目录
3、上传prometheus安装包到opt下,进行安装(192.168.159.68)
4、配置node_exporter(192.168.159.11、192.168.159.10)
5、配置prometheus节点的配置文件(192.168.159.68)
一、Prometheus的部署
1、实验环境
| 主机 | IP | 安装包 |
| prometheus | 192.168.159.68 | prometheus |
| server1 | 192.168.159.11 | node_exporter |
| server2 | 192.168.159.10 | node_exporter |
2、环境初始话
systemctl stop firewalld
systemctl disable firewalld
setenforce 0ntpdate ntp1.aliyun.com ####时间同步,必须要做的
3、上传prometheus安装包到opt下,进行安装(192.168.159.68)
[root@zwb_docker opt]# rz -E
rz waiting to receive.
[root@zwb_docker opt]# tar zxvf prometheus-2.27.1.linux-amd64.tar.gz -C /usr/local/
安装完成,启动prometheus
[root@zwb_docker prometheus-2.27.1.linux-amd64]# ./prometheus
prometheus启动后会占用前端界面,复制会话,重新打开另一个界面进行操作。
查看端口是否开启
[root@zwb_prometheus ~]# ss -antp | grep 9090
LISTEN 0 128 :::9090 :::* users:(("prometheus",pid=11006,fd=8))
ESTAB 0 0 ::ffff:192.168.159.68:9090 ::ffff:192.168.159.1:62136 users:(("prometheus",pid=11006,fd=21))
ESTAB 0 0 ::1:9090 ::1:51520 users:(("prometheus",pid=11006,fd=13))
ESTAB 0 0 ::ffff:192.168.159.68:9090 ::ffff:192.168.159.1:62135 users:(("prometheus",pid=11006,fd=18))
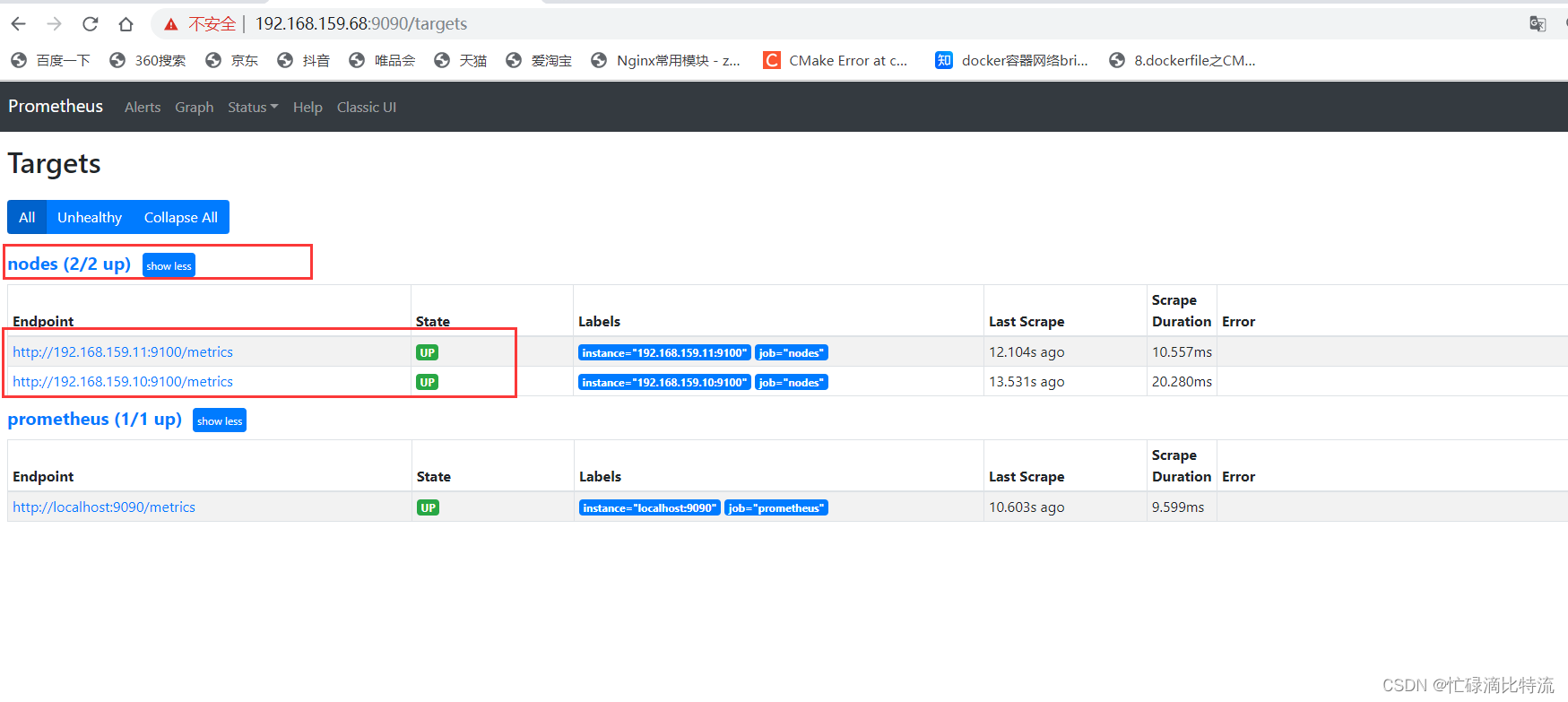
查看WEB页面

4、配置node_exporter(192.168.159.11、192.168.159.10)
两个节点的配置方法一样
[root@zwb opt]# rz -E ### 上传
rz waiting to receive.
