目录
4、Prometheus 支持的抓取数据的方式(基于白盒监控)
1、Prometheus Server:收集和储存时间序列数据
6、Data Visualization(Dashboards)
5、prometheusQL(数据查询语言也是时序数据库使用语言)
一、prometheus业务流向
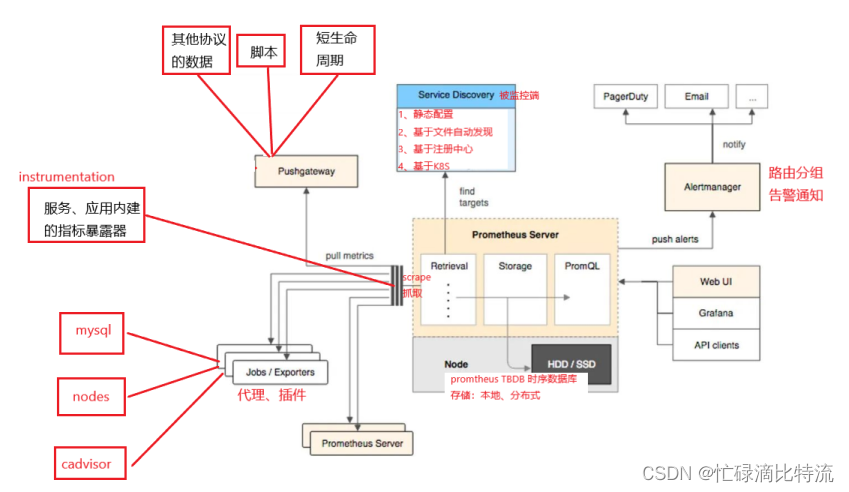
二、常用监控简介
1、cacti
Cacti(英文含义为仙人掌〉是一套基于 PHP、MySQL、SNMP和 RRDtool开发的网络流量监测图形分析工具。
它通过snmpget来获取数据,使用RRDTool绘图,但使用者无须了解RRDTool复杂的参数。它提供了非常强大的数据和用户管理功能,可以指定每一个用户能查看树状结构、主机设备以及任何一张图,还可以与LDAP 结合进行用户认证,同时也能自定义模板,在历史数据的展示监控方面,其功能相当不错。
2、Nagios
Nagios是一款开源的免费网络监视工具,能有效监控windows、Linux和Unix的主机状态,交换机路由器等网络设置打印机等。在系统或服务状态异常时发出邮件或短信报警第一时间通知网站运维人员,在状态恢复后发出正常的邮件或短信通知。
nagios主要的特征是监控告警,最强大的就是告警功能,可支持多种告警方式,但缺点是没有强大的数据收集机制,并且数据出图也很简陋,当监控的主机越来越多时,添加主机也非常麻烦,配置文件都是基于文本配置的,不支持web方式管理和配置,这样很容易出错,不宜维护。
3、Zabbix
zabbix是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案。zabbix能监视各种网络参数,保证服务器系统的安全运营;并提供强大的通知机制以让系统运维人员快速定位/解决存在的各种问题。
zabbix数据采集方式:
①zabbix的push模式:会在采集的对象服务器上放置agent代理,通过agent代理采集的数据,推送(push)给zabbix,但当监控的对象数量庞大,超过两百以上时,就会出问题,不能抗高并发。
②zabbix的pull模式:自行到对象服务器拉取。自行可避开高并发时期。
4、Prometheus
borg.kubernetes
borgmon(监控系统) 对应克隆的版本:prometheus(go语言)、prometheus 特别适合K8S 的架构上
promtheus特性
① 多维的数据模型(基于时间序列的Key、value键值对)
② 灵活的查询和聚合语言PromQL
③ 提供本地存储和分布式存储
④ 通过基于HTTP和HTTPS的Pull模型采集时间序列数据(pull数据的推送,时间序列:每段
时间点的数据值指标,持续性的产生。横轴标识时间,纵轴为数据值,一段时间内数值的动态变化,所有的点连线形成大盘式的折线图)
⑤ 可利用Pushgateway (Prometheus的可选中间件)实现Push模式
⑥ 可通过动态服务发现或静态配置发现目标机器(通过consul自动发现和收缩)
⑦ 支持多种图表和数据大盘
5、监控的迭代
1、传统
①、比较繁琐,使用nagios 传统监控(硬件和软件都可以监控)
②、云平台(共有、私有、混合、专有(定制化)),使用zabbix,集中到平台中
2、运维同步进步
虚拟化、容器(主传统)vsphere系列,资源管理器管理容器系列k8s,使用prometheus
三、运维监控平台设计思路
①、数据收集模块
②、数据提取模块
③、监控告警模块
四、监控体系
1、系统层监控(需要监控的数据)
包括:
硬件方向:CPU、Load、Memory、swap、disk i/o、process等
网络监控方向:网络设备、工作负载、网络延迟、丢包率等
2、中间件及基础设施类监控
包括:
消息中间件:kafka、RocketMQ、等消息代理
WEB服务器容器:tomcat
数据库/缓存数据库:MySQL、PostgreSQL、MogoDB、es、redis
redis的主监控内容:
①、redis所在服务器的系统层监控
②、redis 服务状态
③、RDB AOF日志监控(日志——>如果是哨兵模式——>哨兵共享集群信息,产生的日志——>直接包含的其他节点哨兵信息及mysql信息)
3、应用层监控
包括:用于衡量应用程序代码状态和性能
监控的分类:黑盒监控,白盒监控
功能:
白盒监控,自省指标,等待被下载
黑盒指标:基于探针的监控方式,不会主动干预、影响数据
4、 业务层监控
用于衡量应用程序的价值
