SPOT1的代码:vae.py
写在最前面
该论文为顶会论文,关于离线强化学习offline RL的策略优化
为了方便自己对SPOT中VAE那部分的理解,主要整理了SPOT的大背景、VAE介绍,以及自己对vae.py这部分代码的理解
(尝试理解,但可能没理解)还请各位过路的大佬指点一二
参考
感谢各位大佬的分享,介绍部分写的真好
https://zhuanlan.zhihu.com/p/560536436
https://zhuanlan.zhihu.com/p/419759019
https://zhuanlan.zhihu.com/p/572698195
SPOT
这篇文章认为,在support constraint这个方向上,将offline RL中的策略约束方法可以分为两类:
1、参数化(parameterization):利用行为策略的生成模型直接限制学习策略采取的action;
缺点在于实际使用起来耗时长,不利于后续的迁移或者online的调优。
2、正则化(regularization):在actor loss上加一个惩罚项,衡量学习策略和行为策略之间的散度;
缺点在于这种基于散度(divergence)的正则化方法,和support set本质上基于密度(density)的定义不匹配,无法有效地规避OOD action,导致性能不佳。
这篇文章提出支持策略优化(Supported Policy Optimization,SPOT) ,将理论与算法结合,提出了一种简单而有效的基于密度的正则化项。SPOT直接来源于支撑约束的理论形式化。此外,采用条件 VAE 显式估计正则项中的行为密度。
如何计算行为策略的概率密度logπβ,这里的方法是使用VAE来拟合行为策略。
理解VAE
VAE概述
VAE可以定义为一种autoencoder,它在训练的过程中为避免过拟合,应该明确施加规则性限制,使得随机采样的一个点能够产生有意义的新数据。
然而,VAE为了引入一些潜在空间的正则化,对普通的autoencoder进行了修改:不是将输入编码为隐空间的单个点,而是将其编码为隐空间上的一个分布。
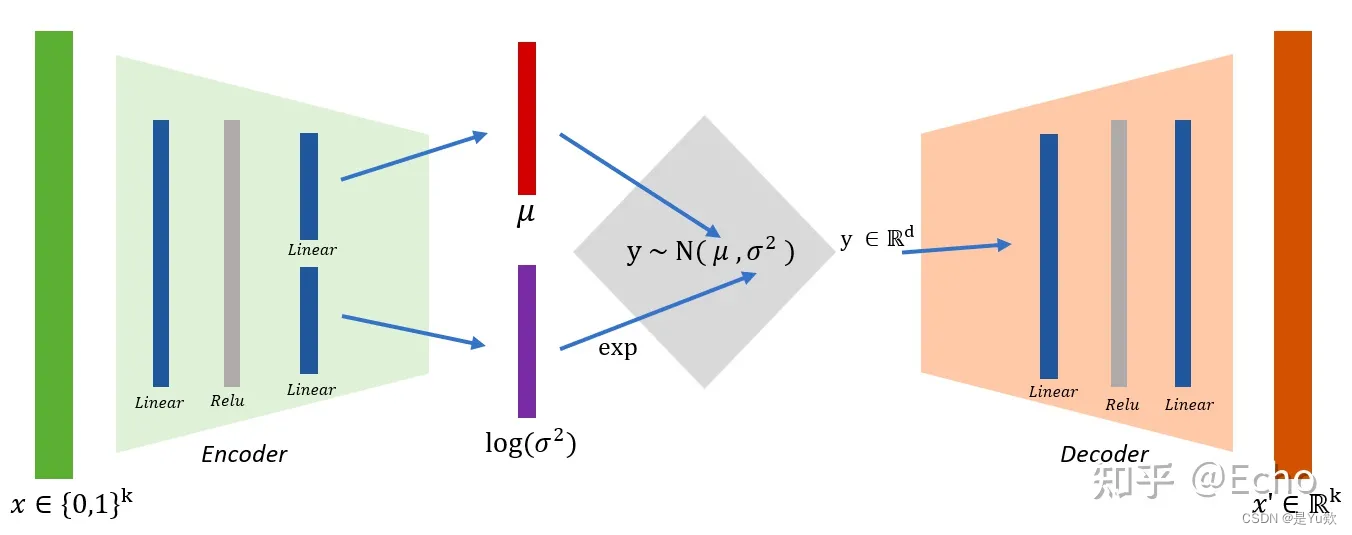
VAE是一种由encoder和decoder组成的体系结构,它的结构其实就是神经网络,它经过训练以最小化编码的解码数据和初始数据之间的重建误差。它的网络输入是一个 d 维的数据点,我们记作 X ,它的最终网络输出同样还是 X。
VAE中最关键的是隐层。
其中编码器将 X 映射到一个隐变量 z 上(z通常是低维的),
然后解码器再把 z 映射回 X 上。
通过分析 z 的分布情况,我们就可以理解原始数据 X 的内在低维表征(对应encoder),同时还可以知道这个原始数据 X 是如何生成的(对应decoder)。
所以这里存在一个问题,假如我们想要通过decoder来凭空生成一个 X,应该输入一个怎样的 z 才比较合理呢?假设这个 z 符合一个概率分布p(z),然后从那个概率分布中采样才能得到一个合理的 X 了。
