目录
2.2,avformat_alloc_output_context2()
2.6.2,avcodec_send_packet()/ avcodec_receive_frame()
2.6.5,av_write_trailer() 写文件尾,写入时长信息等
3.4、AVFilterGraph 、AVFilterContext、AVFilter
3.5.3、FFmpeg Filter Buffer 和 BufferSink 相关APi的使用方法整理
参考:
【FFMPEG中最关键的结构体之间的关系_雷霄骅的博客-CSDN博客_ffmpeg 结构体关系】
【音视频处理之FFmpeg+SDL视频播放器20180409 - yuweifeng - 博客园】
【[总结]FFMPEG视音频编解码零基础学习方法_雷霄骅的博客-CSDN博客_ffmpeg雷霄骅】
0,常用结构体之间的关系:
FFMPEG中结构体很多。最关键的结构体可以分成以下几类:
a) 解协议(http,rtsp,rtmp,mms)
AVIOContext,URLProtocol,URLContext主要存储视音频使用的协议的类型以及状态。URLProtocol存储输入视音频使用的封装格式。每种协议都对应一个URLProtocol结构。(注意:FFMPEG中文件也被当做一种协议“file”)
b) 解封装(flv,avi,rmvb,mp4)
AVFormatContext主要存储视音频封装格式中包含的信息;AVInputFormat存储输入视音频使用的封装格式。每种视音频封装格式都对应一个AVInputFormat 结构。
c) 解码(h264,mpeg2,aac,mp3)
每个AVStream存储一个视频/音频流的相关数据;每个AVStream对应一个AVCodecContext,存储该视频/音频流使用解码方式的相关数据;每个AVCodecContext中对应一个AVCodec,包含该视频/音频对应的解码器。每种解码器都对应一个AVCodec结构。
d) 存数据
视频的话,每个结构一般是存一帧;音频可能有好几帧
解码前数据:AVPacket
解码后数据:AVFrame
他们之间的对应关系如下所示: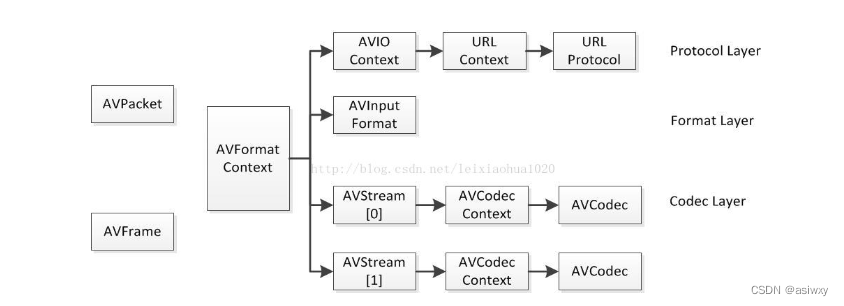
1,编解码
1.1, 编解码流程

1.2,编解码相关的结构体:

I、FFmpeg编解码相关数据结构简介
AVFormatContext
封装格式上下文结构体,也是统领全局的结构体,保存了视频文件封装格式相关信息。
AVInputFormat
每种封装格式(例如FLV, MKV, MP4, AVI)对应一个该结构体。
AVStream
视频文件中每个视频(音频)流对应一个该结构体。
AVCodecContext
编码器上下文结构体,保存了视频(音频)编解码相关信息。
AVCodec
每种视频(音频)编解码器(例如H.264解码器)对应一个该结构体。
AVPacket
存储一帧压缩编码数据。
AVFrame
存储一帧解码后像素(采样)数据。
II、FFmpeg编解码相关数据结构分析
AVFormatContext
struct AVInputFormat *iformat:输入视频的AVInputFormat
struct AVOutputFormat *oformat::输出视频的AVOutputFormat
nb_streams :输入视频的AVStream 个数
streams :输入视频的AVStream []数组
duration :输入视频的时长(以微秒为单位)
bit_rate :输入视频的码率
AVInputFormat
name:封装格式名称
long_name:封装格式的长名称
extensions:封装格式的扩展名
id:封装格式ID
一些封装格式处理的接口函数
AVOutputFormat
与AVInputFormat类似,是类似COM 接口的数据结构,表示输出文件容器格式,着重于功能函数,位于Avoformat.h文件中。
ffmpeg支持各种各样的输出文件格式,MP4,FLV,3GP等等。而 AVOutputFormat 结构体则保存了这些格式的信息和一些常规设置。
每一种封装对应一个 AVOutputFormat 结构,ffmpeg将AVOutputFormat 按照链表存储:

const char *name;
const char *long_name;//格式的描述性名称,易于阅读。
enum AVCodecID audio_codec; //默认的音频编解码器
enum AVCodecID video_codec; //默认的视频编解码器
enum AVCodecID subtitle_codec; //默认的字幕编解码器
struct AVOutputFormat *next;
int (*write_header)(struct AVFormatContext *);
int (*write_packet)(struct AVFormatContext *, AVPacket *pkt);//写一个数据包。 如果在标志中设置AVFMT_ALLOW_FLUSH,则pkt可以为NULL。
int (*write_trailer)(struct AVFormatContext *);
int (*interleave_packet)(struct AVFormatContext *, AVPacket *out, AVPacket *in, int flush);
int (*control_message)(struct AVFormatContext *s, int type, void *data, size_t data_size);//允许从应用程序向设备发送消息。
int (*write_uncoded_frame)(struct AVFormatContext *, int stream_index, AVFrame **frame, unsigned flags);//写一个未编码的AVFrame。
int (*init)(struct AVFormatContext *);//初始化格式。 可以在此处分配数据,并设置在发送数据包之前需要设置的任何AVFormatContext或AVStream参数。
void (*deinit)(struct AVFormatContext *);//取消初始化格式。
int (*check_bitstream)(struct AVFormatContext *, const AVPacket *pkt);//设置任何必要的比特流过滤,并提取全局头部所需的任何额外数据AVIOContext
unsigned char *buffer:缓存开始位置
int buffer_size:缓存大小(默认32768)
unsigned char *buf_ptr:当前指针读取到的位置
unsigned char *buf_end:缓存结束的位置
void *opaque:URLContext结构体
在解码的情况下,buffer用于存储ffmpeg读入的数据。例如打开一个视频文件的时候,先把数据从硬盘读入buffer,然后在送给解码器用于解码。
其中opaque指向了URLContext。
AVStream
id:序号
codec:该流对应的AVCodecContext
time_base:该流的时基
r_frame_rate:该流的帧率
AVCodecContext
codec:编解码器的AVCodec
width, height:图像的宽高(只针对视频)
pix_fmt:像素格式(只针对视频)
sample_rate:采样率(只针对音频)
channels:声道数(只针对音频)
sample_fmt:采样格式(只针对音频)
