目录
Elasticsearch 学习+SpringBoot实战教程(一)
Elasticsearch 学习+SpringBoot实战教程(一)_桂亭亭的博客-CSDN博客
keyword是要求精确匹配,自然就是大小写敏感的
URI Search
使用的是 GET 方式,其中 q 指定查询语句,语法为 Query String Syntax,是 KV 键值对的形式;上面的请求表示对 username 字段进行查询,查询包含 wupx 的所有文档。
URI Search 有很多参数可以指定,除了 q 还有如下参数:
-
df:默认字段,不指定时会对所有字段进行查询
-
sort:根据字段名排序
-
from:返回的索引匹配结果的开始值,默认为 0
-
size:搜索结果返回的条数,默认为 10
-
timeout:超时的时间设置
-
fields:只返回索引中指定的列,多个列中间用逗号分开
-
analyzer:当分析查询字符串的时候使用的分词器
-
analyze_wildcard:通配符或者前缀查询是否被分析,默认为 false
-
explain:在每个返回结果中,将包含评分机制的解释
-
_source:是否包含元数据,同时支持
_source_includes和_source_excludes -
lenient:若设置为 true,字段类型转换失败的时候将被忽略,默认为 false
-
default_operator:默认多个条件的关系,AND 或者 OR,默认为 OR
-
search_type:搜索的类型,可以为
dfs_query_then_fetch或query_then_fetch,默认为query_then_fetch
指定字段查询
这个例子就是指定字段查询,以下的两条语句都可以达到指定字段查询的目的。
GET /user/_search?q=22&df=age
GET /user/_search?q=age:22
他们的含义是,通过get方式查询user索引中的age字段为22的所有信息
泛查询
GET /user/_search?q=22
这个就是泛查询,会对所有的字段进行查询操作,并返回所有数据
Term Query 和 Phrase Query
比如:
(男士 孝子 )等效于 男士 OR 孝子;
”男士 孝子 “等效于 男士 AND 孝子 =》》》》另外还要求前后顺序保存一致。
当为 Term Query 的时候,就需要把这两个词用括号括起来,
请求为 GET /user/_search?q=title:(男士 孝子),意思就是查询 title字段中包括 男士 或者 孝子的所有信息。
当为 Phrase Query 的时候就需要用引号包起来,
请求为 GET /user/_search?q=title:"男士 孝子"。
布尔,范围查询
布尔
URI Search还支持,比如 AND(&&)、OR(||)、NOT(!),需要注意大写,不能小写。
EG:
GET /user/_search?q=title:(男士 NOT 孝子)
这个请求表示查询 title 中必须包括 男士 不能包括 孝子 的文档。
范围查询
比如指定电影的年份大于 1994:GET /movies/_search?q=year:>=1994。
URI Search 还支持通配符查询(查询效率低,占用内存大,不建议使用,特别是放在最前面),还支持正则表达式,以及模糊匹配和近似查询。
URI Search 好处
操作简单,只要写个 URI 就可以了,方便测试,但是 URI Search 只包含一部分查询语法,不能覆盖所有 ES 支持的查询语法。
Request Body Search
这个比我们的URI Search更牛逼点,但是也更复杂
在 ES 中一些高阶用法只能在 Request Body 里做,所以我们尽量使用 Request Body Search,而且写程序的时候也常用的!!
