0. 各种优化器介绍
参考这个博客: 各种优化器SGD,AdaGrad,Adam,LBFGS都做了什么?
1.优化器选择(优先选择以下三个)
1.0. 代码使用pytorch
1.1. SGD+Momentum
optimer = optim.SGD(model.parameters(), lr=0.1, weight_decay=0.2, momentum=0.9, nesterov=True)
- weight_decay:L2正则化惩罚系数
- momentum:惯性动量
- nesterov:就是Nesterov Accelerated Gradient这个优化器,防止按照惯性走的太快,会衡量一下梯度做出修正
- 以上超参数需要调参
1.2. Adam
optimer= optim.Adam(model.parameters(), lr=0.1, weight_decay=0)
- 为不同参数产生自适应的学习速率
- 没有L2正则化
1.3. AdamW(Adam+L2正则)
optimer = optim.AdamW(model.parameters(), lr=0.1, weight_decay=0.2)
2. 学习率更新
手动设置的学习率更新。用的比较少,可以结合SGD使用。
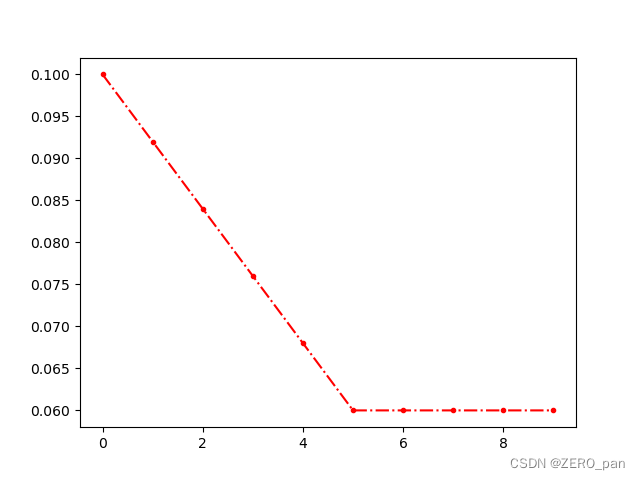
step1.设置一个动态学习率
optimer = optim.SGD(model.parameters(), lr=0.1, weight_decay=0.2, momentum=0.9, nesterov=True)
scheduler = optim.lr_scheduler.LinearLR(optimer , start_factor=1.0, end_factor=0.6, total_iters=5)
start_factor:开始的权重系数
end_factor:结束的权重系数
total_iters:迭代系数
step2.在更新模型参数的同时,更新学习率
optimer.step()
scheduler.step()
step3.学习率
- 0.1*1.0=0.1
- 0.1*0.9=0.09
- 0.1*0.8=0.08
- 0.1*0.7=0.07
- 0.1*0.6=0.06
- 0.06
- 0.06
- 不再改变