文章目录
隐藏浏览器
介绍
在使用Selenium采集网页数据时,需要不断地调用浏览器。实际上,通过对Selenium的设置,可以达到隐藏浏览器的效果。在程序中,对浏览器设置了headless,其作用是实现无界面状态。当设置了隐藏浏览器时也是可以正常进行和之前不隐藏浏览器一样的操作的。
FirefoxBinary firefoxBinary = new FirefoxBinary();
// 设置隐藏浏览器模式
firefoxBinary.addCommandLineOptions("--headless");
FirefoxOptions firefoxOptions = new FirefoxOptions();
firefoxOptions.setBinary(firefoxBinary);
driver = new FirefoxDriver(firefoxOptions);
示例代码
使用隐藏浏览器模式访问百度,并尝试获取其按钮的文字信息。通过测试验证可以在隐藏浏览器模式下正常获取元素值。
import lombok.extern.slf4j.Slf4j;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxBinary;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.firefox.FirefoxOptions;
/**
* 使用Selenium采集网站数据,隐藏浏览器模式
*
* @author zhangyu
* @date 2022/11/18
**/
@Slf4j
public class HeadlessAppExample {
public static void main(String[] args) {
WebDriver driver = null;
try {
System.setProperty("webdriver.gecko.driver", "driver/firefox/geckodriver.exe");
FirefoxBinary firefoxBinary = new FirefoxBinary();
// 设置隐藏浏览器模式
firefoxBinary.addCommandLineOptions("--headless");
FirefoxOptions firefoxOptions = new FirefoxOptions();
firefoxOptions.setBinary(firefoxBinary);
driver = new FirefoxDriver(firefoxOptions);
Thread.sleep(1000);
driver.get("https://www.baidu.com");
// 查找某一元素是否存在
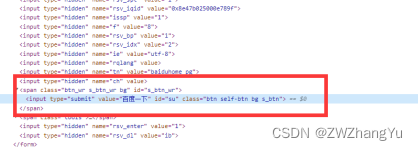
WebElement webElement = driver.findElement(By.id("su"));
log.info("元素text信息:{}", webElement.getAttribute("value"));
} catch (Exception e) {
log.error(e.getMessage());
} finally {
assert driver != null;
driver.quit();
}
}
}

