可见性
所谓可见性,就是说一个线程对共享变量的修改,另一个线程能够立刻看到。
通俗点说,就是两个线程共享一个变量,无论哪一个线程修改了这个变量,另外一个线程都能够立刻看到上一个线程对这个变量的修改
产生可见性问题的原因
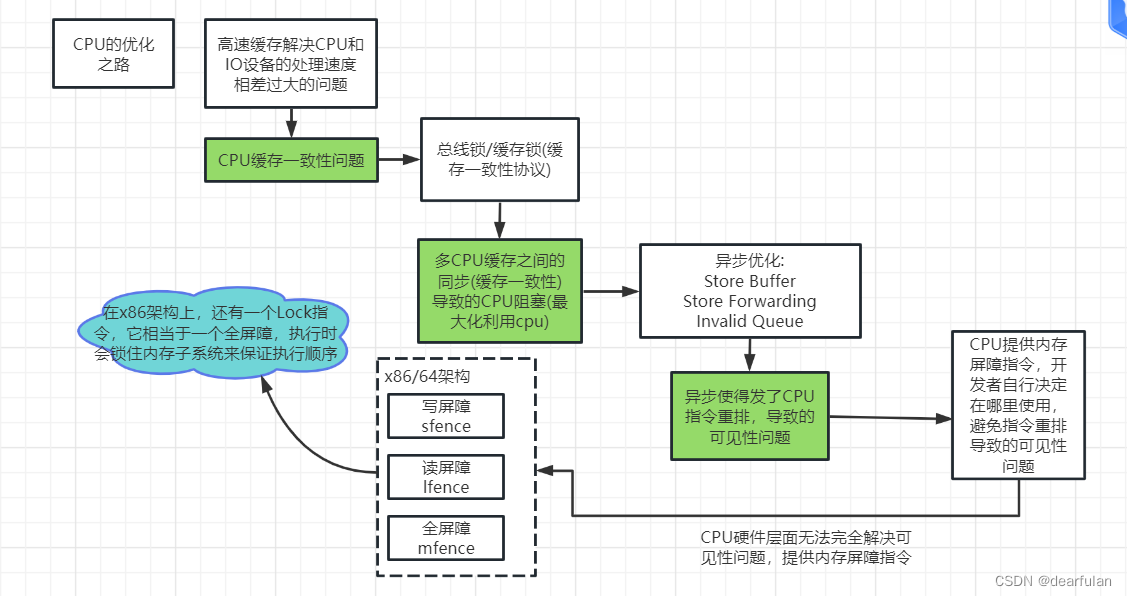
计算机是利用CPU进行数据运算的,但是CPU只能对内存中的数据进行运算,对于磁盘中的数据,必须要先读取到内存,CPU才能进行运算。cpu,内存,磁盘都会影响计算机的处理性能,同时这三者之间有个核心的矛盾点,就是三者在处理速度上的差异。CPU的计算速度是非常快的,其次是内存、最后是IO设备(比如磁盘),也就是说CPU的计算速度是远远高于内存以及磁盘设备的I/O速度的。
虽然CPU从单核升级到多核甚至到多线程技术在最大化的提高CPU的处理性能,但是仅仅提升CPU性能是不够的,如果内存和磁盘的处理性能没有跟上,就意味着整体的计算速度取决于最慢的设备,为了平衡这三者之间的速度差异,最大化的利用CPU。所以在硬件层面、操作系统层面、编译器层面做出了很多的优化
- CPU增加了高速缓存
- 操作系统增加了进程、线程。通过CPU的时间片切换最大化的提升CPU的使用率
- 编译器的指令优化,更合理的去利用好CPU的高速缓存
每一种优化,都会带来相应的问题,而这些问题是导致线程安全性问题的根源。
CPU高速缓存
CPU高速缓存的出现主要是为了解决CPU运算速度与内存读写速度不匹配的矛盾,因为CPU运算速度要比内存读写速度快很多,这样会使CPU花费很长时间等待数据到来或把数据写入内存。
这个高速缓存可以缓存存储在内存中的数据,CPU每次会先从缓存中读取需要运算的数据,如果缓存中不存在该数据,才会从内存中加载。
对于主流的x86平台,cpu的缓存(cache)分为L1、L2、L3总共3级 (处理速度L1>L2>L3)
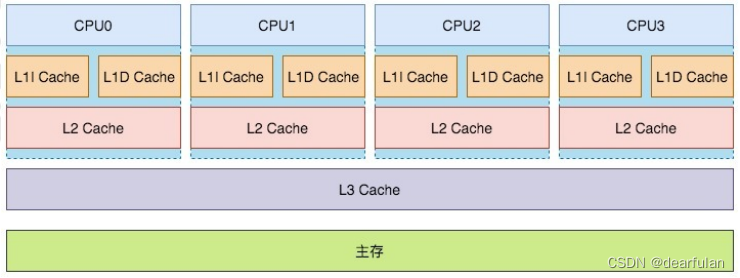
单核CPU下不存在可见性问题
我们还需要注意一点,那就是 在单核CPU上不存在可见性问题。 这是为什么呢?