[root@zwb opt]# tar zxvf node_exporter-1.1.2.linux-amd64.tar.gz ### 解压
-C /usr/local/
[root@zwb opt]# cd /usr/local/node_exporter-1.1.2.linux-amd64/[root@zwb node_exporter-1.1.2.linux-amd64]# mv node_exporter /ur/bin/
#############移动执行脚本到全局环境变量下
开启node_exporter
[root@zwb node_exporter-1.1.2.linux-amd64]# node_exporter
5、配置prometheus节点的配置文件(192.168.159.68)

6、重启prometheus,查看页面
如果整体关机后,开机需要重新启动prometheus和exporter
7、采集数据流向
prometheus节点通过收集。被监测点的node_exporter周期性抓取数据并转化为prometheus兼容格式。node_exporter被监测点的信息需要在prometheus节点配置。
二、配置文件解析
prometeus配置文件prometeus.yml的组成
## 用于定义全局配置,主要定义的是周期。一个是scrape周期,一个自动识别、更新配置文件的周期
# my global config
global:
scrape_interval: 15s# Set the scrape interval to every 15 seconds. Default is every 1 minute.
# 用来指定Prometheus从监控端抓取数据的时间间隔
evaluation_interval: 15s# Evaluate rules every 15 seconds. The default is every 1 minute.
# 用于指定检测告警规则的时间间隔,每15s重新检测告警规则,并对变更进行更新
# scrape_timeout is set to the global default (10s).# 定义拉取实例指标的超时时间
## 用于设置Prometheus与Alertmanager的通信,在Prometheus的整体架构中,Prometheus会根据配置的告警规则触发警报并发送到独立的Alertmanager组件,Alertmanager将对告警进行管理并发送给相关的用户
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs: ### 配置alertmanager的地址信息
- targets:
# - alertmanager:9093# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files: ### 用于指定告警规则的文件路径,告警逻辑(写了布尔值表达式文件的文件名)
# - "first_rules.yml"
# - "second_rules.yml"# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs: ### 指定Prometheus抓取的目标信息(采集数据的配置)
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.static_configs:
- targets: ['localhost:9090']- job_name: 'nodes' ### 自定义指定Prometheus抓取的目标信息
static_configs:
- targets:
- 192.168.159.11:9100
- 192.168.159.10:9100
三、表达式浏览器(prometheusUI控制台)
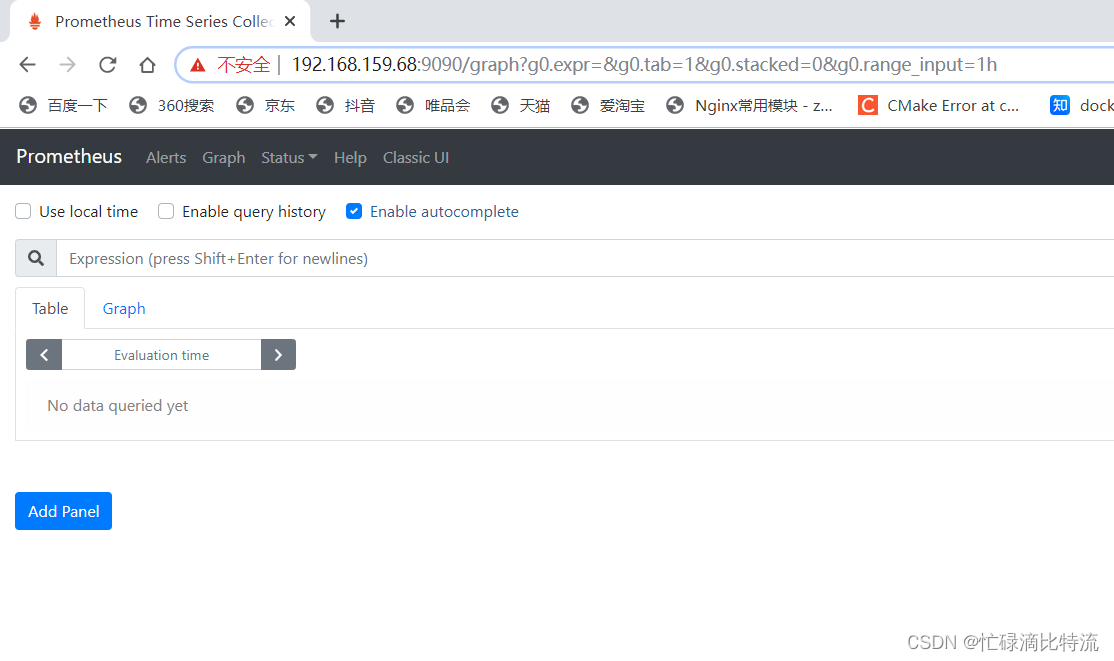
prometheus UI控制台上可以进行数据过滤
1、CPU使用总量
node_cpu_seconds_total
进阶1:计算过去5分钟内的CPU使用速率
PromQL:irate(node_cpu_seconds_total{mode="idle"}[5m])
irate:速率计算函数
node_cpu_seconds_total:node节点CPU使用总量
mode="idle" 空闲指标
5m:过去的5分钟内,所有CPU空闲数的样本值,每个数值做速率运算
四、Prometheus discovery 服务发现
prometheus指标抓取的生命周期
发现——》配置——》relabel——》指标数据抓取——》metrics relabel
发现:当peometheus启动,启动后发现被监控端
配置:定义怎么采集。怎么监控(周期),监控哪些节点
relabel:例如exporter采集数据后,需要转换成Pro能兼容识别的格式(时序数据格式),而这种转换就是聚合数据》
指标数据的抓取:pro pull数据
metrics relabel:重组
1、静态发现(上文自定义的指定抓取目标信息为静态方式)
- job_name: 'nodes' ### 自定义指定Prometheus抓取的目标信息
static_configs:
- targets:
- 192.168.159.11:9100
- 192.168.159.10:9100
2、动态发现
2.1、基于文件服务发现
基于文件的服务发现仅仅略优于静态配置的服务发现方式,它不依赖于任何平台或第三方服务,
因而也是最为简单和通用的实现方式。
2.1.1、动态发现基于文件服务发现实验部分
