目录
1、 Kubernetes 集群的两种管理角色:Master 和 Node
一、目前市场上的云
国内:阿里云、华为云、百度云(私有云)、微软云、其他云
国外:AWS谷歌
二、云计算的主要服务模式
SaaS:Software as a Service,软件即服务,这层的作用是将应用作为服务提供给客户。
PaaS:Platform as a Service,平台即服务,这层的作用是将开发平台作为服务提供给用户。
IaaS:Infrastructure as a Service,基础设施即服务,这层的作用是提供虚拟机或者其他资源作为服务提供给用户。

三、Kubernetes
1、使用Kubernetes的好处
①、可以“轻装上阵”地开发复杂系统
②、使用 Kubernetes 就是在全面拥抱微服务架构
③、我们的系统可以随时随地整体“搬迁”到公有云上
④、Kubernetes 系统架构具备了超强的横向扩容能力
2、资源管理器
1、k8s
k8s首先是对集群化的容器进行批管理(增、删、改、查)
2、k8s的基础概念
K8s视一切可以管理的对象为"资源”,哪怕该服务不是K8s内部的,如果想做为K8的常规组件来使用,K8也提供了API给与我们来自行定义"控制器”(汇聚插件);K8S 也是一个大的生态圈
四、 Kubernetes 基本概念和术语
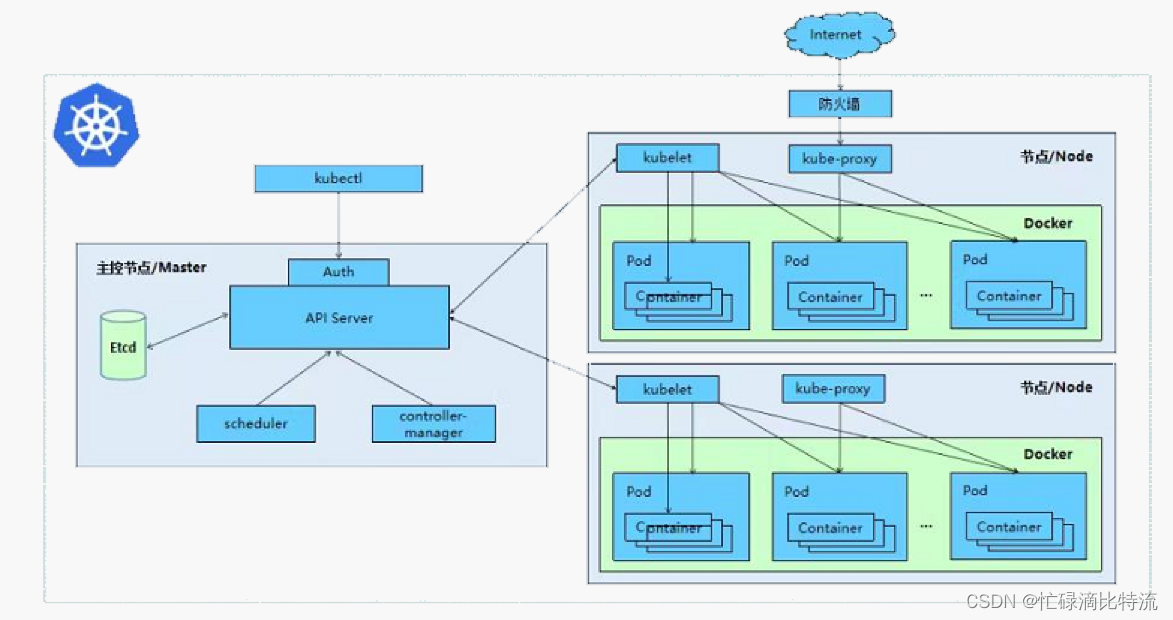
1、 Kubernetes 集群的两种管理角色:Master 和 Node
1.1、master
1.1.1、master概念
1.1.2、master节点上运行的进程
①、Kubernetes API Server(kube-apiserver)
作用:提供了 HTTP Rest 接口的关键服务进程,是 Kubernetes 里所有资源的增、删、改、查等操作的唯一入口,也是集群控制的入口进程。
②、Kubernetes Controller Manager(kube-controller-manager)
作用:Kubernetes 里所有资源对象的自动化控制中心,可以理解为资源对象的“大总管”。
③、Kubernetes Scheduler(kube-scheduler)
作用:负责资源调度(Pod 调度)的进程,相当于公 交公司的“调度室”。
④、etcd服务
作用:Kubernetes 里的所有资源对象的数据存储位置。
1.2、node
1.2.1、node概念
1.2.2、node节点上运行的进程
①、kubelet
作用:负责 Pod 对应的容器的创建、启停等任务,同时与 Master 节点密切协作,实现集群管理的基本功能。
②、kube-proxy
作用:实现 Kubernetes Service 的通信与负载均衡机制(L4层的负载均衡)的重要组件
③、Docker Engine(docker)
作用:Docker 引擎,负责本机的容器创建和管理工作
2、kubernetes是怎样实现高效均衡的资源调度策略的
node节点可以在运行期间动态的增加到k8s的集群中,前提是这个节点已经完成正确的安装、配置和启动关键进程。在默认情况下,kublet会向master注册自己,这也是k8s推荐的管理方式。node被纳入集群管理范围后,kubelet进程就会定时向master节点汇报自生的状态,例如操作系统、Docker 版本、机器的 CPU 和内存情况,以及当前有哪些 Pod 在运行等。这样Master 可以获知每个 Node 的资源使用情况,并实现高效均衡的资源调度策略。 而某个 Node 超过指定时间不上报信息时,会被 Master 判定为“失联”,Node 的状态被标记为 不可用(Not Ready),随后 Master 会触发“工作负载大转移”的自动流程。
3、Pod
pod是可以在kubernetes中创建和管理的,最小的可部署的计算单元(pod是K8s的最小的资源单位)
3.1、pod中容器有几种
| 名称 | 作用 |
| init容器 | 初始化容器环境 |
| pause容器(根容器) |
在pod内提供network namespace和存储卷支持 |
| 业务/应用容器 | 提供业务运行 |
3.2、pod结构
pod 相当于一个容器,pod 有独立的 ip 地址,也有自己的 hostname,利用 namespace 进行资源隔离,相当于一个独立沙箱环境。
pod 内部封装的是容器,可以封装一个,或者多个容器(通常是一组相关的容器)

