1.优化背景
开发过程中,随着业务逻辑过多过复杂,往往写代码的时候不重视代码的性能,往往选择以最方便的方式编写,这无疑埋下了一颗雷,只需要适当的条件去引爆。
所以我们急切于养成良好的编码方式以及远瞻能力,至少要对我们写的代码所应用的业务场景做个前瞻,根据业务迭代频率,开发效率,资源利用率等多方面去做好短期和长期规划,至少半年内不用重构。
2.问题发现
golang提供了pprof工具,它可以做以下数据的分析:
-
-
CPU Profiling:CPU 分析,按照一定的频率采集所监听的应用程序 CPU(含寄存器)的使用情况,可确定应用程序在主动消耗 CPU 周期时花费时间的位置
-
Memory Profiling:内存分析,在应用程序进行堆分配时记录堆栈跟踪,用于监视当前和历史内存使用情况,以及检查内存泄漏
-
Block Profiling:阻塞分析,记录 goroutine 阻塞等待同步(包括定时器通道)的位置
-
Mutex Profiling:互斥锁分析,报告互斥锁的竞争情况
-
-
我们使用了pprof工具能很清晰的看到项目中cpu和内存消耗过大的代码块,所以我们能快速的对症下药。
例图:
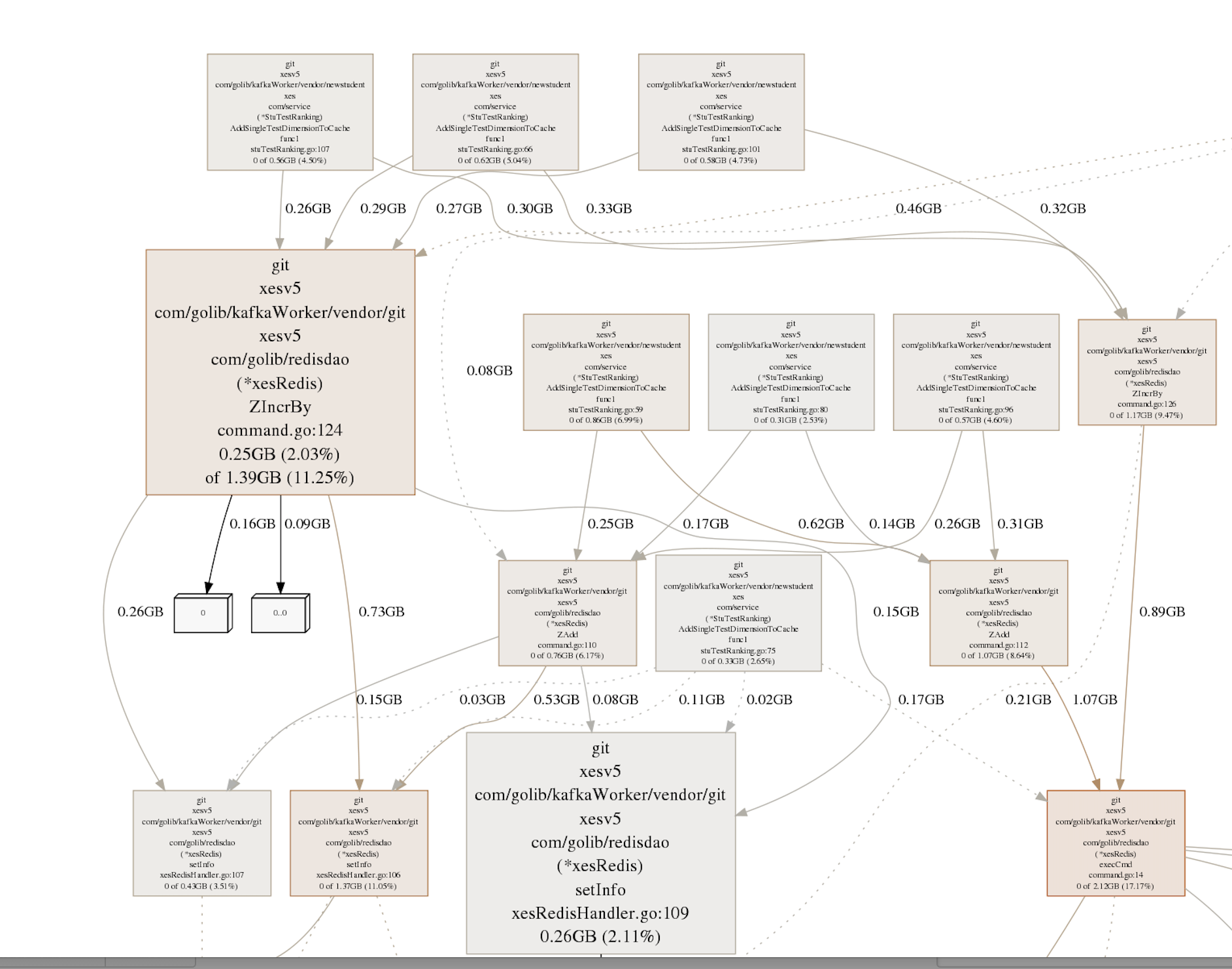
如果你想知道你的Go程序在做什么吗? go tool trace可以向你揭示:Go程序运行中的所有的运行时事件。 这种工具是Go生态系统中用于诊断性能问题时(如延迟,并行化和竞争异常)。
go tool trace可以显示大量的信息,所以从哪里开始是个问题。 我们首先简要介绍使用界面,然后我们将介绍如何查找具体问题。
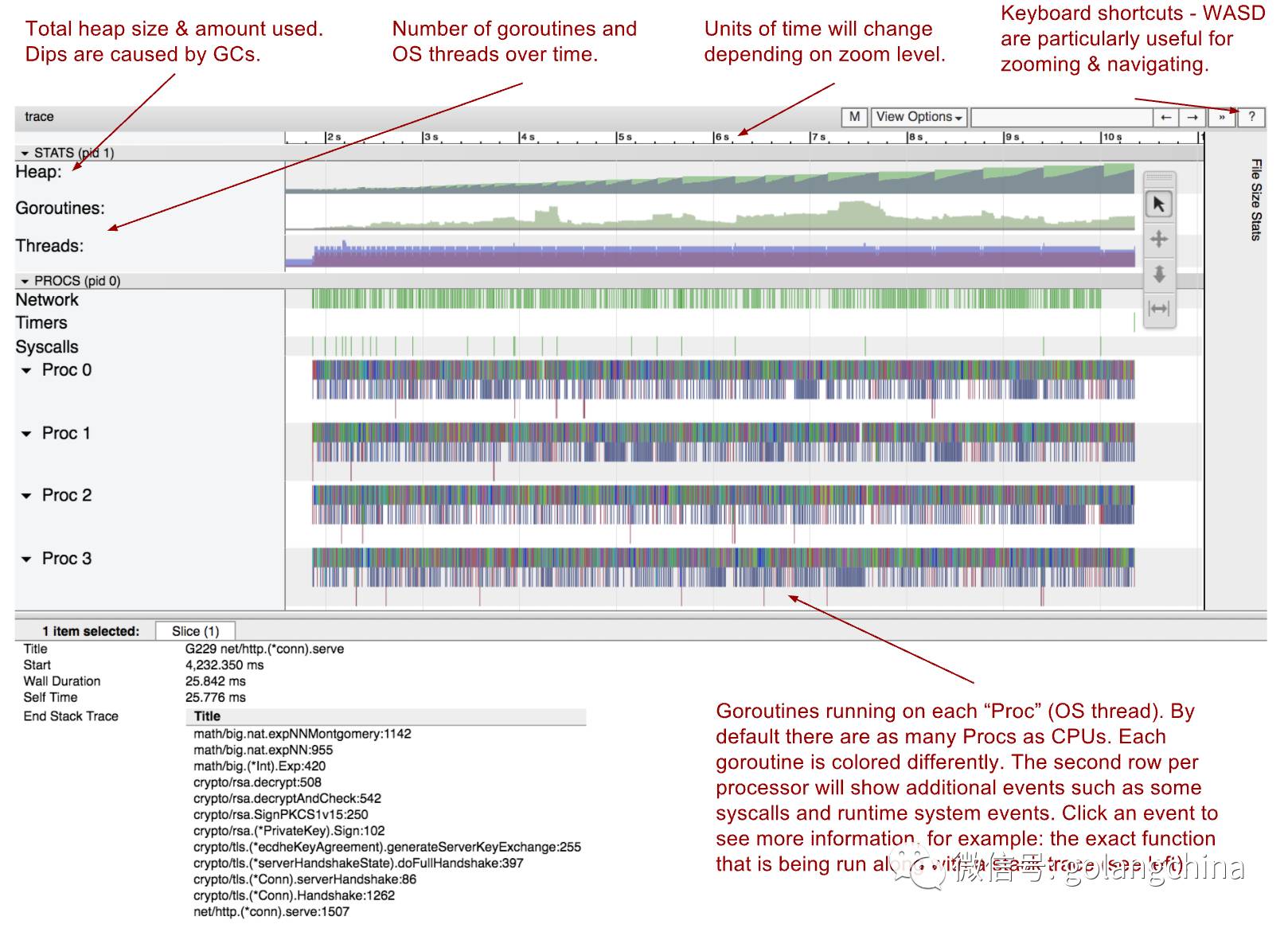
go tool traceUI是一个Web应用程序。 下面我已经嵌入了一个这个web程序的实例! 是可视化并行快速排序实现的追踪信息
3.GC原理

4.优化方案
-
网络IO
1.连接优化