它支持 GET 和 POST 方式对索引进行查询,需要指定操作的索引名称,
同样也要通过 _search 来标明这个请求为搜索请求,我们可以在请求体中使用 ES 提供的 DSL(领域特定语言),下面这个例子就是简单的 Query DSL:
查询
user中的所有信息
POST /user/_search
{
"query": {
"match_all": {}
}
}我们可以使用可视化工具执行看看结果,如下

分页
POST /user/_search{"from":10,"size":20,"query":{"match_all": {}}}
排序
POST /user/_search{"sort":[{"year":"desc"}],"query":{"match_all": {}}}
最好在“数字型”与“日期型”字段上排序,因为对于多值类型或者分析过的字段排序,系统会选一个值,无法得知该值。
desc逆序
返回指定字段
如果 _source 的数据量比较大,有些字段也不需要拿到这个信息,那么就可以对它的 _source 进行过滤,把需要的信息加到 _source 中,比如以下请求就是 _source 中只返回 title:
POST /user/_search{"_source":["title"],"query":{"match_all": {}}}
如果
_source没有存储,那就只返回匹配的文档的元数据,同时_source也支持使用通配符。
脚本字段
脚本字段可以使用 ES 中的 painless 的脚本去算出一个新的字段结果。
GET /movies/_search{"script_fields": {"new_field": {"script": {"lang": "painless","source": "doc['year'].value+'_hello'"}}},"query": {"match_all": {}}}
这个例子中就使用 painless 把电影的年份和 _hello 进行拼接形成一个新的字段 new_field
字段类查询
-
全文匹配:针对 text 类型的字段进行全文检索,会对查询语句先进行分词处理,如 match,match_phrase 等 query 类型
-
单词匹配:不会对查询语句做分词处理,直接去匹配字段的倒排索引,如 term,terms,range 等 query 类型
可以在 Request Body 中使用在 query match 的方式把信息填在里面,我们先来看下 Match Query,比如下面这个例子,填入两个单词,默认是 wupx or huxy 的查询条件,如果想查询两者同时出现,可以通过加 "operator": "and" 来实现。
POST /users/_search
{
"query": {
"match": {
"title": "wupx huxy"
"operator": "and"
}
}
}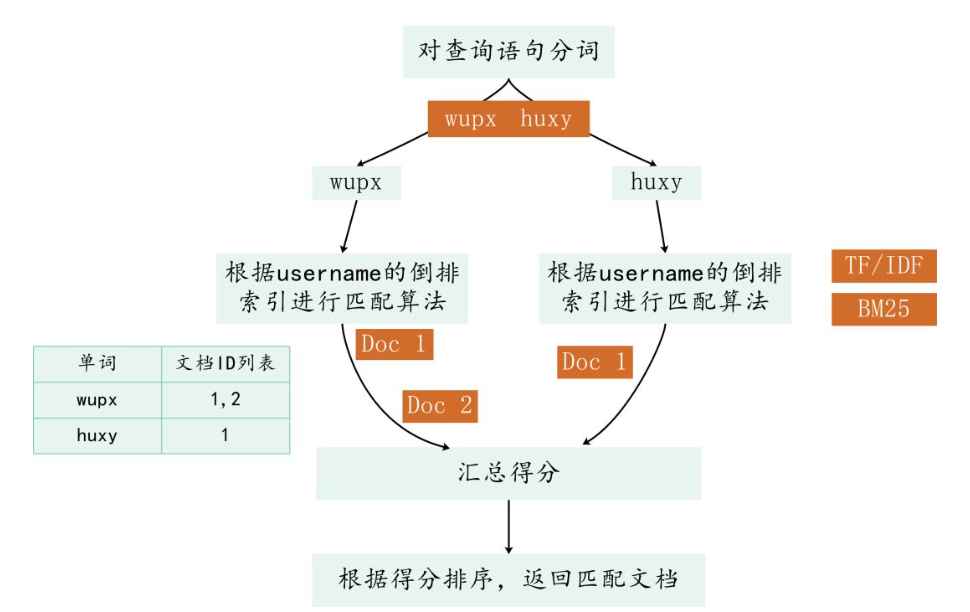
首先对查询语句进行分词,分成 wupx 和 huxy 两个 Term,然后 ES 会拿到 username 的倒排索引,对 wupx 和 huxy 去进行匹配的算分,比如 wupx 对应的文档是 1 和 2,huxy 对应的文档为 1,然后 ES 会利用算分算法(比如 TF/IDF 和 BM25,BM25 模型 5.x 之后的默认模型)列出文档跟查询的匹配得分,然后 ES 会对 wupx huxy 的文档的得分结果做一个汇总,最终根据得分排序,返回匹配文档。
Request Body 中还支持 Match Phrase 查询,但在 query 条件中的词必须顺序出现的,可以通过 slop 参数控制单词间的间隔,比如加上 "slop" :1,表示中间可以有一个其他的字符。
POST /movies/_search{"query": {"match_phrase": {"title":{"query": "one love""slop":1}}}}
了解完 Match Query,让我们再来看下 Term Query:
如果不希望 ES 对输入语句作分词处理的话,可以用 Term Query,将查询语句作为整个单词进行查询,使用方法和 Match 类似,只需要把 match 换为 term 就可以了,如下所示:
POST /users/_search{"query": {"term": {"username":"wupx"}}}