AVCodec
name:编解码器名称
long_name:编解码器长名称
type:编解码器类型
id:编解码器ID
一些编解码的接口函数
AVPacket
pts:显示时间戳
dts :解码时间戳
data :压缩编码数据
size :压缩编码数据大小
stream_index :所属的AVStream
AVFrame
data:解码后的图像像素数据(音频采样数据)。
linesize:对视频来说是图像中一行像素的大小;对音频来说是整个音频帧的大小。
width, height:图像的宽高(只针对视频)。
key_frame:是否为关键帧(只针对视频) 。
pict_type:帧类型(只针对视频) 。例如I,P,B。
III、注意事项
裸流文件,即如h264文件,是没有时长等信息的,封装格式的才有
数据结构第一层为封装格式相关的,下面层为编解码相关的
其中,AVStream中的time_base 表示该流的时基,也就是时间的基数,简单可理解为时间的单位,比如时间数是2,时基是1s,则时间为2s
AVPacket:
可以理解为h264中的数据包,编码后的包
其中,pts:显示时间戳,表示该视频帧几分几秒的时候放到屏幕上。这个值只是一个整数 没有单位,所以要得到具体的几分几秒需要和前面的time_base时基参数相乘得到。
dts:解码时间戳
stream_index:标识,表示该流属于音频流还是视频流。
data:压缩编码的数据,如h264的编码,就可以取出该数据保存起来形成的文件就是h264文件。
通过av_read_frame可从大的数据结构指针中读取到AVPacket数据
注意播放的顺序不一定按照存储的顺序来。即有一个显示的顺序和一个解码的顺序。
AVFrame
data:解码后的图像像素数据,如YUV等,可形成yuv文件(依次存储的是y、u、v分量,其中u 宽和高都只有y一半,整个数据量就y的四分之一,v的也一样)。data是一个指针数组,其中一个分量对应一个数组
数据先通过解码函数avcodec_decode_video2进行解码,然后由于解码出来的数据由于是有黑边(多出一块多余的数据),所以还需用sws_scale函数把这块多余的裁了。
4).解码后的数据要经过sws_scale()函数处理
解码后YUV格式的视频像素数据保存在AVFrame的data[0]、data[1]、data[2]中。但是这些像素值并不是连续存储的,每行有效像素之后存储了一些无效像素。
以亮度Y数据为例,data[0]中一共包含了linesize[0]*height个数据。但是出于优化等方面的考虑,linesize[0]实际上并不等于宽度width,而是一个比宽度大一些的值。
因此需要使用sws_scale()进行转换。转换后去除了无效数据,width和linesize[0] 取值相等。如下图3:

其中,sws_scale()函数需要用到的转换信息,即第一个参数,是由sws_getContext函数获得的
转换后保存在一个新的帧数据结构体,由于使用的转换函数而不是解码函数,所以这个结构体还需要填充其内部的缓冲区,用于存储像素数据,填充的方法使用avpicture_fill函数:
int avpicture_fill(AVPicture *picture, uint8_t *ptr,int pix_fmt, int width, int height);
这个函数的使用本质上是为已经分配的空间的结构体(AVPicture *)ptFrame挂上一段用于保存数据的空间,
这个结构体中有一个指针数组data[AV_NUM_DATA_POINTERS],挂在这个数组里。一般我们这么使用:
I、pFrameRGB=avcodec_alloc_frame();
II、numBytes=avpicture_get_size(PIX_FMT_RGB24, pCodecCtx->width,pCodecCtx->height);
buffer=(uint8_t *)av_malloc(numBytes*sizeof(uint8_t));
III、avpicture_fill((AVPicture *)pFrameRGB, buffer, PIX_FMT_RGB24,pCodecCtx->width, pCodecCtx->height);以上就是为pFrameRGB挂上buffer。这个buffer是用于存缓冲数据的。
ptFrame为什么不用fill空间。主要是下面这句:
avcodec_decode_video(pCodecCtx, pFrame, &frameFinished,packet.data, packet.size);
很可能是ptFrame已经挂上了packet.data,所以就不用fill了。
2,编解码相关的函数:
2.1,av_guess_format
AVOutputFormat *av_guess_format(const char *short_name,
const char *filename,
const char *mime_type);参数:
short_name:格式的名称。
filename:文件的名称。
mime_type:MIME类型。
返回最匹配的AVOutputFormat。如果没有很匹配的AVOutputFormat,则返回NULL。
2.2,avformat_alloc_output_context2()
int avformat_alloc_output_context2(AVFormatContext **ctx,
AVOutputFormat *oformat,
const char *format_name,
const char *filename);
参数:
ctx:函数调用成功之后创建的AVFormatContext结构体。
oformat:指定AVFormatContext中的AVOutputFormat,用于确定输出格式。如果指定为NULL,可以设定后两个参数(format_name或者filename)由FFmpeg猜测输出格式。
PS:使用该参数需要自己手动获取AVOutputFormat,相对于使用后两个参数来说要麻烦一些。
format_name:指定输出格式的名称。根据格式名称,FFmpeg会推测输出格式。输出格式可以是“flv”,“mkv”等等。
filename:指定输出文件的名称。根据文件名称,FFmpeg会推测输出格式。文件名称可以是“xx.flv”,“yy.mkv”等等。
函数执行成功的话,其返回值大于等于0。
2.3,avformat_new_stream
avformat_new_stream 在 AVFormatContext 中创建 Stream 通道。
AVFormatContext :
unsigned int nb_streams; 记录stream通道数目。
AVStream **streams; 存储stream通道。
AVStream :
int index; 在AVFormatContext 中所处的通道索引,4,
2.4,avcodec_open2()
int avcodec_open2(AVCodecContext *avctx, const AVCodec *codec, AVDictionary **options);
该函数用于初始化一个视音频编解码器的AVCodecContext。
avctx:需要初始化的AVCodecContext。
codec:输入的AVCodec
options:一些选项。例如使用libx264编码的时候,“preset”,“tune”等都可以通过该参数设置。avcodec_open2()中最关键的一步就是调用AVCodec的init()方法初始化具体的编码器。AVCodec的init()是一个函数指针,指向具体编解码器中的初始化函数,这里可以设置编码器的扫描方式。