【说明】

隐藏浏览器资源消耗情况

显示浏览器资源消耗情况
当我们设置隐藏浏览器不代表不启动浏览器,当我们打开任务管理器可以看到此时firefox是以后台进程的方式运行的,而且在相同的运行流程下,可以看到显示浏览器资源消耗明显是大于隐藏浏览器的。消耗更少的资源也意味着我们或许可以在同一台机器上运行更多的流程。但是隐藏浏览器可能会出现一些无法预料的问题,这个需要在开发中注意下,同时隐藏浏览器也无法实时看到运行情况,对于可以使用类似浏览器截屏的方式记录流程视图。
如果服务器资源紧张,可以尝试下这个方式,开发阶段设置显示生产环境设置隐藏模式。
此外,如果所处理流程涉及隐私数据,那么此模式也可以作为一种解决方案,通过搭配截屏保存私有服务器方式,既避免了处理流程时数据隐私问题也保存了数据处理流程记录。
浏览器截图
介绍
在网络爬虫中,很多网站会采用验证码的方式来反爬虫,例如在登录时设置验证码、频繁访问时自动弹出验证码等。针对模拟登录时的验证码输入问题,一种简单的解决方案是将验证码保存到本地,之后在程序中手动输入即可。但对于采集每页都需要验证码的网站来说,则需要使用验证码识别算法或调用一些OCR API来自动识别验证码,以保证其效率。
使用Jsoup或者Httpclient,可以直接将验证码下载到本地。而对Selenium来说,可以使用截图的方式截取验证码,并保存到本地。然后通过对该截图进行OCR识别。
不仅对于验证码场景适用,对于自动化处理场景,我们也可以通过周期性的浏览器页面截图做到流程操作记录留存,对于一些关键性的场景设置一些截图可以帮助我们更好的监控线上运行情况。尤其是对于发生异常时,截屏当前页面,对于排查问题非常的方便。
对于Selenium的截屏可以大致分为两种,一种是getScreenshotAs(OutputType.FILE);的方式直接对整个浏览器页面进行截图,另一种是对指定特定HTML元素进行截屏。
示例代码
对整个浏览器页面进行截屏
import cn.hutool.core.io.FileUtil;
import lombok.extern.slf4j.Slf4j;
import org.openqa.selenium.OutputType;
import org.openqa.selenium.TakesScreenshot;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.io.File;
/**
* 使用Selenium对网页特定区域进行截图并保存本地
*
* @author zhangyu
* @date 2022/11/18
**/
@Slf4j
public class ScreenshotExample {
public static void main(String[] args) {
WebDriver driver = null;
try {
System.setProperty("webdriver.gecko.driver", "driver/firefox/geckodriver.exe");
driver = new FirefoxDriver();
Thread.sleep(1000);
driver.get("https://www.baidu.com");
driver.manage().window().maximize();
// 进行整个屏幕截图,设置输出文件
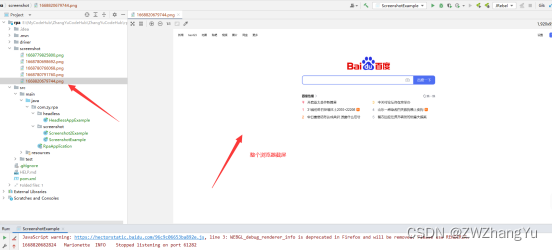
TakesScreenshot scrShot = ((TakesScreenshot) driver);
File SrcFile = scrShot.getScreenshotAs(OutputType.FILE);
// 创建本地文件
File DestFile = new File("screenshot", System.currentTimeMillis() + ".png");
FileUtil.copyFile(SrcFile, DestFile);
Thread.sleep(3000);
} catch (Exception e) {
log.error(e.getMessage());
} finally {
assert driver != null;
driver.quit();
}
}
}
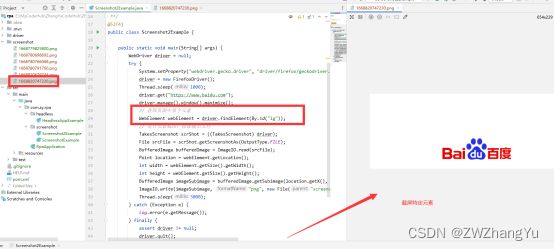
指定特定HTML元素进行截屏
import lombok.extern.slf4j.Slf4j;
import org.openqa.selenium.*;
import org.openqa.selenium.firefox.FirefoxDriver;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
/**
* 使用Selenium对网页特定区域进行截图并保存本地
*
* @author zhangyu
* @date 2022/11/18
**/
@Slf4j
public class Screenshot2Example {
public static void main(String[] args) {
WebDriver driver = null;
try {
System.setProperty("webdriver.gecko.driver", "driver/firefox/geckodriver.exe");
driver = new FirefoxDriver();
Thread.sleep(1000);
driver.get("https://www.baidu.com");
driver.manage().window().maximize();
// 获取页面中某个元素
WebElement webElement = driver.findElement(By.id("lg"));
// 进行元素截图,设置输出文件
TakesScreenshot scrShot = ((TakesScreenshot) driver);
File srcFile = scrShot.getScreenshotAs(OutputType.FILE);
BufferedImage bufferedImage = ImageIO.read(srcFile);
Point location = webElement.getLocation();
int width = webElement.getSize().getWidth();
int height = webElement.getSize().getHeight();
BufferedImage imageSubimage = bufferedImage.getSubimage(location.getX(), location.getY(), width, height);
ImageIO.write(imageSubimage, "png", new File("screenshot", System.currentTimeMillis() + ".png"));
Thread.sleep(3000);
} catch (Exception e) {
log.error(e.getMessage());
} finally {
assert driver != null;
driver.quit();
}
}
}