redis的高可用
一、高可用的概念
高可用是分布式的概念。
假如redis只有一个节点,如果在工作当中redis突然宕机了,而服务器程序的业务逻辑又依赖于redis的数据,这时系统就是不可用的状态。为解决这个问题,就要求redis具备高可用。
所谓高可用,就是一个redis的主节点宕机了,还有备用节点可以顶替它继续运行,服务器程序切换连接新的节点,从而保证系统的可用性。
这里探究的是redis的高可用,所以高可用机制是由redis完成的。它注主要完成以下工作:
(1)数据同步。数据复制过来,备用节点才是可用的。
(2)主从切换。提供一种机制,告诉服务器程序,主节点宕机了,备用节点变成主节点了。
高可用要有一个程度,这个程度由主从切换的时间决定,通常是秒级别。
二、redis 主从复制
主要用来实现 redis 数据的可靠性;防止主 redis 所在磁盘损坏 或redis宕机,造成数据永久丢失。
主从复制是高可用的基础。
redis通常是一主二从的备份方式,而且是在不同的机器中,即异地备份。对于redis而言,是由备份节点连接主节点,而且由备份节点从主节点拉取数据。
也就是,redis是采用异步复制的方式,因为redis要提供高效的key-value存储。
所说的数据同步主要是rdb的数据同步,也就是内存的二进制数据。
2.1、命令
命令:redis-server --replicaof 127.0.0.1 7001
在 redis 5.0 以前使用 slaveof ;redis 5.0 之后使用replicaof。
# redis.conf
replicaof 127.0.0.1 7002
info replication
2.1、同步复制和异步复制
(1)同步复制。向redis发送命令时不能立即返回,而是要等redis将数据同步到备份节点后才返回。
(2)异步复制。向redis发送命令立即返回结果,redis内部将数据写到堆积缓冲区中,redis备份节点会发送offset到主节点;如果offset存在,就根据offset把数据同步到备用节点。这个过程是异步的,和命令没有关系。
注意,分布式一致性中,半数以上节点数据同步成功就算数据同步完成。比如raft一致性。
异步数据的缺点就是存在数据丢失风险。比如主节点宕机了,堆积缓冲区还有数据没有同步到备用节点,这部分数据就丢失了。这样就使得主从之间存在一段时间的数据差异,而且数据差异是不可逆的。
异步复制有全量数据同步和增量数据同步。
(1)全量数据同步:直接把主数据库的全部rdb文件(即整个内存中所有的数据)都同步过来。
(2)增量数据同步:从数据库会记录一个偏移量offset(即记录同步到哪里了),如果offset在环形缓冲区当中,从数据库就会将offset后面的那部分数据同步过了;如果offset不在环形缓存区中,就会全量同步,把主数据库内部所有数据都同步过来。
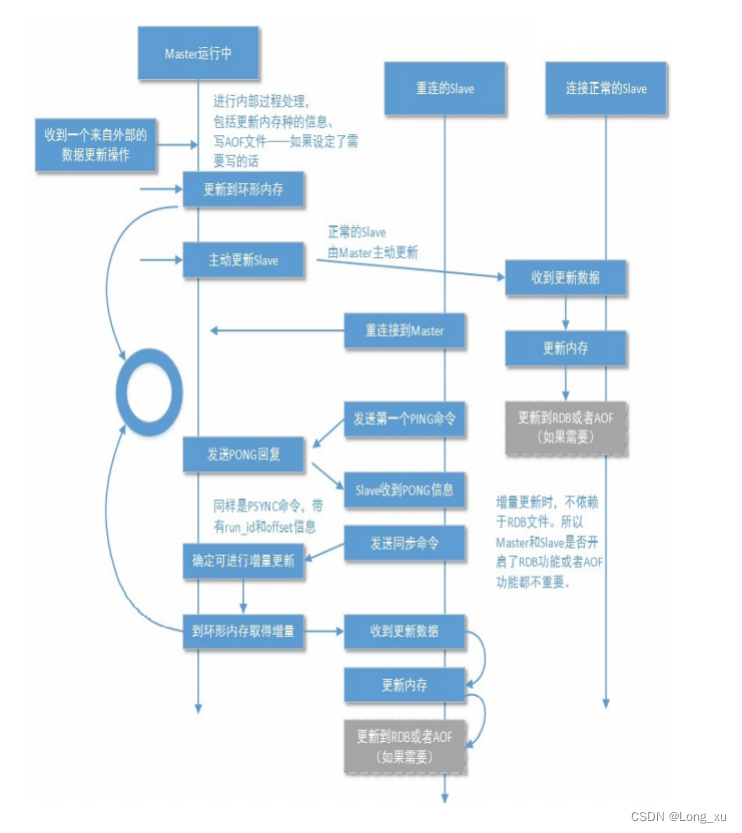
2.2、原理
主从复制主要由环形缓冲区、复制偏移量、RUN ID三个部分组成。