【具体的可以看看雷神的这篇文章,写的很详细:FFmpeg源代码简单分析:avcodec_open2()_雷霄骅的博客-CSDN博客】
2.5,avcodec_find_encoder()
里面调用了函数find_codec(),find_codec()函数既可以用来查找编码器,也可以用来查找解码器。find_codec()中有一个循环,该循环会遍历AVCodec结构的链表,逐一比较输入的ID和每一个编码器或者解码器的ID,直到找到ID取值相等的编码器或者解码器。
在这里有几点需要注意:
(1)av_codec_iterate是一个遍历器,遍历变量codec_list,存储AVCodec的数组。av_codec_iterate的定义见下面。
(2)remap_deprecated_codec_id()用于将一些过时的编码器ID映射到新的编码器ID。
(3)函数的第二个参数x,就是avcodec_find_encoder调用find_codec传递过来的函数av_codec_is_encoder。如果是avcodec_find_decoder调用find_codec传递过来的函数就是av_codec_is_decoder。即find_codec()函数既可以用来查找编码器,也可以用来查找解码器。编码器和解码器都存在变量codec_list中。把满足要求的AVCodec的ID值与传入的ID值进行比较,如果相等,就是我们要找的解码器或者编码器。
【参考:ffmpeg源码分析:avcodec_find_encoder()和avcodec_find_decoder()_风雨兼程8023的博客-CSDN博客_avcodec_find_encoder 】
2.6,关于编码的函数们:
首先编码的大致流程如下:
(1)avformat_alloc_output_context2()
(2)avfomat_write_header()
(3)avcodec_send_frame()/avcodec_receive_packet()
(4)av_write_frame()
(5)av_write_trailer()
avformat_write_header(),av_write_frame()以及av_write_trailer()这三个函数一般是配套使用,其中av_write_frame()用于写视频数据,avformat_write_header()用于写视频文件头,而av_write_trailer()用于写视频文件尾。【以下几个函数参考:avformat_write_header()_FFmpeg从入门到入门的博客-CSDN博客_avformat_write_headerFFmpeg源代码简单分析:avformat_write_header()_雷霄骅的博客-CSDN博客_avformat_write_headeravformat_write_header()_FFmpeg从入门到入门的博客-CSDN博客_avformat_write_header】
2.6.1,avformat_write_header()
int avformat_write_header(AVFormatContext *s, AVDictionary **options);
参数:
s:用于输出的AVFormatContext。
options:额外的选项,一般为NULL。
函数正常执行后返回值等于0。从源代码可以看出,avformat_write_header()完成了以下工作:
(1)调用init_muxer()初始化复用器
(2)调用AVOutputFormat的write_header()
下面来看init_muxer和write_header这两个函数:
init_muxer的代码很长,就不粘贴上来了,函数主要做了以下:
(1)将传入的AVDictionary形式的选项设置到AVFormatContext
(2)遍历AVFormatContext中的每个AVStream,并作如下检查:
a) AVStream的time_base是否正确设置。如果发现AVStream的time_base没有设置,则会调用avpriv_set_pts_info()进行设置。
b) 对于音频,检查采样率设置是否正确;对于视频,检查宽、高、宽高比。
c) 其他一些检查,不再详述。write_header()是AVOutputFormat中的一个函数指针,指向写文件头的函数。不同的AVOutputFormat有不同的write_header()的实现方法。
在这里我们举例子看一下FLV封装格式对应的AVOutputFormat,它的定义位于libavformat\flvenc.c,如下所示。
AVOutputFormat ff_flv_muxer = { .name = "flv", .long_name = NULL_IF_CONFIG_SMALL("FLV (Flash Video)"), .mime_type = "video/x-flv", .extensions = "flv", .priv_data_size = sizeof(FLVContext), .audio_codec = CONFIG_LIBMP3LAME ? AV_CODEC_ID_MP3 : AV_CODEC_ID_ADPCM_SWF, .video_codec = AV_CODEC_ID_FLV1, .write_header = flv_write_header, .write_packet = flv_write_packet, .write_trailer = flv_write_trailer, .codec_tag = (const AVCodecTag* const []) { flv_video_codec_ids, flv_audio_codec_ids, 0 }, .flags = AVFMT_GLOBALHEADER | AVFMT_VARIABLE_FPS | AVFMT_TS_NONSTRICT, };.write_header = flv_write_header, 表明调用flv的write_header会最终调用到flv_write_header函数。每种不同的格式都会对应到各自的实现方法中去。
从源代码可以看出,flv_write_header()完成了FLV文件头的写入工作。该函数的工作可以大体分为以下两部分:
(1)给FLVContext设置参数
写文件头的代码很短,如下所示。
(2)写文件头,以及相关的Tagavio_write(pb, "FLV", 3); avio_w8(pb, 1); avio_w8(pb, FLV_HEADER_FLAG_HASAUDIO * !!flv->audio_enc + FLV_HEADER_FLAG_HASVIDEO * !!flv->video_enc); avio_wb32(pb, 9);可以参考下图中FLV文件头的定义比对一下上面的代码。

2.6.2,avcodec_send_packet()/ avcodec_receive_frame()
ffmpeg中解码的API之前的是avcodec_decode_video2()和avcodec_decode_audio4(),现在使用avcodec_send_packet()/ avcodec_receive_frame()来代替原有的接口。
API与编码/解码和音频/视频非常相似,工作原理如下:
1、像往常一样设置和打开AVCodecContext。
2、输入:1)、对于解码,请调用avcodec_send_packet()以在AVPacket中给出解码器原始的压缩数据。
