一、逻辑回归算法
1. 什么是逻辑回归
逻辑回归就是这样的一个过程:面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,然后测试验证我们这个求解的模型的好坏。
Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别)
回归模型中,y是一个定性变量,比如y=0或1,logistic方法主要应用于研究某些事件发生的概率
2. 逻辑回归的优缺点
优点:
1)速度快,适合二分类问题
2)简单易于理解,直接看到各个特征的权重
3)能容易地更新模型吸收新的数据
缺点:
对数据和场景的适应能力有局限性,不如决策树算法适应性那么强
3. 逻辑回归和多重线性回归的区别
Logistic回归与多重线性回归实际上有很多相同之处,最大的区别就在于它们的因变量不同,其他的基本都差不多。正是因为如此,这两种回归可以归于同一个家族,即广义线性模型(generalizedlinear model)。
4. 逻辑回归用途
寻找危险因素:寻找某一疾病的危险因素等;
预测:根据模型,预测在不同的自变量情况下,发生某病或某种情况的概率有多大;
判别:实际上跟预测有些类似,也是根据模型,判断某人属于某病或属于某种情况的概率有多大,也就是看一下这个人有多大的可能性是属于某病。
5. Regression 常规步骤
寻找h函数(即预测函数)
构造J函数(损失函数)
想办法使得J函数最小并求得回归参数(θ)
6. 构造预测函数h(x)
1) Logistic函数(或称为Sigmoid函数),函数形式为:
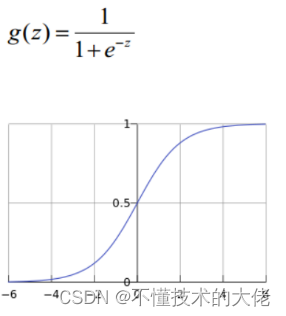
对于线性边界的情况,边界形式如下:
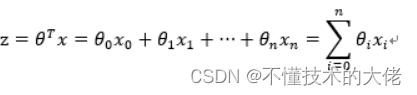
其中,训练数据为向量

函数h(x)的值有特殊的含义,它表示结果取1的概率,因此对于输入x分类结果为类别1和类别0的概率分别为:
P(y=1│x;θ)=h_θ (x)
P(y=0│x;θ)=1-h_θ (x)
7.构造损失函数J(m个样本,每个样本具有n个特征)
Cost函数和J函数如下,它们是基于最大似然估计推导得到的。
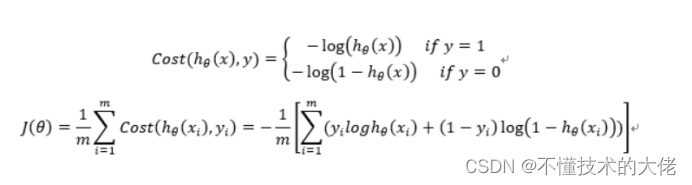
8. 损失函数详细推导过程
1) 求代价函数
概率综合起来写成:
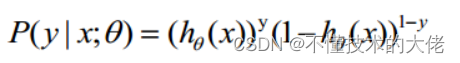
取似然函数为:
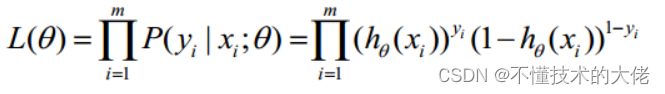
对数似然函数为:

最大似然估计就是求使l(θ)取最大值时的θ,其实这里可以使用梯度上升法求解,求得的θ就是要求的最佳参数。
在Andrew Ng的课程中将J(θ)取为下式,即:

- 梯度下降法求解最小值

θ更新过程可以写成:
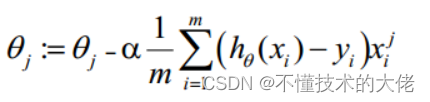
9. 向量化
ectorization是使用矩阵计算来代替for循环,以简化计算过程,提高效率。
向量化过程:
约定训练数据的矩阵形式如下,x的每一行为一条训练样本,而每一列为不同的特称取值:

g(A)的参数A为一列向量,所以实现g函数时要支持列向量作为参数,并返回列向量。
θ更新过程可以改为:

综上所述,Vectorization后θ更新的步骤如下:
- 求 A=x*θ
- 求 E=g(A)-y

10.正则化
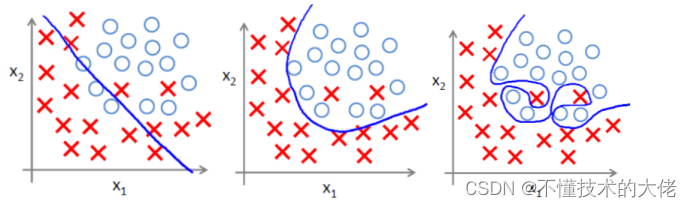
(1) 过拟合问题
过拟合即是过分拟合了训练数据,使得模型的复杂度提高,繁华能力较差(对未知数据的预测能力)
下面左图即为欠拟合,中图为合适的拟合,右图为过拟合。
(2)过拟合主要原因
过拟合问题往往源自过多的特征
解决方法
1)减少特征数量(减少特征会失去一些信息,即使特征选的很好)
• 可用人工选择要保留的特征;
• 模型选择算法;
2)正则化(特征较多时比较有效)
• 保留所有特征,但减少θ的大小
(3)正则化方法
正则化是结构风险最小化策略的实现,是在经验风险上加一个正则化项或惩罚项。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化项就越大。
正则项可以取不同的形式,在回归问题中取平方损失,就是参数的L2范数,也可以取L1范数。取平方损失时,模型的损失函数变为:
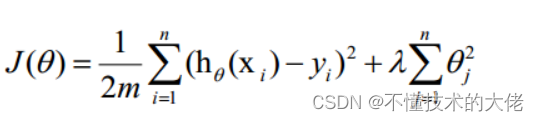
lambda是正则项系数:
• 如果它的值很大,说明对模型的复杂度惩罚大,对拟合数据的损失惩罚小,这样它就不会过分拟合数据,在训练数据上的偏差较大,在未知数据上的方差较小,但是可能出现欠拟合的现象;
• 如果它的值很小,说明比较注重对训练数据的拟合,在训练数据上的偏差会小,但是可能会导致过拟合。
正则化后的梯度下降算法θ的更新变为:

11、Python实现逻辑回归:
from sklearn.linear_model import LogisticRegression
Model = LogisticRegression()
Model.fit(X_train, y_train)
Model.score(X_train,y_train)
# Equation coefficient and Intercept
Print(‘Coefficient’,model.coef_)
Print(‘Intercept’,model.intercept_)
# Predict Output
Predicted = Model.predict(x_test)
-----部分内容参考自:逻辑回归 - 理论篇_pakko的博客-CSDN博客_逻辑回归 二项分布
二、K-means算法
1、概述
K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
k-means 算法接受参数 k ,然后将事先输入的n个数据对象划分为 k个聚类以便使得所获得的聚类满足,同一聚类中的对象相似度较高,而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。
2、实现原理
KMeans算法的基本思想是初始随机给定K个簇中心,按照最邻近原则把待分类样本点分到各个簇。然后按平均法重新计算各个簇的质心,从而确定新的簇心。一直迭代,直到簇心的移动距离小于某个给定的值。
K-Means聚类算法主要分为三个步骤:
(1)第一步是为待聚类的点寻找聚类中心;
(2)第二步是计算每个点到聚类中心的距离,将每个点聚类到离该点最近的聚类中去;
(3)第三步是计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心;
反复执行(2)、(3),直到聚类中心不再进行大范围移动或者聚类次数达到要求为止。
下图展示了对n个样本点进行K-means聚类的效果,这里k取2:
(a)未聚类的初始点集;
(b)随机选取两个点作为聚类中心;
(c)计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去;
(d)计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心;
(e)重复(c),计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去;
(f)重复(d),计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心。
该算法的最大优势在于简洁和快速。算法的关键在于初始中心的选择和距离公式。
K的取值:
确定聚类数K没有最佳的方法,通常需要根据具体的问题由人工进行选择。非监督聚类没有比较直接的聚类评估方法,但是可以从簇内的稠密程度和簇间的离散程度来评估聚类的效果。最常见的方法有轮廓系数Silhouette Coefficient和Calinski-Harabaz Index。其中Calinski-Harabaz Index计算直接简单,得到的结果越大则聚类效果越好。计算公式如下:
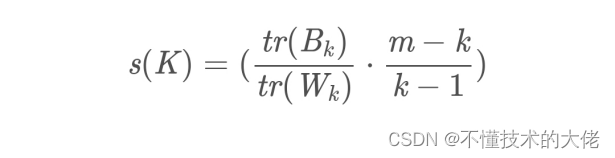
其中:m为训练集样本数,k为类别数。Bk为类别之间的协方差矩阵,Wk为内部数据之间的协方差矩阵。tr为矩阵的迹。
也就是说内部数据的协方差越小越好,类别之间的协方差越大越好,这样对应的Calinski-Harabaz Index分数也就越高
主要步骤:
在N个数据中,随机挑选K个数据(也就是最后聚类为K类)做为聚类的初始中心。
分别计算每个数据点到这K个中心点的欧式距离,离哪个中心点最近就分配到哪个簇中。
重新计算这K个簇数据的坐标均值,将新的均值作为聚类的中心。
重复2和3步骤,直到簇中心的坐标不再变换或者达到规定的迭代次数,形成最终的K个聚类。
k-Means算法,也被称为k-平均或k-均值,是一种广泛使用的聚类算法,或者成为其他聚类算法的基础。
假定输入样本为S=x.....m,则算法步骤为:
选择初始的k个类别中心μ2.Hk
对于每个样本x;,将其标记为距离类别中心最近的类别,即:
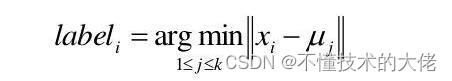
将每个类别中心更新为隶属该类别的所有样本的均值

重复最后两步,直到类别中心的变化小于某阈值。
中止条件:
迭代次数)簇中心变化率/最小平方误差MSE(Minimum Squared Error)
记K个簇中心为M,μ,,k,每个簇的样本数目为N,N2,..,N
使用平方误差作为目标函数:
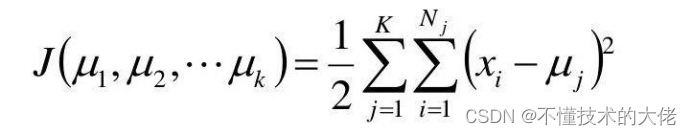
对关于从,....,Hp的函数求偏导,其驻点为:

- k-Means聚类方法总结
(1)优点:
是解决聚类问题的一种经典算法,简单、快速对处理大数据集,该算法保持可伸缩性和高效率当簇近似为高斯分布时,它的效果较好
(2)缺点:
在簇的平均值可被定义的情况下才能使用,可能不适用于某些应用
必须事先给出k(要生成的簇的数目),而且对初值敏感,对于不同的初始值,可能会导致不同结果。
不适合于发现非凸形状的簇或者大小差别很大的簇对躁声和孤立点数据敏感
但可作为其他聚类方法的基础算法,如谱聚类。 - 用JAVA实现代码:
class point {
public float x = 0;
public float y = 0;
public int flage = -1;
public float getX() {
return x;
}
public void setX(float x) {
this.x = x;
}
public float getY() {
return y;
}
public void setY(float y) {
this.y = y;
}
}
public class Kcluster {
point[] ypo;// 点集
point[] pacore = null;// old聚类中心
point[] pacoren = null;// new聚类中心
// 初试聚类中心,点集
public void productpoint() {
Scanner cina = new Scanner(System.in);
System.out.print("请输入聚类中点的个数(随机产生):");
int num = cina.nextInt();
ypo = new point[num];
// 随机产生点
for (int i = 0; i < num; i++) {
float x = (int) (new Random().nextInt(10));
float y = (int) (new Random().nextInt(10));
ypo[i] = new point();// 对象创建
ypo[i].setX(x);
ypo[i].setY(y);
}
// 初始化聚类中心位置
System.out.print("请输入初始化聚类中心个数(随机产生):");
int core = cina.nextInt();
this.pacore = new point[core];// 存放聚类中心
this.pacoren = new point[core];
Random rand = new Random();
int temp[] = new int[core];
temp[0] = rand.nextInt(num);
pacore[0] = new point();
pacore[0].x = ypo[temp[0]].x;
pacore[0].y = ypo[temp[0]].y;
pacore[0].flage = 0;
// 避免产生重复的中心
for (int i = 1; i < core; i++) {
int flage = 0;
int thistemp = rand.nextInt(num);
for (int j = 0; j < i; j++) {
if (temp[j] == thistemp) {
flage = 1;// 有重复
break;
}
}
if (flage == 1) {
i--;
} else {
pacore[i] = new point();
pacore[i].x = ypo[thistemp].x;
pacore[i].y = ypo[thistemp].y;
pacore[i].flage = 0;// 0表示聚类中心
}
}
System.out.println("初始聚类中心:");
for (int i = 0; i < pacore.length; i++) {
System.out.println(pacore[i].x + " " + pacore[i].y);
}
}
// ///找出每个点属于哪个聚类中心
public void searchbelong()// 找出每个点属于哪个聚类中心
{
for (int i = 0; i < ypo.length; i++) {
double dist = 999;
int lable = -1;
for (int j = 0; j < pacore.length; j++) {
double distance = distpoint(ypo[i], pacore[j]);
if (distance < dist) {
dist = distance;
lable = j;
// po[i].flage = j + 1;// 1,2,3......
}
}
ypo[i].flage = lable + 1;
}
}
// 更新聚类中心
public void calaverage() {
for (int i = 0; i < pacore.length; i++) {
System.out.println("以<" + pacore[i].x + "," + pacore[i].y + ">为中心的点:");
int numc = 0;
point newcore = new point();
for (int j = 0; j < ypo.length; j++) {
if (ypo[j].flage == (i + 1)) {
System.out.println(ypo[j].x + "," + ypo[j].y);
numc += 1;
newcore.x += ypo[j].x;
newcore.y += ypo[j].y;
}
}
// 新的聚类中心(就是所有聚合点的中心)
pacoren[i] = new point();
pacoren[i].x = newcore.x / numc;//所有聚类元素x坐标的和/元素数
pacoren[i].y = newcore.y / numc;
pacoren[i].flage = 0;
System.out.println("新的聚类中心:" + pacoren[i].x + "," + pacoren[i].y);
}
}
public double distpoint(point px, point py) {
return Math.sqrt(Math.pow((px.x - py.x), 2) + Math.pow((px.y - py.y), 2));
}
public void change_oldtonew(point[] old, point[] news) {
for (int i = 0; i < old.length; i++) {
old[i].x = news[i].x;
old[i].y = news[i].y;
old[i].flage = 0;// 表示为聚类中心的标志。
}
}
public void movecore() {
// this.productpoint();//初始化,样本集,聚类中心,
this.searchbelong();
this.calaverage();//
double movedistance = 0;
int biao = -1;// 标志,聚类中心点的移动是否符合最小距离
for (int i = 0; i < pacore.length; i++) {
movedistance = distpoint(pacore[i], pacoren[i]);//计算新旧两个中心点的距离
System.out.println("distcore:" + movedistance);// 聚类中心的移动距离
if (movedistance < 0.01) {
biao = 0;
} else {
biao = 0;
} else {
biao = 1;// 需要继续迭代,
break;
}
}
if (biao == 0) {
System.out.print("迭代完毕!!!!!");
} else {
change_oldtonew(pacore, pacoren);
movecore();
}
}
public static void main(String[] args) {
// TODO Auto-generated method stub
Kcluster kmean = new Kcluster();
kmean.productpoint();
kmean.movecore();
}
}
----部分内容参考自:https://blog.csdn.net/weixin_40479663/article/details/82974625?utm_source=app&app_version=4.10.0&code=app_1562916241&uLinkId=usr1mkqgl919blen