目录
在PyTorch官方文档中提供了torchvision.transforms模块对图片数据进行变换,torch.utils.data.Dataset 和 torch.utils.data.DataLoader模块来读取数据。要实现自定义数据集,就要继承 torch.utils.data.Dataset,并实现__getitem__() 和 __len__()两个方法用于读取并处理数据,得到相对应的数据处理结果后。将自定义的Dataset封装到 DataLoader中,就能实现了单/多进程迭代输出数据。
在训练过程中,数据的处理基本包括如下:
- 数据预处理。归一化或者其他,在图片中一般使用
torchvision.transforms模块中的方法进行简单处理。当然也可以自己写方法去处理。 - 划分数据集为训练集和测试集。这种划分一般取决于用户,划分方法有留出法,交叉验证法,自助法等。(一般对于数据量比较大,直接按照7:3随机划分一次即可)
- 自定义数据集。编写自定义
MyDataSet类,继承torch.utils.data.Dataset类,并实现__getitem__()和__len__()方法。 - 使用
DataLoader数据加载器根据自定义数据集加载数据。其中可以使用默认的Sampler和Collate Function。
可视化可参考:PyTorch DataLoader工作原理可视化
torchvision.transforms
在torchvision.transforms模块中提供了一般的图像数据变换操作类,可以用于实现数据预处理(data preprocessing)和数据增广(data argumentation)。这里列举一些常用的变换操作。
一般图像是一个具有 ( c , h , w ) (c,h,w) (c,h,w) 形状的张量。其中c(channel),h(height),w(width)。当然也可以使用batch的Tensor图像。形状为 ( b , c , h , w ) (b,c,h,w) (b,c,h,w)。其中b(batch),c(channel),h(height),w(width)。
在图像常用的定义和使用方式如下:# 定义RGB三通道的均值和方差 mean = [0.485, 0.456, 0.406] std = [0.229, 0.224, 0.225] # 定义转换操作集合。 transform = transforms.Compose([ transforms.Resize(299), transforms.CenterCrop(299), transforms.ToTensor(), transforms.Normalize(mean, std) ])
transforms.Compose
这可以看作是一种容器,能够将多种数据变换进行组合。输入是对载入数据的各种变换操作集列表。
transformer = transforms.Compose([
transforms.Resize(224,224),
transforms.transforms.RandomResizedCrop((224), scale = (0.5,1.0)),
transforms.RandomHorizontalFlip(),
])
# 对图片img进行变换操作
img_trans = transformer(img)
transforms.Normalize(mean, std)
标准正态分布对数据进行标准化,其中mean是均值,std是标准差,变换完成后数据符合均值为0,标准差为1的标准正态分布。对于RGB三通道图,mean和std可以是三维的。
normalize_transformer = transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
裁剪(Crop)
- 中心裁剪:transforms.CenterCrop
- 随机裁剪:transforms.RandomCrop
- 随机长宽比裁剪:transforms.RandomResizedCrop
- 上下左右中心裁剪:transforms.FiveCrop
- 上下左右中心裁剪后翻转,transforms.TenCrop
翻转和旋转(Flip and Rotation)
- 依概率p水平翻转:transforms.RandomHorizontalFlip(p=0.5)
- 依概率p垂直翻转:transforms.RandomVerticalFlip(p=0.5)
- 随机旋转:transforms.RandomRotation
图像变换(resize)
-
transforms.Resize
对载入的图片数据进行缩放,其中,size可以是整数类型(将长宽中最短的缩放到size,然后长的等比缩放),也可以是
(h,w)的序列。transforms.Resize(x)# 将图片短边缩放至x,长宽比保持不变 transforms.Resize([h,w])# 同时指定长宽
除此之外,还有图像变化方法如下:
- 转为tensor,并归一化至[0-1]:transforms.ToTensor
- 填充:transforms.Pad
- 修改亮度、对比度和饱和度:transforms.ColorJitter
- 转灰度图:transforms.Grayscale
- 线性变换:transforms.LinearTransformation()
- 仿射变换:transforms.RandomAffine
- 依概率p转为灰度图:transforms.RandomGrayscale
- 将数据转换为PILImage:transforms.ToPILImage transforms.Lambda:Apply a user-defined lambda as a transform.