## 进入普罗米修斯的工作目录
[root@zwb_prometheus prometheus]# mkdir file_sd ## 创建file_sd目录
[root@zwb_prometheus prometheus]# ls
console_libraries consoles data file_sd LICENSE nohup.out NOTICE prometheus prometheus.yml promtool[root@zwb_prometheus prometheus]# cd file_sd/
[root@zwb_prometheus file_sd]# ls
[root@zwb_prometheus file_sd]# pwd
/usr/local/prometheus/file_sd
[root@zwb_prometheus file_sd]# mkdir targets ### 创建 targets目录
[root@zwb_prometheus file_sd]# ls
targets### 编辑3个配置文件
## 编辑 prometheus.yml文件
[root@zwb_prometheus file_sd]# vim /usr/local/prometheus/file_sd/prometheus.yml
[root@zwb_prometheus file_sd]# cat prometheus.yml
# my global config
# Author: MageEdu <[email protected]>
# Repo: http://gitlab.magedu.com/MageEdu/prometheus-configs/
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus' ### 指定job为prometheus
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
file_sd_configs: ### 将原先的静态改为文件发现
- files:
- targets/prometheus_*.yaml ### 指定加载的文件位置
refresh_interval: 2m ### 2分钟刷新一次
# All nodes
- job_name: 'nodes' ### 指定job为nodes
file_sd_configs:
- files:
- targets/nodes_*.yaml ### 指定加载的文件位置
refresh_interval: 2m ### 2分钟刷新一次[root@zwb_prometheus file_sd]# vim /usr/local/prometheus/file_sd/targets/prometheus_servers.yaml
- targets:
- 192.168.159.68:9090 ### 指定prometheus的位置
labels:
app: prometheus
job: prometheus ### 定义job为prometheus
[root@zwb_prometheus file_sd]# vim /usr/local/prometheus/file_sd/targets/nodes_linux.yaml
- targets: ### 指定nodes的位置
- 192.168.159.10:9100
- 192.168.159.11:9100
labels:
app: node-exporter
job: nodes ###指定job为nodes
### 新建目录和文件的存放位置关系
root@zwb_prometheus file_sd]# pwd
/usr/local/prometheus/file_sd
[root@zwb_prometheus file_sd]# tree ./
./
├── prometheus.yml
└── targets
├── nodes_linux.yaml
└── prometheus_servers.yaml1 directory, 3 files
启动prometheus
[root@zwb_prometheus prometheus]# pwd ###当前位置
/usr/local/prometheus
[root@zwb_prometheus prometheus]# ./prometheus --config.file=./file_sd/prometheus.yml### 通过指定启动文件的位置来启动,不让其启动时加载原先得配置文件
实验结构和配置文件自行对比;
3、
3、基于DNS发现
基于DNS的服务发现针对一组DNS域名进行定期查询,以发现待监控的目标查询时使用的DNS服务器由/etc/resolv.conf文件指定:该发现机制依赖于A、AAAA和SRv资源记录,且仅支持该类方法,尚不支持RFC6763中的高级DNS发现方式。
4、基于consul发现
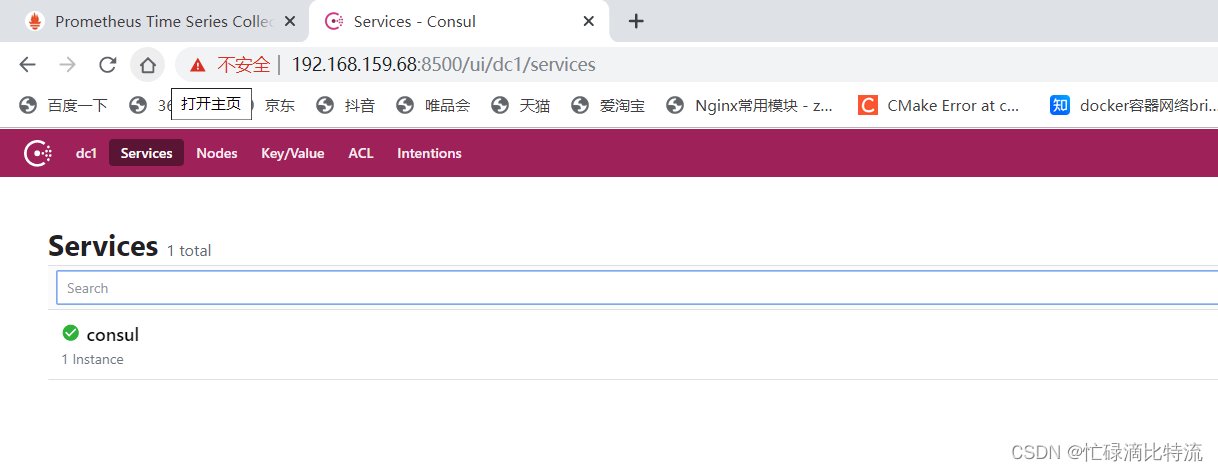
consul是一款基于golang开发的开源工具,主要面向分布式,服务化的系统提供服务注册、服务一发现和配置管理的功能提供服务注册/发现、健康检查、Key/Value存储、多数据中心和分布式一致性保证等功能
原理:通过定义json文件将可以进行数据采集的服务注册到consul中,用于自动发现同时使用prometheus做为client端获取consul上注册的服务,从而进行获取数据
4.1、consul服务部署
第一步:上传安装包(安装于prometheus主机上)
[root@zwb_prometheus opt]# rz -E
rz waiting to receive.