&大量的短连接使用连接池提供长连接代替
&对连接数的消耗速率有个预估,给出最优连接池配置
2.数据优化
&对大数据传输使用压缩算法进行压缩,大小缩减到原数据大小的1/5以内
&优化数据结构,减少嵌套层级,精简字段大小,合理使用字段类型
3.协议封装
&对TCP进行封装,规定header及body的长度,避免粘包
&协议封装复用内存资源和对象资源,根据流量预估,给出最优复用方案 -
内存利用率
1.字符串处理优化
由于string类型是一个不可变类型,但拼接会创建新的string。GO中字符串拼接常见有如下几种方式:- string + 操作 :导致多次对象的分配与值拷贝
- fmt.Sprintf :会动态解析参数,效率好不哪去
- strings.Join :内部是[]byte的append
- bytes.Buffer :可以预先分配大小,减少对象分配与拷贝
&字符串拼接优先考虑bytes.Buffer
&减少[]byte和string的转换,统一使用[]byte处理
&bytes.Buffer等通过预先分配足够大的内存,避免当Grow时动态申请内存,这样可以减少内存分配次数
&频繁操作大字符串,考虑使用sync.Pool对象池,进行内存复用,合理设置内存池新对象的内存空间
2.对象优化
&避免频繁创建临时变量
&对象拷贝考虑使用指针引用,减少内存分配
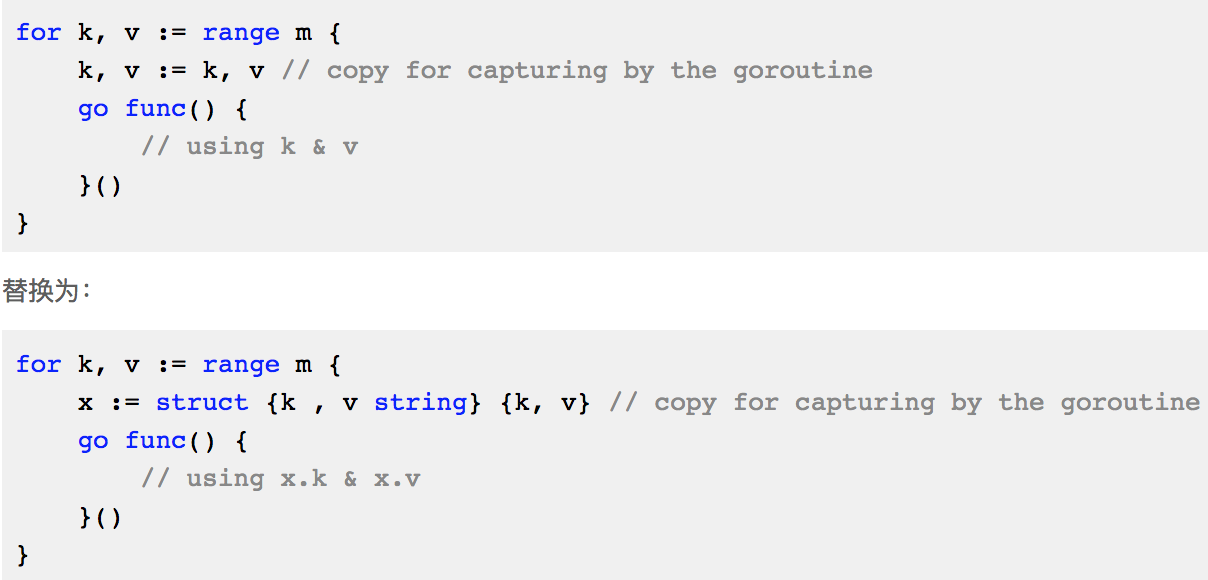
&创建频繁的对象,考虑使用sync.Pool对象池,进行对象复用,优化对象结构,精简属性字段 &小对象合并成结构体一次分配,减少内存分配次数,如例:
3.变量使用优化
&尽量使用局部变量
&多个局部变量合并一个大的结构体或数组,减少扫描对象的次数,一次回尽可能多的内存 &变量拷贝考虑使用指针引用,减少内存分配
4.slice和map的使用优化
&slice和map与数组不一样,不存在固定空间大小,可以根据增加元素来动态扩容。
