导读
增量学习(Incremental Learning),亦称为持续学习(Continual Learning)或终身学习(Life-Long Learning),是一种机器学习方法,它允许模型通过对新数据进行持续学习而不是重头训练整个模型。这种方法允许模型不断地学习新的知识,并在不断实际复杂多变的环境变化。
先前绝大多数增量学习方法均高度依赖于标签数据集,这必然会限制增量学习技术在实际生活中的应用。因此,本文将从高效标签的角度出发,以一种崭新的视角,带领大家从零开始踏入增量学习领域。
在本文的开始,我们会向大家介绍的介绍下引入增量学习的必要性,继而引出最新的三种能够有效利用有效标签数据范式的增量学习方法,包括半监督学习、小样本学习以及自监督学习。其次,我们将针对这三大范式进行一个全面的调研,让大家对这个领域的整个发展脉络有一个清晰的认识。文章的最后,我们会集中讨论当前增量学习存在的一些局限性以及结合现有的技术给出一些值得探讨的研究方向,同时,为了帮助大家更加深入的学习增量学习,一些必要的增量学习框架(基于Pytorch构建)以及最前沿的增量学习方法也将给到大家去实践,进一步提升自身的能力,形成完整的闭环,非常感谢大家对 CVHub 的支持与鼓励。
动机
聊到增量学习,不得不提的一个反例必然是非增量学习,其假定模型每次都可以同时访问每个类别的所有情况下的图像。显然,这是不切实际的。下面简要概括下它的三大局限性:
-
模型仅能识别固定类别的物体;
-
模型无法训练所有背景下的数据(例如不同季节、不同天气、不同光照条件等);
-
模型一旦部署无法在线利用新数据(除非你重新上线一版);
由此可见,引入增量学习是非常有必要的。

Incremental learning examples.
上图提供了三种不同形式的增量学习范式:
-
Semi-Supervision:半监督可以将有限的标记数据与丰富的未标记数据相结合,通过伪标签监督减少对真实标签的依赖程度;
-
Few-shot-Supervision:小样本监督学习则可以扩展预训练的分类器来减少标签依赖,仅利用极少的标记实例;
-
Self-Supervision:自监督学习是通过指定前置文本任务,以舍弃对标签的依赖;
在这里,目标是通过增量学习匹配同一输入图像的不同视图(例如裁剪、旋转和颜色抖动)来获取表征。说一千道一万,可能许多小伙伴心中都有一个疑问:
既然增量学习这么有用,为什么实际应用中却鲜有人用?
学术界通用的解释套路是灾难性遗忘现象。怎么理解呢?大致意思就是说在观察更多增量任务时,模型在先前任务上的性能便会下降,中文有个词形容的非常好——此长彼消,写到这里不得不感慨古人的智慧。为了解决这个问题,有两种典型方法可以缓解,即正则化(regularization)和经验回放(experience replay)。

OWM方法原理示意图
引入了正则化技术可以有效限制神经网络权重在学习任务中的突然漂移,通俗点理解便是简单地通过 来惩罚变化的范数。而经验回放则是将先前的数据适量的加入当前的增量任务来缓解模型的“健忘”程度。然而,还有一个点可能容易被忽略,那便是可扩展性。毕竟当前的增量学习仍然需要大量的标注数据才能获得可观的性能。除了以上两种方式,还有基于知识蒸馏的方法,基于特征回放的方法以及基于网络结构的方法等,文章篇幅有限,此处不再描述。

因此,如何高效利用标签成为了该领域亟需解决的问题。这一点大家比较熟知的应该是迁移学习,该方法建立在大规模预训练模型的基础上,只需利用有限的数据便能有效的将大模型学习到的知识迁移到个人任务上,在实际当中应用非常广泛,几乎成了标配。有了这种成功的典范,我们是否可以思考进一步将这种模式引入到增量学习当中去构建一个更大规模、能够高效利用标签的增量学习器呢?何乐而不为。
在正式介绍这三种范式之前,让我们先简单的了解增量学习任务的主要评估指标。增量学习工作中一般通过绘制增量准确率曲线(incremental accuracy curve)和遗忘率曲线(incremental forgetting curve)来评估性能的优劣。其中涉及到的两个主要指标便是准确率(accuracy)和遗忘率(forgetfulness)。
-
Accuracy: 准确率衡量的是所有学习任务的测试准确性。