2)、对于编码,请调用avcodec_send_frame()为编码器提供包含未压缩音频或视频的AVFrame。 在这两种情况下,建议对AVPackets和AVFrames进行重新计数,否则libavcodec可能必须复制输入数据。 (libavformat总是返回引用计数的AVPackets,av_frame_get_buffer()分配引用计数的AVFrames)
3、在循环中接收输出。 定期调用avcodec_receive _ *()函数并处理其输出:1)、对于解码,请调用avcodec_receive_frame()。 成功后,它将返回一个包含未压缩音频或视频数据的 AVFrame。
2)、对于编码,请调用avcodec_receive_packet()。 一旦成功,它将返回带有压缩帧的AVPacket。 重复调用,直到它返回AVERROR(EAGAIN)或错误。 AVERROR(EAGAIN)返回值意味着需要新的输入数据才能返回新的输出。
【以下流程看不懂,重新找了一篇文章,在下面】
在解码或编码开始时,编解码器可能会接收多个输入帧/数据包而不返回帧,直到其内部缓冲区被填充为止。
结束流情况。 这些需要“刷新”编解码器,因为编解码器可能在内部缓冲多个帧或数据包以实现性能或不必要(考虑B帧)。
pkt==NULL is treated differently from pkt.size==0 (pkt==NULL means get more output, pkt.size==0 is a flush/drain packet) 处理如下:
1、发送NULL到avcodec_send_packet()(解码)或avcodec_send_frame()(编码)函数,而不是有效的输入。 这将进入“flush”模式。2、在循环中调用avcodec_receive_frame()(解码)或avcodec_receive_packet()(编码),直到返回AVERROR_EOF。
3、在再次解码之前,必须使用avcodec_flush_buffers()重新编码。
不是很懂上面的刷新流程,重新找了一个参考:
FFmpeg提供了两组函数,分别⽤于编码和解码:
(1)解码:avcodec_send_packet()、avcodec_receive_frame()。
(2)编码:avcodec_send_frame()、avcodec_receive_packet()。
建议的使⽤流程如下:
(1)设置并打开编解码器上下文AVCodecContext。
(2)输⼊有效的数据:
解码:调⽤avcodec_send_packet()给解码器传⼊包含原始的压缩数据的AVPacket对象。
编码:调⽤ avcodec_send_frame()给编码器传⼊包含解压数据的AVFrame对象。
两种情况下推荐AVPacket和AVFrame都使⽤refcounted(引⽤计数)的模式,这样效率高,否则libavcodec可能不得不对输⼊的数据进⾏拷⻉。
(3)在⼀个循环体内去接收codec的输出,即周期性地调⽤avcodec_receive_*()来接收codec输出的数据。
解码:调⽤avcodec_receive_frame(),如果成功会返回⼀个包含未压缩数据的AVFrame。
编码:调⽤avcodec_receive_packet(),如果成功会返回⼀个包含压缩数据的AVPacket。
注意,这都是完整的包。
反复地调⽤avcodec_receive_packet()直到返回 AVERROR(EAGAIN)或其他错误。返回AVERROR(EAGAIN)错误表示codec需要新的输⼊来输出更多的数据。
对于每个输⼊的packet或frame,codec⼀般会输出⼀个frame或packet,但是也有可能输出0个或者多于1个,多个的情况也不少。
(4)注意:流处理结束的时候需要flush(冲刷) codec。因为codec可能在内部缓冲多个frame或packet,出于性能或其他必要的情况(如考虑B帧的情况)。 处理流程如下:
调⽤avcodec_send_*()传⼊的AVFrame或AVPacket指针设置为NULL。 这将进⼊draining mode(排⽔模式)。实时流应该不存在这些情况,除非输入流结束。
反复地调⽤avcodec_receive_*()直到返回AVERROR_EOF,该⽅法在draining mode时不会返回AVERROR(EAGAIN)的错误,除⾮你没有进⼊draining mode。
当重新开启codec时,需要先调⽤ avcodec_flush_buffers()来重置codec。
(5)编码或者解码刚开始的时候,codec可能接收了多个输⼊的frame或packet后还没有输出数据,直到内部的buffer被填充满。上⾯的使⽤流程可以处理这种情况。
(6)理论上,只有在输出数据没有被完全接收的情况调⽤avcodec_send_*()的时候才可能会发⽣AVERROR(EAGAIN)的错误。你可以依赖这个机制来实现区别于上⾯建议流程的处理⽅式,⽐如每次循环都调⽤avcodec_send_*(),在出现AVERROR(EAGAIN)错误的时候再去调⽤avcodec_receive_*()。
(7)并不是所有的codec都遵循⼀个严格、可预测的数据处理流程,唯⼀可以保证的是 “调⽤avcodec_send_*()/avcodec_receive_*()返回AVERROR(EAGAIN)的时候去avcodec_receive_*()/avcodec_send_*()会成功,否则不应该返回AVERROR(EAGAIN)的错误。”⼀般来说,任何codec都不允许⽆限制地缓存输⼊或者输出。
(8)在同⼀个AVCodecContext上混合使⽤新旧API是不允许的,这将导致未定义的⾏为。
4.avcodec_send_packet
函数:int avcodec_send_packet(AVCodecContext *avctx, const AVPacket *avpkt);
作⽤:⽀持将裸流数据包送给解码器
注意:
(1)输⼊的avpkt-data缓冲区必须⼤于AV_INPUT_PADDING_SIZE,因为优化的字节流读取器必须⼀次读取32或者64⽐特的数据。
(2)不能跟之前的API(例如avcodec_decode_video2)混⽤,否则会返回不可预知的错误。
(3)在将包发送给解码器的时候,AVCodecContext必须已经通过avcodec_open2打开
参数:
avctx:解码上下⽂
avpkt:输⼊AVPakcet.通常情况下,输⼊数据是⼀个单⼀的视频帧或者⼏个完整的⾳频帧。调⽤者保留包的原有属性,解码器不会修改包的内容。解码器可能创建对包的引⽤。如果包没有引⽤计数将拷⻉⼀份。跟以往的API不⼀样,输⼊的包的数据将被完全地消耗,如果包含有多个帧,要求多次调⽤avcodec_recvive_frame,直到avcodec_recvive_frame返回VERROR(EAGAIN)或AVERROR_EOF。输⼊参数可以为NULL,或者AVPacket的data域设置为NULL或者size域设置为0,表示将刷新所有的包,意味着数据流已经结束了。第⼀次发送刷新会总会成功,第⼆次发送刷新包是没有必要的,并且返回AVERROR_EOF,如果×××缓存了⼀些帧,返回⼀个刷新包,将会返回所有的解码包。
返回值:
0: 表示成功
AVERROR(EAGAIN):当前状态不接受输⼊,⽤户必须先使⽤avcodec_receive_frame() 读取数据帧;
AVERROR_EOF:解码器已刷新,不能再向其发送新包;
AVERROR(EINVAL):没有打开解码器,或者这是⼀个编码器,或者要求刷新;
AVERRO(ENOMEN):⽆法将数据包添加到内部队列。
5.avcodec_receive_frame
