PaddleDetection是百度Paddle家族的一个目标检测开发套件。个人感觉Paddle的优点是模型比较丰富,支持的部署方式较多(python、C++、移动端等),缺点是坑比较多,百度的老毛病了,什么都弄一点,但都不精通。本文研究了下PaddleDetection的使用流程,从自己的数据集(我工作中使用到的),记录下整个训练、推理、部署的过程。
一、PaddleDetection的安装
安装比较简单,参考官方教程即可。安装教程路径:PaddleDetection/docs/tutorials/INSTALL.md
先说一个自己安装时碰到的大坑:
Paddle2.3(最新的)与ubuntu22.04不兼容,原因是ubuntu22.04的gcc版本较高,paddle不支持这么高的gcc版本。
本博文安装的版本为paddlepaddle-gpu==2.3.1 paddledetection==2.4
二、PaddleDetection训练自己的数据集(coco)
2.1 paddledetection文件介绍

如图为paddledetection的文件结构,其中configs为配置文件,基本上配置文件就定义了网络的所有结构、数据集、训练策略等。output用来存放训练好的模型,tools内包含了基本的train val等工具脚本。
2.2 构造自己的数据集
paddledetection支持voc、coco、 widerface格式,其中coco的模型最多。coco的数据格式依赖于labelme的标注文件,标注好后转成coco的数据格式就行了,至于转换的代码,网上有很多labelme2coco的脚本,paddledeteciont的文件目录里tools/x2coco.py也可以。目的是构造出对应的coco数据格式如下:

其中,annotations目录包含instances_train2017.json和instaances_val2017.json(用于检测和分割),train2017目录(训练集原图像)和val2017(验证集原图像)。coco数据集说明具体参考PaddleDetection/docs/tutorials/PrepareDataset.md
本次我自己使用的是一个包含5个类别的目标检测数据集,共计包含2k张图片,已按照9:1的比例分为训练集和验证集,由于数据涉及到工作业务,就不具体展示说明了。
2.3 修改配置文件
本文选取faster_rcnn_r50_vd_fpn_ssld_2x_coco.yml模型进行训练,在说明文件configs/faster_rcnn/README.md中,此网络在coco数据上达到了最优的map: 42.6
打开configs/faster_rcnn/faster_rcnn_r50_vd_fpn_ssld_2x_coco.yml发现这就是一个套娃模式的配置文件,一层层打开去配置就行了。
一般的配置都会包含三个主要内容:数据配置、训练策略、网络模型。如下图
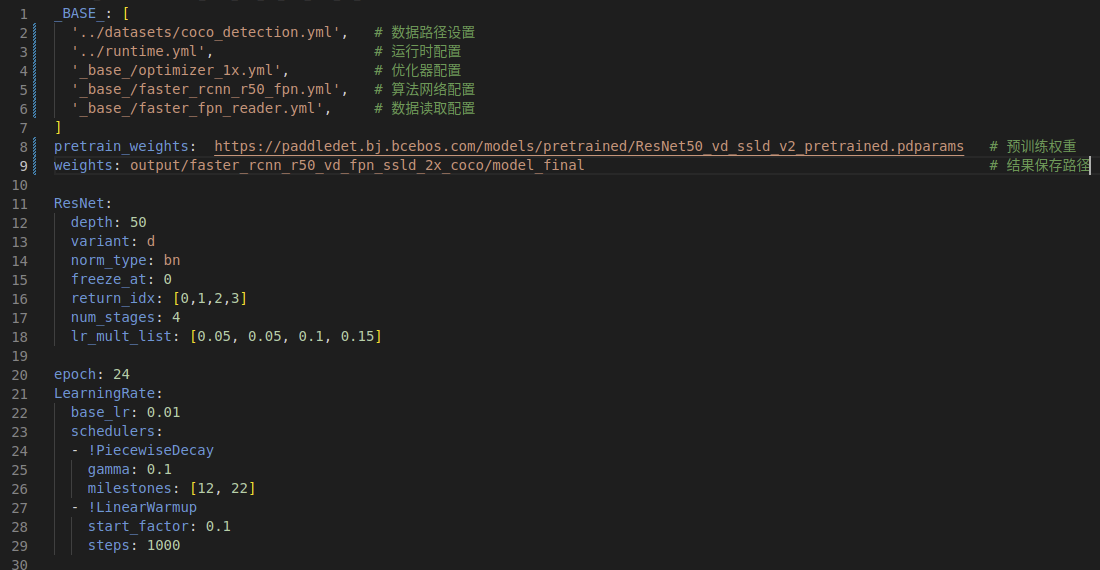
其中, 数据配置在coco_detection.yml

