写在前面
最近手头有一个项目需要交付,作为web项目,并发问题是不可避免的。对于Django后端,常用的并发实现方案就是Celery,虽然网上已经有不少实施例,但是实际开发过程中遇到一些问题。比如长连接异步执行结果如何反馈?Celery执行池如何选择?win下只支持多协程并发,如何解决Eventloop异步循环问题?这篇文章就介绍一个博主亲测成功的实施例架构。
环境配置
安装python库
asgiref 3.5.0
celery 4.4.6
channels 3.0.4
channels-redis 3.4.0
django 3.2.12
eventlet 0.33.3
flower 0.9.7
redis 3.5.3
安装redis
去官网下载一下redis安装即可,版本5.0.14
启动工程
启动redis:cmd中进入redis安装路径
redis-server redis.windows.conf
启动Celery:Vscode输入Celery安装路径,如果是anaconda安装的话,可以先找到安装的虚拟环境文件夹,一般celery安装路径在Lib\site-packages\bin下或在Scripts下
C:\Users\xxx\AppData\Local\conda\conda\envs\xxx\Scripts\celery -A xxx worker -I info -P eventlet -O fair
(可选)启动flower:Vscode输入Celery安装路径(同上一步),redisURL取决于Celery中的配置
C:\Users\xxx\AppData\Local\conda\conda\envs\xxx\Scripts\celery flower --address=127.0.0.1 --port=55555 --broker=redis://127.0.0.1:6379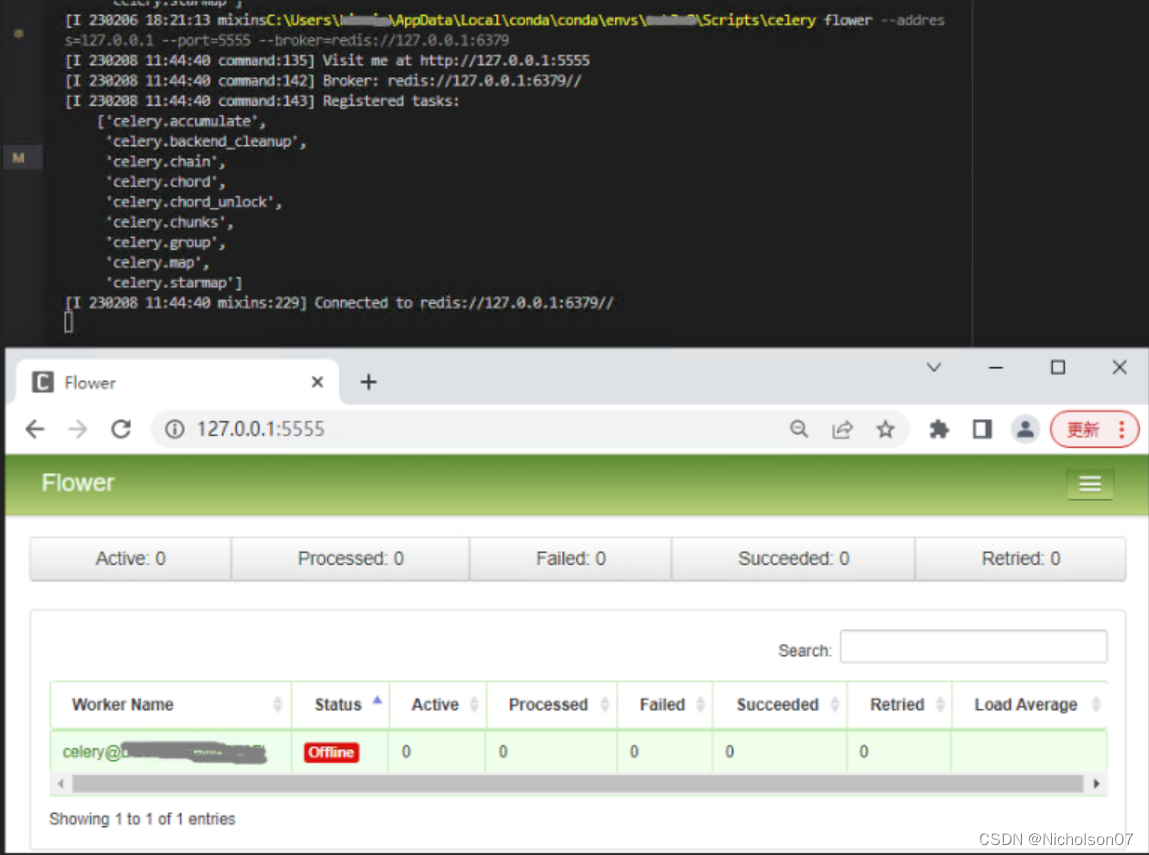
运行django:Vscode输入python虚拟环境路径
C:\Users\xxx\AppData\Local\conda\conda\envs\xxx\python.exe manage.py runserver 127.0.0.1:8020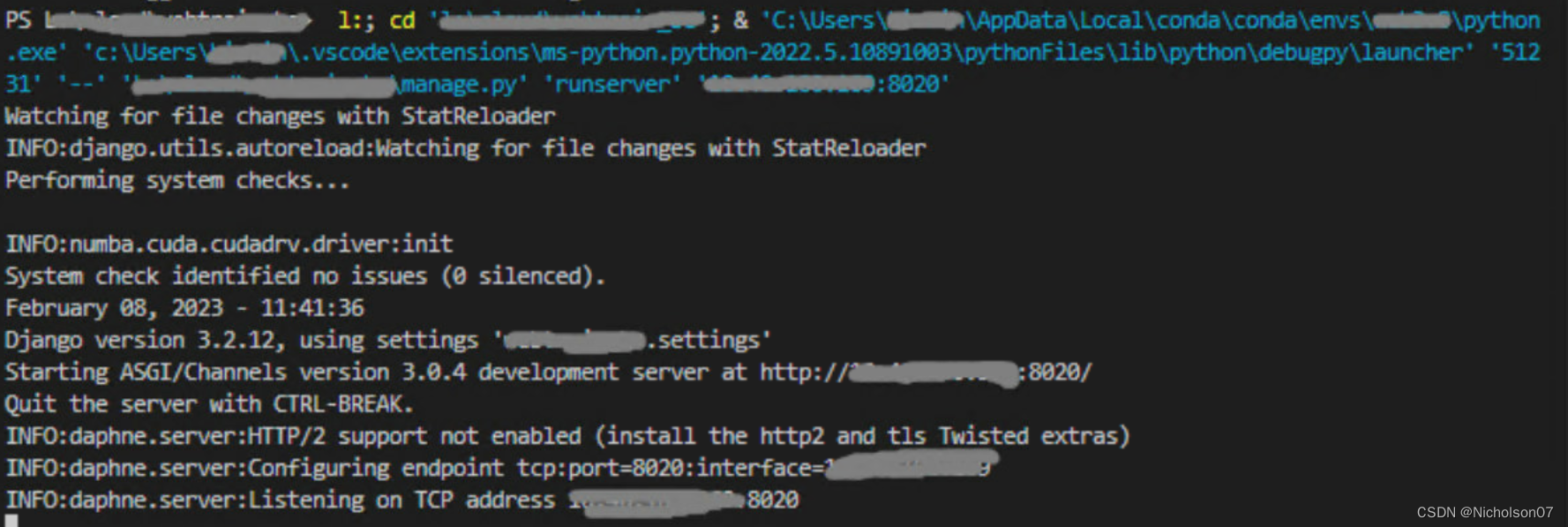
工程框架
以下是本文的demo工程框架
demo
|__main_app
|__migrations
|__service
|__consumer.py
|____init__.py
|__admin.py
|__apps.py
|__models.py
|__tasks.py
|__urls.py
|__views.py
|__demo
|___init__.py
|__asgi.py
|__celery.py
|__settings.py
|__urls.py
|__wsgi.py
|__manage.pyCelery介绍
官方文档
前言 - Celery 中文手册 (celerycn.io)
功能介绍
特性
高可用:如果连接丢失或失败,worker和客户端就会自动重试,并且中间人broker通过主/主,主/从方式来提高可用性。
快速:单个Celery进程每分钟执行数以百万计的任务,且保持往返延迟在亚毫秒级,可以选择多进程、Gevernt等并发执行。
灵活:Celery几乎所有模块都可以扩展或单独使用。可以自制连接池,日志、调度器、消费者、生产者等等。
框架集成:Celery易于和web框架集成,如django-celery,web2py-celery、tornado-celery等等。
强大的调度功能:Celery Beat进程来实现强大的调度功能,可以指定任务在若干秒后或一个时间点来执行,也可以基于单纯的时间间隔或支持分钟、小时、每周的第几天、每月的第几天等等,用crontab表达式来使用周期任务调度。
易监控:可以方便地查看定时任务的执行情况,如执行是否成功,当前状态、完成任务花费时间等,还可以使用功能完备的管理后台或命令行添加、更新、删除任务,提供了完善的错误处理机制。
机制
Celery 是一个异步任务队列/基于分布式消息传递的作业队列,用于分配计算机工作。其本质是生产者和消费者模式。生产者发送任务到消息队列,消费者负责处理任务。任务队列(Queue)的输入是一个称为任务的工作单元,职程(Worker)不断监视任务队列(Queue),获取任务并执行。