函数:int avcodec_receive_frame ( AVCodecContext * avctx, AVFrame * frame )
作⽤:从解码器返回已解码的输出数据。
参数:
avctx: 编解码器上下⽂
frame: 获取使⽤reference-counted机制的audio或者video帧(取决于解码器类型)。请
注意,在执⾏其他操作之前,函数内部将始终先调⽤av_frame_unref(frame)。
返回值:
0: 成功,返回⼀个帧
AVERROR(EAGAIN): 该状态下没有帧输出,需要使⽤avcodec_send_packet发送新的packet到解码器。
AVERROR_EOF: 解码器已经被完全刷新,不再有输出帧
AVERROR(EINVAL): 编解码器没打开
【参考:音频解码器有几种(主流大屏设备音频解码)-天道酬勤-花开半夏】
【注意:如果需要修改幅面的话,需要在解码成yuv或者rgb数据之后,进行幅面转换,然后再将缩放后的buffer送给编码器编码】
贴个代码,看的清晰:
nRet = 1; m_stPacket.data = NULL; m_stPacket.size = 0; nRet = avcodec_send_packet(m_pLongGOPCodecCtx, &m_stPacket); while (nRet >= 0) { nRet = avcodec_receive_frame(m_pLongGOPCodecCtx, m_pFrame); if (nRet >= 0) { nRet = CallBackDecodedBuffer(m_pFrame); if (nRet < 0) { return -107; } } }

avcodec_send_frame的翻译:
向编码器提供原始视频或音频帧。使用 avcodec_receive_packet() 检索缓冲的输出数据包。
@param avctx 编解码器上下文
@param[in] frame AVFrame 包含要编码的原始音频或视频帧。帧的所有权仍然属于调用者,编码器不会写入帧。编码器可以创建对帧数据的引用(如果帧没有被引用计数,则复制它)。它可以为 NULL,在这种情况下,它被认为是一个刷新数据包。这表示流的结束。如果编码器仍有缓冲的数据包,它将在此调用后返回它们。一旦进入刷新模式,额外的刷新数据包将被忽略,发送帧将返回 AVERROR_EOF。
对于音频:
如果设置了 AV_CODEC_CAP_VARIABLE_FRAME_SIZE,那么每帧可以有任意数量的样本。如果未设置,frame->nb_samples 必须等于 avctx->frame_size 用于除最后一帧之外的所有帧。最终帧可能小于 avctx->frame_size。
@return 0 成功,否则为负错误代码:
AVERROR(EAGAIN):在当前状态下不接受输入 - 用户必须使用 avcodec_receive_packet() 读取输出(一旦读取所有输出,应重新发送数据包,并且调用不会因 EAGAIN 而失败)。
AVERROR_EOF:编码器已被刷新,无法向其发送新帧
AVERROR(EINVAL):编解码器未打开,它是一个解码器,或者需要刷新
AVERROR(ENOMEM):未能将数据包添加到内部队列,或类似的其他错误:合法编码错误
avcodec_receive_packet翻译:
* 从编码器读取编码数据。
*
* @param avctx 编解码器上下文
* @param avpkt 这将被设置为编码器分配的引用计数数据包。 请注意,该函数将始终在执行任何其他操作之前调用 av_packet_unref(avpkt)。
* @return 0 成功,否则为负错误代码:
* AVERROR(EAGAIN):输出在当前状态下不可用 - 用户必须尝试发送输入
* AVERROR_EOF:编码器已被完全刷新,不会再有输出包
* AVERROR(EINVAL):编解码器未打开,或者是解码器其他错误:合法编码错误
2.6.3 av_read_frame
av_read_frame()的作用就是获取视频的数据。
注:av_read_frame()获取视频的一帧,不存在半帧说法。但可以获取音频的若干帧。
说明①:av_read_frame()函数是ffmpeg新型的用法,就用法之所以被抛弃,就是因为以前获取的数据可能不是完整的,而av_read_frame()保证了视频数据一帧的完整性。
2.6.4,int av_write_frame
int av_write_frame(AVFormatContext *s, AVPacket *pkt);用于输出一帧视音频数据。
参数:
s:用于输出的AVFormatContext。
pkt:等待输出的AVPacket。
函数正常执行后返回值等于0。av_write_frame()主要完成了以下几步工作:
(1)调用check_packet()做一些简单的检测
(2)调用compute_pkt_fields2()设置AVPacket的一些属性值
(3)调用write_packet()写入数据
2.6.5,av_write_trailer() 写文件尾,写入时长信息等
av_write_trailer()主要完成了以下两步工作:
(1)循环调用interleave_packet()以及write_packet(),将还未输出的AVPacket输出出来。
(2)调用AVOutputFormat的write_trailer(),输出文件尾。
2.6.6,avio_open2()
该函数用于打开FFmpeg的输入输出文件
int avio_open2(AVIOContext **s, const char *url, int flags,
const AVIOInterruptCB *int_cb, AVDictionary **options);avio_open2()函数参数的含义如下:
s:函数调用成功之后创建的AVIOContext结构体。
url:输入输出协议的地址(文件也是一种“广义”的协议,对于文件来说就是文件的路径)。
flags:打开地址的方式。可以选择只读,只写,或者读写。取值如下。
AVIO_FLAG_READ:只读。
AVIO_FLAG_WRITE:只写。
AVIO_FLAG_READ_WRITE:读写。
int_cb:目前还没有用过。
options:目前还没有用过。
3,filter相关结构体介绍
3.1,filter结构体关系介绍
【参考:FFmpeg-4.0 的filter机制的架构与实现.之二 结构体关系与定义_北雨南萍的博客-CSDN博客】
filter涉及的结构体,主要包括:
> FilterGraph, AVFilterGraph
> InputFilter, InputStream, OutputFilter, OutputStream
> AVFilter, AVFilterContext
> AVFilterLink
> AVFilterPad;
结构体之间的关系如下,我们在看的时候,需要横向将图分为三层。

从上图可以看到,FFmpeg的滤镜相关的结构体三层组成:
1) filtergraph层
由结构体 FilterGraph, AVFilterGraph组成;
其中,
FilterGraph, 包含一个InputFilter, 它指示了整个Graph的第一个滤镜,并指示了InputStream, 从而作为整个Graph的输入;
包含一个OutputFilter, 它指示了整个Graph的最后一个滤镜,并指示了OutputStream,从而作为整个Graph的输出;
包含一个AVFilterGraph的实例,它指示的是组成本graph的filter;