[root@zwb_prometheus opt]# ls
consul_1.9.0_linux_amd64.zip
第二步:解压安装包
[root@zwb_prometheus opt]# unzip consul_1.9.0_linux_amd64.zip
[root@zwb_prometheus opt]# unzip consul_1.9.0_linux_amd64.zip ## 解压
Archive: consul_1.9.0_linux_amd64.zip
inflating: consul
[root@zwb_prometheus opt]# ls
consul consul_1.9.0_linux_amd64.zip containerd lnmp.sh mysql-5.7.20 nginx-1.15.9 php-7.1.10 rh
[root@zwb_prometheus opt]# mv consul /usr/bin/ ## 加入到环境变量第三步:配置consul的配置文件
[root@zwb_prometheus opt]# mkdir -pv /etc/consul/data
mkdir: 已创建目录 "/etc/consul"
mkdir: 已创建目录 "/etc/consul/data"
[root@zwb_prometheus opt]# cd /etc/consul/
第四步:启动consul
[root@zwb_prometheus consul]# consul agent \
> -dev \
> -ui \
> -data-dir=/consul/data/ \
> -config-dir=/etc/consul/ \
> -client=0.0.0.0 &
注释:agent -dev:运行开发模式
agent -server:运行server模式
-ui:ui界面
-data-dir:数据位置
/etc/consul:可以以文件形式定义各个services的配置,也可以基于api接口直接配置
-client:监听地址
第五步:创建/etc/consul目录下的prometheus-servers.json配置文件
[root@zwb_prometheus consul]# vim /etc/consul/prometheus-servers.json
{
"services": [
{
"id": "prometheus-server-node01",
"name": "prom-server-node01",
"address": "192.168.159.68",
"port": 9090,
"tags": ["prometheus"],
"checks": [{
"http": "http://192.168.159.68:9090/metrics",
"interval": "5s"
第六步:重载consul配置文件
[root@zwb_prometheus consul]# consul reload
 第七步:创建consul自动发现的prometheus.yml文件
第七步:创建consul自动发现的prometheus.yml文件
[root@zwb_prometheus console_sd]# vim prometheus.yml
# my global config
# Author: MageEdu <[email protected]>
# Repo: http://gitlab.magedu.com/MageEdu/prometheus-configs/
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
consul_sd_configs:
- server: "192.168.159.68:8500"
tags:
- "prometheus"
refresh_interval: 2m
# All nodes
- job_name: 'nodes'
consul_sd_configs:
- server: "192.168.159.68:8500"
tags:
- "nodes"
refresh_interval: 2m
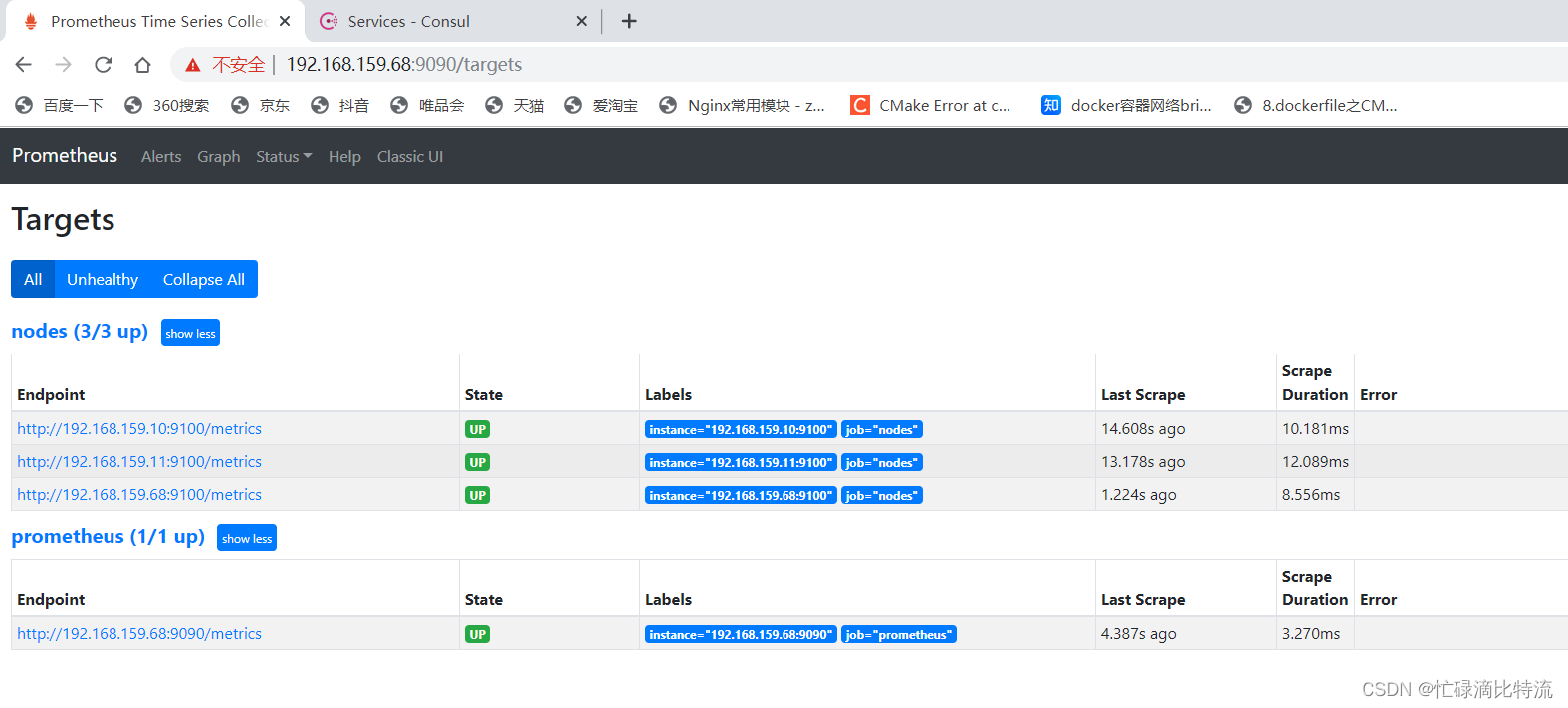
第八步:重启prometheus和consul
[root@zwb_prometheus console_sd]# killall prometheus
[root@zwb_prometheus prometheus]# ./prometheus --config.file=./consul_sd/prometheus.yml ### 指定上面配置的prometheus.yml启动时加载
第九步:注册其他node节点在Pro节点下consul的配置文件下配置
[root@zwb_prometheus consul_sd]# cd /etc/consul/
[root@zwb_prometheus consul]# vim nodes.json
{
"services": [
{
"id": "node_exporter-node01",
"name": "node01",
"address": "192.168.159.11",
"port": 9100,
"tags": ["nodes"],
"checks": [{
"http": "http://192.168.226.11:9100/metrics",
"interval": "5s"
}]
},
{
"id": "node_exporter-node02",
"name": "node02",
"address": "192.168.159.10",
"port": 9100,
"tags": ["nodes"],
"checks": [{
"http": "http://192.168.159.10:9100/metrics",
"interval": "5s"
}]
},
{
"id": "node_exporter-node03",
"name": "node03",
"address": "192.168.159.68",
"port": 9100,
"tags": ["nodes"],
"checks": [{
"http": "http://192.168.159.68:9100/metrics",
"interval": "5s"
}]
}
]
}
五、grafana部署
1、grafana简介
grafana是一款基于go语言开发的通用可视化工具,支持从不同的数据源加载并展示数据,可作为其数据源的部分储存系统如下所示:
TSDB:Prometheus、IfluxDB、OpenTSDB和Graphit
日志和文档存储:Loki和ElasitchSearch
分布式请求跟踪:Zipkin、Jaeger和Tenpo
SQL DB:Mysql、PostgreSQL和Microsoft SQL server
grafana基础默认监听于TCP协议的3000端口,支持集成其他认证服务,且能够通过/metrics输出内建指标;
数据源(Data Source):提供用于展示的数据的储存系统
仪表盘(Dashboard):组织和管理数据的可视化面板(Panel)
团队和用户:提供了面向企业组织层级的管理能力;
2、部署grafana
第一步:上传安装包
[root@server1 opt]# rz -E
rz waiting to receive.