小结
VAE具体训练步骤如下:
首先,将输入编码为潜在空间上的分布;
其次,从该分布中对潜在空间中的一个点进行采样;
第三,对采样点进行解码,计算重构误差;
最后,重构误差通过网络反向传播,更新权重系数;
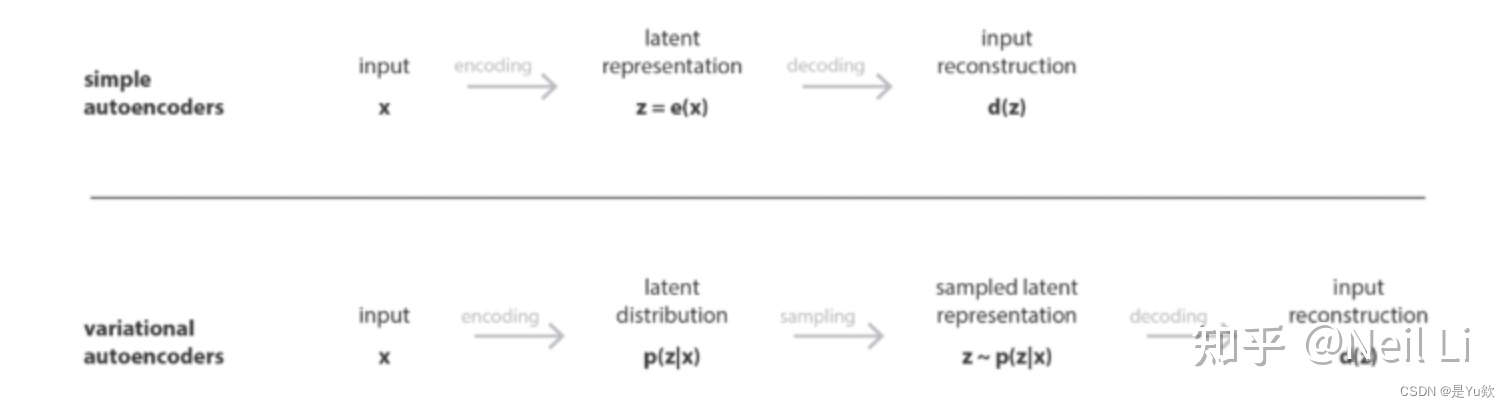
在实践中,编码的分布被选择为正态分布,以便编码器输出是高斯分布的均值和协方差矩阵。
VAE loss
网络结构已经基本清晰,那么最重要的就是它的loss函数了。假如我们想让loss变小,那么也就是要优化 log[p(x)] 这一项让它变大,我们来推导一下它可以变成什么形式:
第一步:
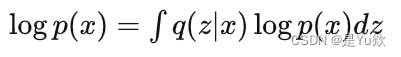

第二步:
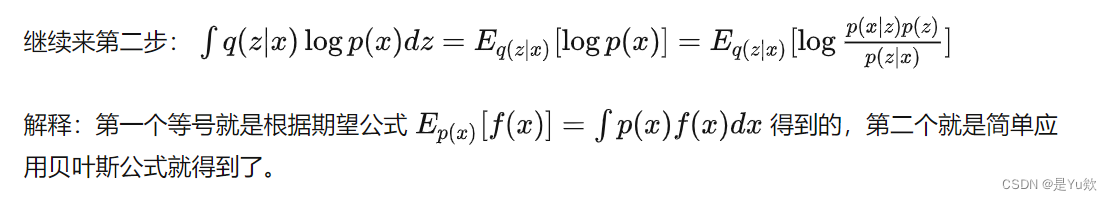
第三步:

第四步:
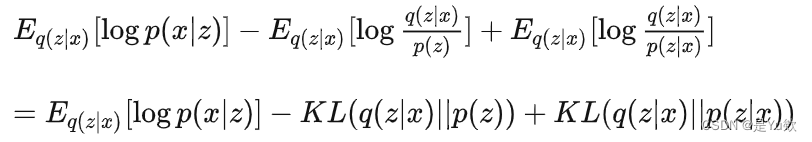
这里的KL指的是KL divergence,它是衡量两个概率分布相似程度的一个指标。如果两个分布完全一样则KL divergence就是0,否则恒大于0。
前两项定义为我们要优化的目标,叫做Lower bound,因为它永远比logp(x) 小;
Lower bound中的第一项其实就是Reconstruction accuracy,我们让它尽量大,就可以让重构出来的数据和原始数据尽可能的像。
第二项因为是负的所以要尽可能小,也就是我们希望encoding出来的隐层变量 z 可以符合 p(x) 分布,这项其实就是一个正则项,以防止网络复杂度过大。
第三项就是我们lower bound和真实的log p(x) 间存在的gap了。我们的目标就是优化Lower bound。
我们一般把 p(z) 定为一个正态分布,所以我们训练好了这个网络之后,这个网络就可以满足两个条件了:
- 对输入数据还原尽可能的准确;
- 隐层变量 z 基本是服从标准正态分布的。
一般vae和IWAE的比较(这篇SPOT论文参考IWAE借鉴了vae)
对比了两种模型的loss,发现IWAE的lower bound比VAE的更加tight,当k趋于无穷时可以接近于真实的loglikelihood。这两种loss会产生不同的梯度,可以发现:
计算VAE梯度时所有对z的采样点有同等权重,
而IWAE的梯度会分配不同的权重。
所以IWAE叫做 Importance weighted AE 。
VAE和IWAE的loss对比
IWAE把一个函数的期望值转换成了采样 k 次然后求均值的方式进行,这个是IWAE中与VAE里最核心的差异点。
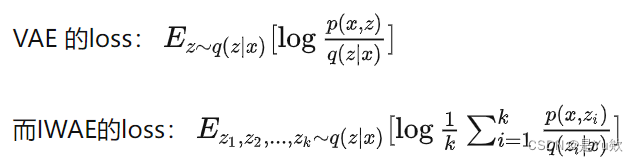
当IWAE中令k=1时,IWAE的loss就是VAE的loss。所以VAE是IWAE的一种简单情况。
而如果让k趋向于无穷,原文证明了IWAE的 lower bound会无限逼近于真实的 p(x) 的 loglikelihood。
