一、问题的发生
当我们尝试用字节流处理读取文档时候
public static void main(String[] args) throws IOException {
FileInputStream fis=null;
try {
// File file = new File("d:/hello/1.png");
File file = new File("d:/hello/demo.txt");
fis = new FileInputStream(file);
byte[] b = new byte[5];
int len;
StringBuffer str = new StringBuffer();
while ((len = fis.read(b)) != -1) {
str.append(new String(b, 0, len));
}
System.out.println(str.toString());
} catch (IOException e) {
e.printStackTrace();
} finally {
if(fis!=null){
fis.close();
}
}
}运行结果是如下图左侧 读取的文本如下图右侧

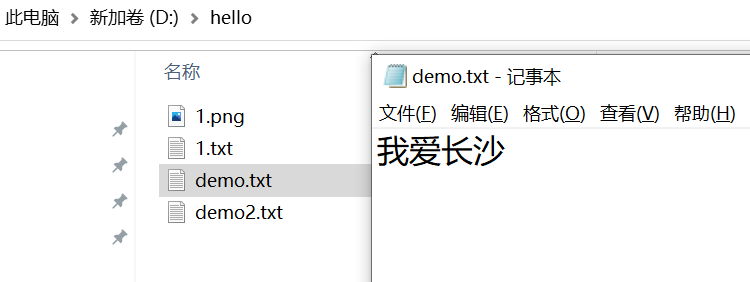
为啥结果是中文 "我" 和 "长 "没有乱码,其它位置上的乱码了?其实这个跟每次去读的byte数组大小有关
二、究其原因
上面的代码fis.read(b)每次读取5个字节,但在UTF-8编码格式下,每个汉字占3个字节(GBK下是2个),那么问题的发生就显而易见了,
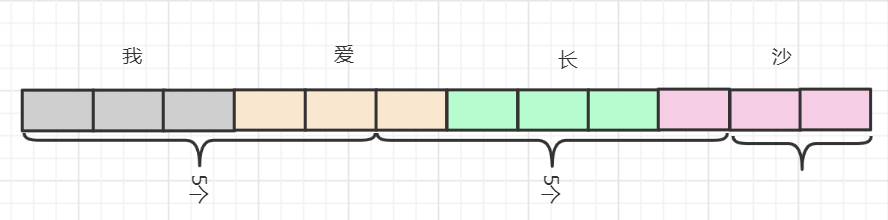
使用字节流读取UTF-8编码的数据乱码的原因分析:当采用UTF-8编码时,如果固定了每次转换的字节数,那么各种类型的字符混用时有很大可能造成乱码。比如每次读取2个字节。 如果存的是"AB",那么OK,不会乱码如果存的是"A文",那么每次读取2个字节,A-->可以读出来A,但是“文”没有读取完整,只读了一个字节的信息,还有2个字节的信息没有读取。所以“文”就会出现乱码
三、如何解决
方法一:如果一定要byte[]数组来存在读取的数据,且数据量较小。那么可以扩大数组的容量,让byte[]数组能够存储所有的字节,然后在转换成字符
// 已知。数据约小于5kb,那么可以把byte数组大小定义成5KB,
byte[] bytes = new byte[1024*5];把所有的数据全部读进去,然后转换成字符,那么不会出现乱码
方法二:使用IO流中的字符流来包装字节流,最便利的就是使用BufferedReader来实现
InputStream is = connection.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));