第二步:第一种方法:直接在虚拟机环境安装。第二种方法:跑容器中
本实验中直接安装虚拟机环境中
[root@server1 opt]# yum -y install grafana-7.3.6-1.x86_64.rpm
#### yum 指定本地安装包,他在安装的同时会自动升级
第三步:开启grafana 服务
[root@server1 opt]# systemctl start grafana-server.service
[root@server1 opt]# vim /etc/grafana/grafana.ini
### 默认用户admin,密码admin。在配置文件中可修改密码

打开web:

第四步:创建监控的展现仪表盘
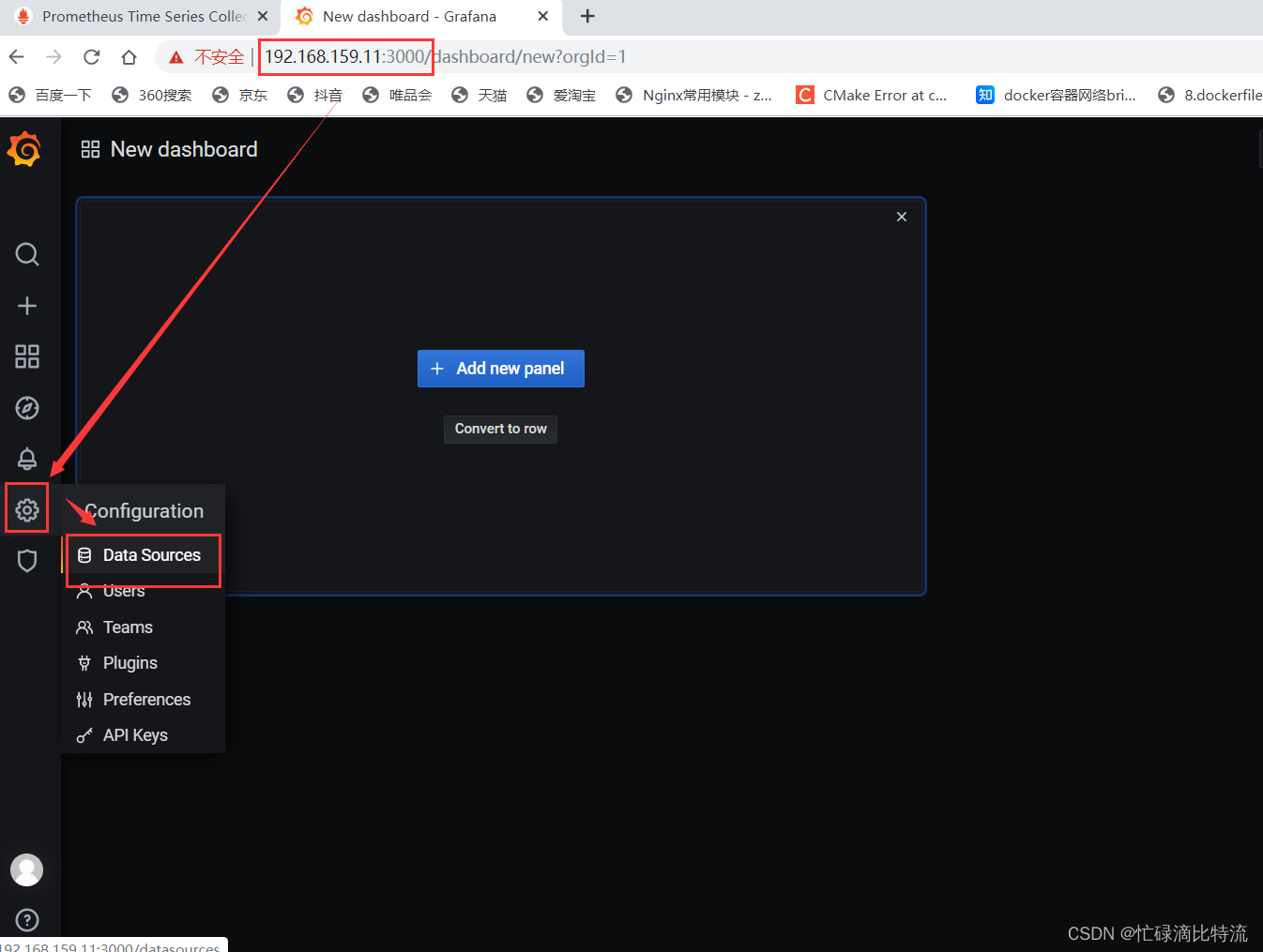
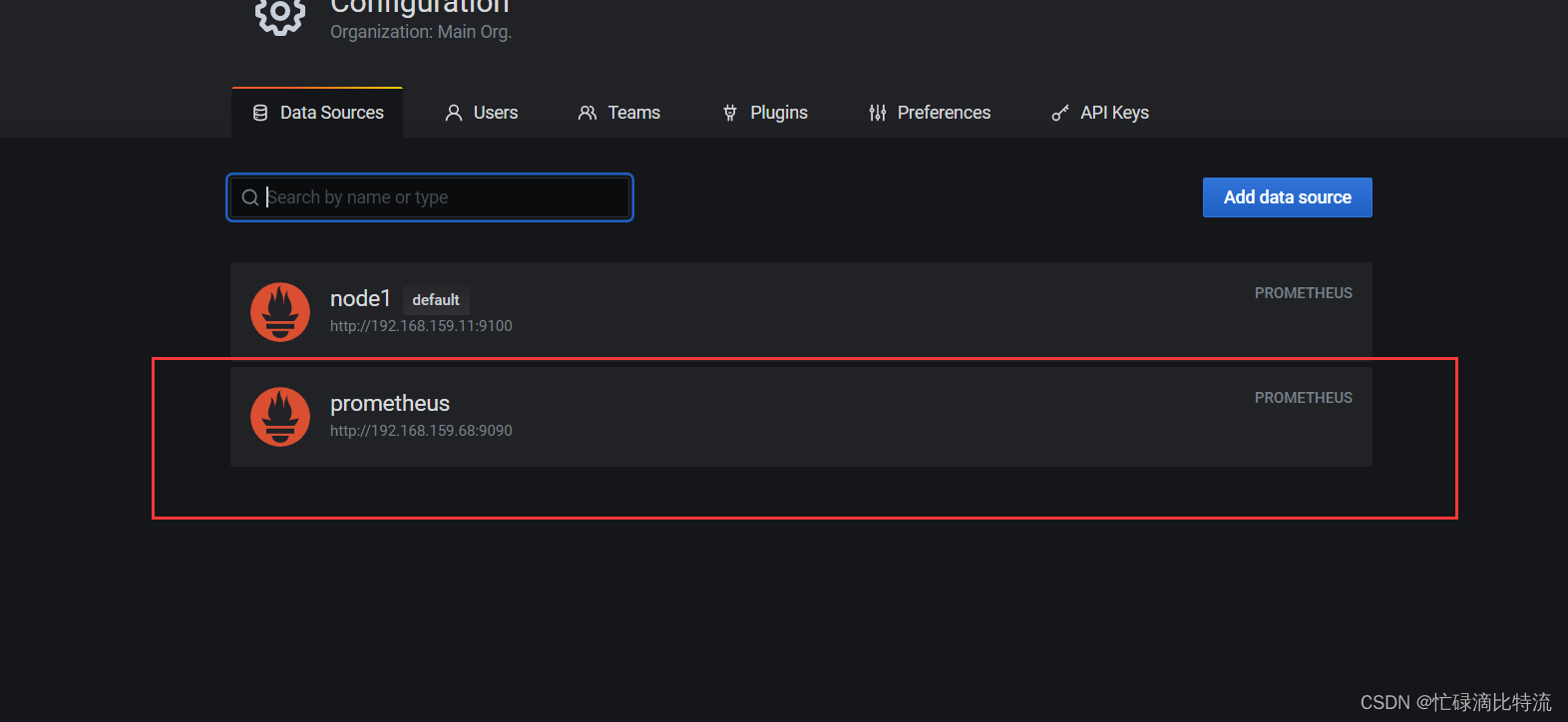

点击 



等待几分钟。会自行跳转
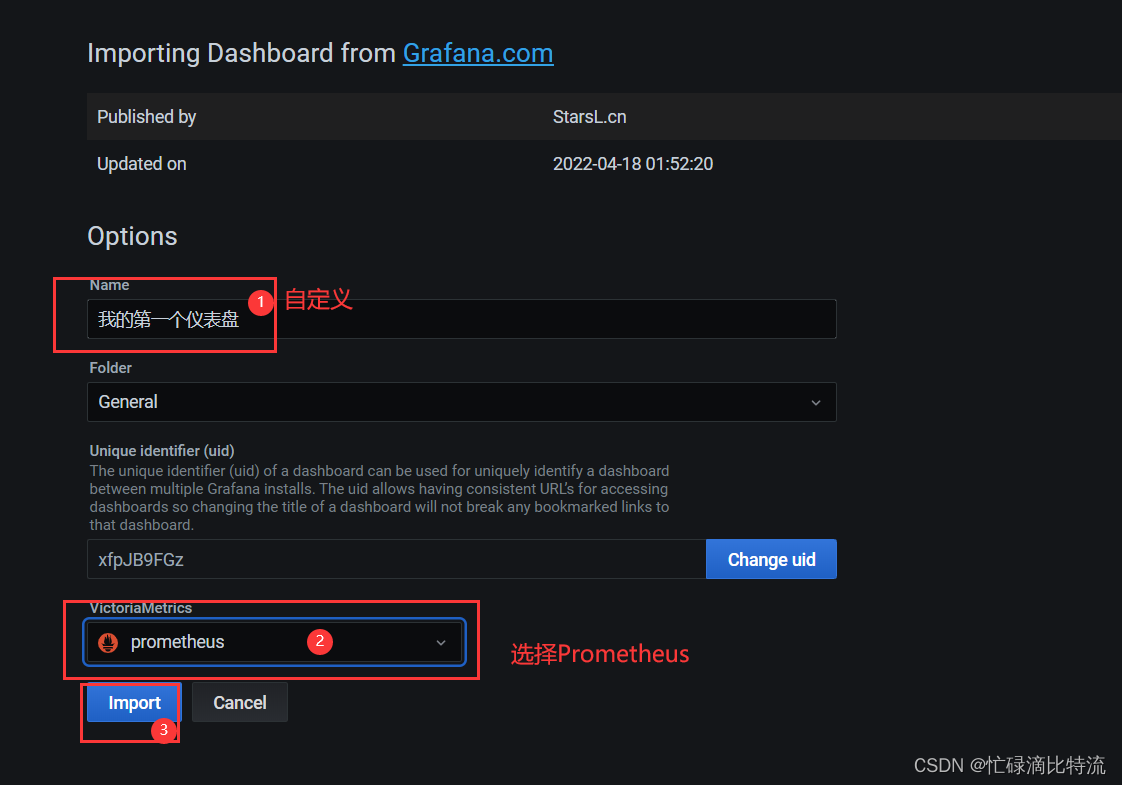
结果:

六、部署alertmanager,告警对接邮箱
第一步:安装在prometheus客户端处
[root@zwb_prometheus opt]# rz -E
rz waiting to receive.