简单的解释下,上述公式表示的是在第 t 个增量阶段,增量准确率指的是当前的模型在所有已见类别上的分类准确率A_t。而不同阶段的增量准确率常常以增量准确率曲线展示。
-
Forgetfulness: 遗忘率衡量的是学习增量任务时平均性能下降程度。

上述公式我们可以简单的理解为模型在学习完当前任务之后在先前任务上的分类准确率。
下表[1]简单的总结了几类不同的增量学习方法,下面我们将基于此表为大家详细的介绍关于 IL 的那点事。

半监督增量学习
首先,让我们先学习下半监督式的增量学习,其旨在通过利用未标记的数据来减少对标签的依赖。常规的做法是先利用一小部分带有标签的数据集训练出一个深度学习模型,然后利用该模型对未标记的数据打上标签。通常,我们将这种用非人工标注的标签信息称之为——伪标签(pseudo labels)。
因此,根据未标记数据的类型,我们可以简单的划分为三种类型:
-
Within-data,即属于同一份数据集内的没有打标签的那部分数据; -
Auxiliary-data,即辅助数据,例如大家从网络上爬下来的数据; -
Test-data,即最简单的测试集数据
其中,Within-data 需要模型从头开始训练,而另外两种方式则是建立在预训练好的模型基础之上。下面分别为大家介绍下典型的方法。
Learning from Within Data
CNNL[2]

CNNL,即连续神经网络学习,是半监督和增量学习交叉领域的早期工作之一。作者在标记好的数据集上训练一个基础的卷积神经网络模型,然后将其用于在未标记数据集上生成伪标签。最后,通过在伪标签上微调增量学习器以实现自训练(self-training)的过程。
DistillMatch[3]

与需要大量内存预算的标准回放方案不同,DistillMatch 中探索了无标签数据流作为回放的潜力,并显著降低了所需的内存预算。与之前的工作需要访问与环境无关的外部数据流不同,作者认为数据流是持续学习代理环境的产物。此外,通过对域外检测器进一步的优化,从而识别出与当前增量学习任务无关的数据分布,以减轻对先前类别的遗忘。
值得注意的是, 知识蒸馏最初是为模型压缩而设计的。随着LwF[4](Learning without forgetting)方法首次将其应用于增量学习, 知识蒸馏损失已成为了众多增量学习方法的基础模块。如下图所示,后续的工作主要可分为基于重要特征蒸馏,基于样本关系蒸馏和基于辅助数据的蒸馏,这些方法有效的改进类别增量学习中的知识蒸馏策略。

Knowledge distillation strategies in class incremental learning
ORDisCo[5]

具有判别器一致性的在线回放(online replay)遵循生成回放策略来回放数据和标签。ORDisCo利用标记数据来训练条件 GAN 生成器,并采用未标记数据作为区分 real-fake 的额外示例。此外,为了进一步提高增量学习任务的一致性,作者还对判别器权重的突变部分进行了惩罚(可理解为加正则)。
MetaCo[6]

MetaCon, 即Meta-Consolidation,是将 ORDisCO 的生成重放方案扩展到元学习设置。作者没有直接训练条件 GAN 进行生成回放,而是优化了生成 GAN 权重的条件超网络。作者以当前任务的语义词嵌入为条件,将超网络参数化为变分自编码器(Variational Auto-Encoder, VAE)。为了稳定超网络,他们存储增量学习类的一阶统计数据以更好的进行数据回放。
PGL[7]

PGL 全称是 Pseudo Gradient Learners,即伪梯度的学习器,其基于元学习预测每个输入的梯度。作者声称伪标签的使用会给分类器带来负优化,导致梯度的错误累积,同时其性能会随时间下降。因此,本文方法通过预测梯度而非标签,该模型不像伪标签那样与一组预定义的类相关联,同时能够利用分布外的数据来提高性能。
Learning from Auxiliary Data
DMC[8]

