文章目录
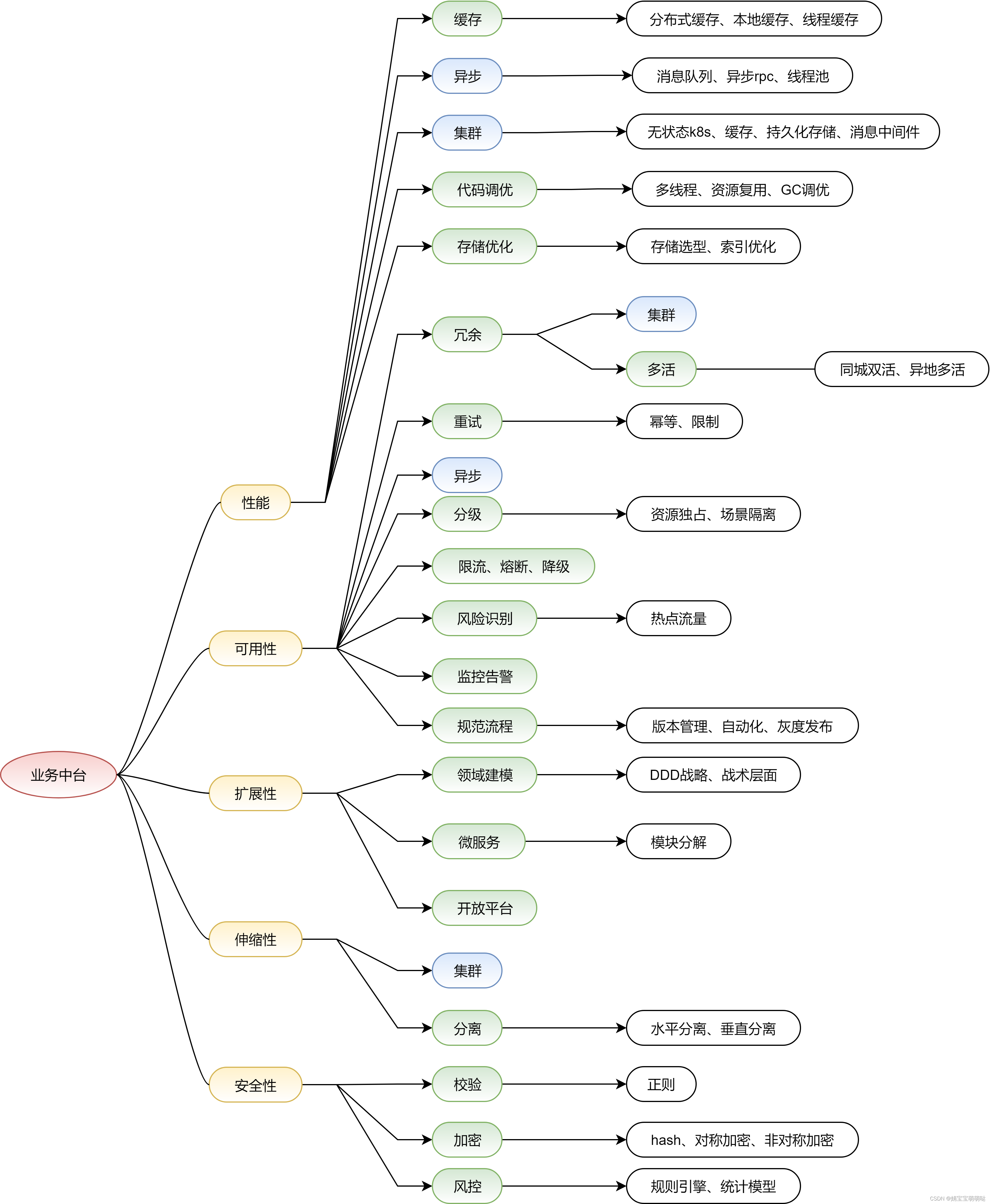
业务中台目标
- 目标:
- 整体目标:高内聚、低耦合,便于开发和维护。
- 五个方向:性能、可用性、扩展性、伸缩性、安全性。
- 原因:
- 实现方式:
- 战略上:
- 横向分层:分散关注、松散耦合。
- 应用层:提供具体业务的API和视图,和用户直接交互。
- 服务层:提供业务编排和业务原子能力。
- 数据层:提供存储服务,如数据库、缓存、搜索引擎、文件。
- 纵向分割:通常按照不同业务划分,专人做专事、不同等级保障。
- 分布式部署:包括服务应用、静态资源、数据存储、计算、配置、锁、文件的分布式。由于通常需要避免单点,需要在C和A之间权衡。
- 横向分层:分散关注、松散耦合。
- 战术上(几种方式可能组合使用):
- 集群。负载均衡和失效转移提供并发特效和可用性。
- 缓存。在数据热点不均匀、数据有一定有效期的情况下使用。
- 异步。堆积消息避开故障时刻提高可用性、减少rt、削峰。
- 冗余。包括集群备份、冷热备份、灾备数据中心。
- 自动化。发布过程、代码管理、安全监测、监控、失效转移恢复、降级、分配资源都可以自动化。
- 安全措施。密码、验证码、加密、过滤、风控等。
- …
- 战略上:
详细理论内容可参考:大型网站架构
具体案例
结合电商商品中台、交易中台、春晚红包的工作经历梳理使用场景
性能
缓存
- 分布式缓存。主流的redis的3种集群,是电商商品中心各种场景的缓存主力。
- 主从redis。client 路由。
- 一致性hash路由。商品主库上的缓存,用于商详等商品单查。已经成功支持过200+ redis实例,抗500w+ qps。
- 多副本路由。上一条的二级缓存,存放热点数据,防止单redis和主库单分片被打挂。50个 redis实例可抗100w+ qps。
- codis。proxy路由。用于C端列表大流量的批量查询,通常多集群部署。单集群256主从server+100proxy可抗近千万qps,并且可以通过节点的方式最多支持到3000w qps。、
- redis cluster。前两者的替代品,扩容更加方便。集群规模受限,建议最多200 server和2T内存,可以通过多集群分片的方式扩展集群的规模。
- 主从redis。client 路由。
- 本地缓存。主流Caffeine,用于列表场景大内存(56G)实例抗突发热点,保护分布式缓存。
- 线程缓存。ThreadLocal,用于aop带出上下文,如商品B端编辑在aop中校验商品状态,并把商品数据带到业务逻辑中修改,减少查库的次数。
异步
- 消息队列。
- 消息中间件。春晚红包抢红包实时链路db只记录中奖流水,后续发奖通过kafka异步。抢红包需要支持600w tps,下游发奖等无法支持,并且异步也可以减少用户等待时间能再次摇奖。
- 事件驱动。用户下单后的预约流程需要商家接单,接单等待时间较长。实现为用户申请落库后直接放回,后续通知商家流程通过可靠领域事件驱动,商家接单之后回调。