因为在单核CPU上,无论创建了多少个线程,同一时刻只会有一个线程能够获取到CPU的资源来执行任务,即使这个单核的CPU已经添加了缓存。这些线程都是运行在同一个CPU上,他们使用的是同一个cpu缓存,只要其中一个线程修改了共享变量的值,那另外的线程就一定能够实时访问到最新的数据。
伪共享和缓存行填充
在系统工程中, 无论是在数据库还是系统内存,对于数据的访问,通常存在部分数据在时间上、空间上大概率的再次访问现象
- 时间局部性现象 如果一个主存数据正在被访问,那么在近期它被再次访问的概率非常大。
- 空间局部性现象 CPU使用到某块内存区域数据,这块内存区域后面临近的数据很大概率立即会被使用到。 例如数组、集合经常会顺序访问(内存地址连续或邻近)。
所以在cpu高速缓存中, 数据在各级缓存中是以缓存行(Cache line,缓存中可以分配的最小存储单位)为单位来存储和读写的,引用主内存中的一块连续地址 ,通常是 64 字节
由于数据在CPU高速缓存中是以缓存行为最小单位的,那么就有可能出现一个缓存行里存在多个对象的问题,此时如果有多个线程并发去操作这个缓存行,就可能会产生缓存失效的问题(也叫伪共享)
比方说CPU1的线程和CPU2的线程都从主内存中加载了一个缓存行到各自的L1,L2Cache中,该缓存行中存在三个变量x,y,z (由于三个变量都存在于两个cpu缓存中,也就是说三个变量都处于共享状态,具体的缓存状态下面会介绍)
此时,cpu1的线程修改了变量x, 为了保证缓存的数据一致性,就需要把cpu2里的缓存标记为失效状态,如果cpu2的线程要操作变量y,就需要cpu1先将对应的缓存行写到内存中,然后再从内存中读取最新的数据。如果两个cpu线程并发操作x,y变量,就会导致每次操作都需要重新去内存中加载数据,这个缓存的作用相当于没有了,也就是所谓的缓存失效
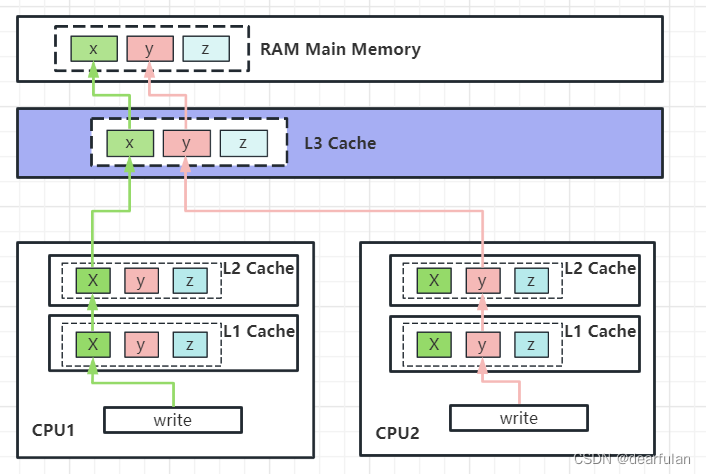
之所以产生这一问题,是因为缓存行的默认大小是64字节,而我们的定义的对象可能小于64字节,就会出现一个缓存行里有存在多个变量的问题,解决这一问题也很简单,我们将这个对象填充到64字节就行了。
java8里提供了@Contented来实现字节填充,注解既可以加在字段,也可以加在类上。加在字段上表示这个字段单独占一个缓存行,加在类上表示类中所有字段都独占一个缓存行。
使用@Contented注解需要配置jvm参数 -XX:-RestrictContended
public class ValuePaddingTest {
public static void main(String[] args) throws InterruptedException {
Pair pair = new Pair();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 2000000000; i++) {
pair.x++;
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 2000000000; i++) {
pair.y++;
}
});
long start = System.currentTimeMillis();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(System.currentTimeMillis() - start);