&slice初始会指定一个数组,当对slice进行append等操作时,当容量不够时,会自动扩容:
- 如果新的大小是当前大小2倍以上,则容量增涨为新的大小;
- 否而循环以下操作:如果当前容量小于1024,按2倍增加;否则每次按当前容量1/4增涨,直到增涨的容量超过或等新大小。
&map的扩容比较复杂,每次扩容会增加到上次容量的2倍。它的结构体中有一个buckets和oldbuckets,用于实现增量扩容:
- 正常情况下,直接使用buckets,oldbuckets为空;
- 如果正在扩容,则oldbuckets不为空,buckets是oldbuckets的2倍,
&初始化时预估大小指定容量
m := make(map[string]string, 100) s := make([]string, 0, 100) // 注意:对于slice make时,第二个参数是初始大小,第三个参数才是容量5.并发优化
&goroutine尽量独立,无冲突地执行;若goroutine间存在冲突,则可以采分区来控制goroutine的并发个数,减少同一互斥对象冲突并发数
传统多线程编程时,当并发冲突在4~8线程时,性能可能会出现拐点。
Go中的推荐是不要通过共享内存来通讯,Go创建goroutine非常容易,当大量goroutine共享同一互斥对象时,也会在某一数量的goroutine出在拐点。
&goroutine虽轻量,但对于高并发的轻量任务处理,频繁来创建goroutine来执行,执行效率并不会太高效,考虑使用goroutine池:
- 过多的goroutine创建,会影响go runtime对goroutine调度,以及GC消耗;
- 高并时若出现调用异常阻塞积压,大量的goroutine短时间积压可能导致程序崩溃。
&把涉及到同步调用的goroutine,隔离到可控的goroutine中,而不是直接高并的goroutine调用
-
-
goroutine的实现,是通过同步来模拟异步操作。在如下操作操作不会阻塞go runtime的线程调度:
- 网络IO - 锁 - channel - time.sleep - 基于底层系统异步调用的Syscall 下面阻塞会创建新的调度线程: - 本地IO调用 - 基于底层系统同步调用的Syscall - CGo方式调用C语言动态库中的调用IO或其它阻塞 网络IO可以基于epoll的异步机制(或kqueue等异步机制),但对于一些系统函数并没有提供异步机制。例如常见的posix api中,对文件的操作就是同步操作。 - 虽有开源的fileepoll来模拟异步文件操作。但 Go的Syscall还是依赖底层的操作系统的API。系统API没有异步,Go也做不了异步化处理。
-
6.调用优化
&长调用栈避免申请过多的临时对象
goroutine的调用栈默认大小是4K(1.7修改为2K),它采用连续栈机制,当栈空间不够时,Go runtime会不动扩容:
-
当栈空间不够时,按2倍增加,原有栈的变量崆直接copy到新的栈空间,变量指针指向新的空间地址;
-
退栈会释放栈空间的占用,GC时发现栈空间占用不到1/4时,则栈空间减少一半。
比如栈的最终大小2M,则极端情况下,就会有10次的扩栈操作,这会带来性能下降。
建议:
-
- 控制调用栈和函数的复杂度,不要在一个goroutine做完所有逻辑;
- 如查的确需要长调用栈,而考虑goroutine池化,避免频繁创建goroutine带来栈空间的变化。
- 控制调用栈和函数的复杂度,不要在一个goroutine做完所有逻辑;
&避免使用cgo或者减少cgo调用次数
GO可以调用C库函数,但Go带有垃圾收集器且Go的栈动态增涨,但这些无法与C无缝地对接。
Go的环境转入C代码执行前,必须为C创建一个新的调用栈,把栈变量赋值给C调用栈,调用结束现拷贝回来。
而这个调用开销也非常大,需要维护Go与C的调用上下文,两者调用栈的映射。相比直接的GO调用栈,单纯的调用栈可能有2个甚至3个数量级以上。