[root@zwb_prometheus opt]# tar zxvf alertmanager-0.22.2.linux-amd64.tar.gz -C /usr/local/
[root@zwb_prometheus local]# mv alertmanager-0.22.2.linux-amd64/ alertmanager
### 修改目录名
### 查看配置文件
cat /usr/local/alertmanager/alertmanager.yml
route: #路由信息
group_by: ['alertname'] #分组
group_wait: 30s #分组缓冲/等待时间
group_interval: 5m #重新分组时间
repeat_interval: 1h #重新告警间隔
receiver: 'web.hook' #接收方/媒介
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/' #标注5001端口
inhibit_rules: #抑制规则的策略
- source_match: #匹配项
severity: 'critical' #严重的级别
target_match:
severity: 'warning' #target匹配warning级别
equal: ['alertname', 'dev', 'instance'] #符合alertname、dev、instance
第二步:邮箱设置
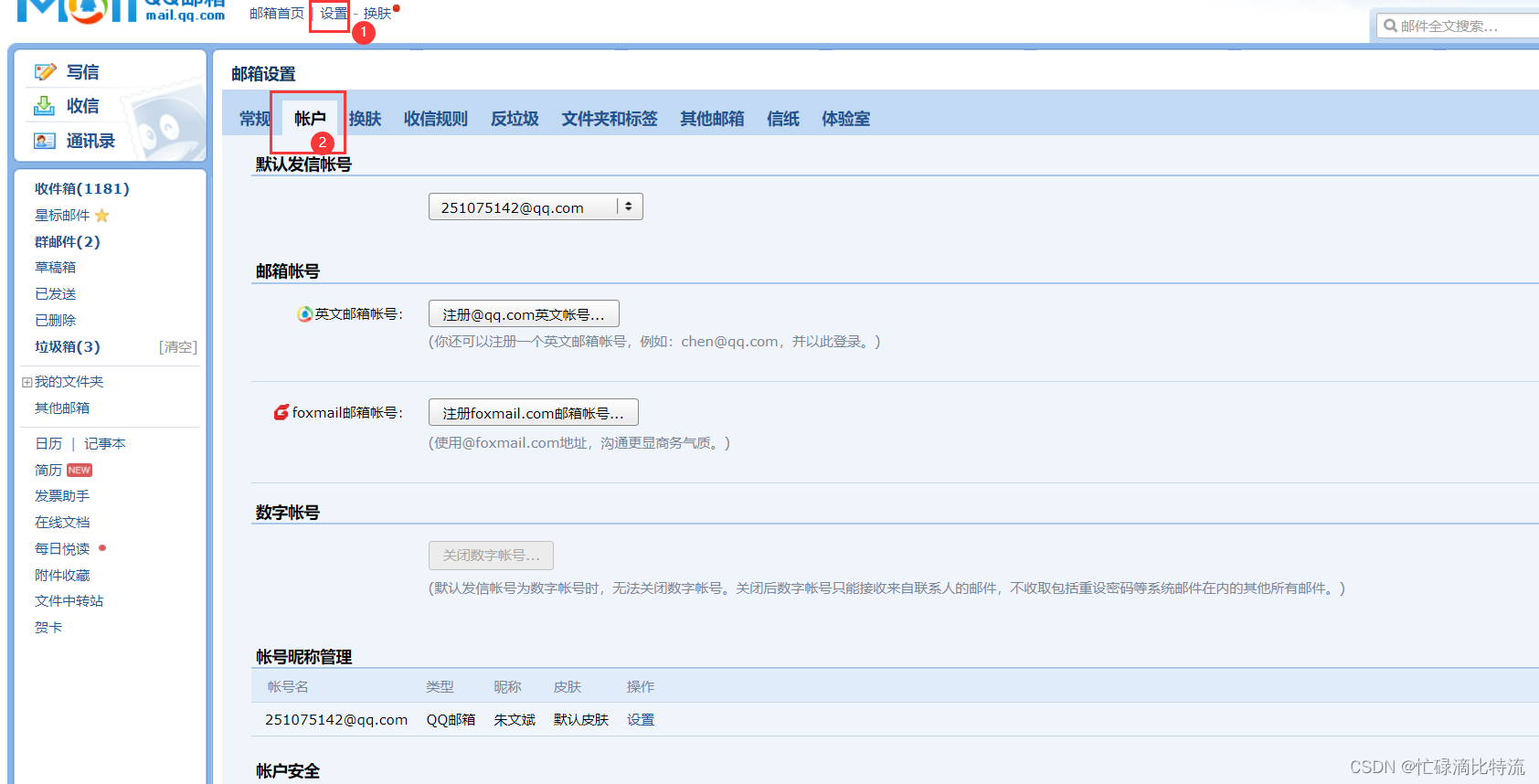
往下翻

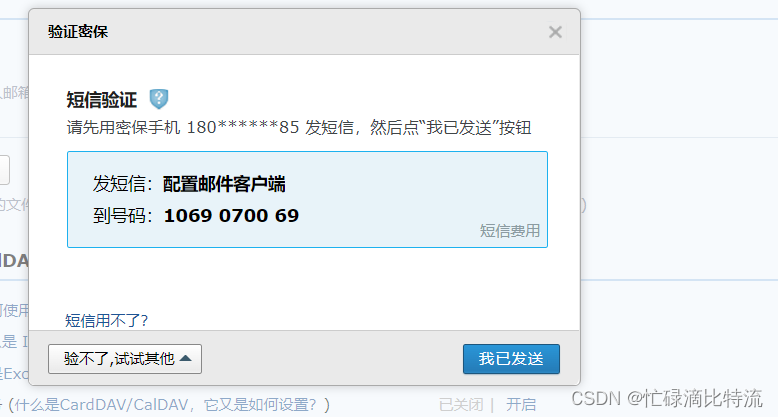
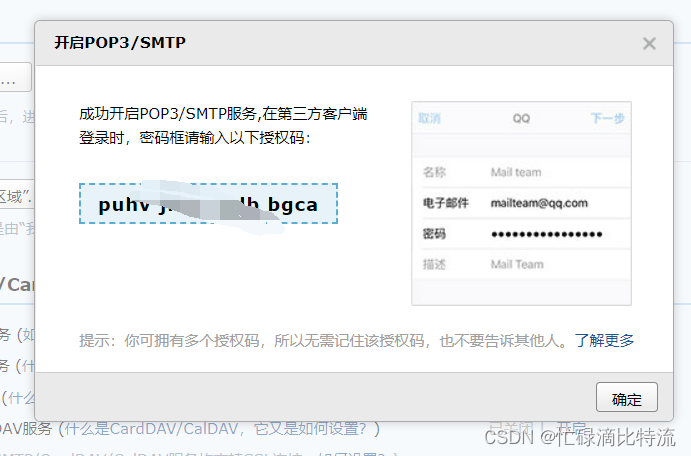 记录授权码
记录授权码
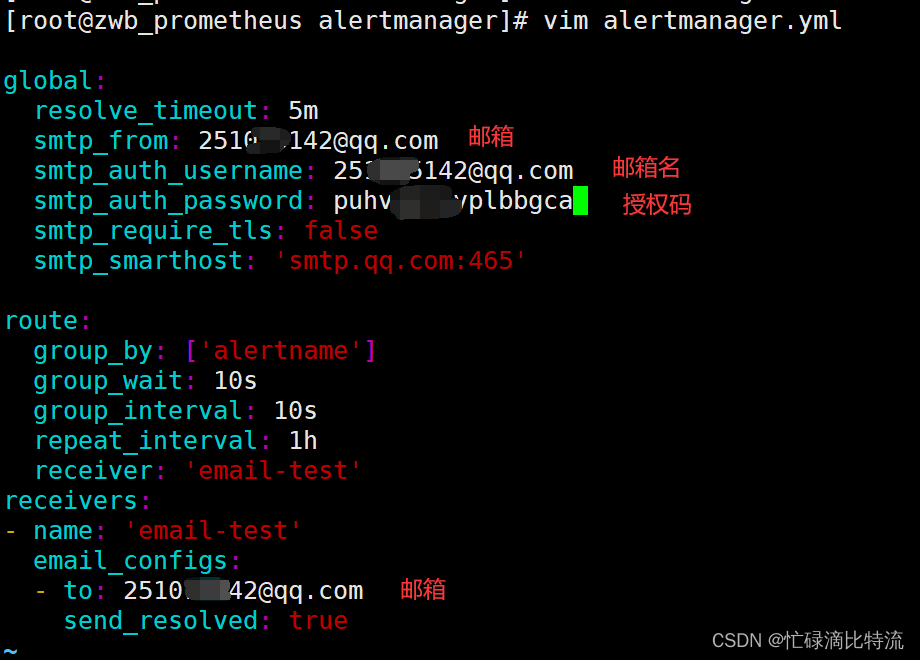
第三步:备份配置文件、配置alertmanager.yml文件
[root@zwb_prometheus alertmanager]# mv alertmanager.yml alertmanager.yml.bck
第四步:启动alertmanager
[root@zwb_prometheus alertmanager]# ./alertmanager
第五步:定义告警发送条件
[root@zwb_prometheus prometheus]# pwd
/usr/local/prometheus#### 定义一个目录用于配置告警促发条件
[root@zwb_prometheus prometheus]# mkdir alert-config
[root@zwb_prometheus prometheus]# cd alert-config/
[root@zwb_prometheus alert-config]# mkdir alert_rules targets[root@zwb_prometheus alert-config]# ls
alert_rules targets
[root@zwb_prometheus alert-config]# vim instance_down.yml
[root@zwb_prometheus alert-config]# cd alert_rules/#### 定义告警条件
[root@zwb_prometheus alert_rules]# vim instance_down.yml
groups:
- name: AllInstances
rules:
- alert: InstanceDown #节点服务挂掉
# Condition for alerting
expr: up == 0 #up状态为0时
for: 1m
# Annotation - additional informational labels to store mo
annotations:
title: 'Instance down'