transforms.ToTensor
用于对载入的图片数据进行类型转换,将之前构成PIL图片的数据转换成Tensor数据类型,让PyTorch能够对其进行计算和处理。
transforms.ToPILImage
用于将Tensor变量的数据转换成PIL图片数据,主要是为了方便图片内容的显示。
torch.utils.data.Dataset
在官方介绍中,如果要使用自定义数据集,需要继承torch.utils.data类,并实现__getitem__() 和 __len__()两个方法:
-
__len__返回的是数据集的大小 -
__getitem__实现通过索引获取数据集中的某一个数据,以[input,label]的形式给出。
在包torch.utils.data中,包含pytorch内部默认的数据处理类:
Dataset(object)IterableDataset(Dataset)TensorDataset(Dataset): 封装成tensor的数据集,每一个样本都通过索引张量来获得。ConcatDataset(Dataset): 连接不同的数据集以构成更大的新数据集Subset(Dataset): 获取指定一个索引序列对应的子数据集ChainDataset(IterableDataset)
而在torchvision也封装了几种常见的数据集,在torchvision.datasets中,包括:FashionMNIST, ImageFolder, CIFAR10, CIFAR100, SVHN, PhotoTour, ImageNet, CocoDetection等。
这里对torch中Dataset类,TensorDataset类,torchvision中ImageFolder类,FashionMNIST类进行分析,其继承关系如下图所示:
这里有个问题,就是在看源码的时候
torchvision.datasets.Dataset中没有__len__()方法,而是在后面类中定义的这个方法。但是官网中说是自定义数据集需要实现两种方法__getitem__()和__len__()方法。如果是直接继承torch.utils.data.Dataset类的,比如TensorDataset数据集继承的方法中是不包括__len__()的。
可以看出,所有的实现类基本都是直接或者间接继承于torch.utils.data.Dataset这个类的。基于此,编写自定义数据集类:
创建my_dataset文件,内容如下:
import torch
from torch.utils.data import Dataset
import numpy as np
# 自定义数据集,继承torch.utils.data.Dataset
class MyDataSet(Dataset):
# 初始化函数,得到数据,这里不绝对,
def __init__(self, pathData, pathLabel):
self.data = np.load(pathData) # 传入dataset 特征的路径
self.label = np.load(pathLabel) # 传入dataset 中label的路径
# 该函数返回数据大小长度,目的是方便DataLoader划分。
def __len__(self):
return len(self.data)
# index是根据batchsize划分数据后得到的索引,最后将data和对应的labels一起返回
def __getitem__(self, index):
data = self.data[index]
labels = self.label[index]
return data, labels
# 表示静态方法,该方法不一定需要,只是在dataloader中方便使用而已
@staticmethod
def collate_fn(batch):
"""
该方法用于DataLoader中的collate_fn参数。到时候可以直接使用 对象.collate_fn,或者 类.collate_fn。
该方法是在Dataloader中重新整理数据的方法。对该batch中的数据进行重新整理。如果没有定义,则会使用默认的collate_fn
:param batch:
:return:
"""
# 官方实现的default_collate可以参考
# https://github.com/pytorch/pytorch/blob/67b7e751e6b5931a9f45274653f4f653a4e6cdf6/torch/utils/data/_utils/collate.py
images, labels = tuple(zip(*batch))
images = torch.stack(images, dim=0)
labels = torch.as_tensor(labels)
return images, labels
那么到时候实例化自定义数据集的时候可以通过:
pathX = '' # 特征数据的文件地址
pathY = '' # 标签数据的文件地址
torch_data = MyDataSet(pathX,pathY)# 实例化数据集dataset
torch.utils.data.DataLoader
torch.utils.data.DataLoader(dataset, batch_size, shuffle, drop_lase, num_workers, collate_fn, sampler)
参数含义:
- dataset: 加载
torch.utils.data.Dataset对象数据或者子类对象。 - batch_size: 每个batch的大小
- shuffle:是否对数据进行打乱
- drop_last:是否对无法整除的最后一个datasize进行丢弃。
- num_workers:表示加载的时候子进程数,一般window中设置为0,Linux中设置为大于0的数
- collate_fn:collate_fn函数会将batch_size个样本整理成一个batch样本,便于批量训练。如果不设置,使用默认的方法。
- sampler:“采样器”,表示从样本中究竟如何取样。
通过Loader操作得到的数据可以通过迭代器进行输出数据。如下:
datas = DataLoader(torch_dataset, batch_size, shuffle=True, num_workers=0)
for i, data in enumerate(datas):
# 这里的i表示第几个batch的数据,而data表示该batch对应的数据,包含训练数据和标签
print("{}个batch \n {}".format(i, data))
# 通过这种方式获取第i个batch数据中训练数据和训练样本
images, labels = data
sampler
pytorch采样器有如下几个(
torch.utils.data包中):
SamplerSequentialSampler: 顺序采样样本,始终按照同一个顺序。RandomSampler: 无放回地随机采样样本元素。SubsetRandomSampler: 无放回地按照给定的索引列表采样样本元素WeightedRandomSampler: # 按照给定的概率来采样样本。BatchSampler: # 在一个batch中封装一个其他的采样器。DistributedSampler: 在包torch.utils.data.distributed中,采样器可以约束数据加载进数据集的子集。
其继承关系如图所示:
Sampler类是所有的采样器的基类,每一个继承自Sampler的子类都必须实现它的__iter__()方法和__len__()方法。
__iter__()实现如何迭代样本__len__()返回一共有多少个样本
对于默认使用的采样器,其实现源码如下:
if batch_sampler is None: # 没有手动传入batch_sampler参数时
if sampler is None: # 没有手动传入sampler参数时
if shuffle:
sampler = RandomSampler(dataset) # 随机采样
else:
sampler = SequentialSampler(dataset) # 顺序采样
batch_sampler = BatchSampler(sampler, batch_size, drop_last)
self.sampler = sampler
self.batch_sampler = batch_sampler
self.__initialized = True
网上找到的一个视频处理采样器:
class RandomSequenceSampler(Sampler):
# 作用与BatchSampler有点类似,每seq_len个视频shuffle
def __init__(self, n_sample, seq_len):
self.n_sample = n_sample # 视频的数量
self.seq_len = seq_len # 视频序列长度
def _pad_ind(self, ind):
zeros = np.zeros(self.seq_len - self.n_sample % self.seq_len)
ind = np.concatenate((ind, zeros))
return ind
def __iter__(self):
idx = np.arange(self.n_sample)
if self.n_sample % self.seq_len != 0:
idx = self._pad_ind(idx)
idx = np.reshape(idx, (-1, self.seq_len))
np.random.shuffle(idx)
idx = np.reshape(idx, (-1))
return iter(idx.astype(int))