Celery 通过消息机制(AMQP协议)进行通信,Celery 可以有多个任务队列(Queue)和多个职称(Worker),用于提高Celery的高可用性以及横向扩展能力。每个任务队列(Queue)都有routing_key。当一个任务启动时,中间人(Broker)根据任务启动时设置的routing_key,将任务分发(Exchange)给对应的任务队列(Queue)。

中间人
不同中间人比较
名称 |
状态 |
监控 |
远程控制 |
RabbitMQ |
稳定 |
是 |
是 |
Redis |
稳定 |
是 |
是 |
Amazon SQS |
稳定 |
否 |
否 |
Zookeeper |
实验阶段 |
否 |
否 |
在实际的使用中,推荐使用RabbitMQ或者Redis作为broker
执行池
概念
当运行类似如下命令启动一个Celery进程时,其实启动的是一个管理进程,此进程不处理实际的任务,而是产生的子进程/线程/协程去处理具体任务,那么这些子进程/线程/协程就叫做执行池;
celery worker --app=worker.app执行池的大小决定了Celery可以并发执行任务的个数。
不同执行池工作方式
Prefork
Celery默认的执行池,是多进程的执行池,一般在计算密集型任务中使用,能充分利用cpu多核。如果不指定 –concurrency(并发进程个数)参数,则无论什么执行池都是尽可能多的使用cpu的核数。
要注意win10下无法使用该执行池,会有如下报错。
ValueError: not enough values to unpack (expected 3, got 0)Solo
这种执行池有点特殊,因为此模式在处理任务时会直接在管理进程中进行,也就意味着只有一个职程(Worker)在处理任务,上个任务不结束,则下个任务就会阻塞。但是在微服务中,比如在使用k8s 进行 docker部署时,可以使用此模式,这样 k8s直接通过观察启动多少个docker容器,就能知道启动了多少个Celery消费者。此模式即使指定--concurrency(并发数) 参数值也没有任何意义。
Eventlet/Gevent
这两个都是基于协程的执行池,一般在 IO密集型任务中使用,如频繁的网络请求,数据库操作等等。Gevent是对Eventlet的高级封装,一般使用时用 gevent,因为此包有monkey.patch_all()方法将所有能转为协程的地方都转为协程,从而增加处理能力。此模式指定--concurrency(并发数) 参数值可以比CPU核数多,理论上只要内存不爆,套接字够用,就可以增加。
预取机制
Celery启动时,默认是会启动预取机制的。
预取机制是为了均衡分配worker负载,即每个worker所执行的任务数量是要均等的。因此会指定任务队列(Queue)中的任务由哪个职称(Worker)执行。但是预取机制并不知道每个任务执行的具体时间,因此当某个任务需要执行很长时间,导致这个任务占用的worker一直得不到释放,这时候任务队列中被这个不被释放的worker预取的任务也一直在等待,并且,其他空闲worker想要取任务,但是都被这个等待的任务阻塞。最终导致整个Celery队列都将陷入等待。
如果你的任务中可能包含长时间执行的任务,建议关闭预取机制,方法如下:
设置CELERY_PREFETCH_MULTIPLIER = 1
使用-O fair启动celery
框架搭建
celery实例创建
创建celery.py
import os
from celery import Celery
from django.conf import settings
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'demo.settings')
app = Celery('demo', backend='redis://localhost:6379')
app.config_from_object('django.conf:settings')
app.autodiscover_tasks(lambda:settings.INSTALLED_APPS)
@app.task(bind=True)
def debug_task(self):
print('Request: {0!r}'.format(self.request))django参数配置
修改settings.py
INSTALL_APPS = [
...,
'channels',
'celery'
]
BROKER_URL = 'redis://127.0.0.1:6379'
CELERY_TIMEZONE = 'Asia/Shanghai'
CELERY_CONCURRENCY = 3 # worker数量
