原文来自简书(@运动小爽),作者写得比较详细了,我自己按这个步骤配置了一遍,可以训练得到结果,因为“简书”有时候图片加载不了,所以自己重新写了一遍,方便阅读;相比原文其中有部分更改。
第一步:制作自己的数据集
首先,为了方便,可以将自己的训练图像名称改成PASCAL VOC格式,比如我自己的数据集共有1150张训练图像,写一个简单的python脚本将其重命名为00001.jpg~001150.jpg。
数据集的制作工具:labelImg。安装和使用方法都很简单,这里不再赘述。
第二步:clone py-faster-rcnn源代码
在bash中执行
git clone --recursive https://github.com/rbgirshick/py-faster-rcnn.git
将得到一个py-faster-rcnn文件夹。
(1)进入py-faster-rcnn/lib
make
(2)进入py-faster-rcnn/caffe-fast-rcnn(如果已经编译好了GPU版Caffe,貌似不用再编译,不需要这一步,直接往下走)
cp Makefile.config.example MAkefile.config
然后配置Makefile.config文件,参考:https://blog.csdn.net/u011511601/article/details/80109122 中第九步。
然后
make all -j8
make pycaffe
在编译/py-faster-rcnn/caffe-fast-rcnn/文件夹时出现了以下错误:
ys@ysubuntu:~/pycaffe/py-faster-rcnn/caffe-fast-rcnn$ make -j8 && make pycaffe
PROTOC src/caffe/proto/caffe.proto
CXX src/caffe/parallel.cpp
CXX src/caffe/internal_thread.cpp
...
In file included from ./include/caffe/util/device_alternate.hpp:40:0,
from ./include/caffe/common.hpp:19,
from ./include/caffe/blob.hpp:8,
from ./include/caffe/net.hpp:10,
from ./include/caffe/solver.hpp:7,
from ./include/caffe/sgd_solvers.hpp:7,
from src/caffe/solvers/nesterov_solver.cpp:3:
./include/caffe/util/cudnn.hpp: In function ‘void caffe::cudnn::createPoolingDesc(cudnnPoolingStruct**, caffe::PoolingParameter_PoolMethod, cudnnPoolingMode_t*, int, int, int, int, int, int)’:
./include/caffe/util/cudnn.hpp:127:41: error: too few arguments to function ‘cudnnStatus_t cudnnSetPooling2dDescriptor(cudnnPoolingDescriptor_t, cudnnPoolingMode_t, cudnnNanPropagation_t, int, int, int, int, int, int)’
pad_h, pad_w, stride_h, stride_w));
^
./include/caffe/util/cudnn.hpp:15:28: note: in definition of macro ‘CUDNN_CHECK’
cudnnStatus_t status = condition; \
^
In file included from ./include/caffe/util/cudnn.hpp:5:0,
from ./include/caffe/util/device_alternate.hpp:40,
from ./include/caffe/common.hpp:19,
from ./include/caffe/blob.hpp:8,
from ./include/caffe/net.hpp:10,
from ./include/caffe/solver.hpp:7,
from ./include/caffe/sgd_solvers.hpp:7,
from src/caffe/solvers/nesterov_solver.cpp:3:
/usr/local/cuda/include/cudnn.h:803:27: note: declared here
cudnnStatus_t CUDNNWINAPI cudnnSetPooling2dDescriptor(
^
Makefile:563: recipe for target '.build_release/src/caffe/solvers/nesterov_solver.o' failed
make: *** [.build_release/src/caffe/solvers/nesterov_solver.o] Error 1
make: *** Waiting for unfinished jobs....
...
