文章目录
项目简介
我们的目的是构建一个花样滑冰智能解析系统,解析部分是一个视频分割任务,不过基于的是骨骼点特征,这是该领域尚未涉足的方向。其余部分通过unity完成。
骨骼点特征的提取
我们的骨骼点特征的提取调用的是OpenPose的API,其能够对每个人提取出25个骨骼点,内容是二维坐标及其置信度的三维特征。我们通过置信度选择最有可能为滑冰选手的一组骨骼点。
该API参考的是论文[1]。接下来,我们会对这篇论文进行一些介绍,可以参考这篇文章。
概述
本文提出了一种检测2D图像中多人的、姿态的方法。
常见的思路是先识别出身体部位,然后再将这些部位连接起来,本文也是这个思路。
该论文的优势是在保证精度的情况下,其速度得到了较大的优化。
具体而言:Part Affinity Fields(PAF,部分亲和场),这是一种非参数的表征方式,用于学习身体部位和个体之间的关系。
Introduction
识别人体姿态的挑战有:
- 每幅图像的人数不确定,且会出现在任何位置;
- 人与人之间的相互作用,会造成空间十分复杂;
- 运行的复杂性随着人数的增多而增大,这使得实时性比较困难。
Method
总体流程为:
- 输入图像;
- 用VGG-19进行图像的特征提取;
- 将其送入two-branch multi-stage CNN,CNN_S用于识别关节点,CNN_L用于识别关节点之间的联系;
- 通过CNN_L的输出将CNN_S的输出连起来;
two-branch multi-stage CNN
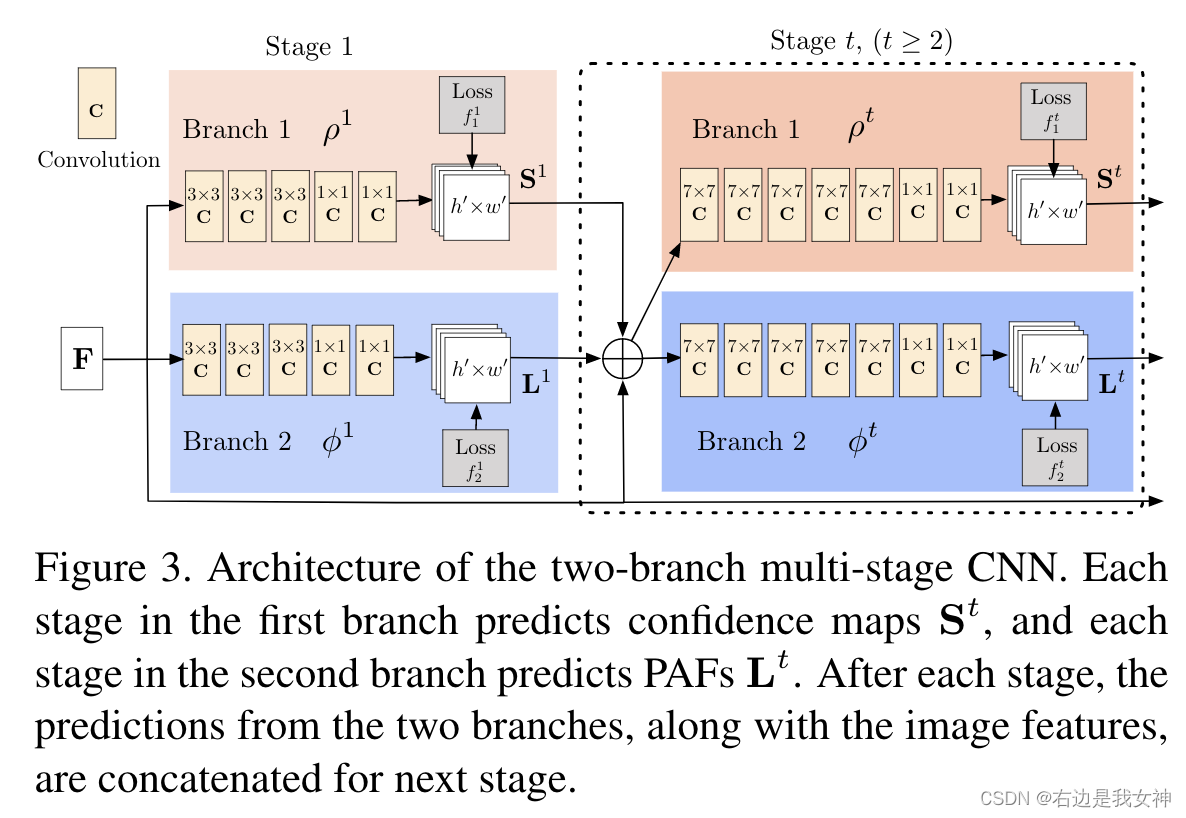
CNN_S输出 S t S_t St是关节点置信图;CNN_L输出 L t L_t Lt是PAFs。
损失函数为:

W的存在是因为GT不一定有确切标注,这使得损失函数的值很大,于是我们令这些位置的w为0。
之后通过公式进行拼接即可,具体而言,是将节点、 边进行合适的组合。
花样滑冰数据集(MCFS)
我们的数据集采用的是本实验室在[2]中提出的数据集。其中既包含了骨骼点数据也包含了I3D数据。
其中,提出了当前数据集存在的三大缺陷:
- 大部分仅包含粗粒度语义信息,这无法胜任细粒度任务。比如说50Salads中的切黄瓜、切芝士,关注的动作都是比较显著的。一旦涉及到横切黄瓜、竖切黄瓜这样的动作就是比较不那么具有关注度。
