文章目录
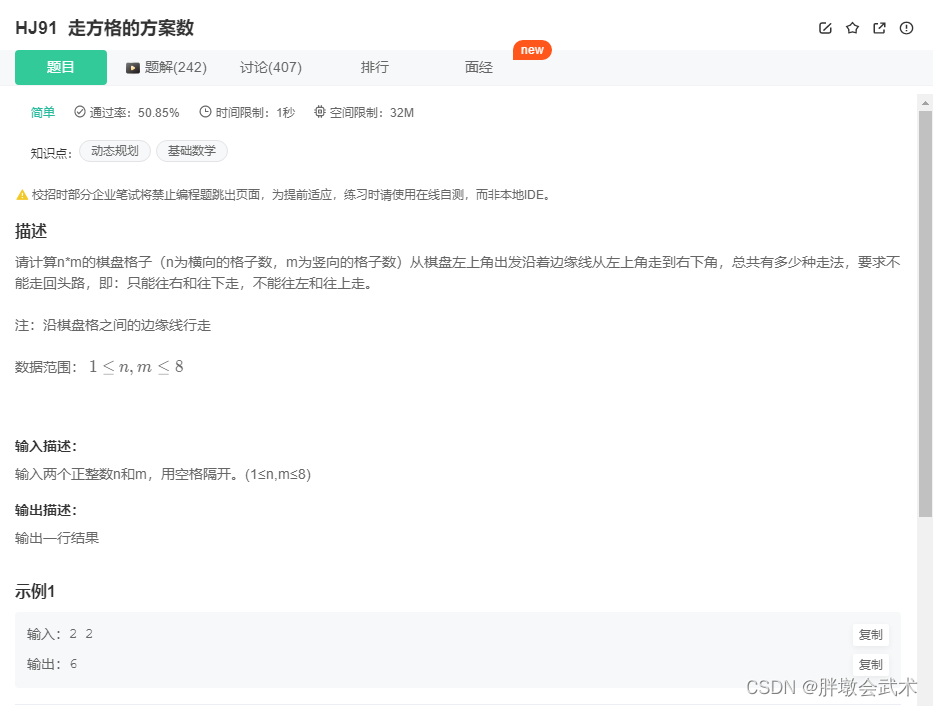
(1)题目描述
(2)Python3实现
def f(n, m):
if n == 0 or m == 0:
return 1 # 若到达右下角,则走法+1
else:
return f(n-1, m) + f(n, m-1) # 递归相加(向右和向下分别计算)
while True:
try:
n1, m1 = map(int, input().split())
print(f(n1, m1))
except:
break
(3)知识点详解
1、input():获取控制台(任意形式)的输入。输出均为字符串类型。
str1 = input()
print(str1)
print('提示语句:', str1)
print(type(str1))
'''
asd123!#
提示语句: asd123!#
<class 'str'>
'''
| 常用的强转类型 | 说明 |
|---|---|
int(input()) |
强转为整型(输入必须时整型) |
list(input()) |
强转为列表(输入可以是任意类型) |
1.1、input() 与 list(input()) 的区别、及其相互转换方法
- 相同点:两个方法都可以进行for循环迭代提取字符,提取后都为字符串类型。
- 不同点:
str = list(input())将输入字符串转换为list类型,可以进行相关操作。如:str.append()
- 将列表转换为字符串:
str_list = ['A', 'aA', 2.0, '', 1]
- 方法一:
print(''.join(str))- 方法二:
print(''.join(map(str, str_list)))备注:若list中包含数字,则不能直接转化成字符串,否则系统报错。
- 方法一:
print(''.join([str(ii) for ii in str_list]))- 方法二:
print(''.join(map(str, str_list)))
map():根据给定函数对指定序列进行映射。即把传入函数依次作用到序列的每一个元素,并返回新的序列。
(1) 举例说明:若list中包含数字,则不能直接转化成字符串,否则系统报错。
str = ['25', 'd', 19, 10]
print(' '.join(str))
'''
Traceback (most recent call last):
File "C:/Users/Administrator/Desktop/test.py", line 188, in <module>
print(' '.join(str))
TypeError: sequence item 3: expected str instance, int found
'''
(2)举例说明:若list中包含数字,将list中的所有元素转换为字符串。
str_list = ['A', 'aA', 2.0, '', 1]
print(''.join(str(ii) for ii in str_list))
print(''.join([str(ii) for ii in str_list]))
print(''.join(map(str, str_list))) # map():根据给定函数对指定序列进行映射。即把传入函数依次作用到序列的每一个元素,并返回新的序列。
'''
AaA2.01
AaA2.01
AaA2.01
'''
2、print() :打印输出。
x, y = 1, 9
print('{},{}' .format(x, y)) # 打印方法一
print('*'*10) # 打印分割符
print(x, ',', y) # 打印方法二
'''
1,9
**********
1 , 9
'''
3、map():将指定函数依次作用于序列中的每一个元素 —— 返回一个迭代器,结果需指定数据结构进行转换后输出。
函数说明:
map(function, iterable)
输入参数:
function:指定函数。iterable:可迭代对象
print('返回一个迭代器: ', map(int, (1, 2, 3)))
# 返回一个迭代器: <map object at 0x0000018507A34130>
结果需指定数据结构进行转换后输出
- 数据结构:list、tuple、set。可转换后输出结果