description: Instance has been down for more than 1 minu
# Labels - additional labels to be attached to the alert
labels:
severity: 'critical' #告警级别[root@zwb_prometheus alert_rules]# cd ../targets/
[root@zwb_prometheus targets]# vim alertmanagers.yaml
- targets:
- 192.168.159.68:9093
labels:
app: alertmanager[root@zwb_prometheus targets]# vim nodes-linux.yaml
- targets:
- 192.168.159.68:9100
- 192.168.159.10:9100
- 192.168.159.11:9100
labels:
app: node-exporter
job: node[root@zwb_prometheus targets]# vim prometheus-servers.yaml
- targets:
- 192.168.159.68:9090
labels:
app: prometheus
job: prometheus[root@zwb_prometheus alert-config]# pwd
/usr/local/prometheus/alert-config### 定义启动prometheus
[root@zwb_prometheus alert-config]# vim prometheus.yml
# my global config
# Author: MageEdu <[email protected]>
# Repo: http://gitlab.magedu.com/MageEdu/prometheus-configs/
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).# Alertmanager configuration
alerting:
alertmanagers:
- file_sd_configs:
- files:
- "targets/alertmanagers*.yaml"# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rules/*.yaml"
- "alert_rules/*.yaml"# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.file_sd_configs:
- files:
- targets/prometheus-*.yaml
refresh_interval: 2m# All nodes
- job_name: 'nodes'
file_sd_configs:
- files:
- targets/nodes-*.yaml
refresh_interval: 2m- job_name: 'alertmanagers'
file_sd_configs:
- files:
- targets/alertmanagers*.yaml
refresh_interval: 2m[root@zwb_prometheus prometheus]# ./prometheus --config.file=./alert-config/prometheus.yml ### 再pro工作目录下启动
第六步:模拟单节点宕机
killall node_exporter
[root@server2 ~]# ss -antp | grep node_exporter
[root@server2 ~]# ##端口已经关闭
第七步:验证
查看PrometheusUI
 查看邮箱
查看邮箱