- 当前的数据集中,场景和工具需要参与到标签的预测当中,因为比如“切黄瓜”和“切番茄”这样的标签就需要注意物品。但是在大部分应用中注意人体的姿态才是重要的,我们需要一款数据集能够让模型更加注意人体的姿态。
- 不同动作的速度差异很小,微小的速度变化很难带来帧级别特征的改变,所以大部分数据集的难度不高,换句话说,从长达几十秒的视频中识别几秒的动作是一个值得研究的挑战。
MCFS的优点和挑战在于:
- 在标注label时分了很多层次,这样使得该数据集同时包含细粒度和粗粒度的语义信息;
- 额外提供了骨骼点特征;
- 标签只涉及人体姿态且背景单一,迫使模型关注人体运动;
- 动作的速度持续时间差异很大;
- 类别之间高度相似。
我们的方法
我们所期待的系统是能够识别细粒度的语义信息的。所以这加剧了motion speed and duration和similarity of category这两个问题。
因此我们需要一个模型能同时关注动作的时间变化和动作本身的差异。
另外,因为滑冰的动作更强调于动作本身,所以选择骨骼点进行分析会优于I3D特征。
但是当前大部分的能够分析骨骼点的模型都是针对视频识别的,目前还没有应用在视频分割任务中的模型。
我们的思路是先用骨骼点分析模型提取特征,之后进入视频分割模型(MSTCN)来得到逐帧的标签。
DSTA
关于骨骼点分析模型,我们选取的是DSTA[3],可以参考这篇文章。
Introduction
我们只知道骨骼点的位置,但是要想学习到他们之间的连接关系,常用的方式是手工编写规则。显然这不是最好的选择。本文基于注意力机制提出了自动学习的模型。
根据注意力网络发现骨骼点数据关联的难点有三个:
- 原始的自注意力机制的输入是序列数据,而骨骼点数据同时存在与空间是时间维度。有一种简单的方法是将时空数据展平成一个单一的序列(比如说骨骼点数据是(T,25,3),我们将其展开变成(T*25,3))。这样的策略将时间和空间同等对待了。本文的想法是在(25,3)内用一个自注意力,在(T,d)中用一个自注意力。这样分解为了时间注意力和空间注意力。为了平衡空间和时间的独立性和互动性,设计了三种策略
- 当将骨骼点送入注意力网络时,没有预定义的顺序或结构。为了给每个关节提供一个唯一的标记,引入一种位置编码技术。分为了空间编码和时间编码。