- rpc异步。商品列表聚合素材、标签等数据使用异步dubbo,并行调用减少列表渲染时间。
- 线程池。商品列表的缓存回写通过线程池异步,减少为命中缓存时用户请求等待的时间。
集群
- 服务层k8s实例的集群化。商品列表场景单机房上千实例可抗300w+ qps,并在10ms内返回。单机压力大会导致cpu飙升的长尾。
- 缓存的集群化。商品列表的缓存集群抗300w+ qps的批量查询流量,并保证rt在1ms左右。
- 持久化存储的集群化。
- mysql。
- 商品256库256表,可以支持百万qps的查询,日常流量下商详场景的redis雪崩,也可以基本支持业务。
- 春晚预热的全局预算累计拆分到32个库,可支持几十万的写入。
- hbase。商品列表缓存下的持久化存储,支持百万qps的查询。
- mysql。
代码优化
- 多线程。春晚红包下单回滚库存、限购等资源时并行回滚,减少用户等待时间。
- 资源复用。下单页对大ab参数的解析只做一次,后续都使用解析后的对象。解析大json有可能占用机器将近一半的cpu耗时。
- GC调优。
- 更换gc方式。商品敏感数据服务由于需要使用本地缓存,gc压力大,上游50ms经常超时。使用zgc,通过损失一定cpu获得1-2ms的gc时间,极大的降低了上游的超时率。
- 调整其他gc参数。
存储优化
- 存储选型。商品操作日志这种写多读少的场景,使用hbase这种追加式的存储,做到毫秒级写入。
- 索引调优。
- 添加索引减少每次扫描的数据行数,从而降低响应时间。
- 商品的sku包含删除和未删除的sku,热门商品修改频繁,删除的sku较多,导致每次可能需要查到上万sku,但实际生效的只有几十上百个。添加商品Id+SKU状态的索引解决这一问题。
- 添加查询条件引导优化器走扫描数据量少的索引。
- 添加索引减少每次扫描的数据行数,从而降低响应时间。
可用性
分布式场景判断是否可用的一般方式:超时
集群
- 服务层的无状态化k8s集群。可负载均衡+重试做到失效转移。
- dubbo调用支持配置retry属性,也可二次开发健康度lb,从而使得请求最终落到下游的正常实例上。
- 存储层的数据备份。可失效转移。
多活
- 同城双活,异地、跨云多活。
- 商品中心、交易中心等核心服务均部署两个以上的机房,同时提供服务,并且定期做切流量演练。
风险识别
- 热点流量。
- 业务识别。热点商品通过定时任务拉秒杀服务获取,并刷到多副本缓存中,用于商品详情页和下单,避免数据库被打崩。
- 系统识别。
- 商品列表使用caffeine本地缓存,通过tiny-lfu识别热点并缓存到本地,保护分布式缓存。
- 商品详情、下单服务使用改造之后的sentinel,发现db访问热点,并刷到多副本缓存。
分级
- 高优先级的服务占用更好的硬件资源,部署在不同的宿主机上,甚至异地容灾。
