一、前言
官方原话:EISeg(Efficient Interactive Segmentation)是基于飞桨开发的一个高效智能的交互式分割标注软件。涵盖了高精度和轻量级等不同方向的高质量交互式分割模型,方便开发者快速实现语义及实例标签的标注,降低标注成本。 另外,将EISeg获取到的标注应用到PaddleSeg提供的其他分割模型进行训练,便可得到定制化场景的高精度模型,打通分割任务从数据标注到模型训练及预测的全流程。
官方GitHub:PaddleSeg/EISeg at release/2.6 · PaddlePaddle/PaddleSeg · GitHub

由于我也常常使用百度飞浆的PaddleSeg框架,与ElSeg标注得到的文件也是适配的,且相比LabelMe的比较繁琐的标注,ElSeg的标注更加省时省力。ElSeg支持COCO格式和Json格式的保存方式,适配度高。
二、实战
1.安装
安装百度飞浆的SDK:
pip install paddlepaddle安装EISeg:
pip install eiseg命令行启动:
eiseg
成功开启,这里还没导入相应的预训练模型,需要提前去官网选择下载相关的预训练模型:
官网:PaddleSeg/image.md at release/2.6 · PaddlePaddle/PaddleSeg · GitHub


这里我使用的是HRNet18_OCR64通用场景标注的高精度模型,下载好后导入到EISeg中使用:
加载完成后,左下角会有一行小字显示:
HRNet18_OCR64模型加载成功2.数据集处理与标注
将原始数据集进行重命名和归一化处理:
新建 change_name.py 文件
import os
#任何格式的文件都适用
path = r"F:\Datasets\Lane_line_dataset\divide"
filelist = os.listdir(path)
count=0
for file in filelist:
print(file)
for file in filelist:
Olddir=os.path.join(path,file)
if os.path.isdir(Olddir):
continue
filename=os.path.splitext(file)[0]
filetype=os.path.splitext(file)[1]
Newdir=os.path.join(path,str(count).zfill(6)+filetype)
os.rename(Olddir,Newdir)
count+=1将原始图像的命名格式改为:000000、000001、000002等(以此类推)