2) filterchain层
它由AVFilter, AVFilterContext, AVFilterLink, AVFilterPad组成;
其中,AVFilterContext是AVFilter的实例;
而filter之间是用 AVFilterLink进行连接,意思是,滤镜之间并不是直接相连的,是通过AVFilterLink进行连接;
AVFilterContext 通过AVFilterLink进行连接后,就组成了Filterchain。
而AVFilterContext与AVFilterLink之间的AVFilterPad是直接相连的,对应的关系是
AVFilterContext的output_pad 连接它下游AVFilterLink的 input_pad ;
AVFilterContext的input_pad 连接它上游AVFilterLink的 output_pad ;
3) filter层
由AVFilterContext, AVFilterPad组成;
其中AVFilterContext是真正进行数据处理的滤镜实体;
AVFilterPad用于AVFilterContext之间的callback(回调):
第一个AVFilterContext的outputs[0]指针,指向第一个AVFilterLink,这个AVFilterLink的dst指针,指向第二个AVFilterContext。
如果在前一个AVFilterContext调用
outputs[0]->dstpad->filter_frame(Frame* input_frame1),
那其实就意味着,第一个过滤器,可以把处理好的一个frame(名字为input_frame1),可以通过这个调用,传递给第二个过滤器的input_pads的filter_frame函数。
而第二个过滤器,里面就是用户自己实现的filter_frame(),以对数据进行处理;
以 ./ffmpeg_g -i INPUT.mp4 -vn -acodec libfdk_aac -filter_complex "aresample=osf=s16,denoise" -ar 16000 -ac 1 -y OUTPUT.mp4 为例:
它们的实际数据流程如下图所示(看完结构体简介之后,可以用这个图来验证一下学的咋样):

3.2,filter结构体的中文理解
首先,要理解filter相关结构体的中文翻译是什么?避免为避免英译中过程中一些死板的字面意思引起读者错误理解。
这篇文章给出了我个人认为比较好理解的翻译:
本文档将描述由
libavfilter库提供的过滤器(filters),源(sources),接收器(sinks)。关于将Filter翻译为过滤器还是滤波器一直没定论,同时sink也没有比较贴切的中文名词可以放在本语境中。为避免中文翻译之后产生歧义且便于音视频开发者阅读,后续文章中提及上面三个对象以及类似
input pad这种不好直接翻译的名词时均用英文表示。FFmpeg中的Filter相关功能是由库
libavfilter提供的。一个Filter可以有N个输入和N个输出(N ≥ 0)。Filtergraph是链接多个Filter的有向图。
它可以包含循环,各个Filter之间也可以有多个链接。每个链接有一个
input pad连接到一个Filter并从那里获取输入,有一个output pad连接到另一个Filter提供输出。所有的Filter都是已经注册在程序中的。没有输入的Filter叫source,没有输出的Filter叫sink。
3.3 filter相关函数的介绍以及调用流程
【参考:FFmpeg 开发之 AVFilter 使用流程总结 - 灰色飘零 - 博客园】
3.4、AVFilterGraph 、AVFilterContext、AVFilter
在 FFmpeg 中有多种多样的滤镜,你可以把他们当成一个个小工具,专门用于处理视频和音频数据,以便实现一定的目的。如 overlay 这个滤镜,可以将一个图画覆盖到另一个图画上;transport 这个滤镜可以将图画做旋转等等。
一个 filter 的输出可以作为另一个 filter 的输入,因此多个 filter 可以组织成为一个网状的 filter graph,从而实现更加复杂或者综合的任务。
在 libavfilter 中,我们用类型 AVFilter 来表示一个 filter,每一个 filter 都是经过注册的,其特性是相对固定的。而 AVFilterContext 则表示一个真正的 filter 实例,这和 AVCodec 以及 AVCodecContext 的关系是类似的。
AVFilter 中最重要的特征就是其所需的输入和输出。
AVFilterContext 表示一个 AVFilter 的实例,我们在实际使用 filter 时,就是使用这个结构体。AVFilterContext 在被使用前,它必须是 被初始化的,就是需要对 filter 进行一些选项上的设置,通过初始化告诉 FFmpeg 我们已经做了相关的配置。
AVFilterGraph 表示一个 filter graph,当然它也包含了 filter chain的概念。graph 包含了诸多 filter context 实例,并负责它们之间的 link,graph 会负责创建,保存,释放 这些相关的 filter context 和 link,一般不需要用户进行管理。除此之外,它还有线程特性和最大线程数量的字段,和filter context类似。graph 的操作有:分配一个graph,往graph中添加一个filter context,添加一个 filter graph,对 filter 进行 link 操作,检查内部的link和format是否有效,释放graph等。
3.5、AVFilter 相关Api使用方法整理
3.5.1. AVFilterContext 初始化方法
AVFilterContext 的初始化方式有三种,avfilter_init_str() 和 avfilter_init_dict()、avfilter_graph_create_filter().
/*
使用提供的参数初始化 filter。
参数args:表示用于初始化 filter 的 options。该字符串必须使用 ":" 来分割各个键值对, 而键值对的形式为 'key=value'。如果不需要设置选项,args为空。
除了这种方式设置选项之外,还可以利用 AVOptions API 直接对 filter 设置选项。
返回值:成功返回0,失败返回一个负的错误值
*/
int avfilter_init_str(AVFilterContext *ctx, const char *args);/*
使用提供的参数初始化filter。
参数 options:以 dict 形式提供的 options。
返回值:成功返回0,失败返回一个负的错误值
注意:这个函数和 avfilter_init_str 函数的功能是一样的,只不过传递的参数形式不同。 但是当传入的 options 中有不被 filter 所支持的参数时,这两个函数的行为是不同:
avfilter_init_str 调用会失败,而这个函数则不会失败,它会将不能应用于指定 filter 的 option 通过参数 options 返回,然后继续执行任务。
*/
int avfilter_init_dict(AVFilterContext *ctx, AVDictionary **options);/**
* 创建一个Filter实例(根据args和opaque的参数),并添加到已存在的AVFilterGraph.
* 如果创建成功*filt_ctx会指向一个创建好的Filter实例,否则会指向NULL.