- num_classes:修改为自己数据集的类别数
- TrainDataset:训练集路径配置
- EvalDataset:验证集路径配置
- TestDataset:测试集路径配置,把验证集作为测试集即可
配置网络faster_rcnn_r50_fpn.yml

这是网络文件,里面定义了backbone,Head等信息,如果不自己修改模型的话(大佬级),这个文件基本上不用修改,使用官方的网络架构就好。注意这里的pretrained预训练模型是SwinTransformer的,并不是整个网络的。
配置训练策略faster_fpn_reader.yml, optimizer_1x.yml, runtime.yml。其实从名字就可以理解上述配置文件的内容。
- reader.yml表示数据tensor的读取配置,包括input_size、batch_size、transformer等参数设置;
- optimizer_swin_1x.yml表示优化器的配置,包括learning_rate、optimizer等参数设置;
- runtime.yml表示运行中的参数配置,包括use_gpu、log_iter、save_dir等参数
2.4 训练
Train & Val & Infer
# Train
export CUDA_VISIBLE_DEVICES=0
python tools/train.py -c configs/faster_rcnn/faster_rcnn_r50_vd_fpn_ssld_2x_coco.yml --eval --use_vdl=true
- -c : 配置文件.yml
- --eval : 边训练边评估开关
- --use_vdl : 可视化训练过程,与--vdl_log_dir参数成对使用
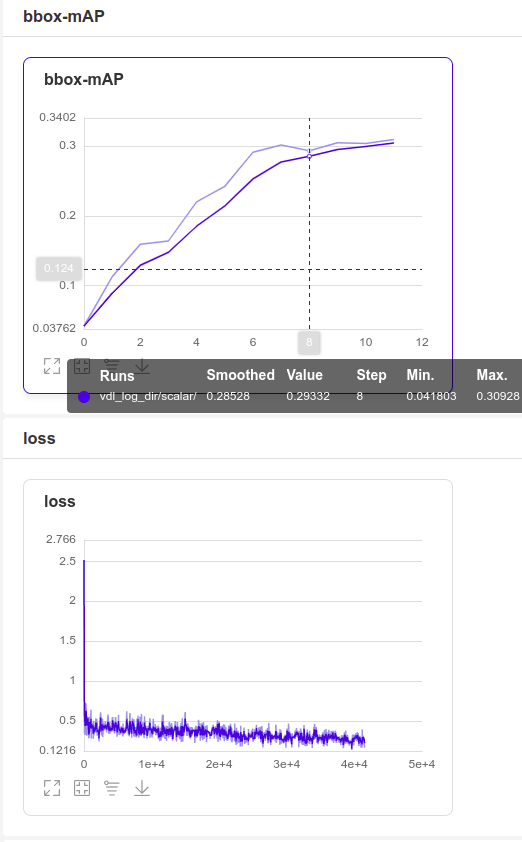
其中--vdl_log_dir的默认值为vdl_log_dir/scalar,当--use_vdl=true时,里面会生成训练过程的.log文件,记录loss和map变化。然后使用命令
visualdl --logdir vdl_log_dir/scalar/
可在“http://localhost:8040/”中生成一个web服务,可以看到loss变化。如下所示:
# Val
export CUDA_VISIBLE_DEVICES=0
python tools/eval.py -c configs/faster_rcnn/faster_rcnn_r50_vd_fpn_ssld_2x_coco.yml -o weights=output/faster_rcnn_r50_vd_fpn_ssld_2x_coco/ model_final.pdparams --classwise- -c :配置文件.yml
- -o : 权重文件.pdparams
- --classwise : 输出每单个类别的AP值
# Infer
export CUDA_VISIBLE_DEVICES=0
python tools/infer.py -c configs/faster_rcnn/faster_rcnn_r50_vd_fpn_ssld_2x_coco.yml -o weights=output/faster_rcnn_r50_vd_fpn_ssld_2x_coco/model_final.pdparams --infer_img=demo/DJI_1116.png --output_dir=output/ --draw_threshold=0.5 --use_vdl=True- -c : 设置配置文件.yml
- -o : 设置权重文件.pdparams
- --infer_img : 图片路径
- --output_dir : 结果保存路径
- --draw_threshold : 画图时选的边框置信度阈值
上述是一个完整的Train & Val & Infer过程。但在实际使用中,往往不会经常这样使用,因为这里的Infer耦合了很多训练部分的代码,且调用不够灵活。实际使用中,还需要一个步骤是deploy,同理deploy里也有Infer过程,是不依赖于训练过程的,且经过优化的,能够更好的嵌入到其他项目中。
三、模型导出与部署
在模型训练过程中保存的模型文件是包含前向预测和反向传播的过程,在实际的工业部署则不需要反向传播,因此需要将模型进行导成部署需要的模型格式。 在PaddleDetection中提供了 tools/export_model.py脚本来导出模型
python部署方式
# 导出模型
python tools/export_model.py -c configs/faster_rcnn/faster_rcnn_r50_vd_fpn_ssld_2x_coco.yml -o weights=output/faster_rcnn_r50_vd_fpn_ssld_2x_coco/model_final.pdparams --output_dir=./inference_model
模型导出后,在对应文件夹生成了四个文件如下:
infer_cfg.yml :预处理transformer参数,input_size参数等
model.pdiparams
model.pdiparams.info
model.pdmodel
# 预测
python deploy/python/infer.py --model_dir=./inference_model/faster_rcnn_r50_vd_fpn_ssld_2x_coco --image_file=demo/DJI_1116.png --device=GPU
paddledetection的文件和代码太多了,实际部署中根本用不到。更多的使用方式应该是:把paddle嵌入到项目中使用其推理过程。因为模型导出后就跟训练过程没关系了,所以我们只要把./inference_model里需要用到的模型文件夹,还有deploy文件夹复制到其他项目中就可以使用其推理功能了。
还是要参考deploy/python/infer.py的源码,最好是自己写一个Infer的函数,用来适应自己的业务需要。例子如下:

import os
import yaml
import glob
import json
from pathlib import Path
import time
import cv2
import numpy as np
import math
import paddle
from paddle.inference import Config
from paddle.inference import create_predictor
from infer import Detector, visualize_box_mask
# paddle.enable_static()
model_dir = "/home/elvis/CodeReconstruction/Det_Tinktek_V2.0/paddledetection/inference_model/faster_rcnn_r50_vd_fpn_ssld_2x_coco"
detector = Detector(model_dir,
device='GPU',
run_mode='paddle',
batch_size=1,
trt_min_shape=1,
trt_max_shape=1280,
trt_opt_shape=640,
trt_calib_mode=False,
cpu_threads=1,
enable_mkldnn=False,
enable_mkldnn_bfloat16=False,
output_dir='output',
threshold=0.5,
delete_shuffle_pass=False)
img_path = "/home/elvis/paddle/PaddleDetection/demo/1116.png"
frame = cv2.imread(img_path)
results = detector.predict_image([frame[:, :, ::-1]], visual=False) # bgr-->rgb
print(results)
print(detector.det_times.info())
im = visualize_box_mask(frame, results, detector.pred_config.labels, detector.threshold)
im = np.array(im)
cv2.imshow('Mask Detection', im)
cv2.waitKey(0)
# def pre_img(detector, frame:cv2):
# results = detector.predict_image([frame[:, :, ::-1]], visual=False) # bgr-->rgb
四、可能遇到的错误
我在使用模型configs/faster_rcnn/faster_rcnn_swin_tiny_fpn_3x_coco.yml进行训练时,用tools/infer.py推理也正常,但在模型导出后,使用deploy/python/infer.py推理出错,错误如下,暂时不知到问题出在哪。