也就是说只要算力够强大,只要采样次数够多,就可以优化到真实的loglikehood。
VAE和IWAE的梯度区别

SPOT中的vae损失函数
VAE的训练过程中,损失函数为ELBO loss。
ELBO,全称为 Evidence Lower Bound,即证据下界。这里的证据指数据或可观测变量的概率密度。
计算的方法如下公式所示:
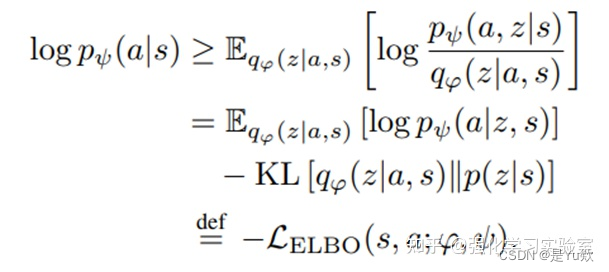
可参考上面第一二步变形,不等式右边最初为 log[p(x)]
可以将这里的 logp 替换 logπβ, 但是因为大于号的存在,这样的估计有很大的偏差。因此SPOT算法中为了降低偏差,借鉴IWAE模型,使用重要性采样的技术。
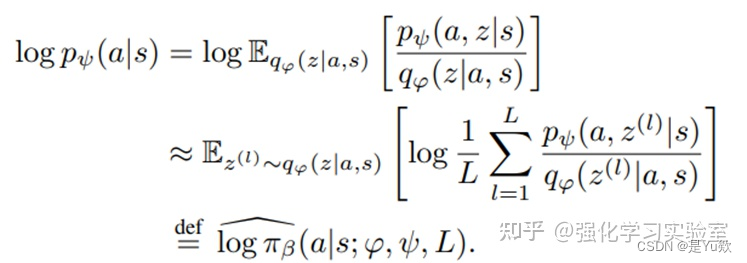
L 为采样的次数,L越大,偏差越小。
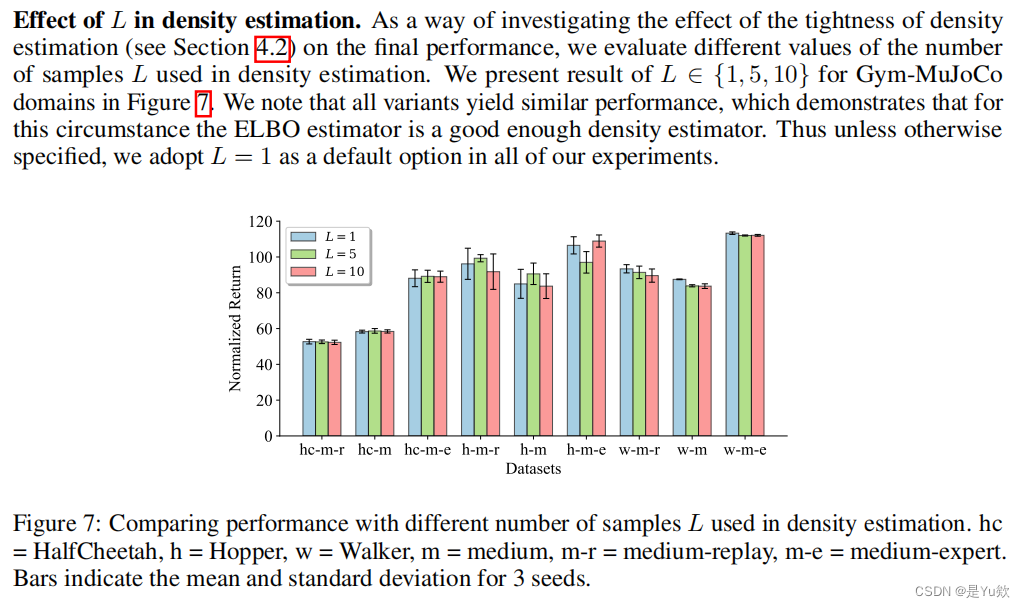
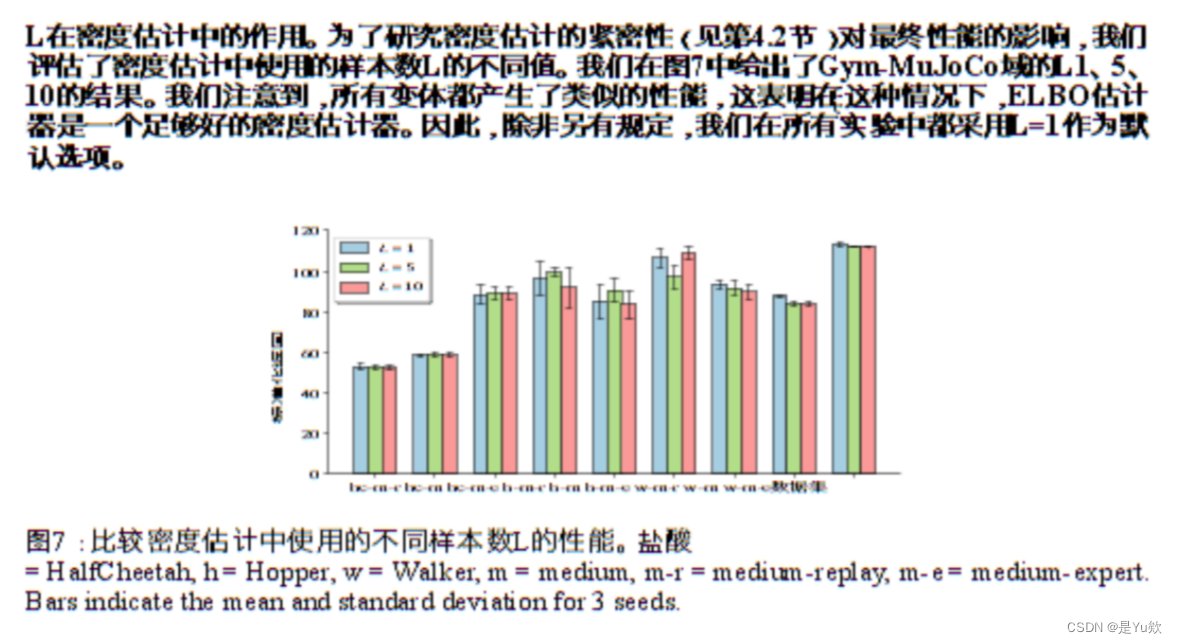
论文中对L的实验(L 对于密度估计的影响)
当L=1的时候,效果和L=5,10 相差不是很多。因此实现时L的取值为1。而当L=1的时候,logπβ 便可以用ELBO loss代替。
官方代码中的注释:
Note: elbo_loss one is proportional to elbo_estimator
i.e. there exist a>0 and b, elbo_loss = a * (-elbo_estimator) + b
翻译:
注意:elbo_loss 1与elbo_estimator成正比, 即存在a>0和b, elbo_loss = a
(-elbo_estimator) + b
论文中附录对此的说明
原文:
百度的翻译版本:
VAE梯度计算
针对所有采样点计算logwi的梯度,但是VAE是直接取它们平均,将所有的视为一样重要。
因为梯度计算是要优化网络的参数,所以引入 
来表示模型参数。
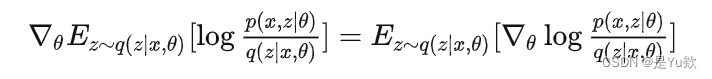
因为期望就是求和取平均,所以可以把求导符号放到里面去。为了简便起见,我们用 w来代替

最后一个等号即是假如我们采用 k 个 z 的方式来计算这个期望。可以看到过程就是,根据输入的数据来产生 k 个 z 值,每个 z 值都会产生一个梯度,然后对它们的梯度求平均而已。所以每个 k 是同等重要的,VAE的梯度计算不是“加权平均”。
代码部分 vae.py
import torch
import torch.nn.functional as F
from torch import nn
import math
import torch.distributions as td
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class VAE(nn.Module):