* @return 失败返回负数,否则返回大于等于0的数
*/
int avfilter_graph_create_filter(AVFilterContext **filt_ctx, const AVFilter *filt, const char *name, const char *args, void *opaque, AVFilterGraph *graph_ctx);3.5.2. AVFilterGraph 相关的Api
AVFilterGraph 表示一个 filter graph,当然它也包含了 filter chain的概念。graph 包含了诸多 filter context 实例,并负责它们之间的 link,graph 会负责创建,保存,释放 这些相关的 filter context 和 link,一般不需要用户进行管理。
graph 的操作有:分配一个graph,往graph中添加一个filter context,添加一个 filter graph,对 filter 进行 link 操作,检查内部的link和format是否有效,释放graph等。
根据上述操作,可以列举的方法分别为:
分配空的filter graph:
/* 分配一个空的 filter graph. 成功返回一个 filter graph,失败返回 NULL */ AVFilterGraph *avfilter_graph_alloc(void);
创建一个新的filter实例:
/*
在 filter graph 中创建一个新的 filter 实例。这个创建的实例尚未初始化。
详细描述:在 graph 中创建一个名称为 name 的 filter类型的实例。
创建失败,返回NULL。创建成功,返回 filter context实例。创建成功后的实例会加入到graph中,
可以通过 AVFilterGraph.filters 或者 avfilter_graph_get_filter() 获取。
*/
AVFilterContext *avfilter_graph_alloc_filter(AVFilterGraph *graph, const AVFilter *filter, const char *name);
返回名字为name的filter context:
/* 返回 graph 中的名为 name 的 filter context。 */ AVFilterContext *avfilter_graph_get_filter(AVFilterGraph *graph, const char *name);
在 filter graph 中创建一个新的 filter context 实例,并使用args和opaque初始化这个filter context:
/* 在 filter graph 中创建一个新的 filter context 实例,并使用 args 和 opaque 初始化这个实例。 参数 filt_ctx:返回成功创建的 filter context 返回值:成功返回正数,失败返回负的错误值。 */ int avfilter_graph_create_filter(AVFilterContext **filt_ctx, const AVFilter *filt, const char *name, const char *args, void *opaque, AVFilterGraph *graph_ctx);
配置 AVFilterGraph 的链接和格式:
/* 检查 graph 的有效性,并配置其中所有的连接和格式。 有效则返回 >= 0 的数,否则返回一个负值的 AVERROR. */ int avfilter_graph_config(AVFilterGraph *graphctx, void *log_ctx);
释放AVFilterGraph:
/* 释放graph,摧毁内部的连接,并将其置为NULL。 */ void avfilter_graph_free(AVFilterGraph **graph);
在一个已经存在的link中插入一个FilterContext:
/* 在一个已经存在的 link 中间插入一个 filter context。 参数filt_srcpad_idx和filt_dstpad_idx:指定filt要连接的输入和输出pad的index。 成功返回0. */ int avfilter_insert_filter(AVFilterLink *link, AVFilterContext *filt, unsigned filt_srcpad_idx, unsigned filt_dstpad_idx);
将字符串描述的filter graph 加入到一个已存在的graph中:
/*
将一个字符串描述的 filter graph 加入到一个已经存在的 graph 中。
注意:调用者必须提供 inputs 列表和 outputs 列表。它们在调用这个函数之前必须是已知的。
注意:inputs 参数用于描述已经存在的 graph 的输入 pad 列表,也就是说,从新的被创建的 graph 来讲,它们是 output。
outputs 参数用于已经存在的 graph 的输出 pad 列表,从新的被创建的 graph 来说,它们是 input。
成功返回 >= 0,失败返回负的错误值。
*/
int avfilter_graph_parse(AVFilterGraph *graph, const char *filters,
AVFilterInOut *inputs, AVFilterInOut *outputs,
void *log_ctx);
/*
和 avfilter_graph_parse 类似。不同的是 inputs 和 outputs 参数,即做输入参数,也做输出参数。
在函数返回时,它们将会保存 graph 中所有的处于 open 状态的 pad。返回的 inout 应该使用 avfilter_inout_free() 释放掉。
注意:在字符串描述的 graph 中,第一个 filter 的输入如果没有被一个字符串标识,默认其标识为"in",最后一个 filter 的输出如果没有被标识,默认为"output"。
intpus:作为输入参数是,用于保存已经存在的graph的open inputs,可以为NULL。
作为输出参数,用于保存这个parse函数之后,仍然处于open的inputs,当然如果传入为NULL,则并不输出。
outputs:同上。
*/
int avfilter_graph_parse_ptr(AVFilterGraph *graph, const char *filters,
AVFilterInOut **inputs, AVFilterInOut **outputs, void *log_ctx);
/*
和 avfilter_graph_parse_ptr 函数类似,不同的是,inputs 和 outputs 函数不作为输入参数,
仅作为输出参数,返回字符串描述的新的被解析的graph在这个parse函数后,仍然处于open状态的inputs和outputs。
返回的 inout 应该使用 avfilter_inout_free() 释放掉。
成功返回0,失败返回负的错误值。
*/
int avfilter_graph_parse2(AVFilterGraph *graph, const char *filters,
AVFilterInOut **inputs, AVFilterInOut **outputs);
将graph转换为可读取的字符串描述:
/* 将 graph 转化为可读的字符串描述。 参数options:未使用,忽略它。 */ char *avfilter_graph_dump(AVFilterGraph *graph, const char *options);
3.5.3、FFmpeg Filter Buffer 和 BufferSink 相关APi的使用方法整理
Buffer 和 BufferSink 作为 graph 的输入点和输出点来和我们交互,我们仅需要和其进行数据交互即可。其API如下:
//buffersrc flag
enum {
//不去检测 format 的变化
AV_BUFFERSRC_FLAG_NO_CHECK_FORMAT = 1,
//立刻将 frame 推送到 output
AV_BUFFERSRC_FLAG_PUSH = 4,
//对输入的frame新建一个引用,而非接管引用
//如果 frame 是引用计数的,那么对它创建一个新的引用;否则拷贝frame中的数据
AV_BUFFERSRC_FLAG_KEEP_REF = 8,
};
向 buffer_src 添加一个Frame:
/*
向 buffer_src 添加一个 frame。
默认情况下,如果 frame 是引用计数的,那么这个函数将会接管其引用并重新设置 frame。
