博文有提到从网页源代码中提取文字:
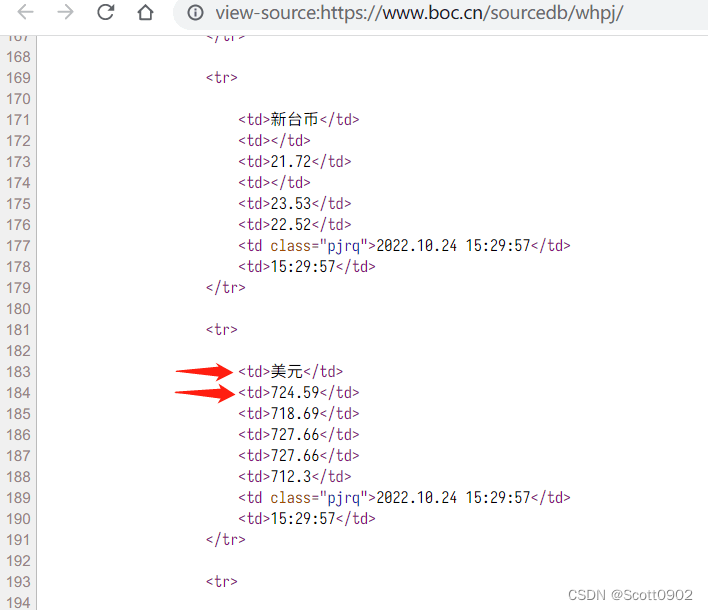
要获取“<td>美元</td>”和“<td class="pjrq">”之间的数字,我在原文里使用自编的查找字符串函数,现在尝试正则表达式,首先想当然地使用下面的语句:
re.search('<td>美元</td>(.*?)<td class="pjrq">', text)[1]结果报错:TypeError: 'NoneType' object is not subscriptable。匹配不了。
“<td>美元</td>”和“<td class="pjrq">”之间隔开了多行,只要字符串含有换行符“\n”就无法匹配。如何获取多个段落的文字?
后来研究了Python的正则表达式 re 库的用法,原来还有一个 re.DOTALL 的参数,只要加上它就能匹配包含换行符的文字,因此上述语句要改为:
s1 = re.search('<td>美元</td>(.*?)<td class="pjrq">', text, re.DOTALL)[1]
# 先获取“美元”和“pjrq”之间的文字,再从中获取数字
s2 = re.findall('<td>(.*?)</td>', s1)
print (s2)
'''
输出结果:
['724.59', '718.69', '727.66', '727.66', '712.3']
'''One more thing...
我在琢磨上面的代码如何转换成C++,令人苦恼的是C++的正则表达式函数没有dotall的参数。
刚刚看了别人提到,还有下面的用法,C++没有 re.DOTALL 参数也能这样匹配得到:
"keyword1([^]*?)keyword2"
regex_search(text, match, regex("<td>美元</td>([^]*?)<td class=\"pjrq\">"))