# Vanilla Variational Auto-Encoder
# Vanilla 变分自动编码器(VAE)
def __init__(self, state_dim, action_dim, latent_dim, max_action, hidden_dim=750, dropout=0.0):
# 调用父类方法初始化模块的state
super(VAE, self).__init__()
# 由两个神经网络(编码器、解码器)组成
# 编码器encode : [b, input_dim] => [b, z_dim]
self.e1 = nn.Linear(state_dim + action_dim, hidden_dim) # 第一个全连接层
self.e2 = nn.Linear(hidden_dim, hidden_dim) # mu
self.mean = nn.Linear(hidden_dim, latent_dim)
self.log_std = nn.Linear(hidden_dim, latent_dim) # log_var
# 解码器decode : [b, z_dim] => [b, input_dim]
self.d1 = nn.Linear(state_dim + latent_dim, hidden_dim)
self.d2 = nn.Linear(hidden_dim, hidden_dim)
self.d3 = nn.Linear(hidden_dim, action_dim)
self.max_action = max_action
self.latent_dim = latent_dim
self.device = device
加噪的过程:forward向前传播部分
def forward(self, state, action):
"""
向前传播部分, 在model_name(inputs)时自动调用
:param: 训练集输入[self, state, action]
:return: u, mean, std
"""
mean, std = self.encode(state, action)
z = mean + std * torch.randn_like(std)
u = self.decode(state, z)
return u, mean, std
这部分是在model_name(inputs)时自动调用
计算接近正态分布的损失elbo_loss
def elbo_loss(self, state, action, beta, num_samples=1):
"""
计算VAE的训练过程中的损失函数elbo_loss
Note: elbo_loss one is proportional to elbo_estimator
i.e. there exist a>0 and b, elbo_loss = a * (-elbo_estimator) + b