make: *** [.build_release/src/caffe/parallel.o] Error 1
ys@ysubuntu:~/pycaffe/py-faster-rcnn/caffe-fast-rcnn$ make clean
ys@ysubuntu:~/pycaffe/py-faster-rcnn/caffe-fast-rcnn$
错误的原因应该是py-faster-rcnn中自带的cudnn相关文件版本太老。
解决办法参考:py-faster-rcnn安装问题总结。也就是用最新下载的caffe源代码中/caffe/include/和/caffe/src/下面所有和cudnn相关的.hpp文件和.cpp文件复制到/py-faster-rcnn/caffe-fast-rcnn/文件夹下,替换掉老版本的cudnn文件。
这样就能顺利编译/py-faster-rcnn/caffe-fast-rcnn/文件夹了。
第三步:将自己的数据集放到指定位置
为了尽量少改动代码,最方便的方式是按照源代码中的PASCAL VOC数据集的放置格式,即在…/py-faster-rcnn/data/文件夹下,新建一个名为VOCdevkit2007,然后,其子文件夹的目录树如下图:
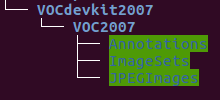
也就是在VOCdevkit2007下再建一个名为VOC2007的文件夹;然后在VOC2007下面分别建立3个文件夹:Annotations、ImageSets和JPEGImages。其中JPEGImages下面放的是训练集图片:
Annotations下面放的是自己制作的训练集图片对应的.xml标签文件:
ImageSets下面的目录如下:
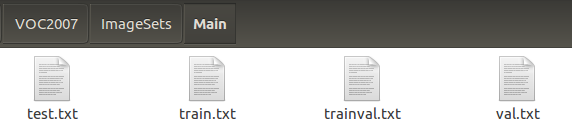
这里我用代码(get_voc2007_Main.py)生成的,代码要放在下图目录位置:
 其中get_voc2007_Main.py代码如下:
其中get_voc2007_Main.py代码如下:
import os
import random
trainval_percent = 0.66 #可以自己修改
train_percent = 0.5 #可以自己修改
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
第四步:下载训练好的VGG16模型
参照py-faster-rcnn的使用说明,要训练模型需要下载一个训练好的VGG16模型用于迁移学习。在py-faster-rcnn/目录下打开bash,执行:
./data/scripts/fetch_imagenet_models.sh
或者用迅雷下载,更快(我的电脑一直打开不了这个网页,fetch_imagenet_models.sh里的链接也打不开)
下载下来后,在/py-faster-rcnn/data/文件夹下新建一个imagenet_models文件夹,将VGG16模型放进去:

第五步:修改配置来训练自己的数据集
(1)修改train.prototxt和solver.prototxt
打开/py-faster-rcnn/models/pascal_voc/VGG16/faster_rcnn_end2end/train.prototxt,使用编辑器的查找替换功能,将其中的数字21替换成你自己的数据集类别数+1,将数字84替换成你自己的(数据集类别数+1)*4,这个文件中共有3处21,一处84需要替换;
在/py-faster-rcnn/models/pascal_voc/VGG16/faster_rcnn_end2end/solver.prototxt中,根据自己的实际情况修改,比如我只是的总训练迭代次数只设置了10000次,所以solver文件中,stepsize值我改成了6000。
(2)修改pascal_voc.py
将/py-faster-rcnn/lib/datasets/pascal_voc.py中的约33行处的:
self._classes = ('__background__', # always index 0
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor')
改为自己的类别
(3)修改train_net.py
在/py-faster-rcnn/tools/train_net.py中,可以为其中的命令行参数设置默认值,这样就不用每次训练时都在命令行设置多个参数了,下面是我设置的默认值:
def parse_args():
"""
Parse input arguments
"""
parser = argparse.ArgumentParser(description='Train a Fast R-CNN network')
parser.add_argument('--gpu', dest='gpu_id',
help='GPU device id to use [0]',
default=0, type=int)
parser.add_argument('--solver', dest='solver',
help='solver prototxt',
default='models/pascal_voc/VGG16/faster_rcnn_end2end/solver.prototxt', type=str)
parser.add_argument('--iters', dest='max_iters',
help='number of iterations to train',
default=10000, type=int)
parser.add_argument('--weights', dest='pretrained_model',
help='initialize with pretrained model weights',
default='data/imagenet_models/VGG16.v2.caffemodel', type=str)
parser.add_argument('--cfg', dest='cfg_file',
help='optional config file',
default='experiments/cfgs/faster_rcnn_end2end.yml', type=str)
parser.add_argument('--imdb', dest='imdb_name',
help='dataset to train on',
default='voc_2007_trainval', type=str)
parser.add_argument('--rand', dest='randomize',