}
static class Pair {
long x1,x2,x3,x4,x5,x6,x7;
volatile long x=0;
long y1,y2,y3,y4,y5,y6,y7;
volatile long y=0;
}
}

public class NoValuePaddingTest {
public static void main(String[] args) throws InterruptedException {
Pair pair= new Pair();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 2000000000; i++) {
pair.x++;
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 2000000000; i++) {
pair.y++;
}
});
long start = System.currentTimeMillis();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(System.currentTimeMillis() - start);
}
static class Pair {
// long x1,x2,x3,x4,x5,x6,x7;
volatile long x = 0;
// long y1,y2,y3,y4,y5,y6,y7;
volatile long y = 0;
}
}

缓存一致性问题和缓存一致性协议
在多线程环境中,当多个线程并行执行加载同一块内存数据时,由于每个CPU都有自己独立的L1、L2缓存,所以每个CPU的这部分缓存空间都会缓存到相同的数据,并且每个CPU执行相关指令时,彼此之间不可见,就会导致缓存的一致性问题
为了达到数据访问的一致,我们可以通过锁(缓存锁,总线锁)来保证对各个缓存行操作的互斥。这就需要各个处理器在访问缓存时遵循一些协议,在读写时根据协议来操作,常见的协议有MSI,MESI,MOSI等。最常见的就是MESI协议。
MESI表示缓存行的四种状态,分别是
- M(Modify) 表示共享数据只缓存在当前CPU缓存中,并且是被修改状态,也就是缓存的数据和主内存中的数据不一致
- E(Exclusive) 独占状态 表示数据只缓存在当前CPU缓存中,并且没有被修改
- S(Shared) 共享状态 表示数据可能被多个CPU缓存,并且各个缓存中的数据和主内存数据一致
- I(Invalid) 失效状态 表示缓存已经失效
在CPU的缓存行中,每一个缓存的变量一定会处于Shared,Exclusive,Invalid三种状态之一
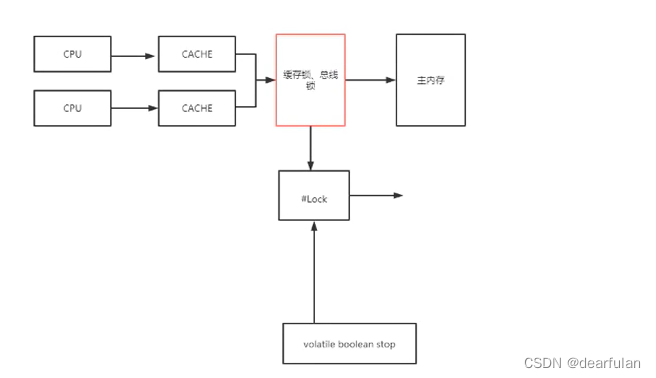
java代码中,我们在变量上添加volatile关键字,最终生成的执行指令里就会加一个#Lock(汇编指令), 触发缓存锁,从而保证可见性
CPU指令重排序