CELERYD_FORCE_EXECV = True # 非常重要,有些情况下可以防止死锁
CELERYD_PREFETCH_MULTIPLIER = 1 # 预取机制,worker中任务数量
CELERYD_MAX_TASKS_PER_CHILD = 200 # 每个worker最多执行万100个任务就会被销毁,可防止内存泄露
CELERY_QUEUES = (
Queue("default", Exchange("default"), routing_key="default"),
Queue("queue1", Exchange("queue1"), routing_key="queue1"),
Queue("queue2", Exchange("queue2"), routing_key="queue2"),
)
CELERY_ROUTES = {
'test1': {"queue": "queue1", "routing_key": "queue1"},
'test2': {"queue": "queue2", "routing_key": "queue2"},
}
CHANNEL_LAYERS = {
"default": {
"BACKEND": "channels_redis.core.RedisChannelLayer",
"CONFIG": {
"hosts": [('127.0.0.1', 6379)],
},
},
}Websocket异步接口实现
修改demo\urls.py
from django.urls import path
from main_app.service.comsumer import Test1, Test2
websocket_urlpatterns = [
path('ws/test1', Test1.as_asgi()),
path('ws/test2', Test2.as_asgi())
]实现consumer.py
import json
from channels.generic.websocket import WebsocketConsumer
from channels.exceptions import StopConsumer
from main_app.tasks import test1, test2
class Test1(WebsocketConsumer):
msg = None
def connect(self):
print('建立连接')
self.accept()
def disconnect(self, close_code):
print('断开连接')
return StopConsumer()
def receive(self, text_data):
request = json.loads(text_data)
self.msg = request['msg']
test1.delay(self.channel_name, self.msg)
def error(self, event):
self.send(json.dumps({ "type": "error", "context": self.msg }))
def postProcess(self, event):
self.send(json.dumps({ "type": "success", "context": self.msg }))
class Test2(WebsocketConsumer):
msg = None
def connect(self):
print('建立连接')
self.accept()
def disconnect(self, close_code):
print('断开连接')
return StopConsumer()
def receive(self, text_data):
request = json.loads(text_data)
self.msg = request['msg']
test2.delay(self.channel_name, self.msg)
def error(self, event):
self.send(json.dumps({ "type": "error", "context": self.msg }))
def postProcess(self, event):
self.send(json.dumps({ "type": "success", "context": self.msg }))实现tasks.py
from demo.celery import app