Terms Query 顾名思义就是一次可以传入多个单词进行查询,关键词是 terms,如下所示:
POST /users/_search{"query": {"terms": {"username": ["wupx","huxy"]}}}
另外 DSL 还支持特定的 Query String 的查询,比如指定默认查询的字段名 default_field 就和前面介绍的 df 是一样的,在 query 中也可以使用 AND 来实现一个与的操作。
POST users/_search{"query": {"query_string": {"default_field": "username","query": "wupx AND huxy"}}}
下面来看下 Simple Query String Query,它其实和 Query String 类似,但是会忽略错误的查询语法,同时只支持部分查询语法,不支持 AND OR NOT,会当作字符串处理,Term 之间默认的关系是 OR,可以指定 default_operator 来实现 AND 或者 OR,支持用 + 替代 AND,用 | 替代 OR,用 - 替代 NOT。
下面这个例子就是查询 username 字段中同时包含 wu 和px 的请求:
{"query": {"simple_query_string": {"query": "wu px","fields": ["username"],"default_operator": "AND"}}}
Response
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 0.9808292,"hits" : [{"_index" : "users","_type" : "_doc","_id" : "1","_score" : 0.9808292,"_source" : {"username" : "wupx","age" : "18"}}]}}
其中 took 表示花费的时间;
total 表示符合条件的总文档数;
hits 为结果集,默认是前 10 个文档;
_index 为索引名;
_id 为文档 id;
_score 为相关性评分;
_source 为文档的原始信息。
使用RestHighLevelClient的方式对文档搜索
精确查询
对应的原生查询语句
注意这里的term就是精准查询到 关键字
GET user/_search
{
"query": {
"term": {
"city": "上海"
}
}
}服务层
// 文档搜索
public String searchDocument(String indexName,String city){
//2 构建搜索请求
SearchRequest searchRequest = new SearchRequest().indices(indexName);
//3 构建搜索内容
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("city", city);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(termQueryBuilder);
//4 填充搜索内容
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = null;
try {
//5 执行搜索操作
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
//6 返回值
return JSON.toJSONString(searchResponse.getHits().getHits());
}控制器
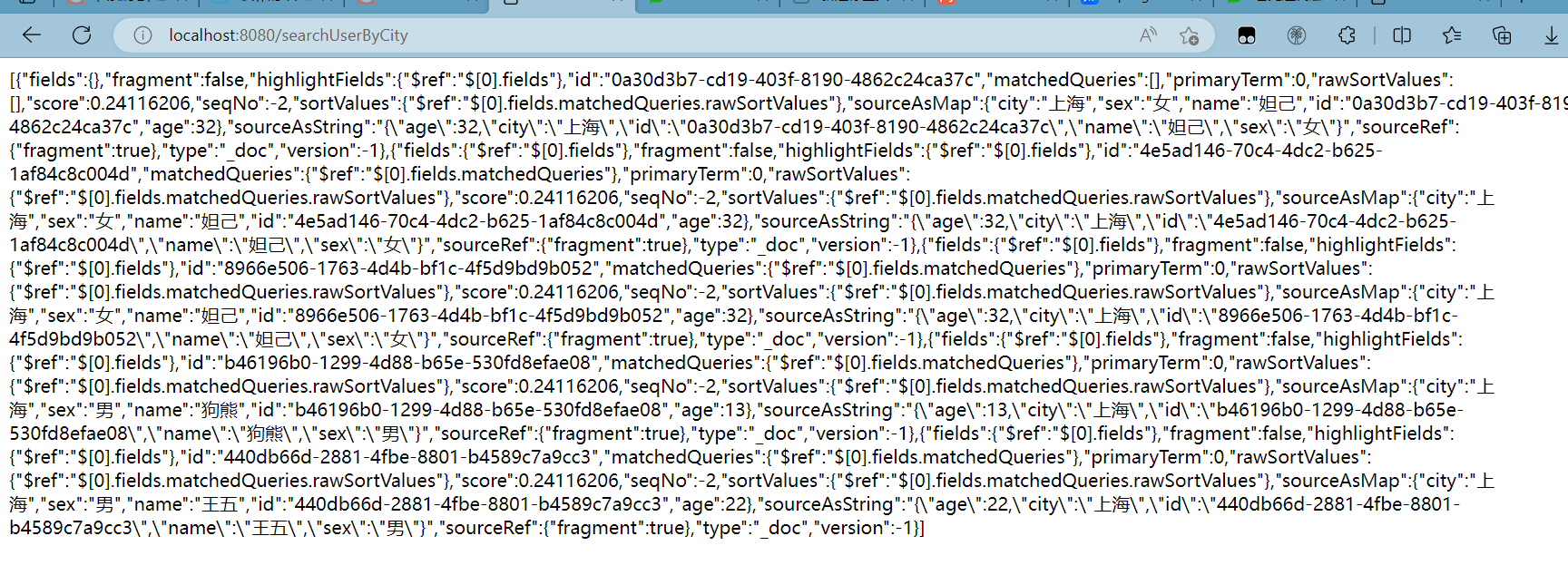
@GetMapping("/searchUserByCity")
public String searchUserByCity() throws IOException {
return service.searchDocument("user","上海");
}访问链接localhost:8080/searchUserByCity
分页查询
GET user/_search
{
"query": {
"term": {
"city": "上海"
}
},
"from":0,
"size":5