- 商品服务独立宿主机,和其他服务隔离,并做多机房部署和异地灾备。
- 高优先级的场景和其他场景隔离,避免被影响。
- 商品详情的缓存使用独立的redis集群,和其他缓存独立。
- 电商核心的盈利部门广告从单独的商品集群查询商品。
异步
- 方式同上一节中的mq,dubbo。
- 下单流程生成交易快照使用mq+异步dubbo双通道,不影响核心的下单链路。
限流
- 保证有效流量不超过自身的处理能力。分为集群限流和单机限流。几种限流算法。
- 集群限流。用存储如redis计数,适合流量小、精度高的场景,如1w qps左右。
- 单机限流。本地内存限流,适用于流量大精度不高的场景。
- 商品服务均使用单机限流 。dubbo在filter中用sentinel的滑动窗口,每个窗口默认0.5s。
熔断
- 抛弃下游请求。下单页服务对下游的所有依赖如果超过50%,会被mesh层熔断。
降级
- 强依赖降级:
- 无损降级。如读容灾存储。
- 交易支付流程如果查询账号服务失败,则从容灾的redis中获取账户信息。账号信息每次查询账号服务后更新,由于账户变更不频繁,读容灾存储基本等于无损降级。
- 有损降级。如异步补偿写。
- 交易下单流程中如果限购服务异常,可以降级成读历史订单后补偿扣限购,而不是同步扣限购。可能造成超卖。
- 无损降级。如读容灾存储。
- 弱依赖降级:可以失败
- 缩短超时时间。交易下单页对于历史留资等若依赖超时时间设置成200ms而不是框架默认的1s
- 支持丢弃请求。以上的留资服务可以手动降级,不去请求。
重试
- 需要注意:
- 下游保证幂等。
- 重试的错误类型。网络超时可以重试,业务异常需要具体问题具体分析,有些异常重试没有意义。
- 某分布式事务组件的思路是一阶段提交,二阶段无限重试,但是二阶段调下游的入参有问题被拦截,无限重试卡住。
- 重试次数限制。过多的重试会造成读或写扩散,打挂下游。
规范流程
- 版本管理。分布式服务场景下,分支开发、主干发布。
- 大多数互联网公司的做法,开发分支本地调试,测试分支发布到测试环境,主干分支发布到生产环境
- 测试分支可以建设泳道,减少需求之间的影响,但是也可能遗漏多个需求同时修改触发的bug
- 自动化发布、自动化测试。
- 整个公司使用发布平台发布,减少人工操作失误的概率。
- 预发布、灰度发布。
- 公司所有上线必须走预发验证,之后滚动发布。
监控告警
- 监控+告警人工介入。如cat可以监控应用并通过电话消息等多种方式触达开发人员,及时介入线上故障。
扩展性
领域建模
- 通过DDD战略层面拆分各个业务域
- 交易中台拆分成商品、营销、交易、履约、结算5个业务域,大多数需求可以闭环在各个业务域内。
- DDD战术层面搭建微服务。
- 使用六边形框架搭建微服务。
- 交易中台的服务使用DDD构建,切下游模型、接口变更时只需要对rpc适配层进行少量代码改动,无须修改领域层。
- 领域模型的通用性,必要时可分离为业务子域或者基础设施子域。