(1)RUNID用于构建主从的关系,无论主库还是从库都有自己的 RUNID,RUNID 启动时自动产生,RUNID 由 40 个随机的十六进制字符组成;当从库对主库初次复制时,主库将自身的 RUNID 传送给从库,从库会将 RUNID 保存;当从库断线重连主库时,从库将向主库发送之前保存的 RUNID。
从数据库同步的时候,先发送RUNID,验证自己是否是目标的从数据库; 如果是就开始同步;如果不是就同步主数据的RUNID,然后把自己的数据丢失,再去拉取主数据库的所有数据。
(2)环形缓冲区(复制积压缓冲区)本质是固定长度先进先出队列。环形缓冲区决定是全量数据同步还是增量数据同步。使用环形是为了防止数据的遗漏,同时避免数据移动和能覆盖过旧的数据。
(3)主从都会维护一个复制偏移量。从数据库使用偏移量和环形缓冲区验证,如果offset在环形缓冲区当中,增量数据同步;如果offset不在环形缓存区中,全量数据同步。
(4)主从复制不能保证高可用,只解决了单点故障问题。
三、redis 哨兵模式
哨兵模式是 Redis 可用性的解决方案;它由一个或多个 sentinel实例构成 sentinel 系统;该系统可以监视任意多个主库以及这些
主库所属的从库;当主库处于下线状态,自动将该主库所属的某个从库升级为新的主库。
哨兵模式的作用:
(1)监控数据节点的状态。
(2)选主。
客户端来连接集群时,会首先连接 sentinel,通过 sentinel 来查询主节点的地址,然后再连接主节点进行数据交互。当主节点
发生故障时,客户端会重新向 sentinel 索要主库地址,sentinel会将最新的主库地址告诉客户端。通过这样客户端无须重启即
可自动完成节点切换。
哨兵模式当中涉及多个选举流程采用的是 Raft 算法的领头选举方法的实现。哨兵模式要部署奇数个节点,目的是为了选主。哨兵节点不存储任何业务数据,只有redis存储数据,哨兵节点只是存储一些状态。
哨兵模式只提供一个数据节点服务。但是,如果主节点宕机了,哨兵模式会从备用节点中选一个数据最新(根据复制偏移量判断,偏移量越大数据越新)的出来当主节点。
3.1、配置
# sentinel.cnf
# sentinel 只需指定检测主节点就行了,通过主节点自动发现从节点
sentinel monitor mymaster 127.0.0.1 6379 2
# 判断主观下线时长
sentinel down-after-milliseconds mymaster 30000
# 指定可以有多少个Redis服务同步新的主机,一般而言,这个数字越小同步时间越长,而越大,则对网络资源要求越高
sentinel parallel-syncs mymaster 1
# 指定故障切换允许的毫秒数,超过这个时间,就认为故障切换失败,默认为3分钟
sentinel failover-timeout mymaster 180000
3.2、检测异常
(1)主观下线。
