物理分区
“分区”(partitioning)操作就是要将数据进行重新分布,传递到不同的流分区去进行下一 步计算。keyBy()是一种逻辑分区(logical partitioning)操作。 Flink 对于经过转换操作之后的 DataStream,提供了一系列的底层操作算子,能够帮我们 实现数据流的手动重分区。为了同 keyBy()相区别,我们把这些操作统称为“物理分区”操作。
常见的物理分区策略有随机分区、轮询分区、重缩放和广播,还有一种特殊的分区策略— —全局分区,并且 Flink 还支持用户自定义分区策略。
随机分区(shuffle)
最简单的重分区方式就是直接“洗牌”。通过调用 DataStream 的 shuffle()方法,将数据随 机地分配到下游算子的并行任务中去。
创建一个数据流类作为数据源
class f4 extends SourceFunction[ Event ]{ //实现SourceFunction接口 泛型为之前定义好的样例类Event
//标志位
var running = true
//重写抽象方法
override def run(sourceContext: SourceFunction.SourceContext[Event]): Unit = {
//随机数生成器
val random = new Random ()
//定义数据随机选择的范围
val user = Array ("张三", "李四", "王五")
val url = Array ("02", "01", "03", "04")
//用标志位作为循环判断条件,不停的发出数据
while (running) {
val event = Event (user (random.nextInt (user.length) ), url (random.nextInt (url.length) ), Calendar.getInstance.getTimeInMillis)
//调用ctx的方法向下游发送数据
sourceContext.collect (event)
//每隔1秒发送一条数据
Thread.sleep (1000)
}
}
override def cancel(): Unit = running = false
}进行随机分区操作
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置全局并行度
env.setParallelism(1)
//读取数据流文件
val stream: DataStream[Event] = env.addSource( new f4)
//洗牌之后打印输出
stream.shuffle.print().setParallelism(4) //并行度设置为4
//执行
env.execute()
}分区结果基本都是均匀随机的
轮询分区(Round-Robin)
轮询也是一种常见的重分区方式。简单来说就是“发牌”,按照先后顺序将数据做依次分发。通过调用 DataStream的.rebalance()方法,就可以实现轮询重分区。rebalance() 使用的是 Round-Robin 负载均衡算法,可以将输入流数据平均分配到下游的并行任务中去
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置全局并行度
env.setParallelism(1)
//读取数据流文件
val stream: DataStream[Event] = env.addSource( new f4)
//轮询重分区之后打印输出
stream.rebalance.print().setParallelism(4) //并行度设置为4
//执行
env.execute()
}按照规律顺序的轮询分区输出

重缩放分区(rescale)
重缩放分区和轮询分区非常相似。当调用 rescale()方法时,其实底层也是使用 Round-Robin算法进行轮询,但是只会将数据轮询发送到下游并行任务的一部分中。也就 是说,“发牌人”如果有多个,那么 rebalance()的方式是每个发牌人都面向所有人发牌;而 rescale()的做法是分成小团体,发牌人只给自己团体内的所有人轮流发牌。
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置全局并行度
env.setParallelism(1)
//读取数据流文件
val stream: DataStream[Int] = env.addSource(new RichParallelSourceFunction[Int] { //定义一个并行的数据源
override def run(ctx: SourceFunction.SourceContext[Int]): Unit = {
for (i <- 0 to 10) {
//利用运行时上下文中的subTask的信息来控制数据由哪个并行子任务生成
if( getRuntimeContext.getIndexOfThisSubtask == (i + 1) % 2 )
ctx.collect(i + 1)
}
}
override def cancel(): Unit = ???
})setParallelism(2) //并行度设置为2
//分区之后打印输出
stream.rescale.print().setParallelism(4) //并行度设置为4
//执行
env.execute()
}
广播(broadcast)
这种方式其实不应该叫作“重分区”,因为经过广播之后,数据会在不同的分区都保留一 份,可能进行重复处理。可以通过调用 DataStream 的 broadcast()方法,将输入数据复制并发送 到下游算子的所有并行任务中去。
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置全局并行度
env.setParallelism(1)
//读取数据流文件
val stream: DataStream[Event] = env.addSource( new f4)
//分区之后打印输出
stream.broadcast.print().setParallelism(4) //并行度设置为4
//执行
env.execute()
}
全局分区(global)
全局分区也是一种特殊的分区方式。这种做法非常极端,通过调用.global()方法,会将所 有的输入流数据都发送到下游算子的第一个并行子任务中去。这就相当于强行让下游任务并行 度变成了 1,所以使用这个操作需要非常谨慎,可能对程序造成很大的压力。
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置全局并行度
env.setParallelism(1)
//读取数据流文件
val stream: DataStream[Event] = env.addSource( new f4)
//分区之后打印输出
stream.global.print().setParallelism(4) //并行度设置为4
//执行
env.execute()
}执行后全部被划分到一个分区中

自定义分区(Custom)
当Flink提供的所有分区策略都不能满足用户的需求时,我们可以通过使用partitionCustom()方法来自定义分区策略。 在调用时,方法需要传入两个参数,第一个是自定义分区器(Partitioner)对象,第二个 是应用分区器的字段,它的指定方式与 keyBy 指定 key 基本一样:可以通过字段名称指定, 也可以通过字段位置索引来指定,还可以实现一个 KeySelector 接口。
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env
.fromElements(1,2,3,4,5,6,7,8)
.partitionCustom(
new Partitioner[Int] {
// 根据 key 的奇偶性计算出数据将被发送到哪个分区
override def partition(key: Int, numPartitions: Int): Int = key % 2
},
data => data // 以自身作为 key
)
.print()
env.execute()
}
输出算子(Sink)