- 商品中心的商品扩展属性通过k-v形式存储,shema通过groovy脚本校验,可以做到不发版迭代业务。已经迭代过数十个需求。
- 商品详情装修组件也设计为通用的组件+schema+数据的形式,支持业务动态配置详情页。
- 商品消息通过配置化每个业务可以单独订阅感兴趣的组合,如只关心商品和SKU的消息。
- 通用的能力,如商品黑名单、商品店铺协议、商品操作日志、计数能力单独抽业务子域,其他业务可以复用。
- 使用六边形框架搭建微服务。
微服务
- 通过微服务分解业务模块。是DDD的技术实现。
- 微服务之间可以通过多种方式交互
- 同步的rpc、http调用。
- 异步的消息中间件、异步rpc。
- 微服务之间的交互协议也是可扩展的
- json, hessian,thrift等序列化方式
- hbase等nosql存储
扩展点
- 开放平台。注重对外部开发者的扩展性。
- 交易中台会定义一套三方下单的接口,并公开在开平文档中,saas根据供应商提供client_key路由到指定的url
- 中台扩展点。交易中台通过在编排层流程节点定义接口,业务侧实现接口的方式,将业务定制逻辑剥离。
伸缩性
分割
- 水平方向:按照业务处理流程分离,比如API层、编排层、原子能力层、中间件层、存储层。
- 交易中台的服务层无状态,可以快速扩容。有状态的存储层相对伸缩性较差。
- 垂直方向:
- 按照业务模块分离。
- 交易中台新建设预约能力,和正向、履约独立,不用再对现有流程进行修改。
- 商品中心的库存服务单独拆分,和商品数据动静分离。商品可以往大流量支持场景,使用缓存伸缩,库存往小流量写场景堆存储伸缩。
- 按照数据冷热程度分离。
- 商品库会hive表捞删除1年的商品,通过kafka推给业务删除商品库的相关数据并存储到hbase中,hbase提供只读能力。
- 按照业务模块分离。
集群
- 服务层的无状态化k8s集群。可扩容支持大促流量,负载均衡业务无感知。
- 双11等大促时,商品中台需要两倍以上的k8s实例做压测和保障,可扩容并依赖dubbo的负载均衡支持业务。
- 有状态的存储集群可以扩容,并通过2种方法识别到数据在哪个分片上。
- 元数据服务器。
- 商品中心使用hbase,依赖meta节点获取rowkey的分布,扩容无须业务感知。
- redis cluster的槽迁移,依赖槽的路有扩容同样无须业务感知
- 路由算法。商品中心客户端路由缓存使用一致性hash,扩容通过平台配置,业务无须修改代码
- 元数据服务器。
安全性
校验
- 字符串强校验。不拼接字符串作为sql入参
- 下单流程对手机号会进行正则校验,防止sql注入。
加密
- 单向hash加密(MD5、SHA),对称加密(DES、RC),非对称加密(RSA)等。
- 订单的用户信息属于用户隐私,需要通过AES加密之后存储在DB,防止泄漏。
风控
- 规则引擎+统计模型识别黑产。
- 交易中台下单前过风控拦截,下单后、支付前后通知风控分析用户行为。