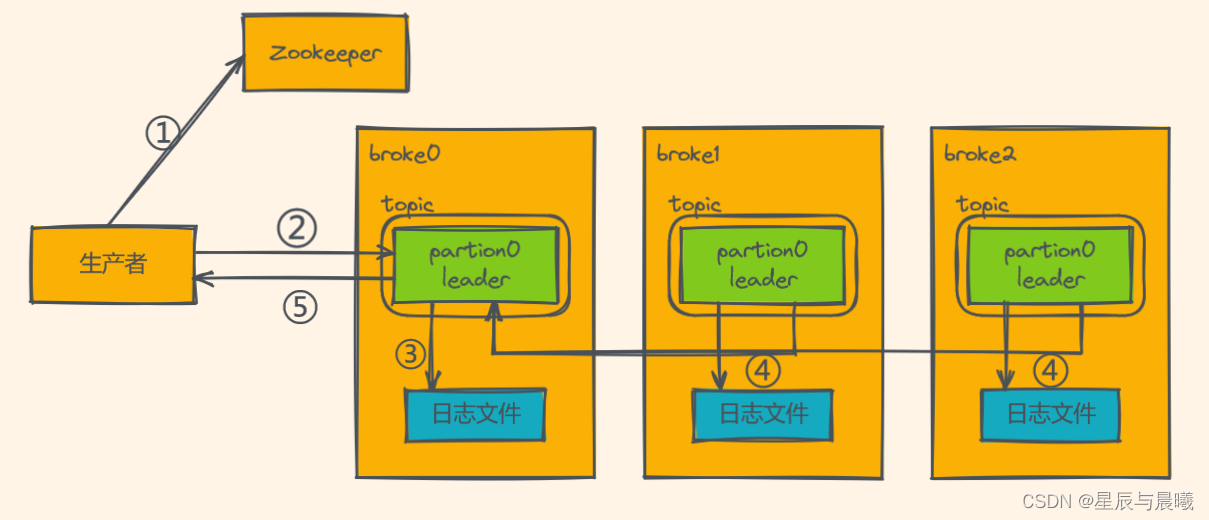
Kafka数据写入流程
执行流程:
- 生产者获取对应分区的 leader 位置
- 发数据给leader
- broker进程上的leader将消息写入到本地log中
- 其他的follower从leader上拉取消息,写入到本地log,并向leader发送ACK
- leader接收到所有的ISR中的Replica的ACK后,并向生产者返回ACK表示成功。
Kafka数据消费流程
在所有消费队列当中,在消费数据的流程分为两种:推模式(push)、拉模式(pull)
- 推模式(push):消息队列记录所有的消费的状态,某一条消息如果被标记为已消费,则消费者是不能再对它进行消费的
- 拉模式(pull):就是消费者自己记录消费状态,每个消费者互相独立地顺序拉取数据
- kafka 采用的拉取模型,由消费者自己记录消费状态,每个消费者互相独立地顺序拉取每个分区的消息。
- 消费者可以按照任意的顺序消费消息。
比如,消费者可以重置到旧的偏移量,重新处理之前已经消费过的消息;或者直接跳到最近的位置,从当前的时刻开始消费。
执行流程:
- 消费者从 ZK 当中获取到 partition 以及 consumer 对应的 offset (默认从ZK中获取上一次消费的offset)
- 找到该分区的leader,拉取数据
- leader从本地log(日志)当中读取数据,最终返回给消费者
- 最终拉取完数据,提交offset给ZK

消息不丢失机制
broker数据不丢失
生产者通过分区的 leader 写入数据后,所有在 ISR 中 follower 都会从 leader 中复制数据,这样,可以确保即使 leader 崩溃了,其他的follower的数据仍然是可用的。
生产者数据不丢失
- 生产者连接leader写入数据时,可以通过ACK机制来确保数据已经成功写入。ACK机制有三个可选配置。
- 配置ACK响应要求为 -1/all 时 —— 表示所有的节点都收到数据(leader和follower)都接收到数据。
- 配置ACK响应要求为 1 时 —— 表示leader收到数据(默认配置)
- 3.配置ACK影响要求为 0 时 —— 生产者只负责发送数据,不关心数据是否丢失(这种情况可能会产生数据丢失,但性能是最好的)
- 生产者可以采用同步和异步两种方式发送数据
- 同步:发送一批数据给kafka后,等待kafka返回结果后再执行下一个语句。
- 异步:发送一批数据给kafka,只是提供一个回调函数。
说明:如果 broker 迟迟不给 ack,而 buffer 又满了,开发者可以设置是否直接清空 buffer 中的数据
消费者数据不丢失
在消费者消费数据的时候,只要每个消费者记录好offset值即可,就能保证数据不丢失。