程序会在CPU层面/JVM层面优化指令的执行顺序,为什么要优化指令的执行顺序呢? 这是因为当多个cpu线程操作同一个变量时,如果一个cpu线程里修改了变量x的值,基于缓存一致性协议,就需要通知其他cpu该缓存数据已失效,并且要等所有CPU都响应确认后再再将最新的数据写入到主内存,这个期间当前cpu是处于空闲状态的。如下图所示:

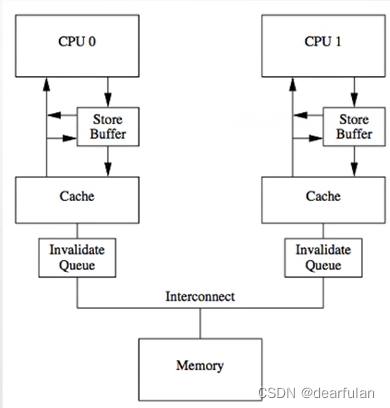
Store Buffer和Store Forwarding
为了最大限度的利用cpu的资源,引入了Store Buffer。CPU将修改后想要回写到主内存的数据写入到store buffer中,并发送一个令其他cpu中该数据无效的消息,然后继续处理后续指令。当发出去的设置该缓存为无效状态的通知都响应了后,数据才会最终被同步到主存中去。(利用了异步处理的思想,和mq类似)
function () {
a = 1;
b = a + 1;
assert(b == 2);
}
如果在a的修改写入到主内存之前,执行了b=a+1,那么最终计算出来的结果就会和预期的有出入,
由于store buffer可能会破坏程序的执行顺序,工程师在store buffer的基础上,又实现了store forwarding技术: cpu可以直接从store buffer中加载数据,即支持将cpu存入store buffer的数据传递(forwarding)给后续的加载操作,而不使用cache里的原始数据。
但是这样在多线程下还是会有问题:
a=0;b=0;
void function1() {
a = 1;
b = 1;
}
void function2() {
while (b == 1) {
assert(a == 1)
}
}
a,b的初始值都为0,假设a存在于cpu1的cache中,b存在于cpu0的cache中,均为Exclusive独占状态,cpu0执行function1()函数,cpu1执行function2()函数。
如下图所示 :
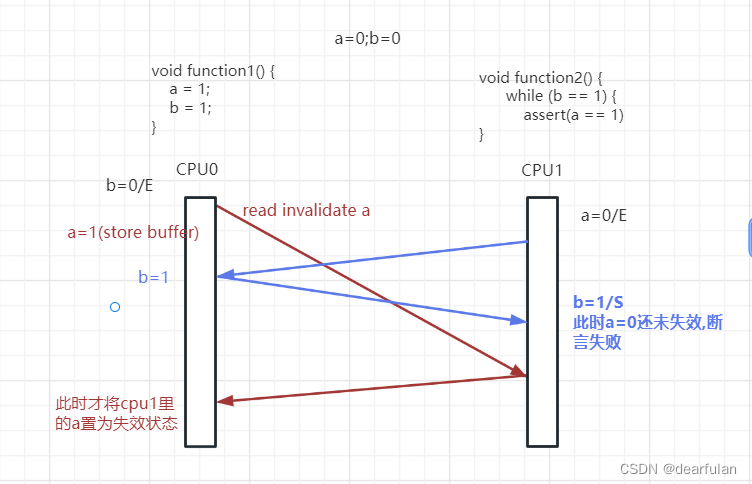
当cpu1执行function2()时,需要从cpu0读取b的值, 可以获取到最新的值b=1
而cpu0在执行function1()时, 需要从cpu1读取a的值(异步),所以会先将a=1放入到store buffer,而b=1由于该变量本来就是cpu0独占的,所以直接更新并写入到主内存;
此时由于cpu1还没有接受到a的失效消息,所以在执行function2()的时候,仍旧使用cpu1缓存里的值a=0, 结果导致断言不成立
出现这个问题的原因在于cpu并不知道变量a, b之间有依赖,cpu0对a的写入需要和其他cpu通信,因此有延迟,而对b的写入直接修改本地cache就行,因此b比a先在cache中生效,导致cpu1读到b=1时,a还存在于store buffer中。
Invalid Queue
基于前面的问题,又引入了Invalid Queue失效队列来优化这一问题,还是使用异步的思想,Invalidate ACK耗时的主要原因是cpu要先将对应的cache line置为Invalid后再返回应答,一个很忙的cpu可能会导致其它cpu都在等它的Invalidate ACK,通过异步方式, cpu可以先将Invalidate消息放到失效队列Invalid Queue,然后就返回Invalidate ACK。cpu可以后续再处理Invalid Queue中的消息,从而大幅降低Invalidate ACK的响应耗时(也就是减少上面红色箭头的耗时)。