}服务层
// 文档搜索--分页查询
public String searchDocument2(String indexName,String city){
//2 构建搜索请求
SearchRequest searchRequest = new SearchRequest().indices(indexName);
//3 构建搜索内容
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//拿到前5条数据
searchSourceBuilder
.query(QueryBuilders.termQuery("city", city))
.from(0)
.size(5);
//4 填充搜索内容
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = null;
try {
//5 执行搜索操作
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
//6 返回值
return JSON.toJSONString(searchResponse.getHits().getHits());
}控制层
@GetMapping("/searchUserByCity2")
public String searchUserByCity2() throws IOException {
return service.searchDocument2("user","上海");
}访问localhost:8080/searchUserByCity2
字符匹配AND精准查询
term 与matchphrase的比较 term用于精确查找有点像 mysql里面的"=" match是先将查询关键字分词然后再进行查找。term一般用在keywokrd类型的字段上进行精确查找。
注意这里的bool,表示使用布尔查询,其中的must是相当于SQL语句中的and的意思。
所以就是查找name中包含“妲己”并且年龄为22岁的信息,请注意不能写成"妲",因为我们在新建文档的时候是这样新建的“妲己”,那么我们如果匹配“妲”就会匹配不到,加入这样写就可以匹配到了“妲 己”,请注意空格,这是分词的依据之一
ES查询语句。
GET user/_search
{
"query": {
"bool":{
"must": [
{
"match_phrase": {
"name": "妲己"
}
},
{
"term": {
"age": "32"
}
}
]
}
},
"from":0,
"size":10
}服务层
// 文档分词搜索+精确查询
public String searchDocument3(String indexName,String name,Integer age){
//2 构建搜索请求
SearchRequest searchRequest = new SearchRequest().indices(indexName);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//3 构建复杂的查询语句
BoolQueryBuilder bq=QueryBuilders
.boolQuery()
//分词匹配
.must(QueryBuilders.matchPhraseQuery("name",name))
//精确匹配
.must(QueryBuilders.matchQuery("age",age));
//4 填充搜索语句
searchSourceBuilder
.query(bq)
.from(0)
.size(5);
//4 填充搜索内容
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = null;
try {
//5 执行搜索操作
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
//6 返回值
return JSON.toJSONString(searchResponse.getHits());
}控制层
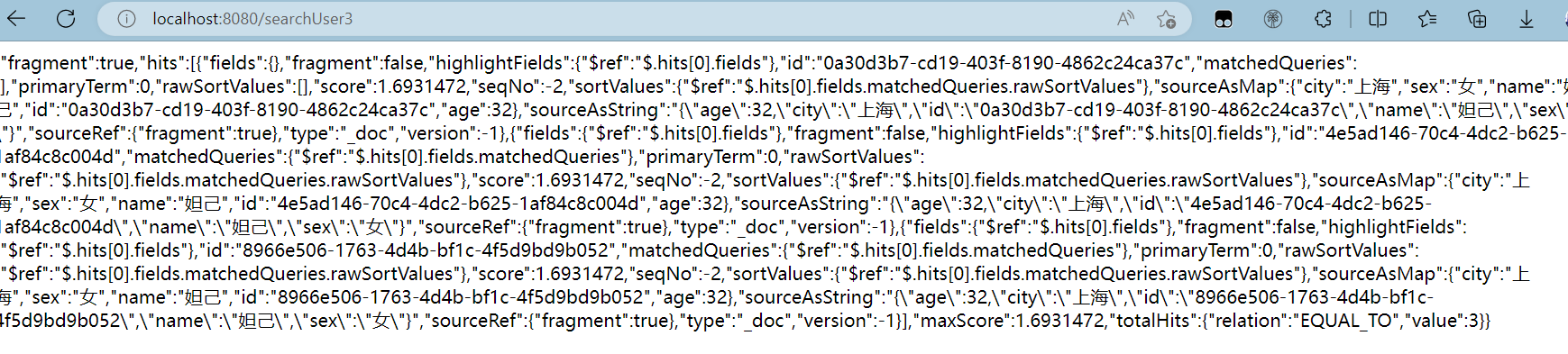
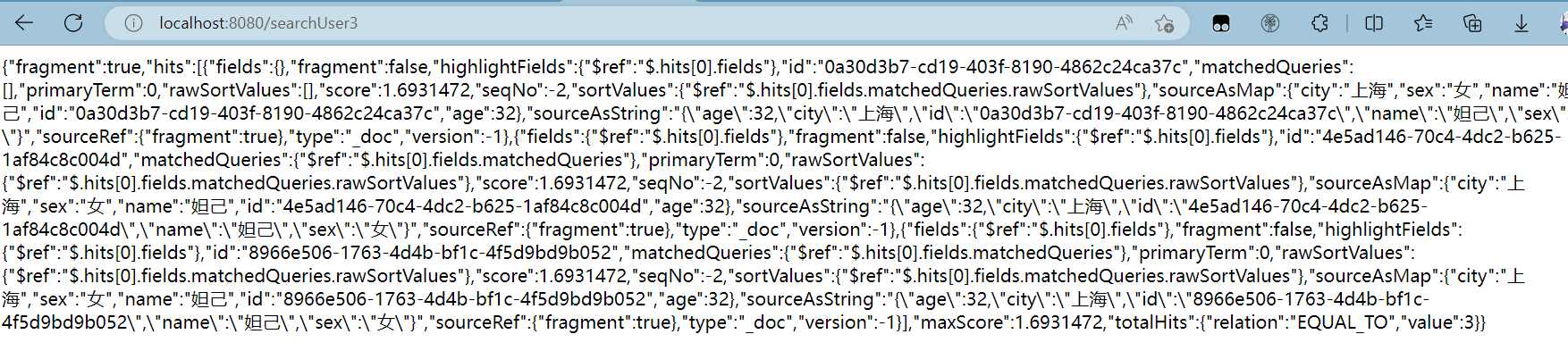
@GetMapping("/searchUser3")