每一个pod中都可以多个容器,这些容器可分为以下:
①、用户程序所在的容器即业务容器,数量可多可少,他们是并行启动的。
②、pause容器,这是每个pod都会有的一个根容器,他的作用有两个:
1、可以以他为根据,评估整个pod的健康状态
2、可以在跟容器上设置IP地址,其他的容器都以此IP(pod ip),以实现pod内部的网络通信
③、init初始化容器
init容器必须在应用程序(业务)容器启动之前运行完成,而应用程序容器是并行运行的,所
以Init容器能够提供了一种简单的阻塞或延迟应用容器的启动的方法。
init容器特点:
①、Init容器总是运行到成功完成为止
②、每个Init容器都必须在下一个Init容器启动之前成功完成,他们之间是串行启动的
③、pause容器个业务容器们运行行前,都会先跑一个init初始化容器。如果 Pod 的Init容器失败,k8s 会不断地重启该Pod(为了让init容器可以启动完成),直到 Init容器成功为止。然而,如果 Pod对应的重启策略(restartPolicy)为Never,它不会重新启动。
因此可以得出:pod的最小的部署单元为:基础容器(pause)、初始化容器(init初始化容器)、业务容器。
4、pod和容器的关系

容器封装在Pod中
①、Pod的自我修复能力
当副本集为3时,即pod的个数为3,主控制器管理着副本控制器,副本控制器管理着各自的pod。
假如此时pod_1容器宕机了。副本集控制器会上报主控制A,主控器A收到后会重新创建副本控制器C,新的副本控制器C也会生成一个新的pod,然后主控制器会删除副本控制器A(副本集控制器和各自的pod是对应的。pod挂了,则副本集控制器也就挂了,也会被移除)。最后副本控制器C替代了副本控制器A;新的pod替代了pod_1。(在此过程中,用户感觉设备“重启了”,然这个并不是重启,而是一个删除pod和副本集控制器和新建的一个过程)
Pod的弹性伸缩能力
前置条件:
条件一:
cpu 的使用率: 为20%~70%
20%为最低的可容忍的负载率
70%为最高的可容忍的负载率
条件二:
docker cgroup资源限制:cpu为300M,mem为300M
②、弹性伸缩促发条件:(弹性伸缩,是定义一次,自动控制的)
例如:
当pod_3的cpu使用率低于300x20%=60M的使用率,就会触发条件,删除Pod_3。把它的任务分配个剩下的pod。
当pod_1、pod_2、pod_3的内存使用率为300x70%=210M以上,就会触发条件,在生成一个主控制器D,和副本集控制器pod_4
5、kubernetes服务发现与负载均衡
5.1、pod网络
①、pod 有自己独立的 IP 地址
②、pod 内部的容器之间是通过 localhost 进行访问
5.2、pod如何对外部提供访问
pod 想对外提供服务,必须绑定物理机端口 (即在物理机上开启端口,让这个端口和 pod 的端口进行映射),这样就可以通过物理机进行数据包的转发。

5.3、pod 的负载均衡
pod的负载均衡几种方式
1、iptables
2、ipvs(默认下,一般使用该方式。使用kube-proxy(软件形式)在四层的负载均衡
3、uperspace
pod 是一个进程,是有生命周期的,一旦宕机、版本更新都会创建新的 pod( IP 地址会变化,hostname 会变化),此时再使用 Nginx 做负载均衡就不太合适了,因为它不知道 pod 发生了改变,那么请求就不能被接受。所以服务发生了变化它根本不知道,Nginx 无法发现服务,不能用 Nginx 做负载均衡。
6、创建pod的流程
①、首先kubectl转化为json后向api-server提交创建pod的请求
②、api-server收到pod的创建请求后,会将信息记录在etcd中
③、scheduler监听到api-server的处理请求后,然后向api-server申请后端节点信息
④、api-server 收到scheduler的请求后,提交申请到etcd,获取后端节点信息。并把结果返回scheduler
⑤、scheduler 进行预选优选、打分,然后提交结果给api-server
⑥、controller-manager 监听api-server处理的请求信息,并将所需的控制器资源给与api-server
⑦、api-server 和node节点的kubelet进行对接交互
⑧、kubelet调用资源创建pod,并将统计信息返回给api-server
⑨、api-server将信息记录在etcd中