不过由于Invalid Queue处理失效消息也是异步的,在cpu1执行断言的时候,如果Invalid Queue里的失效消息还没有处理,那么还是有可能读取到a=0的数据,导致断言失败
Invalid Queue 虽然不能解决顺序一致性带来的可见性问题,但是它可以帮助我们避免store buffer积压太多的数据,我们修改一个共享的数据之后,需要先发送invalidate 消息并等对方cpu回复Invalidate ACK,之后store buffer里的数据才会写入到主内存,这个等待过程中,本地cpu的store buffer是会不断写入新的数据的,并且如果对方cpu应答过慢(假设对方cpu太忙),那么本地cpu的store buffer是很可能会满出的。通过引入Invalid Queue,可以大大减少数据在store buffer里的存储时间
内存屏障
CPU由于性能优化导致的顺序一致性问题,在CPU层面无法被解决,因为CPU只是一个运算工具,它只负责接收指令和执行指令,并不清楚当前执行的整个逻辑中是否存在不能优化的问题,也就是说硬件层面也无法优化这种顺序一致性带来的可见性问题。
因此,在CPU层面提供了写屏障、读屏障、全屏障这样的指令,让开发者自己去判断是否允许cpu进行这样的优化
在x86架构中,这三种指令分别是SFENCE、LFENCE、MFENCE指令,
sfence:也就是save fence,写屏障指令。在sfence指令前的写操作必须在sfence指令后的写操作前完成。lfence:也就是load fence,读屏障指令。在lfence指令前的读操作必须在lfence指令后的读操作前完成。mfence:也就是mix fence,混合屏障指令,在mfence前的读写操作必须在mfence指令后的读写操作前完成。
在Linux系统中,将这三种指令分别封装成了, smp_wmb-写屏障 、 smp_rmb-读屏障 、 smp_mb-读写屏障 三个方法。
读屏障用于处理 invalidate queue(cpu执行读屏障时,会先把当前invalidate queue中的数据处理掉之后,再执行屏障后的“读取操作”),写屏障用于处理 store buffer(cpu执行写屏障时,会先把当前store buffer中的数据刷到cache之后,再执行屏障后的“写入操作”)。
总结
volatile 关键字的底层实现是 lock 前缀指令。 lock 前缀指令和内存屏障到底有什么关系呢?
我认为是没有什么关系的。
只不过 lock 前缀指令一部分功能能达到内存屏障的效果罢了。
这一点在《IA-32 架构软件开发人员手册》上也能找到对应的描述。
手册上给 lock 前缀指令的定义是总线锁,也就是 lock 前缀指令是通过锁住总线保证可见性和禁止指令重排序的。虽然“总线锁”的说法过于老旧了,现在的系统更多的是“锁缓存行”。但我想表达的是,lock 前缀指令的核心思想还是“锁”,这和内存屏障有着本质的区别。

关于JMM和Happens-Before的内容在下一篇:JMM以及happens-before原则
参考资料:
https://www.cnblogs.com/coderw/p/16380057.html