注意:elbo_loss 1与elbo_estimator成正比,
即存在a>0和b, elbo_loss = a (-elbo_estimator) + b
小结:用ELBO loss代替logπβ
"""
mean, std = self.encode(state, action)
mean_s = mean.repeat(num_samples, 1, 1).permute(1, 0, 2) # [B x S x D]
std_s = std.repeat(num_samples, 1, 1).permute(1, 0, 2) # [B x S x D]
z = mean_s + std_s * torch.randn_like(std_s)
state = state.repeat(num_samples, 1, 1).permute(1, 0, 2) # [B x S x C]
action = action.repeat(num_samples, 1, 1).permute(1, 0, 2) # [B x S x C]
u = self.decode(state, z)
recon_loss = ((u - action) ** 2).mean(dim=(1, 2))
# 为了使得q和p这两个分布尽可能的相似,我们可以最小化两个分布之间的KL散度,
# 简单来说KL散度就是衡量两个分布之间的距离,值越小两者越相近,值越大两者差距越大。
KL_loss = -0.5 * (1 + torch.log(std.pow(2)) - mean.pow(2) - std.pow(2)).mean(-1)
vae_loss = recon_loss + beta * KL_loss
return vae_loss

借鉴IWAE模型,使用重要性采样的技术
def iwae_loss(self, state, action, beta, num_samples=10):
# 为了降低偏差,借鉴IWAE模型,使用重要性采样的技术。
ll = self.importance_sampling_estimator(state, action, beta, num_samples)
return -ll
在前面有写嘿嘿

计算vae输入输出损失elbo_estimator
def elbo_estimator(self, state, action, beta, num_samples=1):
# 计算输入输出损失
# elbo_loss 1与elbo_estimator成正比, 即存在a>0和b, elbo_loss = a(-elbo_estimator) + b
mean, std = self.encode(state, action)
mean_s = mean.repeat(num_samples, 1, 1).permute(1, 0, 2) # [B x S x D]