public String searchUser3() throws IOException {
return service.searchDocument3("user","妲己",32);
}
 字符匹配OR精准查询
字符匹配OR精准查询
原始查询语句
GET user/_search
{
"query": {
"bool":{
"should": [
{
"match_phrase": {
"name": "妲己"
}
},
{
"term": {
"age": "32"
}
}
]
}
},
"from":0,
"size":10
}服务层
// 文档分词搜索OR精确查询
public String searchDocument4(String indexName,String name,Integer age){
//2 构建搜索请求
SearchRequest searchRequest = new SearchRequest().indices(indexName);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//3 构建复杂的查询语句
BoolQueryBuilder bq=QueryBuilders
.boolQuery()
//分词匹配
.should(QueryBuilders.matchPhraseQuery("name",name))
//精确匹配
.should(QueryBuilders.matchQuery("age",age));
//4 填充搜索语句
searchSourceBuilder
.query(bq)
.from(0)
.size(5);
//4 填充搜索内容
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = null;
try {
//5 执行搜索操作
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
//6 返回值
return JSON.toJSONString(searchResponse.getHits());
}控制层
@GetMapping("/searchUser4")
public String searchUser4() throws IOException {
return service.searchDocument4("user","妲己",22);
}结果

模糊查询
原始语句
GET user/_search
{
"query": {
"wildcard": {
"city": {
"value": "上*"
}
}
}
} // 文档模糊查询
public String searchDocument5(String indexName,String city){
//2 构建搜索请求
SearchRequest searchRequest = new SearchRequest().indices(indexName);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//3 构建模糊查询的语句
WildcardQueryBuilder bq=QueryBuilders
.wildcardQuery("city",city);
//4 填充搜索语句
searchSourceBuilder
.query(bq);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = null;
try {
//5 执行搜索操作
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
//6 返回值
return JSON.toJSONString(searchResponse.getHits());
} @GetMapping("/searchUser5")
public String searchUser5() throws IOException {
return service.searchDocument5("user","上*");
}结果
 OK! 下一节我们学习使用ORM框架对ES进行操作,就不用这么麻烦了,哈哈,欢迎订阅我,谢谢谢谢
OK! 下一节我们学习使用ORM框架对ES进行操作,就不用这么麻烦了,哈哈,欢迎订阅我,谢谢谢谢
参考 看完这篇还不会 Elasticsearch 搜索,那我就哭了!