五、prometheus的场景使用
适合的场景:
Prometheus可以很好地记录任何纯数字时间序列(它自生也是一种时序数据库TSDB),它既适用于以机器为中心的监视,也适用于高度动
态的面向服务的体系结构的监视。在微服务世界中,它对多维数据收集和查询的支持是一种特别的优势。(k8s)
Prometheus是为可靠性而设计的,它是您在中断期间要使用的系统,可让您快速诊断问题。每个
Prometheus服务器都是独立的,而不依赖于网络存储或其他远程服务。当基础结构的其他部分损
坏时,您可以依靠它,并且无需设置广泛的基础结构即可使用它
不适合的场景:
普罗米修斯重视可靠性。即使在故障情况下,您始终可以查看有关系统的可用统计信息。如果您需
要100%的准确性(例如按请求计费),则Prometheus并不是一个不错的选择,因为所收集的数据
可能不会足够详细和完整。
六、prometheus 时序数据
1、时序数据定义
是在一段时间内通过重复测量(measurement)而获得的观测值的集合将这些观测值绘制于图形之上,它会有一个数据轴和一个时间轴,服务器指标数据、应用程序性能监控数据、网络数据等也都是时序数据。

按照某个时序以时间维度采集的数据,称之为样本。
2、数据来源
prometheus基于HTTP call (http/https请求),从配置文件中指定的网络端点(endpoint/IP:端口)上周期性获取指标数据。很多环境、被监控对象,本身是没有直接响应/处理http请求的功能prometheus-exporter则可以在被监控端收集所需的数据,收集过来之后,还会做标准化,把这些数据转化为prometheus可识别,可使用的数据(兼容格式)
3、收集数据
监控概念:白盒监控、黑盒监控
白盒监控:自省方式。被监控端内部,可以自己生成指标,只要等待监控系统来采集时提供出去即可。
黑盒监控:对于被监控系统没有侵入性,对其没有直接"影响",这种类似于基于探针机制进行监控(snmp协议)
4、Prometheus 支持的抓取数据的方式(基于白盒监控)
①、Exporters ——>会聚合源数据,工作在被监控端,周期性的抓取数据并转换为prometheus兼容格式等待prometheus来收集,自己并不推送。
②、Instrumentation(内建指标暴露器) ——>指被监控对象内部自身有数据收集、监控的功能,只需要prometheus直接去获取。
③、Push gateway ——>短周期5s—10s的数据收集。
PS:exporter、instrumentation和push gateway 分别采集的是什么数据
——》exproter:相当于插件或代理形式的指标暴露器,类似于zabbix的agent
——》instrumentation:内建的指标暴露器,可直接被Prometheus过来拿,例如cadvisor
——》push gateway:①、不方便使用http/https协议暴露指标数据的一些指标数据
②、短周期任务—》指的是不易被周期性pull捕捉到的数据
5、prometheus(获取方式的优势)
Prometheus同其它TSDB相比有一个非常典型的特性:它主动从各Target上拉取(pull)数据,而非等待被监控端的推送(push)
Pull模型的优势:
集中控制:有利于将配置集在Prometheus server上完成,包括指标及采取速率等;
Prometheus的根本目标在于收集在target上预先完成聚合的聚合型数据,而非一款由事件驱动的存
储系统通过targets(标识的是具体的被监控端)
七、prometheus生态组件
prometheus生态圈中包含了多个组件,其中部分组件可选。下面介绍几个主要的:
1、Prometheus Server:收集和储存时间序列数据
通过scrape以抓取的方式去获取数据放入storge(TSDB时序数据库),制定Rules/Alerts:告警规
则,service discovery是自动发现需要监控的节点。
2、Client Library:客户端库
目的在于为那些期望原生提供Instrumentation功能的应用程序提供便捷的开发途径
3、Push Gateway:
接收那些通常由短期作业生成的指标数据的网关,并支持由Prometheus Server进行指标拉取操作
4、Exporters