sentinel 会以每秒一次的频率向所有节点(其他sentinel、主节点、以及从节点)发送 ping 消息,然后通过接收返回判断该
节点是否下线;如果在配置指定 down-after-milliseconds 时间内则被判断为主观下线。
(2)客观下线。
当一个 sentinel 节点将一个主节点判断为主观下线之后,为了确 认这个主节点是否真的下线,它会向其他 sentinel 节点进行询
问,如果收到一定数量(半数以上)的已下线回复,sentinel 会将主节点判定为客观下线,并通过领头 sentinel 节点对主节点
执行故障转移。
3.3、故障转移
主节点被判定为客观下线后,开始领头 sentinel 选举,需要半数以上的 sentinel 支持,选举领头 sentinel 后,开始执行对主节点
故障转移。
(1)从从节点中选举一个从节点作为新的主节点。
(2)通知其他从节点复制连接新的主节点。
(3)若故障主节点重新连接,将作为新的主节点的从节点。
3.4、使用
- 连接一个哨兵节点,并且获取主节点信息;SENTINEL GET-MASTER-ADDR-BY-NAME 。
- 验证当前获取的主节点;ROLE 或者 INFO REPLICATION。
- 为当前连接的哨兵节点,添加发布订阅(PUB/SUB)连接,并且订阅 +switch-master 频道。
3.5、缺点
redis 采用异步复制的方式,意味着当主节点挂掉时,从节点可能没有收到全部的同步消息,这部分未同步的消息将丢失。如
果主从延迟特别大,那么丢失可能会特别多。sentinel 无法保证消息完全不丢失,但是可以通过配置来尽量保证少丢失。
同时,它的致命缺点是不能进行横向扩展。
# 主库必须有一个从节点在进行正常复制,否则主库就停止对外写服务,此时丧失了可用性
min-slaves-to-write 1
# 这个参数用来定义什么是正常复制,该参数表示如果在10s内没有收到从库反馈,就意味着从库同步不正常;
min-slaves-max-lag 10
四、redis cluster集群
Redis cluster 将所有数据划分为 16384( 2 14 2^{14} 214 )个槽位,每个redis 节点负责其中一部分槽位。cluster 集群是一种去中心化的集群方式。
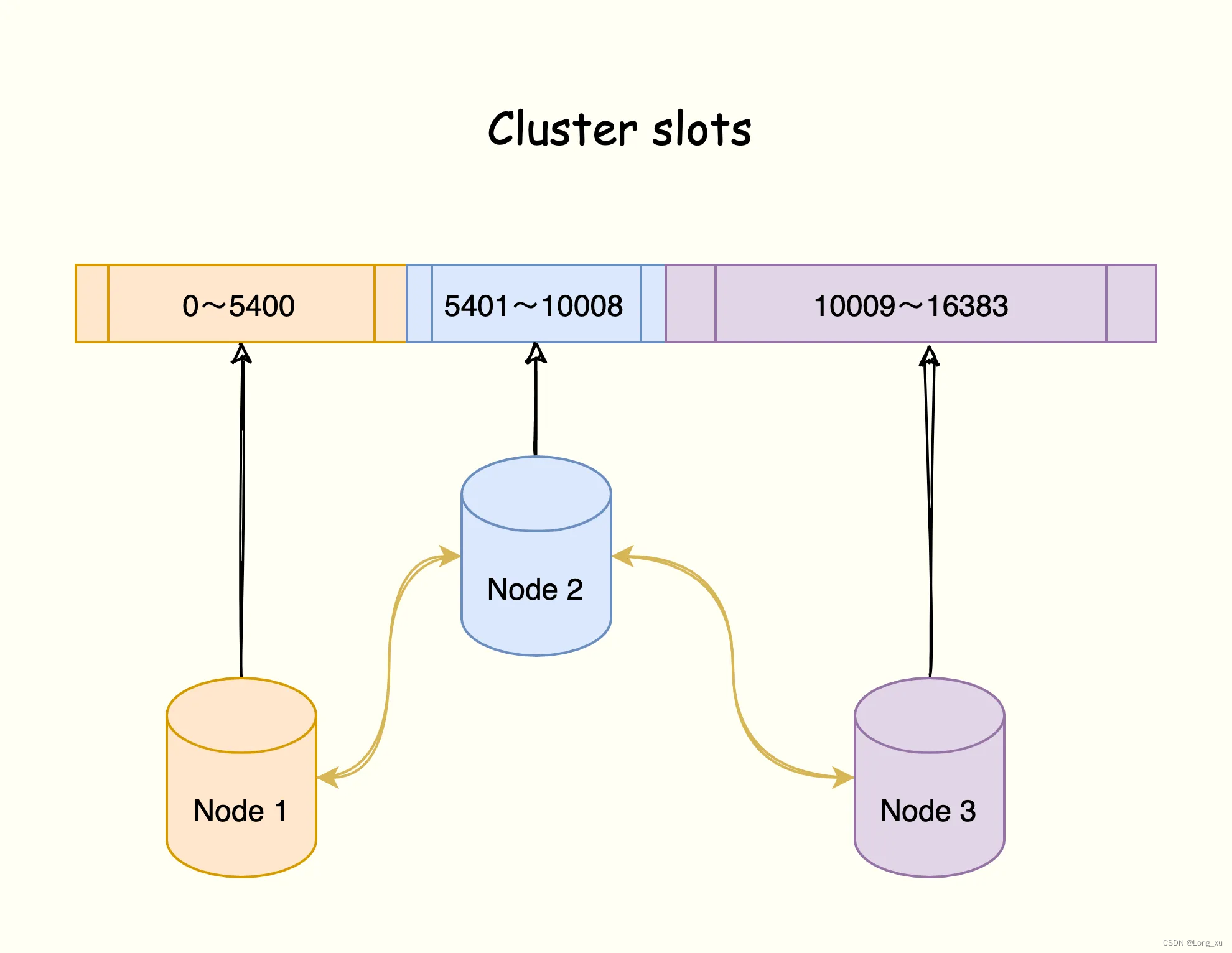
如图,该集群由三个 redis 节点组成,每个节点负责整个集群的一部分数据,每个节点负责的数据多少可能不一样。这三个节 点相互连接组成一个对等的集群,它们之间通过一种特殊的二进制协议交互集群信息。
当 redis cluster 的客户端来连接集群时,会得到一份集群的槽位配置信息。这样当客户端要查找某个 key 时,可以直接定位到
目标节点。
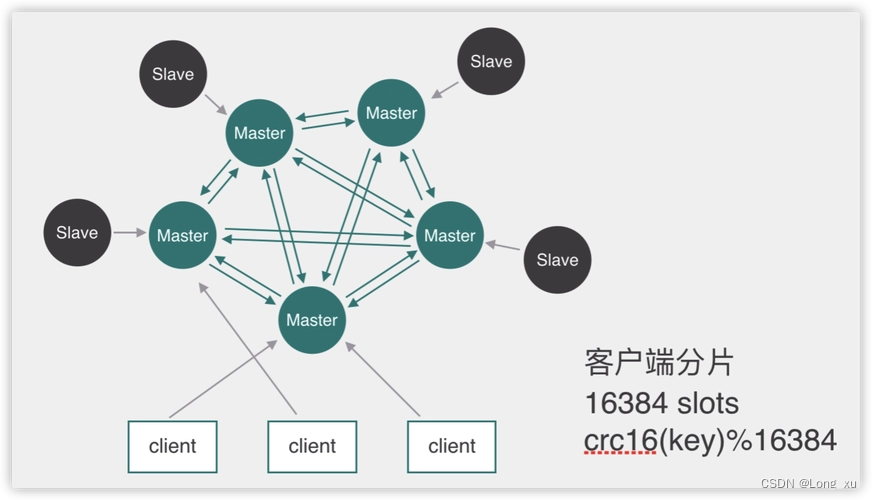
客户端为了可以直接定位(对 key 通过 crc16 进行 hash 再对 2 14 2^{14} 214取余)某个具体的 key 所在节点,需要缓存槽位相关信息,这样才可以准确快速地定位到相应的节点。同时因为可能会存在客户端与服务器存储槽位的信息不一致的情况,还需要纠正