def __len__(self):
return self.n_sample + (self.seq_len - self.n_sample % self.seq_len)
collate_fn
在继承Dataset类的自定义类中,__getitem__()方法一般返回一组类似于[input,label]的一个样本,而在创建DataLoader类的对象时,collate_fn函数会将batch_size个样本整理成一个batch样本,便于批量训练。
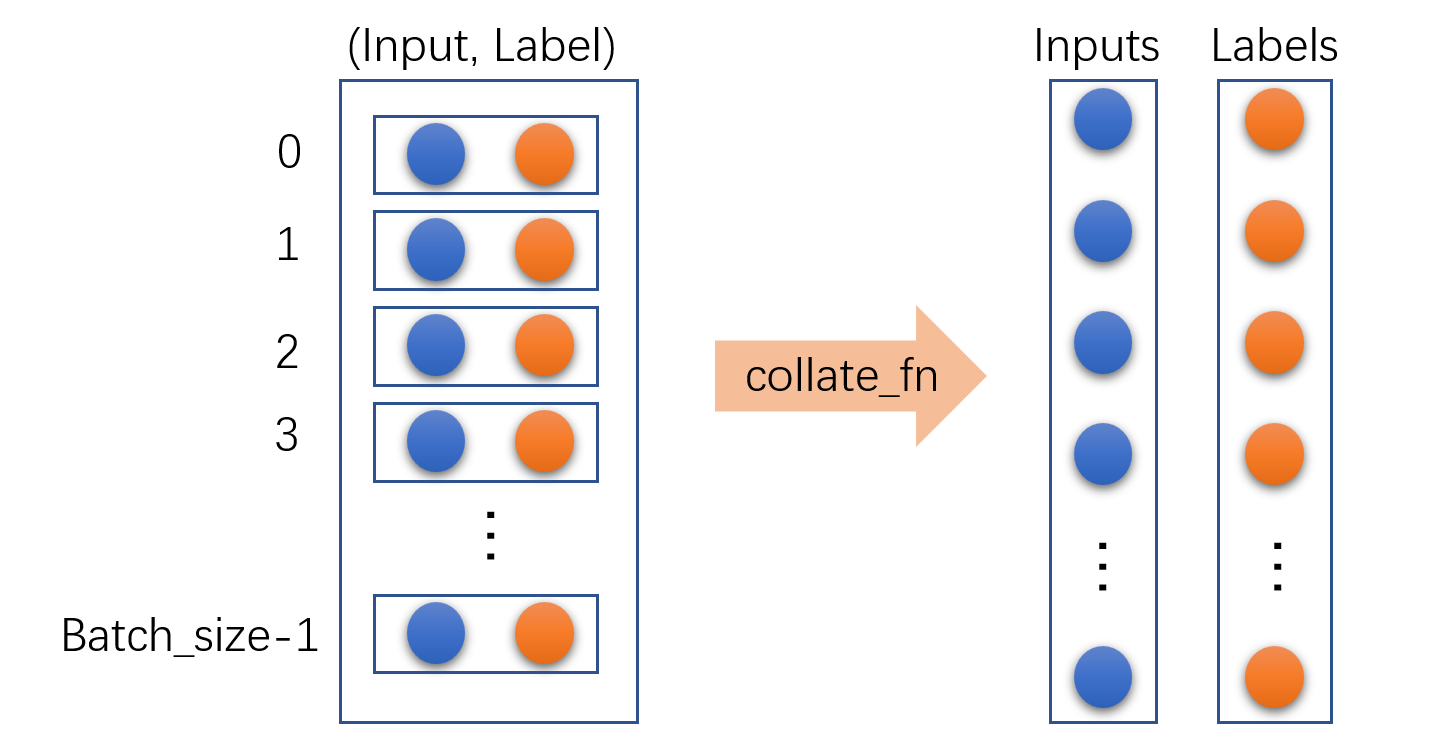
如果在DataLoader中不设置
collate_fn,则会使用默认的函数default_collate(batch),在该方法中的有self.dataset[i] for i in indices其中,indices是该batch_size中从Dataset子类中获取的索引集合,而self.dataset[i]就是Dataset子类中
__getitem__()返回的结果。默认的函数default_collate(batch) 只能对大小相同的batch_size个input进行整理,
将
[(input0, label0), (input1, label1),(input2, label2), ]整理成([input0,input1,input2,], [label0,label1,label2,]), 这里要求多个input的大小要相同,如果不相同时候需要使用自定义函数callate_fn来处理。对于目标检测,其输入一般是
(input,box,label)形式,这种也需要自定义,因为默认函数只能处理(input,label)格式。
简单的collate_fn函数参考:
函数定义形式:
def collate_fn(self, batch):
for unit in batch:
unit_x.append(unit[0])
unit_y.append(unit[1])
...
return {
x: torch.tensor(unit_x), y: torch.tensor(unit_y)}
# 使用,直接将函数名传进去就好
loader = Dataloader(collate_fn=collate_fn)
说明,这里的batch是该batch_size中的数据集合
函数输入形式:
[(input0, label0), (input1, label1),(input2, label2),...]函数输出形式:
([input0,input1,input2,...], [label0,label1,label2,...])
创建可被调用的类的形式:
class collater():
def __init__(self, *params):
self. params = params
def __call__(self, data):
'''在这里重写collate_fn函数'''
# 对于类的形式,使用的时候是,创建对象作为输入即可
collate_fn = collater(*params)
loader = Dataloader(collate_fn=collate_fn)
对于目标检测的自定义collate_fn函数参考如下:
def collate_fn(self, batch):
paths, imgs, targets = list(zip(*batch))
# Remove empty placeholder targets
# 有可能__getitem__返回的图像是None, 所以需要过滤掉
targets = [boxes for boxes in targets if boxes is not None]
# Add sample index to targets
# boxes是每张图像上的目标框,但是每个图片上目标框数量不一样呢,所以需要给这些框添加上索引,对应到是哪个图像上的框。
for i, boxes in enumerate(targets):
boxes[:, 0] = i
targets = torch.cat(targets, 0)
# Selects new image size every tenth batch
if self.multiscale and self.batch_count % 10 == 0:
self.img_size = random.choice(range(self.min_size, self.max_size + 1, 32))
# Resize images to input shape
# 每个图像大小不同呢,所以resize到统一大小
imgs = torch.stack([resize(img, self.img_size) for img in imgs])
self.batch_count += 1
return paths, imgs, targets