- 基于先验知识的基础上,加入适当的正则化,可以减少过拟合问题,提高模型的泛化性能。这是基于每一帧骨骼点语义意义的固定性,因此这仅用在空间维度。
Method
时空注意力模块
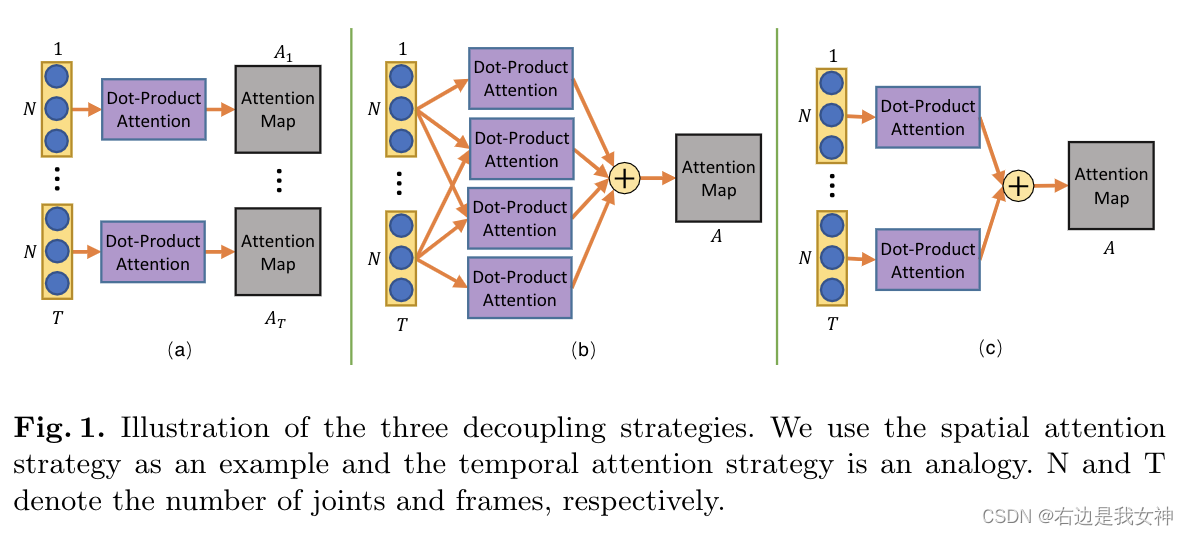
输入的骨骼点数据是(N,T,C),有个老兄就说,干脆把骨骼点和时间一起排列成一个序列,这样就直接能用上Transformer的自注意力机制了。
但是吧,时间和空间的信息能混为一谈吗?显然不行。所以说就有了三种策略。
- 每个帧都给算一个注意力矩阵: A t = s o f t m a x ( σ ( X t ) ϕ ( X t ) ′ ) A^t=softmax(\sigma(X_t)\phi(X^t)') At=softmax(σ(Xt)ϕ(Xt)′);
- 两两帧之间算一个注意力矩阵然后加起来共享: A t = s o f t m a x ( ∑ t T ∑ τ T ( σ ( X t ) ϕ ( X τ ) ′ ) ) A^t=softmax(\sum_t^T \sum_\tau^T(\sigma(X_t)\phi(X_\tau)')) At=softmax(∑tT∑τT(σ(Xt)ϕ(Xτ)′))
- 每个帧都给算一个注意力矩阵然后平均一下共享: A t = s o f t m a x ( ∑ t T σ ( X t ) ϕ ( X t ) ′ ) A^t=softmax(\sum_t^T\sigma(X^t)\phi(X_t)') At=softmax(∑tTσ(Xt)ϕ(Xt)′)
空间注意力的输入是 X t ∈ R N × C X_t\in R^{N\times C} Xt∈RN×C,得到的注意力矩阵 A t ∈ R N × N A^t\in R^{N\times N} At∈RN×N。
时间注意力的输入是 X n ∈ R T × C X_n\in R^{T\times C} Xn∈RT×C,得到的注意力矩阵 A n ∈ R T × T A^n\in R^{T\times T} An∈RT×T。
解耦的位置编码
编码的公式用的是Transformer的。
对于空间编码,同一帧中的关节进行顺序编码,不同帧中的相同关节具有相同的编码;
对于时间编码,同一帧中的关节有相同的编码,不同帧中的相同关节按顺序编码。
空间全局正则化