DMC,Deep Model Consolidation,即深度模型整合应该是最早利用未标记的辅助数据来减轻灾难性遗忘的代表作之一。作者首先在标记好的数据集上训练深度分类器,然后用于在辅助数据上生成伪标签。其中,伪标签充当当前模型和先前模型之间的正则化器,以减少对先前“看到”的类的遗忘。
CIL-QUD[9]

CIL-QUD 是一种使用查询未标记数据的类增量学习方法,其建立在 DMC 的基础上,但是采用基于检索的方法。作者在内存中将每个增量类的少量实例存储为查询 Anchor。查询锚用于在辅助数据集中检索视觉上相似的样本,然后用于记忆重放。
Learning from Test Data
CoTTA[10]

CoTTA,Continual Test-Time Adaptation,即在推理时调整预训练的深度分类器。这种情况是很常见的,以自动驾驶为例,想象一辆自动驾驶汽车在不断变化的天气条件下持续行驶,这种情况下我们无法保证喂给模型的数据能够覆盖各类天气状况。因此,这种自适应的能力是非常有必要的,尤其是当测试数据与原始训练源不同并且源数据不再可用时。为了解决这个新问题,作者提出了一种基于正则化的方法,通过在同一输入的多个增强中强制执行一致性正则化,以及对一些网络参数进行选择性微调。
NOTE

NOTE,即No i.i.d. TEst-time adaptation,即非独立同分布的测试时适应,是将 COTTA 进一步扩展到现实场景的工作,其后续测试示例具有高度的时间相关性。作者声称,在这种情况下,依赖伪标签形式的 BN 统计可能会严重地使学习器偏向当前批次。因此,本文方法采用 IN 替代 BN。值得一提的是,相对 CoTTA 其性能要好得多。此外,相关的工作还有去年发表在 CVPR 2022 上的 LAME[11],有兴趣的小伙伴也可以自己的读读原文。

Incremental Learning with Semi-Supervision
小样本增量学习
在增量学习任务的训练期间,小样本监督学习器使用来自新类别的少量示例更新预训练模型。在这方面,小样本监督方法同时解决了两个基本挑战:
-
Overfitting to Novel Categories
众所周知,如果我们直接基于这极其有限的训练样本去重头优化模型,那必将导致我们的模型会过度拟合这些样本。为此,我们可以在增量训练期间将已经学习的分类器权重与相关的新类别相关联。这里,根据不同关联机制,我们可以简单的将该任务划分为几大类,即基于图的方法,基于聚类的方法以及基于网络架构的方法。此外,一些技术还涉及到利用语义词嵌入来识别语义相关类别以进行知识的迁移。
-
Forgetfulness of Base Categories
上面我们提过,学习新的类别可能会导致原有模型权重的“漂移”,从而导致最终的模型性能下降。解决此问题的两种有效技术包括通过度量学习目标进行正则化,例如在 CVPR 2020 曾经发表过的 anchor loss[12],或者简单地对基类数据进行内存回放。
Graph-Based Methods
TOPIC[13]

TOPIC,即 TOpology-Preserving knowledge InCrementer 是一种基于图的增量小样本学习器。作者将每个增量类视为一个新节点,将其插入到已存在的基础分类器嵌入的完全连接图中。它们根据成对关系将信息从基础分类器节点传播到新分类器的节点当中,同时通过分类器嵌入的相似度进行衡量。此外,为了防止图漂移并保留初始图拓扑,作者采用了 anchor loss 形式的度量学习进行正则化。
CEC[14]

CEC,即 Continually Evolving Classifier,是建立在 TOPIC 之上的方法,其利用了图注意力网络。其中,初始图随着传入的少量学习任务流不断迭代。作为一项新颖的增量学习任务,本文方法关注已经存在的语义相关类别,以构建分类器权重。最后,通过进一步从基础类别数据生成伪增量学习任务,增强了对新类别的学习能力。然而,CEC 整体的的重心更多地放在新类别的学习上,而不是保持原有类别的表现,这最终会加剧“健忘”。
Clustering-Based Methods
IDL-VQ[15]
增量深度学习向量化利用高斯混合将学习类别的视觉特征量化为参考向量质心。随后,任何传入的新类都由它们与现有参考向量的 soft similarity 进行表示。为了减少灾难性遗忘的现象,作者额外存储了每个类别的一个样本并在增量训练的期间进行回放。
SA-KD[16]