但这个行为可以由 flags 来控制。如果 frame 不是引用计数的,那么拷贝该 frame。
如果函数返回一个 error,那么 frame 并未被使用。frame为NULL时,表示 EOF。
成功返回 >= 0,失败返回负的AVERROR。
*/
int av_buffersrc_add_frame_flags(AVFilterContext *buffer_src, AVFrame *frame, int flags);
添加一个frame到 src filter:
/*
添加一个 frame 到 src filter。
这个函数等同于没有 AV_BUFFERSRC_FLAG_KEEP_REF 的 av_buffersrc_add_frame_flags() 函数。
*/
int av_buffersrc_add_frame(AVFilterContext *ctx, AVFrame *frame);
/* 添加一个 frame 到 src filter。 这个函数等同于设置了 AV_BUFFERSRC_FLAG_KEEP_REF 的av_buffersrc_add_frame_flags() 函数。 */ int av_buffersrc_write_frame(AVFilterContext *ctx, const AVFrame *frame);
从sink获取已filtered处理的帧,并放到参数frame中:
/*
从 sink 中获取已进行 filtered 处理的帧,并将其放到参数 frame 中。
参数ctx:指向 buffersink 或 abuffersink 类型的 filter context
参数frame:获取到的被处理后的frame,使用后必须使用av_frame_unref() / av_frame_free()释放掉它
成功返回非负数,失败返回负的错误值,如 EAGAIN(表示需要新的输入数据来产生filter后的数据),
AVERROR_EOF(表示不会再有新的输入数据)
*/
int av_buffersink_get_frame_flags(AVFilterContext *ctx, AVFrame *frame, int flags);
/*
同 av_buffersink_get_frame_flags ,不过不能指定 flag。
*/
int av_buffersink_get_frame(AVFilterContext *ctx, AVFrame *frame)
/* 和 av_buffersink_get_frame 相同,不过这个函数是针对音频的,而且可以指定读取的取样数。此时 ctx 只能指向 abuffersink 类型的 filter context。 */ int av_buffersink_get_samples(AVFilterContext *ctx, AVFrame *frame, int nb_samples);
3.5.3、FFmpeg AVFilter 使用整体流程
下图就是FFmpeg AVFilter在使用过程中的流程图:

我们对上图先做下说明,理解下图中每个步骤的关系,然后,才从代码的角度来给出其使用的步骤。
1. 最顶端的AVFilterGraph,这个结构前面介绍过,主要管理加入的过滤器,其中加入的过滤器就是通过函数avfilter_graph_create_filter来创建并加入,这个函数返回是AVFilterContext(其封装了AVFilter的详细参数信息)。
2. buffer和buffersink这两个过滤器是FFMpeg为我们实现好的,buffer表示源,用来向后面的过滤器提供数据输入(其实就是原始的AVFrame);buffersink过滤器是最终输出的(经过过滤器链处理后的数据AVFrame),其它的诸如filter 1 等过滤器是由avfilter_graph_parse_ptr函数解析外部传入的过滤器描述字符串自动生成的,内部也是通过avfilter_graph_create_filter来创建过滤器的。
3. 上面的buffer、filter 1、filter 2、filter n、buffersink之间是通过avfilter_link函数来进行关联的(通过AVFilterLink结构),这样子过滤器和过滤器之间就通过AVFilterLink进行关联上了,前一个过滤器的输出就是下一个过滤器的输入,注意,除了源和接收过滤器之外,其它的过滤器至少有一个输入和输出,这很好理解,中间的过滤器处理完AVFrame后,得到新的处理后的AVFrame数据,然后把新的AVFrame数据作为下一个过滤器的输入。
4. 过滤器建立完成后,首先我们通过av_buffersrc_add_frame把最原始的AVFrame(没有经过任何过滤器处理的)加入到buffer过滤器的fifo队列。
5. 然后调用buffersink过滤器的av_buffersink_get_frame_flags来获取处理完后的数据帧(这个最终放入buffersink过滤器的AVFrame是通过之前创建的一系列过滤器处理后的数据)。
使用流程图就介绍到这里,下面结合上面的使用流程图详细说下FFMpeg中使用过滤器的步骤,这个过程我们分为三个部分:过滤器构建、数据加工、资源释放。
3.5.3.1, 过滤器构建:
1)分配AVFilterGraph
AVFilterGraph* graph = avfilter_graph_alloc();2)创建过滤器源
char srcArgs[256] = {0};
AVFilterContext *srcFilterCtx;
AVFilter* srcFilter = avfilter_get_by_name("buffer");
avfilter_graph_create_filter(&srcFilterCtx, srcFilter ,"out_buffer", srcArgs, NULL, graph);3)创建接收过滤器
AVFilterContext *sinkFilterCtx;
AVFilter* sinkFilter = avfilter_get_by_name("buffersink");
avfilter_graph_create_filter(&sinkFilterCtx, sinkFilter,"in_buffersink", NULL, NULL, graph);4)生成源和接收过滤器的输入输出
这里主要是把源和接收过滤器封装给AVFilterInOut结构,使用这个中间结构来把过滤器字符串解析并链接进graph,主要代码如下:
AVFilterInOut *inputs = avfilter_inout_alloc();
AVFilterInOut *outputs = avfilter_inout_alloc();
outputs->name = av_strdup("in");
outputs->filter_ctx = srcFilterCtx;
outputs->pad_idx = 0;
outputs->next = NULL;
inputs->name = av_strdup("out");
inputs->filter_ctx = sinkFilterCtx;
inputs->pad_idx = 0;
inputs->next = NULL;这里源对应的AVFilterInOut的name最好定义为in,接收对应的name为out,因为FFMpeg源码里默认会通过这样个name来对默认的输出和输入进行查找。
5)通过解析过滤器字符串添加过滤器
const *char filtergraph = "[in1]过滤器名称=参数1:参数2[out1]";
int ret = avfilter_graph_parse_ptr(graph, filtergraph, &inputs, &outputs, NULL);这里过滤器是以字符串形式描述的,其格式为:[in]过滤器名称=参数[out],过滤器之间用,或;分割,如果过滤器有多个参数,则参数之间用:分割,其中[in]和[out]分别为过滤器的输入和输出,可以有多个。
6)检查过滤器的完整性
avfilter_graph_config(graph, NULL);3.5.3.2, 数据加工
1)向源过滤器加入AVFrame
AVFrame* frame; // 这是解码后获取的数据帧
int ret = av_buffersrc_add_frame(srcFilterCtx, frame);2)从buffersink接收处理后的AVFrame
int ret = av_buffersink_get_frame_flags(sinkFilterCtx, frame, 0);现在我们就可以使用处理后的AVFrame,比如显示或播放出来。
3.5.3.3, 资源释放
使用结束后,调用avfilter_graph_free(&graph);释放掉AVFilterGraph类型的graph。