from channels.layers import get_channel_layer
import json
import os
import threading
@app.task(name='test1')
def test1(channel_name, msg):
print('test1 start')
channel_layer = get_channel_layer()
workers = app.control.inspect()
print('channel_name:', channel_name,
'当前worker:', workers.active(),
'当前进程: %d' % os.getpid(),
'父进程: %d' % os.getppid(),
'Thread id: %d' % threading.currentThread().ident)
for i in range(0, 10000):
for i in range(0, 10000):
i
print(msg)
print("test1 end")
@app.task(name='test1')
def test2(channel_name, msg):
print('test2 start')
channel_layer = get_channel_layer()
workers = app.control.inspect()
print('channel_name:', channel_name,
'当前worker:', workers.active(),
'当前进程: %d' % os.getpid(),
'父进程: %d' % os.getppid(),
'Thread id: %d' % threading.currentThread().ident)
for i in range(0, 10000):
for i in range(0, 10000):
i
print(msg)
print("test1 end")效果展示

问题分析
可以发现,现在以及可以通过celery实现长连接异步任务执行了,但是有一个比较大的缺点是websocket无法获取异步任务test1,test2的执行结果,前端无法显示,并且长连接会一直建立,不会关闭,所以接下来就是要解决这个回调的问题。
Websocket异步回调
asgiref实现回调
修改tasks.py
引入async_to_sync实现异步转同步,调用websocket中的postProcess接口返回内容。
from demo.celery import app
from channels.layers import get_channel_layer
from asgiref.sync import async_to_sync
import json
import os
import threading
@app.task(name='test1')
def test1(channel_name, msg):
print('test1 start')
channel_layer = get_channel_layer()
workers = app.control.inspect()
print('channel_name:', channel_name,
'当前worker:', workers.active(),
'当前进程: %d' % os.getpid(),
'父进程: %d' % os.getppid(),
'Thread id: %d' % threading.currentThread().ident)
for i in range(0, 10000):
for i in range(0, 10000):
i
print(msg)
async_to_sync(channel_layer.send)(channel_name, {'type': 'postProcess'})
print("test1 end")
@app.task(name='test1')
def test2(channel_name, msg):
print('test2 start')
channel_layer = get_channel_layer()
workers = app.control.inspect()
print('channel_name:', channel_name,
'当前worker:', workers.active(),
'当前进程: %d' % os.getpid(),
'父进程: %d' % os.getppid(),