SA-KD 是一种语义感知知识蒸馏的方法,其利用 K-means 聚类来构建参考类质心,从而表示新的输入。最后,通过将表示投影到语义词嵌入空间,以进一步促进与基类的关联。
SUB-REG[17]

子空间正则化通过利用 QR 分解将基础分类器的嵌入投影到正交子空间。随后,测量新类输入和子空间向量之间的 soft similarity 以表示新类权重。最后,为了缓解权重漂移,额外引入了 L1 损失进行权重调节。
FACT[18]

Forward-Compatible Training 是当前小样本增量学习的 SOTA。论文作者首先展示了 few-shot 学习器的特征空间被预训练(即基础)类完全占据,没有为未来(即few-shot)类留下空间,因此限制了前向兼容性。为此,他们建议同时将输入图像分配给与基类正交的单独集群,从而有效地为新类别保留空间。最后,通过结合混合增强,FACT 有效提高了基础类和新类的性能。
Architectural Methods
FSLL[19]

Few-shot Lifelong Learning 的做法是从模型架构中选择一些权重来微调增量学习任务。如此一来,不仅可以限制模型容量同时防止过拟合,还能通过最小化学习任务之间的干扰来防止遗忘。最后,结合 L1 损失,FSLL 在多个基准测试中显着优于基于图架构的 TOPIC 方法。
C-FSCIL[20]
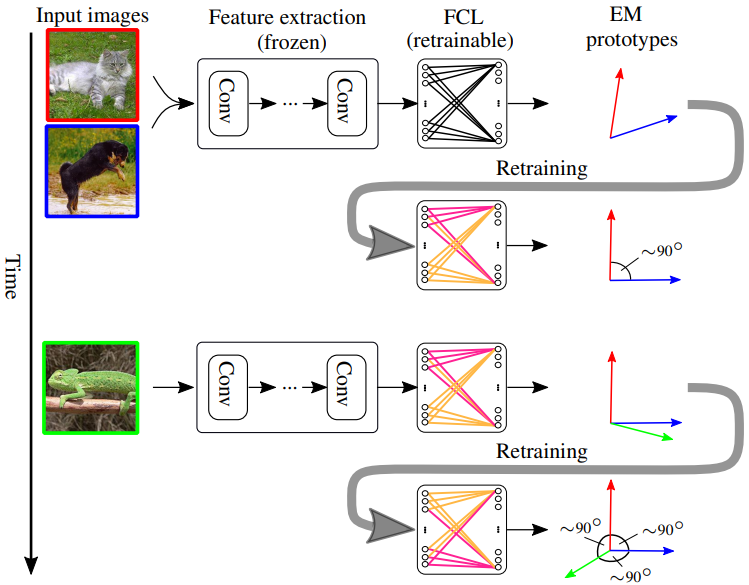
Constrained-FSCIL 是 CVPR 2022 新提出的一项小样本增量学习技术。作者使用带有传入任务流的新颖分类器嵌入来扩展架构。在这个过程中,通过在学习到的嵌入中施加准正交性,有效地减少了任务之间的干扰,间接缓解了遗忘现象。

自监督增量学习
基于自监督模式的增量学习主要有三种主要范式:
-
Pre-training
-
Auxiliary-training
-
Main-training
下面就这三块简单聊聊。
Pre-training
Pre-training 主要就是在增量学习任务开始之前先对主干网络预训练一波,大家可以理解为是一种“预热”操作。这方面的研究主要是建立在自监督预训练可以显著减少后续(迁移)学习任务中对标签监督的需求的想法之上。
SSL-OCL[21]

