做nlp很多时候要用到嵌入层,pytorch中自带了这个层
什么是embedding层
我用最通俗的语言给你讲
在nlp里,embedding层就是把单词表[‘你’,‘好’,‘吗’]
编码成
‘你’ --------------[0.2,0.1]
‘好’ --------------[0.3,0.2]
‘吗’ --------------[0.6,0.5]
的向量的办法
为什么要embedding
我还是用一句话概括:
因为one-hot编码表示太浪费内存了,我们都是穷人家的孩子。
pytorch里面怎么用
类定义

参数
这里说几个重要参数:
- num_embeddings: 嵌入层字典的大小(单词本里单词个数)
- embedding_dim: 每个产出向量的大小

说明
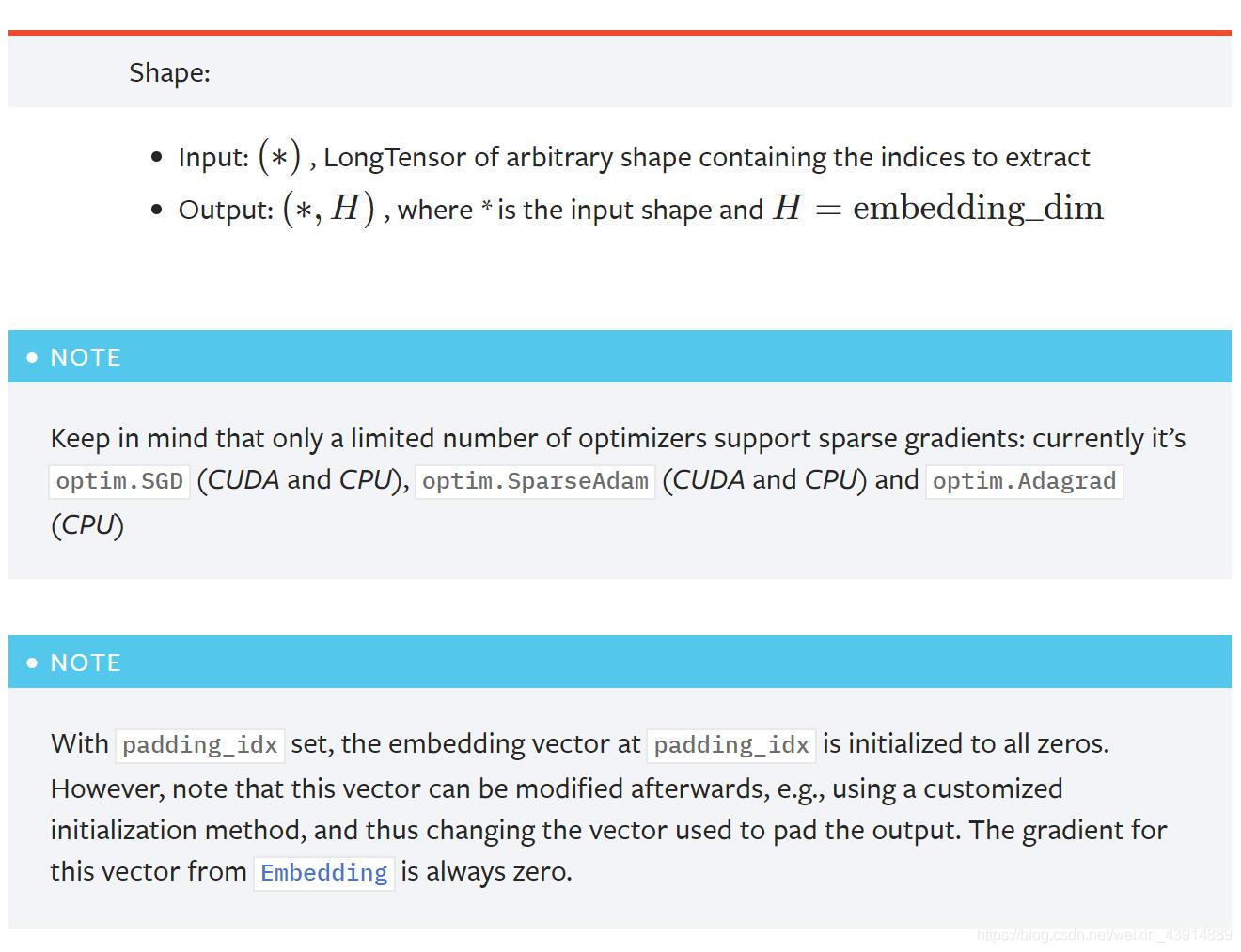
以下几点需要注意:
- 输入输出第一维度默认相同
实例
>>> # an Embedding module containing 10 tensors of size 3
>>> embedding = nn.Embedding(10, 3)
>>> # a batch of 2 samples of 4 indices each
>>> input = torch.LongTensor([[1,2,4,5],[4,3,2,9]])
>>> embedding(input)
tensor([[[-0.0251, -1.6902, 0.7172],
[-0.6431, 0.0748, 0.6969],
[ 1.4970, 1.3448, -0.9685],
[-0.3677, -2.7265, -0.1685]],
[[ 1.4970, 1.3448, -0.9685],
[ 0.4362, -0.4004, 0.9400],
[-0.6431, 0.0748, 0.6969],
[ 0.9124, -2.3616, 1.1151]]])
>>> # example with padding_idx
>>> embedding = nn.Embedding(10, 3, padding_idx=0)
>>> input = torch.LongTensor([[0,2,0,5]])
>>> embedding(input)
tensor([[[ 0.0000, 0.0000, 0.0000],
[ 0.1535, -2.0309, 0.9315],
[ 0.0000, 0.0000, 0.0000],
[-0.1655, 0.9897, 0.0635]]])
自己的小例子更容易懂
a = torch.LongTensor([0])
embedding = torch.nn.Embedding(2, 5)
b = embedding(a)
b
Out[29]: tensor([[1.7931, 0.5004, 0.3444, 0.7140, 0.3001]], grad_fn=<EmbeddingBackward>)