机制(通过返回 -MOVED 3999 127.0.0.1:6479,客户端收到后需要立即纠正本地的槽位映射表)来实现槽位信息的校验调整。
另外,redis cluster 的每个节点会将集群的配置信息持久化到配置文件中,这就要求确保配置文件是可写的,而且尽量不要依靠人工修改配置文件。
一般来说,redis cluster集群设置奇数个主节点,所有节点间构建成一个系统(这个系统就是redis cluster集群)。
尽量使多个主节点的数据均衡;采用分布式一致性hash。
多个主节点的目的是为了使数据可以横向扩展;因为一个节点的空间是有限的。
4.1、数据迁移
redis cluster 提供了工具 redis-trib 可以让运维人员手动调整槽位的分配情况,它采用 ruby 语言开发,通过组合原生的 rediscluster 指令来实现。
图中:A 为待迁移的源节点,B 为待迁移的目标节点
4.2、复制以及故障转移
cluster 集群中节点分为主节点和从节点,其中主节点用于处理槽,而从节点则用于复制该主节点,并在主节点下线时,代替主节点继续处理命令请求。
4.2.1 故障检测
集群中每个节点都会定期地向集群中的其他节点发送 ping 消息,如果接收 ping 消息的节点没有在规定时间内回复 pong消息,那么这个没有回复 pong 消息的节点会被标记为 PFAIL(probable fail)。
集群中各个节点会通过互相发送消息的方式来交换集群中各个节点的状态信息;如果在一个集群中,半数以上负责处理槽的主节点都将某个主节点 A 报告为疑似下线,那么这个主节点 A将被标记为下线(FAIL )。标记主节点 A 为下线状态的主节点会广播这条消息,其他节点(包括A节点的从节点)也会将A节点标识为 FAIL。
4.2.2 故障转移
当从节点发现自己的主节点进入 FAIL 状态,从节点将开始对下线主节点进行故障转移。
- 从数据最新的从节点中选举为主节点;
- 该从节点会执行 replica no one 命令,称为新的主节点;
- 新的主节点会撤销所有对已下线主节点的槽指派,并将这些槽全部指派给自己;
- 新的主节点向集群广播一条 pong 消息,这条 pong 消息可以让集群中的其他节点立即知道这个节点已经由从节点变成主节点,并且这个主节点已经接管了之前下线的主节点。
- 新的主节点开始接收和自己负责处理的槽有关的命令请求,故障转移结束。
五、redis 集群配置
5.1、hiredis-cluster 安装编译
要求cmake版本再5.11以上。
git clone https://github.com/Nordix/hirediscluster.git
cd hiredis-cluster
mkdir build
cd build
cmake -DCMAKE_BUILD_TYPE=RelWithDebInfo -
DENABLE_SSL=ON ..