用于在线持续学习的自监督学习(SSL-OCL)方法提议在通过自监督进行增量训练之前预训练骨干网络的权重。通过这种方式,作者旨在充分利用预训练数据集带来的迁移学习能力。通过采用 MoCo-V2 和 SwAV 等方法的自监督预训练方式,本文方法获得了性能上的提升。
Auxiliary-training
辅助训练指的是在训练期间用自监督的方法提供监督信号,以获得更具辨别力的特征空间。这类方法建立在自监督学习任务可以向学习者提供额外的监督信号以防止过拟合的想法之上。
PASS[22]

Prototype-Augmented Self-Supervision(PASS) 是一种基于正则化的增量学习技术。该模型优化了每个增量类的单个原型,其中原型是通过原始标签进行监督学习的。为了提高模型的泛化能力并避免过拟合现象,作者引入了更多的数据增强技巧。例如,采用自监督标签增强(SLA)生成原始输入的四种不同变换角度([0°, 90°, 180°, 270°]),然后将其用作额外的前置文本任务来区分模型。作者展示了这种方法减轻了对先前学习的类的过度拟合,从而获得了更好的结果。
Main-training
这是一种完全基于自监督学习目标进行训练的方法,并在训练后通过线性探测对其进行评估。此类方法主要的核心思想是认为自监督可以完全取代人工标签。
Buffer-SSL[23]

Buffer-SSL 即缓冲自监督学习,是一种基于记忆的方法,它是在现成的自监督算法 SimSiam 进行扩展的并推广到增量学习任务当中。SimSiam 的一个主要弊端是无法保留以前学到的知识,因此 Buffer-SSL 为其补充了一个用于回放的内存缓冲区。一种简单的方法是将所有示例存储在内存中,但是这会导致内存开销太大,并且是对于视频帧这种帧之间存在高度的冗余性。为此,作者只存储簇质心,这减少了内存大小并增加了内存可扩展性。通过构建缓冲区可以显著缓解自监督表示的遗忘。
LUMP[24]

Lifelong Unsupervised Mixup 也是一种基于记忆的方法,利用混合增强来减轻健忘。具体来说,网络通过学习将输入实例与存储在内存中的先前学习任务中用到的的实例进行混合。这种思想比较简单,说白了就是回放此类示例来达到减少遗忘并提高性能的目的。
CaSSLe[25]

CaSSLe 是一种基于正则化的自监督增量学习方法。由于存储来自先前学习任务的数据会导致内存效率低下并且可能侵犯隐私的动机,本文方法转而学习在当前模型和过去模型之间提取自监督的表示。其中,蒸馏以预测方式执行,当前模型的特征会被投影到先前模型的特征空间。
PFR[26]

PFR,即投影函数正则化同样是一种基于正则化的技术,与 CaSSLe 非常类似。作者使用基于蒸馏的目标扩展了 Barlow-Twins 方法,学习将当前的视觉表示投射到先前的模型表示。此外,论文展示了具有 PFR 目标的 Barlow-Twins 表现出更低的遗忘和更高的准确性。