用于暴露现有应用程序或服务(不支持Instrumentation)的指标给Prometheus Server,而Prometheus内建了数据样本采集器,可以通过配置文件定义,告诉prometheus到那个监控对象中采集指标数据,prometheus 采集过后,会存储在自己内建的TSDB数据库中,提供了promQL 支持查询和过滤操作,同时支持自定义规则来作为告警规则,持续分析一场指标,一旦发生,通知给alerter来发送告警信息,还支持对接外置的UI工具(grafana)来展示数据
采集、抓取数据是其自身的功能,但一般被抓去的数据一般来自于:
export/instrumentation (指标数据暴露器) 来完成的,或者是应用程序自身内建的测量系统
5、Alertmanager:告警
由告警规则对接,从Prometheus Server接收到"告警通知"后,通过去重、分组、路由等预处理功能后以高效向用户完成告警信息发送
6、Data Visualization(Dashboards)
与TSDB对接并且展示数据库中的数据,Prometheus web UI (Prometheus Server内建),及Grafana等
7、Service Discovery
动态发现待监控的Target,从而完成监控配置的重要组件,在容器化环境中尤为有用;该组件目前由PropetheusServer内建支持
八、prometheus数据模型
1、标签、指标、样本
prometheus用键值方式存储时序式的聚合数据,他不支持文本信息,prometheus最总表达的是一种趋线图等图形的表达方式。prometheus以键值对的方式,以横轴为时间,纵轴为数据的方式来表示,每一个单位时间点即为具体的一个value值,然后把每个时刻的value值汇聚成所需要的趋势图。
其中的"键"称为指标(metric),通常意味着cpu速率、内存使用率或分区空闲比例等。
同一指标可能适配到多个目标或设备、因而它使用"标签"作为元数据,从而为metric添加更多的信息描述
某个时刻的value值即为样本

2、样本包含的对象
prometheus每一份样本数据都包含了:
① 时序列标识:key+lables
② 当前时间序列的样本值value
③ 这些标签可以作为过滤器进行指标过滤及聚合运算,如何从上万的数据过滤出关键有限的时间序列,同时从有限的时间序列在特定范围的样本那就需要手动编写出时间序列的样本表达式来过滤出我们需求的样本数据
3、指标类型
默认都是以双精度浮点型数据
1、默认都是以双精度浮点型数据
2、gauge:仪表盘:有起伏特征的
3、histogram:直方图:
在一段时间范围内对数据采样的相关结果,并记入配置的bucket中,他可以存储更多的数据,包括样本值分布在每个bucket的数量,从而prometheus就可以使用内置函数进行计算。
计算样本平均值:以值得综合除以值的数量。
计算样本分位值:分位数有助于了解符合特定标准的数据个数,例如评估响应时间超过1秒的请求比例,若超过20%则进行告警等
4、summary,摘要,histogram的扩展类型,它是直接由监控端自行聚合计算出分位数,同时
将计算结果响应给prometheus server的样本采集请求,因而,其分位数计算是由监控端完成。
4、job、targets/instance
在配置文件中的位置,对应的页面参数位置
1、 job:能够接收prometheus server数据scrape
2、 targets:每一个可以被监控的系统,成为targets多个相同的targets的集合(类)称为job
3、 instance:实例 与 targets(类似)
与target相比,instance更趋近于一个具体可以提供监控数据的实例,而targets则更像一个对象、目标性质
[root@zwb_prometheus prometheus-2.27.1.linux-amd64]# pwd
/usr/local/prometheus-2.27.1.linux-amd64
[root@zwb_prometheus prometheus-2.27.1.linux-amd64]# cat prometheus.yml


5、prometheusQL(数据查询语言也是时序数据库使用语言)
支持两种向量,同时内置提供了一组用于数据处理的函数
① 即时向量:最近以此时间戳上跟踪的数据指标(一个时间点上的数据)
即时向量选择器:返回0个1个或者多个时间序列上在给定时间戳上的各自的一个样本,
该样本成为即时样本
② 时间范围向量:指定时间范围内所有时间戳上的数据指标
范围向量选择器:返回0个1个或多个时间序列上在给定时间范围内的各自的一组样本
(范围向量选择器无法用于绘图)