help='randomize (do not use a fixed seed)',
action='store_true')
parser.add_argument('--set', dest='set_cfgs',
help='set config keys', default=None,
nargs=argparse.REMAINDER)
if len(sys.argv) == 1:
parser.print_help()
sys.exit(1)
args = parser.parse_args()
return args
另外可能需要修改的是/py-faster-rcnn/lib/fast_rcnn/config.py中的__C.TRAIN.SNAPSHOT_ITERS参数,它确定了你的模型每训练多少次保存一次快照,源码设置的是10000,根据自己设置的最大迭代次数来合理修改(它的值当然不能大于最大迭代次数,不然训练了半天一个模型都没保存)。
第六步:训练模型
以上准备工作完成后,在/py-faster-rcnn/目录下打开bash,执行:
python ./tools/train_net.py --gpu 0
训练可能遇到的问题:
我写了一份问题总结:https://blog.csdn.net/zhou4411781/article/details/96474303
(1)AttributeError: ‘module’ object has no attribute ‘text_format’
解决办法:
打开py-faster-rcnn/lib/fast_rcnn/train.py增加一行import google.protobuf.text_format 即可解决问题
参考:https://blog.csdn.net/qq_33202928/article/details/72526710
(2)bbox_targets[ind, start:end] = bbox_target_data[ind, 1:] TypeError: slice indices must be integers or None or have an index method
可能是源代码发布的时候,numpy 是支持浮点数作为索引的,但是在 numpy1.12.0 之后,numpy 只能用整数作为索引。
解决办法(两种):
第一种是卸载当前的 numpy,安装回以前的 1.11.2 版本,但是同时安装的 opencv 版本也得退回老版本,因为新版本的 opencv3.1 依赖于新版本的 numpy,相同的依赖问题还有matplotlib。因此的重装回 openCV2.4.13, matplotlib1.5.1,当然这种办法比较麻烦
第二种办法是找到使用浮点数作为 numpy 索引的相关代码,将其强制转换为 int 型:
在./lib/rpn/proposal_target_layer.py的126行 ,增加
start = int(start)
end = int(end)
在166行,增加
fg_rois_per_this_image = int(fg_rois_per_this_image)
参考:https://blog.csdn.net/a417197457/article/details/80593316
(3)UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xe6 in position 13: ordinal not in range(128)
原因是:python的str默认是ascii编码,和unicode编码冲突,就会报这个标题错误
解决办法:
在开头添加如下代码:
import sys
reload(sys)
sys.setdefaultencoding("utf8")
(4)roidb[i][‘image’] = imdb.image_path_at(i)
IndexError: list index out of range
解决办法:
删除fast-rcnn-master/data/cache/ 文件夹下的.pkl文件,或者改名备份,重新训练即可
参考:https://blog.csdn.net/marshwb/article/details/50451548 中第三部分“训练过程中错误”
第七步:测试模型
(1)修改test.prototxt
打开/py-faster-rcnn/models/pascal_voc/VGG16/faster_rcnn_end2end/test.prototxt,使用编辑器的查找替换功能,将其中的数字21替换成你自己的数据集类别数+1,将数字84替换成你自己的(数据集类别数+1)*4,这个文件中共有1处21,一处84需要替换;
(2)修改 demo.py
训练得到的模型在这里:

将其复制到/py-faster-rcnn/data/faster_rcnn_models/目录下。
然后打开 demo.py
1)将
CLASSES = ('__background__',
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor')
改成自己的标签
2)将NETS = {'vgg16': ('VGG16', 'VGG16_faster_rcnn_final.caffemodel'),
中的模型改成自己训练保存的模型。比如我修改的内容:
CLASSES = ('__background__', 'type1', 'type2', 'type3', 'type4', 'type5')
NETS = {'vgg16': ('VGG16', 'vgg16_faster_rcnn_iter_10000.caffemodel'),
3)将prototxt = os.path.join(cfg.MODELS_DIR, NETS[args.demo_net][0], 'faster_rcnn_alt_opt', 'faster_rcnn_test.pt')
改成
prototxt = os.path.join(cfg.MODELS_DIR, NETS[args.demo_net][0],
'faster_rcnn_end2end', 'test.prototxt')
4)将im_names = ['000456.jpg', '000542.jpg', '001150.jpg', '001763.jpg', '004545.jpg']
列表中的图片名改成自己要测试的图片名称,当然首先需要将相应的图片复制到/py-faster-rcnn/data/demo/目录下。
修改完成,在/py-faster-rcnn/目录下打开bash,执行
python ./tools/demo.py
没问题的话,就能顺利看到测试结果