- 数据结构:str。返回一个迭代器
- 数据结构:dict。ValueError,需输入两个参数
print('将元组转换为list: ', list(map(int, (1, 2, 3))))
print('将字符串转换为list: ', tuple(map(int, '1234')))
print('将字典中的key转换为list: ', set(map(int, {
1: 2, 2: 3, 3: 4})))
'''
将元组转换为list: [1, 2, 3]
将字符串转换为list: (1, 2, 3)
将字典中的key转换为list: {1, 2, 3}
'''
################################################################################
dict_a = [{
'name': 'python', 'points': 10}, {
'name': 'java', 'points': 8}]
print(list(map(lambda x : x['name'] == 'python', dict_a)))
print(dict(map(lambda x : x['name'] == 'python', dict_a)))
"""
[True, False]
TypeError: cannot convert dictionary update sequence element #0 to a sequence
"""
4、str.split():通过指定分隔符(默认为空格)对字符串进行切片,并返回分割后的字符串列表(list)。
函数说明:
str.split(str=".", num=string.count(str))[n]
参数说明:
- str: 表示分隔符,默认为空格,但是不能为空。若字符串中没有分隔符,则把整个字符串作为列表的一个元素。
- num:表示分割次数。如果存在参数num,则仅分隔成 num+1 个子字符串,并且每一个子字符串可以赋给新的变量。
- [n]: 表示选取第n个切片。
- 注意:当使用空格作为分隔符时,对于中间为空的项会自动忽略。
s = 'www.dod.com.cn'
print('分隔符(默认): ', s.split()) # 【输出结果】分隔符(默认): ['www.dod.com.cn']
print('分隔符(.): ', s.split('.')) # 【输出结果】分隔符(.): ['www', 'dod', 'com', 'cn']
print('分割1次, 分隔符(.): ', s.split('.', 1)) # 【输出结果】分割1次, 分隔符(.): ['www', 'dod.com.cn']
print('分割2次, 分隔符(.): ', s.split('.', 2)) # 【输出结果】分割2次, 分隔符(.): ['www', 'dod', 'com.cn']
print('分割2次, 分隔符(.), 取出分割后下标为1的字符串: ', s.split('.', 2)[1]) # 【输出结果】分割2次, 分隔符(.), 取出分割后下标为1的字符串: dod
print(s.split('.', -1)) # 【输出结果】['www', 'dod', 'com', 'cn']
###########################################
# 分割2次, 并分别保存到三个变量
s1, s2, s3 = s.split('.', 2)
print('s1:', s1) # 【输出结果】s1: www
print('s2:', s1) # 【输出结果】s2: www
print('s3:', s2) # 【输出结果】s3: dod
###########################################
# 连续多次分割
a = 'Hello<[www.dodo.com.cn]>Bye'
print(a.split('[')) # 【输出结果】['Hello<', 'www.dodo.com.cn]>Bye']
print(a.split('[')[1].split(']')[0]) # 【输出结果】www.dodo.com.cn
print(a.split('[')[1].split(']')[0].split('.')) # 【输出结果】['www', 'dodo', 'com', 'cn']