make
sudo make install
sudo ldconfig
5.2、创建文件夹
# 创建 6 个文件夹
mkdir -p 7001 7002 7003 7004 7005 7006
cd 7001
vi 7001.conf
# 7001.conf 中的内容如下
5.3、编辑 7001.conf
pidfile "/home/flyredis-data/7001/7001.pid"
logfile "/home/fly/redis-data/7001/7001.log"
dir /home/fly/redis-data/7001/
port 7001
daemonize yes
cluster-enabled yes
cluster-config-file nodes-7001.conf
cluster-node-timeout 15000
pidfile存放进程ID。
daemonize表示后台运行。
5.4、复制配置
cp 7001/7001.conf 7002/7002.conf
cp 7001/7001.conf 7003/7003.conf
cp 7001/7001.conf 7004/7004.conf
cp 7001/7001.conf 7005/7005.conf
cp 7001/7001.conf 7006/7006.conf
5.5、修改配置
sed -i 's/7001/7002/g' 7002/7002.conf
sed -i 's/7001/7003/g' 7003/7003.conf
sed -i 's/7001/7004/g' 7004/7004.conf
sed -i 's/7001/7005/g' 7005/7005.conf
sed -i 's/7001/7006/g' 7006/7006.conf
5.6、创建启动配置
#!/bin/bash
redis-server 7001/7001.conf
redis-server 7002/7002.conf
redis-server 7003/7003.conf
redis-server 7004/7004.conf
redis-server 7005/7005.conf
redis-server 7006/7006.conf
启动结果:
fly@fly-virtual-machine:~/redis/cluster-mode$ ps aux | grep redis-server
fly 68816 0.0 0.1 64472 4564 ? Ssl 15:33 0:00 redis-server *:7001 [cluster]
fly 68818 0.0 0.1 64472 5192 ? Ssl 15:33 0:00 redis-server *:7002 [cluster]
fly 68828 0.0 0.1 64472 4740 ? Ssl 15:33 0:00 redis-server *:7003 [cluster]
fly 68830 0.0 0.1 64472 4748 ? Ssl 15:33 0:00 redis-server *:7004 [cluster]
fly 68832 0.0 0.1 64472 4576 ? Ssl 15:33 0:00 redis-server *:7005 [cluster]
fly 68842 0.0 0.1 64472 4548 ? Ssl 15:33 0:00 redis-server *:7006 [cluster]
fly 75184 0.0 0.0 16192 1100 pts/21 S+ 15:43 0:00 grep --color=auto redis-server
5.7、手动创建集群
# 节点会面
cluster meet ip port
# 分配槽位
cluster addslots slot
# 分配主从
cluster replicate node-id
5.8、智能创建集群
redis-cli --cluster help
# --cluster-replicas 后面对应的参数 为 一主对应几个从数据库
redis-cli --cluster create host1:port1 ...