有一个全局注意力图被加到了所学到的注意力图当中去,这个注意力图它代表了人体关节的关系模式。
另外我们还有一个参数 α \alpha α来平衡这个正则化矩阵。
完整的注意力模块
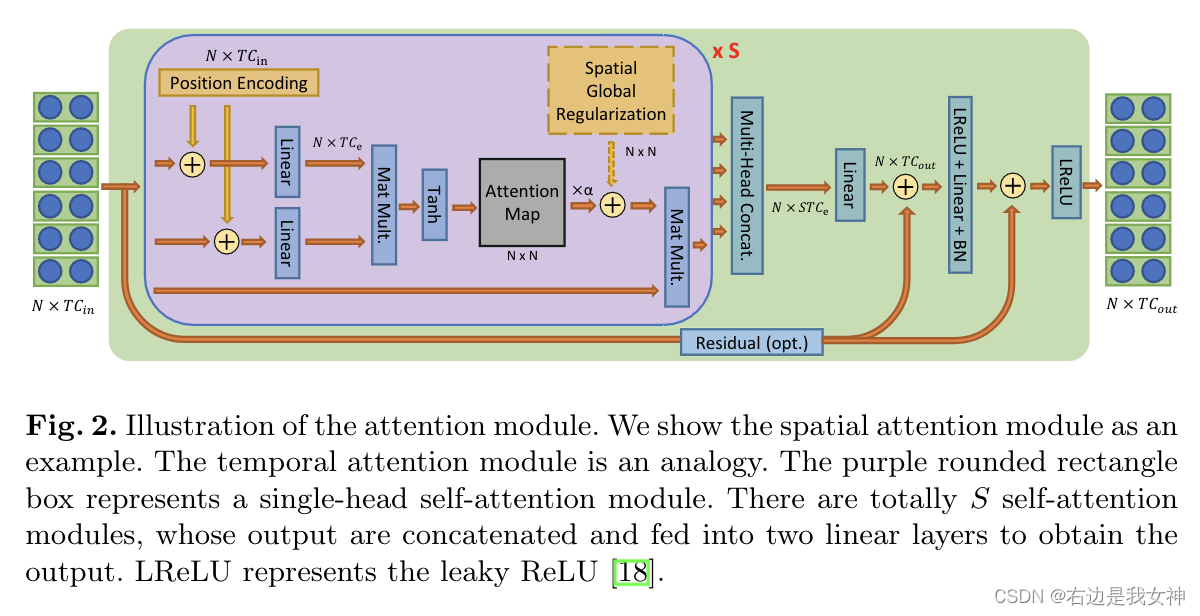
上图就是一个注意力模块,和Transformer的结构很相似哦。
- 输入 X ∈ R N × C i n X\in R^{N\times C_{in}} X∈RN×Cin和空间编码相结合;
- 被两个线性映射函数编码成 X ∈ R N × C e X\in R^{N\times C_e} X∈RN×Ce,这有助于减少冗余的特征;
- 然后按照第三种策略计算注意力矩阵,加入空间正则化后和V进行矩阵乘法后输出;
- 之后进入FFN,得到最后的结果。
整体架构
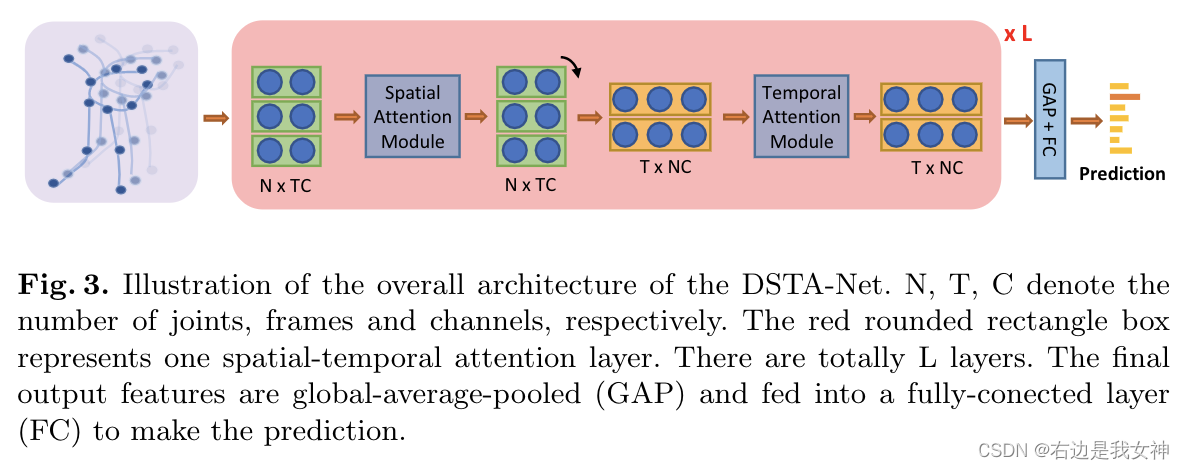
数据解耦
空间信息是统一框架内两个不同关节的差异,主要包含不同关节之间的相对位置关系;
时间信息是两个具有相同空间意义的关节在不同帧中的差异,主要描绘一个关节在时间维度上的运动轨迹。
此外,对于时间流,还进行了高帧速率采样和低帧速率采样来计算时间运动。
最后,我们将时空流、空间流、快速时间流和慢速时间流这四个模型分别训练,得到的结果取均值。
ETSN
关于ETSN的介绍可以参考这篇文章。
GCN-ETSN(代码)
整体流程
def forward(self, x):
if self.training:
# # for training
outputs = []
if self.GCN != None:
# 修正形状
#x = x.view(1,25,2,-1).permute(0, 2, 3, 1)
x = x.view(1,25,2,-1).permute(0, 2, 3, 1) # B,C,T,N
# GCN模型
x = self.GCN(x)
# 修正形状
x = x.permute(0, 3, 1, 2).contiguous().view(1, self.in_channel, -1)
# Prediction
out = self.stage1(x)
outputs.append(out)
# Refine(Dilated TCN or ETSPNet)
if self.stages is not None:
for stage in self.stages:
out = stage(F.softmax(out, dim=1))
outputs.append(out)
return outputs
else:
# for evaluation
if self.GCN != None:
x = x.view(1,25,2,-1).permute(0, 2, 3, 1)
x = self.GCN(x)
x = x.permute(0, 3, 1, 2).contiguous().view(1, self.in_channel, -1)
out = self.stage1(x)
if self.stages is not None:
for stage in self.stages:
out = stage(F.softmax(out, dim=1))
return out
STAttentionBlock
位置编码
class PositionalEncoding(nn.Module):
def __init__(self, channel, joint_num, time_len, domain):
super(PositionalEncoding, self).__init__()
self.joint_num = joint_num
self.time_len = time_len
self.domain = domain
if domain == "temporal":
# temporal embedding
pos_list = []
for t in range(self.time_len):
for j_id in range(self.joint_num):
pos_list.append(t)
elif domain == "spatial":
# spatial embedding
pos_list = []
for t in range(self.time_len):
for j_id in range(self.joint_num):
pos_list.append(j_id)
position = torch.from_numpy(np.array(pos_list)).unsqueeze(1).float()