Incremental Learning with Self-Supervision
局限性
尽管上述三种高效的增量学习范式取得了一定的成就,但本身仍然存在一些局限性,接下来让我们简单的分析一波。
半监督
基于半监督范式的增量学习可以通过伪监督的形式利用部分标记数据。然而,伪标签的质量部分仍然取决于标记数据的数量和质量。为此,这些模型仍然需要提供大量标签才能正常工作,因此并没有从根本上解决问题。
不能理解的小伙伴可以思考下,伪标签是怎么得到的?还不是得训练出一个基础模型出来,这个模型训练得不好打出来的伪标签只会让模型表现得更糟糕。
此外,伪标签自带的噪声问题也会随着时间逐渐累计,尤其是对于长增量学习序列的任务来说更是致命的。一种潜在的补救措施是从伪标签转向伪梯度,但是梯度估计也可能随时间推移而发生改变。既然如此,是否存在一种没有任何形式的伪监督的情况下能够直接通过输入统计更新规范化参数的方法呢?让我们后面揭晓。
小样本
小样本学习主要涉及到在增量训练钱和增量训练期间均会利用到标签信息。其中,预训练部分的标签复杂度特别高,毕竟它前期仍然需要用到大量的元数据样本,这对于医学成像或视觉异常检测等这类数据匮乏的领域来说,严重限制了它们的作用。
此外,小样本学习范式在增量学习过程中通过冻结主干网络的权重以防止过拟合新晋少量样本的现象。虽然效果很好,但这种做法并不自然,因为人类是具备非常强大的泛化性能,可以利用极少的样本进行学习,例如看过一次的东西大部分人就能够记住这是件什么物品。
自监督
当自监督用于预训练或辅助训练时,自监督增量学习器的标签复杂性与普通增量学习器相当。使用自监督作为唯一的监督信号是在训练期间完全省略标签的关键。然而,单纯的自监督增量学习需要一个单独的标记线性探测阶段用于准确的评估模型迭代的效果,从而限制了它们的适用性。
此外,增量学习的自监督范式完全依赖于基于对比学习的方法来提取监督信号,例如 MoCo 等方法。然而,随基于掩码重建的 MAE 方法的提出,表明了基于重建的目标显然是优于基于对比学习所得到的的目标,这不失为一个新的探索方向。
展望
通过对以上几种增量学习方法的分析,我们可以进一步总结出更具备现实意义的一些可研究方向。
Mixed-Supervised Learning
混合监督学习在非增量学习是挺常见的一种形式,例如 ECCV 2020 中就出现过一篇《When does self-supervision improve few-shot learning?》的文章,作者便结合了自监督和小样本学习。

另外,也有半监督+小样本结合的监督形式,发表在 NeurIPS 2019 上的 《Learning to Self-Train for Semi-Supervised Few-Shot Classification》。因此,我们是否可以将这种思路借鉴到增量学习任务当中去呢?

Incremental Dense Learning
上面我们所列举的大多数例子均是围绕图像分类任务展开的。然而,对于语义分割这种密集型的预测任务而言,如何解决标签问题是一个棘手的问题,毕竟为图像中的每一个像素都赋予一个新的语义类别是个非常痛苦的工作,还真是谁行谁上。这里首先进行尝试的工作可能是 ICCV 2019 上的 《Recall: Replay-based continual learning in semantic segmentation》,作者通过为旧类重新创建不再可用的数据并概述背景类的内容修复方案来解决这些问题。

一种潜在的解决方案可以考虑引入弱监督的方式对增量目标进行分割,例如发表在 CVPR 2022 上的这篇文章《Incremental learning in semantic segmentation from image labels》便涉及到了。然而,与常规的分割模型相对,这种方式目前的性能还非常有限,大家可以看看如何去提升它。