在EISeg中选择重命名后的数据集文件夹进行标注,将输出标注的格式修改为json格式(默认下是输出COCO格式):
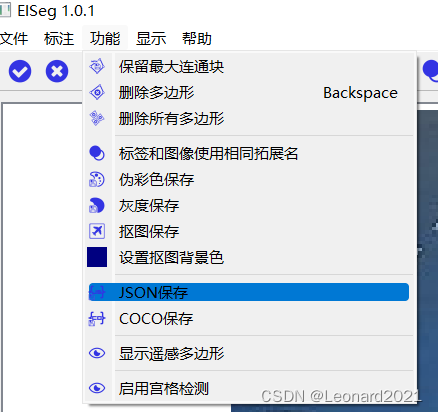
我选择的是一个无人车的车道线数据集,自定义分割标签的名称和对应颜色,设置好后导出备用:


然后就可以开始标注了,鼠标左键是正向趋势的标注,鼠标右键是逆向趋势的标注,你可以自行尝试使用。重要的一点是,每次标注完一种颜色则需要点保存,再开始标注另一种颜色。
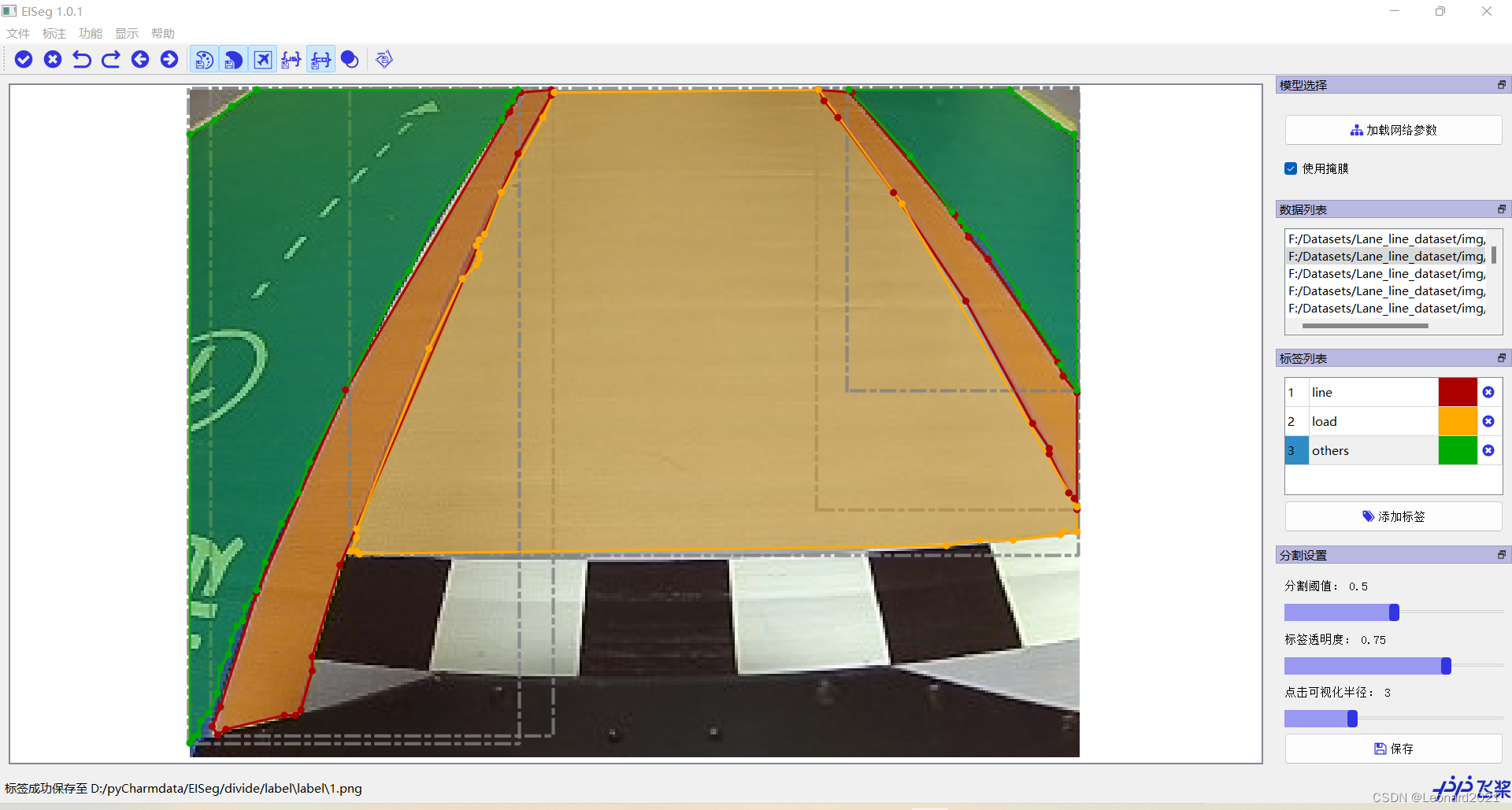
全部标注完成后会在原始文件夹下产生一个新的文件夹:labels文件夹,内含:
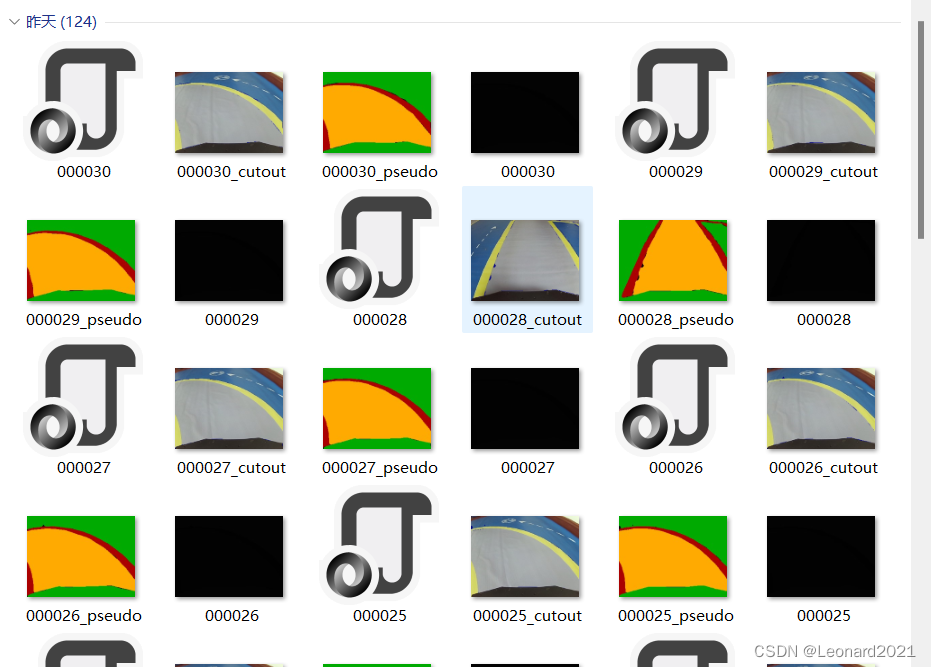
其中,黑色的、只以数字为图像名称的图像就是我们PaddleSeg训练所需要的 annotations,我用程序将其分离开来:
新建 get_annotations.py :
import os
import shutil
def read_name():
source_file_path0 = 'data/label/' #注意opencv库不能打开中文路径
name0 = os.listdir(source_file_path0) #读取源路径下所有文件的名称,将其放在一个列表内返回,每个元素代表一个文件名
new_file_path0 = 'data/annotations/'
return name0, new_file_path0, source_file_path0
if __name__ == "__main__":
name, new_file_path, source_file_path = read_name()
print(name)
for i in name:
if 'png' in i:
png_name=i[:-4]
print("png:", png_name, type(png_name))
if png_name.isdigit():#是返回正
middle_file_name = source_file_path + i #指定文件的路径为路径名加文件名
shutil.copy(middle_file_name, new_file_path) #左边是源文件的路径加文件名称,后面是目标路径,可不加文件名称
PaddleSeg训练所需要数据集架构:
data
|
|--annotions # 存放所有原图
| |--000000.jpg
| |--000001.jpg
| |--...