# pe = position/position.max()*2 -1
# pe = pe.view(time_len, joint_num).unsqueeze(0).unsqueeze(0)
# Compute the positional encodings once in log space.
pe = torch.zeros(self.time_len * self.joint_num, channel)
div_term = torch.exp(torch.arange(0, channel, 2).float() *
-(math.log(10000.0) / channel)) # channel//2
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.view(time_len, joint_num, channel).permute(2, 0, 1).unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x): # nctv
x = x + self.pe[:, :, :x.size(2)]
return x
在self.GCN中,我们只采用了DSTA中的STAttention模块。
class STAttentionBlock(nn.Module):
def __init__(self, in_channels, out_channels, inter_channels, num_subset=2, num_node=25, num_frame=32,
kernel_size=1, stride=1, glo_reg_s=True, att_s=True, glo_reg_t=False, att_t=False,
use_temporal_att=False, use_spatial_att=True, attentiondrop=0, use_pes=True, use_pet=False):
super(STAttentionBlock, self).__init__()
self.inter_channels = inter_channels
self.out_channels = out_channels
self.in_channels = in_channels
self.num_subset = num_subset
self.glo_reg_s = glo_reg_s
self.att_s = att_s
self.glo_reg_t = glo_reg_t
self.att_t = att_t
self.use_pes = use_pes
self.use_pet = use_pet
self.num_node = num_node
pad = int((kernel_size - 1) / 2)
self.use_spatial_att = use_spatial_att
# 空间注意力
if use_spatial_att: #T
atts = torch.zeros((1, num_subset, num_node, num_node))
self.register_buffer('atts', atts)
# self.pes = PositionalEncoding(in_channels, num_node, num_frame, 'spatial')
self.ff_nets = nn.Sequential(
nn.Conv2d(out_channels, out_channels, 1, 1, padding=0, bias=True),
nn.BatchNorm2d(out_channels),
)
if att_s: #T
self.in_nets = nn.Conv2d(in_channels, 2 * num_subset * inter_channels, 1, bias=True)
self.alphas = nn.Parameter(torch.ones(1, num_subset, 1, 1), requires_grad=True)
if glo_reg_s: #T
self.attention0s = nn.Parameter(torch.ones(1, num_subset, num_node, num_node) / num_node,
requires_grad=True)
self.out_nets = nn.Sequential(
nn.Conv2d(in_channels * num_subset, out_channels, 1, bias=True),
nn.BatchNorm2d(out_channels),
)
else:
self.out_nets = nn.Sequential(
nn.Conv2d(in_channels, out_channels, (1, 3), padding=(0, 1), bias=True, stride=1),
nn.BatchNorm2d(out_channels),
)
self.use_temporal_att = use_temporal_att
if use_temporal_att:
attt = torch.zeros((1, num_subset, num_frame, num_frame))
self.register_buffer('attt', attt)
self.pet = PositionalEncoding(out_channels, num_node, num_frame, 'temporal')
self.ff_nett = nn.Sequential(
nn.Conv2d(out_channels, out_channels, (kernel_size, 1), (stride, 1), padding=(pad, 0), bias=True),
nn.BatchNorm2d(out_channels),
)
if att_t:
self.in_nett = nn.Conv2d(out_channels, 2 * num_subset * inter_channels, 1, bias=True)
self.alphat = nn.Parameter(torch.ones(1, num_subset, 1, 1), requires_grad=True)
if glo_reg_t:
self.attention0t = nn.Parameter(torch.zeros(1, num_subset, num_frame, num_frame) + torch.eye(num_frame),
requires_grad=True)
self.out_nett = nn.Sequential(
nn.Conv2d(out_channels * num_subset, out_channels, 1, bias=True),
nn.BatchNorm2d(out_channels),
)
else:
self.out_nett = nn.Sequential(
nn.Conv2d(out_channels, out_channels, (7, 1), padding=(3, 0), bias=True, stride=(stride, 1)),
nn.BatchNorm2d(out_channels),
)
if in_channels != out_channels or stride != 1:
if use_spatial_att:
self.downs1 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=True),
nn.BatchNorm2d(out_channels),
)
self.downs2 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=True),
nn.BatchNorm2d(out_channels),
)
if use_temporal_att:
self.downt1 = nn.Sequential(
nn.Conv2d(out_channels, out_channels, 1, 1, bias=True),
nn.BatchNorm2d(out_channels),
)
self.downt2 = nn.Sequential(
nn.Conv2d(out_channels, out_channels, (kernel_size, 1), (stride, 1), padding=(pad, 0), bias=True),
nn.BatchNorm2d(out_channels),
)
else:
if use_spatial_att:
self.downs1 = lambda x: x
self.downs2 = lambda x: x
if use_temporal_att:
self.downt1 = lambda x: x
self.downt2 = lambda x: x
self.soft = nn.Softmax(-2)
self.tan = nn.Tanh()
self.relu = nn.LeakyReLU(0.1)
self.drop = nn.Dropout(attentiondrop)
def forward(self, x):
N, C, T, V = x.size() # N batch_size C channels T frame_num V joint_num 1 2 xxxx 25
# 先进入空间注意力
if self.use_spatial_att: #T
# 空间注意力矩阵
attention = self.atts
# 进行位置编码
if self.use_pes:
self.pes = PositionalEncoding(self.in_channels, self.num_node, T, 'spatial').cuda(x.get_device())
y = self.pes(x)
else:
y = x
if self.att_s: #T
# in_nets将c -> 2*num_subset*inter_channels
# q和k都是从y中来的 q:nsctv k:nsctv
q, k = torch.chunk(self.in_nets(y).view(N, 2 * self.num_subset, self.inter_channels, T, V), 2,
dim=1) # nctv -> n num_subset c'tv
# Attention(Q,K,V) = softmax(QK^T/C^(1/2)) 这里是把ct看做了c softmax变为tan
# attention:nsvv
attention = attention + self.tan(
torch.einsum('nsctu,nsctv->nsuv', [q, k]) / (self.inter_channels * T)) * self.alphas
#print(attention.shape)
# 空间正则化 简简单单加了个矩阵
if self.glo_reg_s: #T
attention = attention + self.attention0s.repeat(N, 1, 1, 1)
attention = self.drop(attention)
y = torch.einsum('nctu,nsuv->nsctv', [x, attention]).contiguous() \
.view(N, self.num_subset * self.in_channels, T, V)
y = self.out_nets(y) # nctv
y = self.relu(self.downs1(x) + y)
y = self.ff_nets(y)
y = self.relu(self.downs2(x) + y)
else:
y = self.out_nets(x)
y = self.relu(self.downs2(x) + y)
if self.use_temporal_att:
attention = self.attt
if self.use_pet:
z = self.pet(y)
else:
z = y
if self.att_t:
q, k = torch.chunk(self.in_nett(z).view(N, 2 * self.num_subset, self.inter_channels, T, V), 2,
dim=1) # nctv -> n num_subset c'tv
attention = attention + self.tan(
torch.einsum('nsctv,nscqv->nstq', [q, k]) / (self.inter_channels * V)) * self.alphat
if self.glo_reg_t:
attention = attention + self.attention0t.repeat(N, 1, 1, 1)
attention = self.drop(attention)
z = torch.einsum('nctv,nstq->nscqv', [y, attention]).contiguous() \
.view(N, self.num_subset * self.out_channels, T, V)
z = self.out_nett(z) # nctv
z = self.relu(self.downt1(y) + z)
z = self.ff_nett(z)
z = self.relu(self.downt2(y) + z)
else:
z = self.out_nett(y)
z = self.relu(self.downt2(y) + z)
return z
参考文献
[1] Cao Z, Simon T, Wei S E, et al. Realtime multi-person 2d pose estimation using part affinity fields[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 7291-7299.
[2] Liu S, Zhang A, Li Y, et al. Temporal Segmentation of Fine-grained Semantic action: A Motion-Centered Figure Skating Dataset[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(3): 2163-2171.
[3] Shi L, Zhang Y, Cheng J, et al. Decoupled spatial-temporal attention network for skeleton-based action recognition[J]. arXiv preprint arXiv:2007.03263, 2020.