Incremental Active Learning
在主动学习中,学习代理会选择最有影响力的示例,由人类专家进行注释。这显着降低了标记成本,因为只需一小部分示例足以训练一个好的模型。这方面的代表工作有《Towards robust and reproducible active learning using neural networks》,发表在 CVPR 2022 上。
神奇的是,主动学习在增量学习中几乎没有任何应用,你敢相信吗?然而,这种方法可以帮助选择一小撮范例来辅助半监督或小样本监督范式的增量学习,无论是从预训练还是增量训练的角度,值得一试。
Incremental Object Discovery
对于人类而言,我们几乎可以在不需要任何监督的前提下,展示出惊人的发现前所未见物体的能力,几乎不费吹灰之力便能够对新对象进行分组。然而,现有的增量学习方法普遍没有发现新对象的能力,几乎所有对象都需要被标记,哪怕是 few-shot.
然而,我们知道,这其实并不现实,毕竟真实世界每天都会出现千奇百怪的新生物体。为此,严格意义上来说,增量学习不仅需要具备从有限的标记样本中进行监督学习,还要有挖掘新对象的能力。因此,未来的一个终极研究目标必定是朝着类人方向迈进的,让我们拭目以待!
进阶
PyCIL[27]
PyCIL 是一个基于 Pytorch 构建的类别增量学习框架,其中不仅包含了如 EWC、iCaRL 等一批早期的经典代表性方法,还包含了一些最新的 SOTA 级别的 Class-IL 算法,希望能够帮助一些希望了解和研究相关领域的学者。目前该算法工具箱基于 MIT 协议开源,非常鼓励大家尝试!
Awesome IL Algorithms[28]
<Awesome Incremental Learning / Lifelong learning> 是一个持续更新的关于增量学习的仓库,大家如果需要查阅最新的论文,可以及时订阅。
Survey
-
Deep Class-Incremental Learning: A Survey (arXiv 2023)
-
A Comprehensive Survey of Continual Learning: Theory, Method and Application (arXiv 2023)
-
Continual Learning of Natural Language Processing Tasks: A Survey (arXiv 2022)
-
Continual Learning for Real-World Autonomous Systems: Algorithms, Challenges and Frameworks (arXiv 2022)
-
Recent Advances of Continual Learning in Computer Vision: An Overview (arXiv 2021)
-
Class-incremental learning: survey and performance evaluation (TPAMI 2022)
-
A continual learning survey: Defying forgetting in classification tasks (TPAMI 2021)
Papers
-
Online Bias Correction for Task-Free Continual Learning (ICLR2023)
-
Sparse Distributed Memory is a Continual Learner (ICLR2023)
-
Continual Learning of Language Models (ICLR2023)
-
Progressive Prompts: Continual Learning for Language Models without Forgetting (ICLR2023)
-
Is Forgetting Less a Good Inductive Bias for Forward Transfer? (ICLR2023)
-
Online Boundary-Free Continual Learning by Scheduled Data Prior (ICLR2023)
-
Incremental Learning of Structured Memory via Closed-Loop Transcription (ICLR2023)
-
Better Generative Replay for Continual Federated Learning (ICLR2023)
-
3EF: Class-Incremental Learning via Efficient Energy-Based Expansion and Fusion (ICLR2023)
-
Progressive Voronoi Diagram Subdivision Enables Accurate Data-free Class-Incremental Learning (ICLR2023)
-
Learning without Prejudices: Continual Unbiased Learning via Benign and Malignant Forgetting (ICLR2023)
-
Building a Subspace of Policies for Scalable Continual Learning (ICLR2023)
-
A Model or 603 Exemplars: Towards Memory-Efficient Class-Incremental Learning (ICLR2023)
-
Continual evaluation for lifelong learning: Identifying the stability gap (ICLR2023)
-
Continual Unsupervised Disentangling of Self-Organizing Representations (ICLR2023)
-
Warping the Space: Weight Space Rotation for Class-Incremental Few-Shot Learning (ICLR2023)
-
Neural Collapse Inspired Feature-Classifier Alignment for Few-Shot Class-Incremental Learning (ICLR2023)
-
On the Soft-Subnetwork for Few-Shot Class Incremental LearningOn the Soft-Subnetwork for Few-Shot Class Incremental Learning (ICLR2023)
-
Task-Aware Information Routing from Common Representation Space in Lifelong Learning (ICLR2023)
-
Error Sensitivity Modulation based Experience Replay: Mitigating Abrupt Representation Drift in Continual Learning (ICLR2023)
-
Neural Weight Search for Scalable Task Incremental Learning (WACV2023)
-