|
|--images # 存放所有标注图
| |--000000.png
| |--000001.png
| |--...我们再将annotions内图像进行伪彩色标注图处理
python tools/gray2pseudo_color.py <dir_or_file> <output_dir> 
最后进行数据集划分:
python tools/split_dataset_list.py <dataset_root> images annotations --split 0.6 0.2 0.2 --format jpg png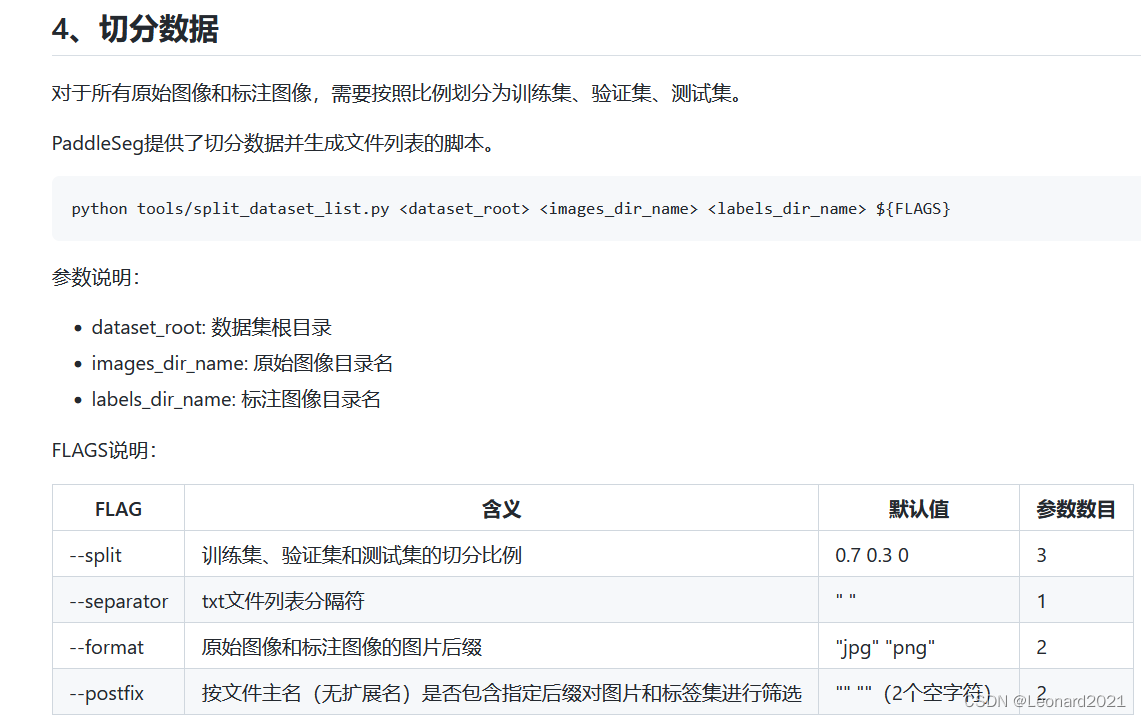
得到最终训练所需的数据集架构:
data
|
|--annotions
| |--000000.jpg
| |--000001.jpg
| |--...
|
|--images
| |--000000.png
| |--000001.png
| |--...
|
|--train.txt
|
|--val.txt
|
|--test.txt三个txt文件的内容如下,每行是一张原始图片和标注图片的相对路径(相对于txt文件),两个相对路径中间是空格分隔符。
images\000004.jpg annotations\000004.png
images\000000.jpg annotations\000000.png
...至此,PaddleSeg进行语义分割训练所需要的数据集架构基本完成。
使用PaddleSeg训练自己数据集的教程:
PPLiteSeg训练自己的数据集实现自动驾驶并爆改制作成API可供其他Python程序调用实时语义分割(超低延时)_Leonard2021的博客-CSDN博客