'Thread id: %d' % threading.currentThread().ident)
for i in range(0, 10000):
for i in range(0, 10000):
i
print(msg)
async_to_sync(channel_layer.send)(channel_name, {'type': 'postProcess'})
print("test1 end")效果展示

问题分析
这样的话可以返回消息,并且当并发数为1的时候不会有问题,但是当并发数大于1 的时候会有报错,就是上方红色框起来的部分。
RuntimeError: You cannot use AsyncToSync in the same thread as an async event loop - just await the async function directly.这是由于eventlet是创建多个协程来实现并发,本质上多个协程是运行在同一个线程下的,这点从之前的截图中打印的消息可以看出来,虽然两个人任务运行的worker id不同,但是父进程、进程、线程都是一致的。下面就来解决这个报错问题。
使用结合协程锁解决问题
上面的问题产生是由于同一个线程中多个协程同时调用async_to_sync函数导致的,因此我们只要给协程加一个锁就可以了。
修改tasks.py
from demo.celery import app
from channels.layers import get_channel_layer
from asgiref.sync import async_to_sync
from eventlet.lock import Lock
import json
import os
import threading
lock = Lock()
def returnForWebsocket(channel_layer, channel_name, json):
with lock:
async_to_sync(channel_layer.send)(channel_name, json)
@app.task(name='test1')
def test1(channel_name, msg):
print('test1 start')
channel_layer = get_channel_layer()
workers = app.control.inspect()
print('channel_name:', channel_name,
'当前worker:', workers.active(),
'当前进程: %d' % os.getpid(),
'父进程: %d' % os.getppid(),
'Thread id: %d' % threading.currentThread().ident)
for i in range(0, 10000):
for i in range(0, 10000):
i
print(msg)
returnForWebsocket(channel_layer, channel_name, {'type': 'postProcess'})
print("test1 end")
@app.task(name='test1')
def test2(channel_name, msg):
print('test2 start')
channel_layer = get_channel_layer()
workers = app.control.inspect()
print('channel_name:', channel_name,
'当前worker:', workers.active(),
'当前进程: %d' % os.getpid(),
'父进程: %d' % os.getppid(),
'Thread id: %d' % threading.currentThread().ident)
for i in range(0, 10000):
for i in range(0, 10000):
i
print(msg)
returnForWebsocket(channel_layer, channel_name, {'type': 'postProcess'})
print("test1 end")效果展示

参考资料
前言 - Celery 中文手册 (celerycn.io)
python celery 多work多队列 (shuzhiduo.com)
celery分布式任务队列从入门到精通_大帅不是我的博客-CSDN博客_celery zookeeper