Attribution-aware Weight Transfer: A Warm-Start Initialization for Class-Incremental Semantic Segmentation (WACV2023)
-
FeTrIL: Feature Translation for Exemplar-Free Class-Incremental Learning (WACV2023)
-
Sparse Coding in a Dual Memory System for Lifelong Learning (AAAI2023)
总结
增量学习的目标是在动态和开放的环境中,使模型能够在保留已有知识的基础上,不断学习新的类别知识。可以说,如果没有积累所学知识并基于已有的知识来逐步学习更多知识的能力,该系统并不能称之为一个真正意义上的智能系统。
通过对本文的阅读理解,相信大家已经对增量学习有了一定的认识。总的来说,本文主要向大家介绍了三种对标签高效的增量学习方法,包括半监督、小样本和自监督。其次,我们着重分析了现有方法的局限性以及给出了一些建议性的意见。最后,为了让各位小伙伴能够实现完整的闭环,我们还额外提供了必要的增量学习框架和一些最新的论文资料供大家进一步实践和学习。在可预知的未来,我们也不难猜测,增量学习必将更多的向下游任务涌入,包括但不仅限于增量目标检测、增量语义分割以及增量视频分析等。
References
[1]Towards Label-Efficient Incremental Learning: https://arxiv.org/pdf/2302.00353.pdf
[2]CNNL: https://dl.acm.org/doi/abs/10.1145/3094243.3094247
[3]DistillMatch: https://t.co/1sdMip6kuw,
[4]LWF: https://arxiv.org/abs/1606.09282
[5]ORDisCo: https://openaccess.thecvf.com/content/CVPR2021/papers/Wang_ORDisCo_Effective_and_Efficient_Usage_of_Incremental_Unlabeled_Data_for_CVPR_2021_paper.pdf,
[6]MetaCo: https://arxiv.org/abs/2110.01856
[7]PGL: https://arxiv.org/pdf/2201.09196.pdf
[8]DMC: https://openaccess.thecvf.com/content_WACV_2020/papers/Zhang_Class-incremental_Learning_via_Deep_Model_Consolidation_WACV_2020_paper.pdf
[9]CIL-QUD: https://openreview.net/pdf?id=oLvlPJheCD
[10]CoTTA: https://openaccess.thecvf.com/content/CVPR2022/papers/Wang_Continual_Test-Time_Domain_Adaptation_CVPR_2022_paper.pdf
[11]LAME: https://openaccess.thecvf.com/content/CVPR2022/papers/Boudiaf_Parameter-Free_Online_Test-Time_Adaptation_CVPR_2022_paper.pdf
[12]anchor loss: https://openaccess.thecvf.com/content_CVPR_2020/papers/Tao_Few-Shot_Class-Incremental_Learning_CVPR_2020_paper.pdf
[13]TOPIC: https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123640256.pdf
[14]CEC: https://openaccess.thecvf.com/content/CVPR2021/papers/Zhang_Few-Shot_Incremental_Learning_With_Continually_Evolved_Classifiers_CVPR_2021_paper.pdf
[15]IDL-VQ: https://openreview.net/pdf?id=3SV-ZePhnZM
[16]SA-KD: https://openaccess.thecvf.com/content/CVPR2021/papers/Cheraghian_Semantic-Aware_Knowledge_Distillation_for_Few-Shot_Class-Incremental_Learning_CVPR_2021_paper.pdf
[17]SUB-REG: https://openreview.net/forum?id=boJy41J-tnQ
[18]FACT: https://openaccess.thecvf.com/content/CVPR2022/papers/Ramanujan_Forward_Compatible_Training_for_Large-Scale_Embedding_Retrieval_Systems_CVPR_2022_paper.pdf
[19]FSLL: https://ojs.aaai.org/index.php/AAAI/article/view/16334/16141
[20]C-FSCIL: https://openaccess.thecvf.com/content/CVPR2022/papers/Hersche_Constrained_Few-Shot_Class-Incremental_Learning_CVPR_2022_paper.pdf
[21]SSL-OCL: https://www.bmvc2021-virtualconference.com/assets/papers/0636.pdf
[22]PASS: https://openaccess.thecvf.com/content/CVPR2021/papers/Zhu_Prototype_Augmentation_and_Self-Supervision_for_Incremental_Learning_CVPR_2021_paper.pdf
[23]Buffer-SSL: https://www.ecva.net/papers/eccv_2022/papers_ECCV/papers/136860687.pdf
[24]LUMP: https://openreview.net/forum?id=9Hrka5PA7LW
[25]CaSSLe: https://arxiv.org/abs/2112.04215
[26]PFR: https://openaccess.thecvf.com/content/CVPR2022W/CLVision/papers/Gomez-Villa_Continually_Learning_Self-Supervised_Representations_With_Projected_Functional_Regularization_CVPRW_2022_paper.pdf
[27]PyCIL: https://github.com/G-U-N/PyCIL
[28]Awesome IL Algorithms: https://github.com/xialeiliu/Awesome-Incremental-Learning