std_s = std.repeat(num_samples, 1, 1).permute(1, 0, 2) # [B x S x D]
z = mean_s + std_s * torch.randn_like(std_s)
state = state.repeat(num_samples, 1, 1).permute(1, 0, 2) # [B x S x C]
action = action.repeat(num_samples, 1, 1).permute(1, 0, 2) # [B x S x C]
mean_dec = self.decode(state, z)
std_dec = math.sqrt(beta / 4)
# Find p(x|z)
# 假设P(x)是多个高斯分布(即 GMM)的混合,并且潜在变量 z 满足连续高斯分布。
# 由于真正的p(x|z)是难以处理的,因此让变分近似后验为具有对角协方差结构的多元高斯。
std_dec = torch.ones_like(mean_dec).to(self.device) * std_dec
log_pxz = td.Normal(loc=mean_dec, scale=std_dec).log_prob(action)
# 为了使得q和p这两个分布尽可能的相似,我们可以最小化两个分布之间的KL散度,
# 简单来说KL散度就是衡量两个分布之间的距离,值越小两者越相近,值越大两者差距越大。
KL_loss = -0.5 * (1 + torch.log(std.pow(2)) - mean.pow(2) - std.pow(2)).sum(-1)
elbo = log_pxz.sum(-1).mean(-1) - KL_loss
return elbo
也没找到调用的地方,应该也是自动调用
为了得到论文中\hat \log \pi_\beta的确切值,计算对L个样本的期望
p(z|x)后验分布本身是不好求的。所以有学者就想出了使用另一个可伸缩的分布q(z|x)来近似p(z|x)。
通过深度网络来学习q(z|x)的参数,一步步优化q使其与p(z|x)十分相似,就可以用它来对复杂的分布进行近似的推理。
def importance_sampling_estimator(self, state, action, beta, num_samples=500):
# * num_samples correspond to num of samples L in the paper
# * note that for exact value for \hat \log \pi_\beta in the paper, we also need **an expection over L samples**
# num_samples对应论文中样本L的num
# 注意,为了得到论文中\hat \log \pi_\beta的确切值,我们还需要对L个样本的期望
mean, std = self.encode(state, action)
