一.使用scrapy模拟抓取百度翻译json数据
爬虫文件中的代码
import scrapy
import json
class TranslateSpider(scrapy.Spider):
name = 'translate'
# allowed_domains = ['xx.com']
# start_urls = ['http://xx.com/'] #这里发起的是post请求
def start_requests(self):
data = {
'kw': 'spide'
}
yield scrapy.FormRequest(url='https://fanyi.baidu.com/sug',callback=self.parse,formdata=data)
def parse(self, response):
obj = json.loads(response.text)
value= obj['data'][0]['v']
print(value)
pass
start_requests(self) 是一个专门发送post请求的一个方法
data是发起post请求需要的表单数据
scrapy.FromRequest()这个对url发起post请求,里面需要填入url地址,callback函数,data表单
这里最后有一个json,导入json库,就是因为这个网页返回的数据是json数据,然后需要先通过json.loads()方法拿到obj对象,最后通过字典的key获取相应value值就好了
二.scrapy模拟登录github
1.分析网页

这里可以看到表单需要的数据在登录界面的源代码中,使用input隐藏标签将表单数据隐藏

抓取思路
1.首先我们需要对登录界面发起一个get请求,拿到我们form表单中所需的name属性值

2…拿到表单数据后,利用生成器yield 对github发起post请求,并且传入表单数据

3,将返回的github源码写入一个html文件中
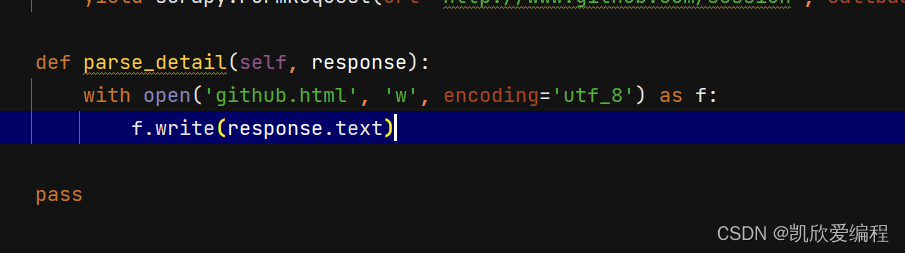
4.创建scapy项目启动文件运行爬虫文件

5.拿到github数据的网页源码
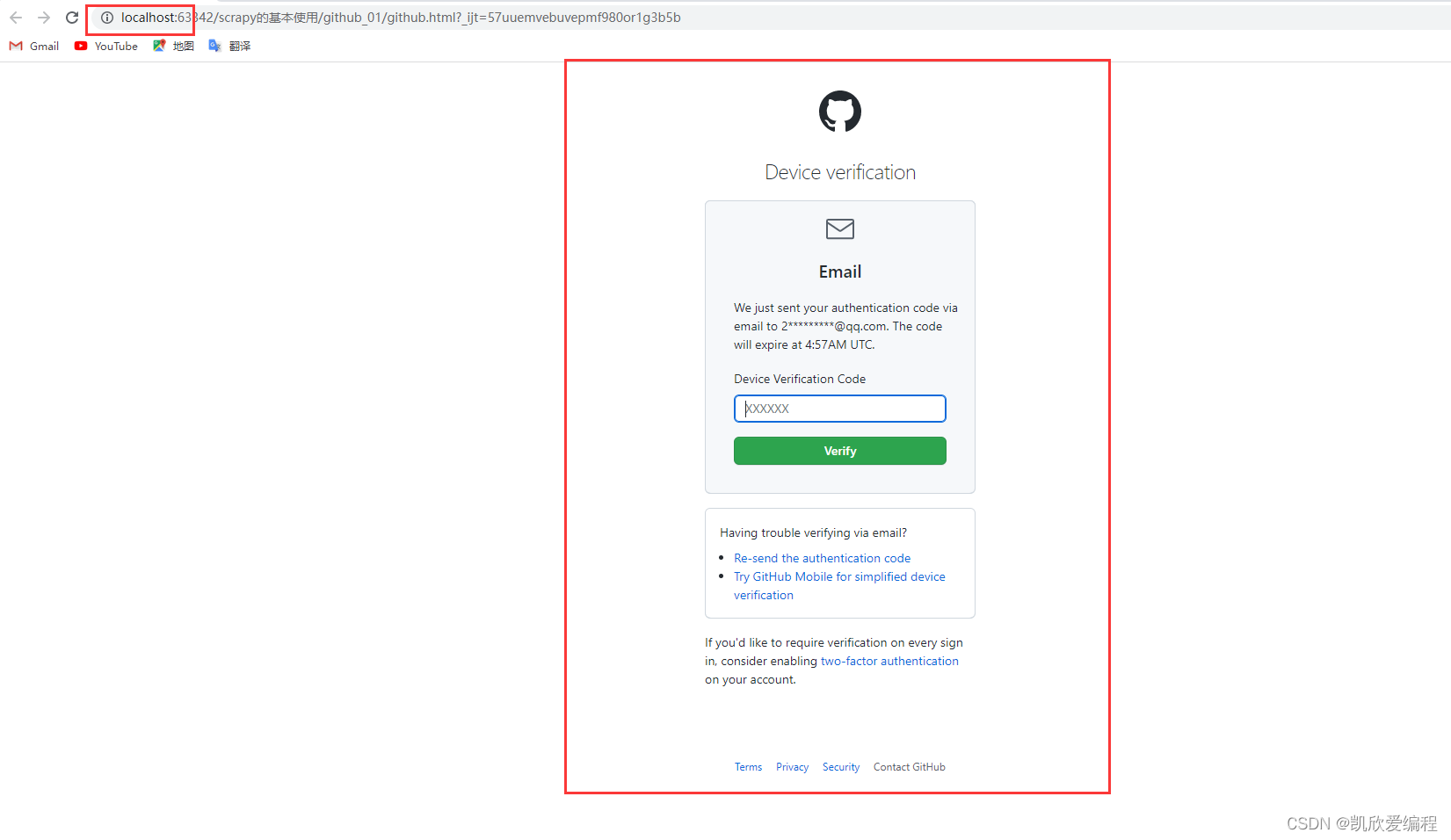
看到我们上面是localhost登录说明我们已经登陆成功了,这里因为没有直接进入github页面是因为我好久没有登陆github了,你直接输入你邮箱接收的验证码就好了
创建scrapy项目和爬虫文件和基本的配置就不写了,不清楚可以看我scrapy的第一篇文章