- 以往的大多数教程都是数年前的Faster RCNN源码,因为旧环境和现有环境的不同,导致环境配置方面出现一系列问题。
- 特别是利用setup.py或者make.sh配置所需的环境时,遇到并解决一个又一个的问题,遗憾的是,失败总是贯彻全局。
- 解决方案:找到近年的Faster RCNN源码,观察是否需要setup.py,作为一个Lucky Boy,在此分享我的操作流程。
源码编写的非常棒!里面也详细叙述了如何使用此源码,我在这里简要叙述一下重要步骤。
目录
1、配置环境
可以直接利用命令直接安装:
pip install requirement.txt建议:自己耐心安装所缺少的环境,特别是:
CUDA、CUDNN和Torch的版本一定要对应。2、下载预训练模型
官网提供两个预训练模型:

共同点:基于VOC07+12数据集进行训练。
不同点:前者的骨干网络为Resnet50,后者的骨干网络为VGG16。
注意:训练过程中,需要选取使用哪一种骨干网络,此时需要和预训练模型中的骨干网络对应。
3、处理数据集

(1)配置的数据集路径如上图左边的列表所示:
- Annotations:xml文件
- ImageSets/Main:索引文件
- JPEGimages:图像文件

(2)修改class.txt:填写自己数据集的类别。
(3)数据集索引文件:编写可以生成数据集索引的py文件(参考文件在文章末尾)。
(4)训练所需txt文件:通过voc_annotation.py文件根据数据集所在的路径,生成训练所必须的文件:train.txt and val.txt。
注意:voc_annotation.py中包含生成索引文件的代码。因为本人数据集是提前随机8:1:1划分完毕的,voc_annotation.py里面包含随即划分,所以本人从voc_annotation.py中提取代码单独作为索引py文件。
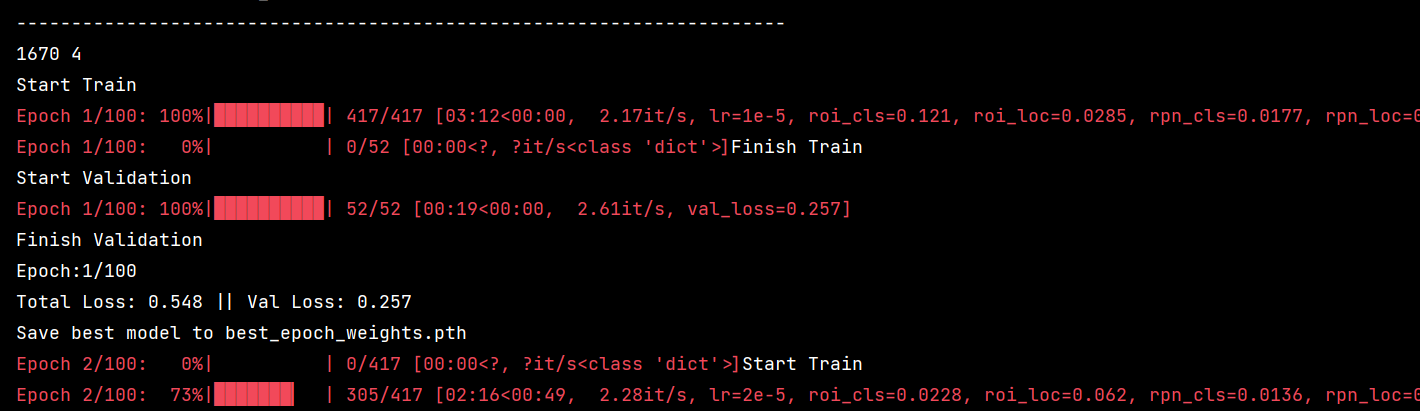
4、代码跑通截图:
5、训练生成文件:
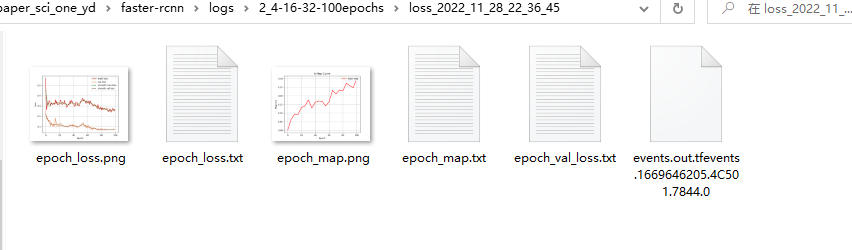

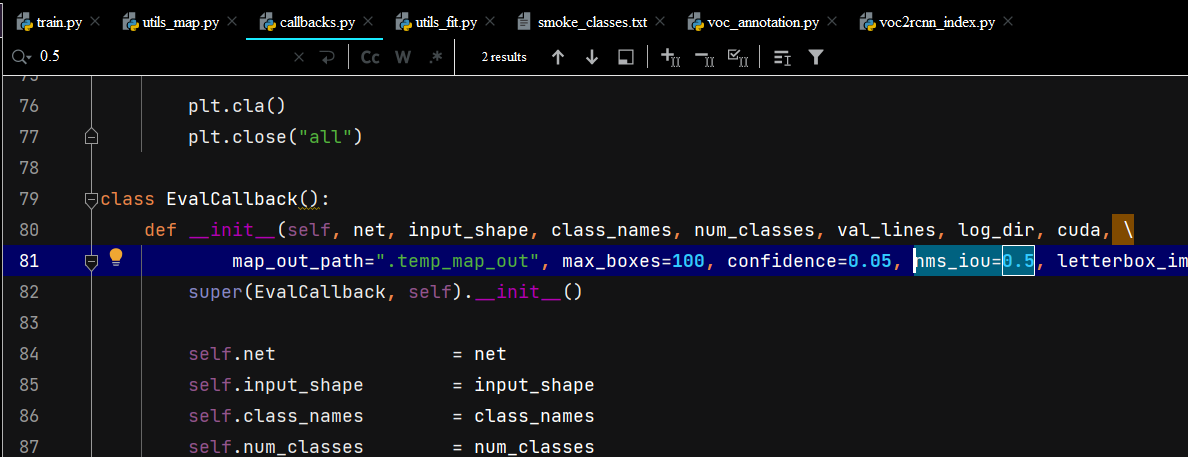
上图包含checkpoints权重文件和训练过程中的Loss和mAP文件,这里的mAP默认为0.5,代表NMS过程中的IOU=0.5,如下图所示。
附录:
Index.py
import os
import random
xmlfilepath=r'./JPEGImages/val/'
saveBasePath=r".\ImageSets\Main/"
temp_xml = os.listdir(xmlfilepath)
total_xml = []
for xml in temp_xml:
if xml.endswith(".jpg") or xml.endswith('.png'):
total_xml.append(xml)
num=len(total_xml) #xml文件总数
print(num)
list = range(num)
ftrain = open(os.path.join(saveBasePath,'val.txt'), 'w')
for i in list:
name = total_xml[i].split('.')[0]+'\n'
ftrain.write(name)
ftrain.close()
>>> 如有疑问,欢迎评论区一起探讨。