连接到外部系统
与 Source 算子非常类似,除去一些 Flink 预实现的 Sink,一般情况下 Sink 算子的创建是 通过调用 DataStream 的 addSink()方法实现的。
stream.addSink(new SinkFunction(…))addSource 的参数需要实现一个 SourceFunction 接口;类似地,addSink 方法同样需要传入 一个参数,实现的是 SinkFunction 接口。在这个接口中只需要重写一个方法 invoke(),用来将指 定的值写入到外部系统中。这个方法在每条数据记录到来时都会调用:
default void invoke(IN value, Context context) throws Exception输出到文件
case class Event(user: String, url: String, timestamp: Long) def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置全局并行度
env.setParallelism(1)
//创建当前样例类Event的对象
val stream: DataStream[Event] = env.fromElements(
Event("张三", "01", 1000L),
Event("李四", "04", 2000L),
Event("王五", "01", 6000L),
Event("赵六", "03", 1000L)
)
//以文本形式分布式的写入文件中
//定义fileSink
val fileSink: StreamingFileSink[String] = StreamingFileSink
.forRowFormat(new Path("D:\\Flink\\datas"), new SimpleStringEncoder[String]("UTF-8"))
.build()
//转换为String StreamingFileSink.forRowFormat("路径","编码器")
stream.map(_.toString).addSink(fileSink)
//执行
env.execute()
}
输出到 Kafka
Flink 官方为 Kafka 提供了 Source 和 Sink 的连接器,我们可以用它方便地从 Kafka 读写数 据。Flink 与 Kafka 的连接器提供了端到端的精确一次(exactly once)语义保证,这在实际项 目中是最高级别的一致性保证。
配置步骤:
- 添加 Kafka 连接器依赖 。
- 启动 Kafka 集群
- 编写输出到 Kafka 的示例代码
我们可以直接将用户行为数据保存为文件 clicks.csv,读取后不做转换直接写入 Kafka,主 题(topic)命名为“clicks”。
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置全局并行度
env.setParallelism(1)
//将数据写入到kafa
//创建连接配置
val properties = new Properties()
properties.put("bootstrap.servers", "hadoop102:9092")
val stream = env.readTextFile("input/clicks.csv")
stream.addSink(new FlinkKafkaProducer[String](
"clicks",
new SimpleStringSchema(),
properties
))
//执行
env.execute()
}我们可以直接将用户行为数据保存为文件 clicks.csv,读取后不做转换直接写入 Kafka,主 题(topic)命名为“clicks”。
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic clicks
输出到 Redis
Flink 没有直接提供官方的 Redis 连接器,不过 Bahir 项目还是担任了合格的辅助角色,为 我们提供了 Flink-Redis 的连接工具。但版本升级略显滞后,目前连接器版本为 1.1,支持的 Scala 版本最新到 2.11。
导入的 Redis 连接器依赖
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency> def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//创建连接配置
val conf = new FlinkJedisPoolConfig.Builder().setHost("hadoop102").build()
env.addSource(new ClickSource)
.addSink(new RedisSink[Event](conf, new MyRedisMapper())) //写入
env.execute()
}输出到 MySQL(JDBC)
添加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>准备数据表

写入mysql
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置全局并行度
env.setParallelism(1)
//将数据写入到mysql
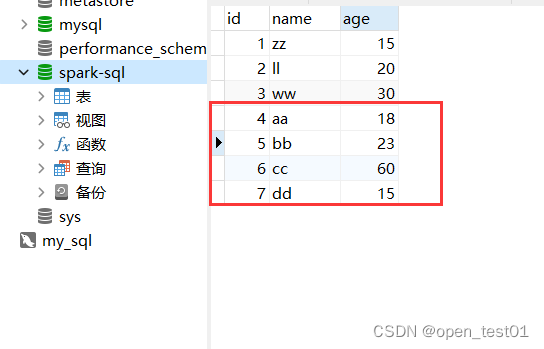
val stream: DataStream[Event] = env.fromElements(
Event(4, "aa", 18),
Event(5, "bb", 23),
Event(6, "cc", 60),
Event(7, "dd",15)
)
//JdbcSink.sink(需要写入的sql语句,添加的元素,连接jdbc的配置)
stream.addSink( JdbcSink.sink(
"INSERT INTO user(id,name,age) VALUES(?,?,?)", //定义写入mysql的语句
new JdbcStatementBuilder[Event] {
override def accept(t: PreparedStatement, u: Event): Unit = {
//setInt(索引位置,元素)
t.setInt(1,u.id)
t.setString(2,u.name)
t.setInt(3,u.age)
}
},
//创建JDBC连接的配置项
new JdbcConnectionOptions
.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://master:3306/spark-sql")
.withDriverName("com.mysql.jdbc.Driver") //添加驱动类
.withUsername("root") //指定用户名
.withPassword("p@ssw0rd") //指定密码
.build()
))
//执行
env.execute()
}如果运行时报如下错误:
Wed Mar 22 20:36:28 CST 2023 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.
警告:不建议在没有服务器身份验证的情况下建立SSL连接。根据MySQL 5.5.45+、5.6.26+和5.7.6+的要求,如果没有设置显式选项,默认必须建立SSL连接。为了符合不使用SSL的现有应用程序,verifyServerCertificate属性被设置为'false'。您需要通过设置useSSL=false显式禁用SSL,或者设置useSSL=true并为服务器证书验证提供信任存储区。
hive中conf目录下的hive-site.xml中在mysql连接字符串的url中添加配置 ?useSSL=false即可

useSSL=false //禁用SSL
useServerPrepStmts=true //开启预编译功能到数据表中查看添加成功