hostN:portN --cluster-replicas <arg>
redis-cli --cluster create 127.0.0.1:7001
127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004
127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1
搭建结果:
fly@fly-virtual-machine:~/redis/cluster-mode$ redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 127.0.0.1:7005 to 127.0.0.1:7001
Adding replica 127.0.0.1:7006 to 127.0.0.1:7002
Adding replica 127.0.0.1:7004 to 127.0.0.1:7003
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: 63bc9c9f79604b17cdace3f2837fce5590bc5a23 127.0.0.1:7001
slots:[0-5460] (5461 slots) master
M: ae318407bd3f93b88491e4baa47241040d7de58d 127.0.0.1:7002
slots:[5461-10922] (5462 slots) master
M: 7f768fd2f82c5a87d9c02ec81b06b6eca70ffa34 127.0.0.1:7003
slots:[10923-16383] (5461 slots) master
S: 7e4508327ab4bc3e86a02f00a58218c48db1d8c8 127.0.0.1:7004
replicates 63bc9c9f79604b17cdace3f2837fce5590bc5a23
S: d14ab611806580d25c419ad4f52fac85fb789dbb 127.0.0.1:7005
replicates ae318407bd3f93b88491e4baa47241040d7de58d
S: c62f22a573585c8e4cefa4816b60d9e9ef0edc79 127.0.0.1:7006
replicates 7f768fd2f82c5a87d9c02ec81b06b6eca70ffa34
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.
>>> Performing Cluster Check (using node 127.0.0.1:7001)
M: 63bc9c9f79604b17cdace3f2837fce5590bc5a23 127.0.0.1:7001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: ae318407bd3f93b88491e4baa47241040d7de58d 127.0.0.1:7002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 7e4508327ab4bc3e86a02f00a58218c48db1d8c8 127.0.0.1:7004
slots: (0 slots) slave
replicates 63bc9c9f79604b17cdace3f2837fce5590bc5a23
S: d14ab611806580d25c419ad4f52fac85fb789dbb 127.0.0.1:7005
slots: (0 slots) slave
replicates ae318407bd3f93b88491e4baa47241040d7de58d
M: 7f768fd2f82c5a87d9c02ec81b06b6eca70ffa34 127.0.0.1:7003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: c62f22a573585c8e4cefa4816b60d9e9ef0edc79 127.0.0.1:7006
slots: (0 slots) slave
replicates 7f768fd2f82c5a87d9c02ec81b06b6eca70ffa34
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
5.9、测试集群
(1)设置值。
redis-cli -c -p 7001
set name fly_test
(2)主节点宕机。
redis-cli -p 7001 shutdown
(3)主节点重启
redis-server 7001/7001.conf
(4)扩容。
先添加节点,再分配槽位。
cp -R 7001 7007
cd 7007
mv 7001.conf 7007.conf
rm 7001.log dump.rdb nodes-7001.conf
sed -i "s/7001/7007/g" 7007.conf
cp -R 7007 7008
cd 7008
mv 7007.conf 7008.conf
sed -i "s/7007/7008/g" 7008.conf
cd ..
redis-server 7007/7007.conf
redis-server 7008/7008.conf
redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7001
redis-cli --cluster add-node 127.0.0.1:7008 127.0.0.1:7001 --cluster-slave --cluster-master-id d8f8470cf1698e67c5958a06b05e04f2197680c3
redis-cli --cluster reshard 127.0.0.1:7001
How many slots do you want to move (from 1 to
16384)? 1000
What is the receiving node ID?
d8f8470cf1698e67c5958a06b05e04f2197680c3
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: all
redis-cli --cluster reshard 127.0.0.1:7001 --cluster-from 07617e42f430fe61ce6238fd85fa1a6ff04ab486 --cluster-to 71e81275c71e8021bf080a1010d6f384cdc68e90 --cluster-slots 1000
(5)缩容。
先移动槽位,再删除节点。
redis-cli --cluster reshard 127.0.0.1:7001 --cluster-from 71e81275c71e8021bf080a1010d6f384cdc68e90 --cluster-to 07617e42f430fe61ce6238fd85fa1a6ff04ab486 --cluster-slots 1000
# 删除节点 7007
redis-cli --cluster del-node 127.0.0.1:7001 71e81275c71e8021bf080a1010d6f384cdc68e90
# 此时 7008 成为其他节点的 副本节点
redis-cli --cluster del-node 127.0.0.1:7001 ace84fc6e27cd847dd9e06296559e0854fe7b2b2
总结
- 哨兵模式的流程。
- cluster集群特征:去中心化、主节点对等、解决了数据扩容、客户端与服务器端缓存槽位信息、可人为数据迁移。
- cluster集群的缺点:因为主从采用异步复制,在故障转移时仍然存在数据丢失情况。