mean_enc = mean.repeat(num_samples, 1, 1).permute(1, 0, 2) # [B x S x D]
std_enc = std.repeat(num_samples, 1, 1).permute(1, 0, 2) # [B x S x D]
z = mean_enc + std_enc * torch.randn_like(std_enc) # [B x S x D]
state = state.repeat(num_samples, 1, 1).permute(1, 0, 2) # [B x S x C]
action = action.repeat(num_samples, 1, 1).permute(1, 0, 2) # [B x S x C]
mean_dec = self.decode(state, z)
std_dec = math.sqrt(beta / 4)
# Find q(z|x)
# 隐变量 Z 后验分布的近似推断过程
log_qzx = td.Normal(loc=mean_enc, scale=std_enc).log_prob(z)
# Find p(z)
# 从该分布中对潜在空间中的一个点进行采样
mu_prior = torch.zeros_like(z).to(self.device)
std_prior = torch.ones_like(z).to(self.device)
log_pz = td.Normal(loc=mu_prior, scale=std_prior).log_prob(z)
# Find p(x|z)
# 生成变量X' 的条件分布生成过程,Z的后验分布p(z|x)
std_dec = torch.ones_like(mean_dec).to(self.device) * std_dec
log_pxz = td.Normal(loc=mean_dec, scale=std_dec).log_prob(action)
# 3、对采样点进行解码,计算重构误差
# 为了使得q和p这两个分布尽可能的相似,我们可以最小化两个分布之间的KL散度,
# 简单来说KL散度就是衡量两个分布之间的距离,值越小两者越相近,值越大两者差距越大。
w = log_pxz.sum(-1) + log_pz.sum(-1) - log_qzx.sum(-1)
ll = w.logsumexp(dim=-1) - math.log(num_samples)
return ll
编码+解码
def encode(self, state, action):
# encode:将输入编码为潜在空间上的分布
z = F.relu(self.e1(torch.cat([state, action], -1)))
z = F.relu(self.e2(z))
mean = self.mean(z)
# Clamped for numerical stability
# 为数值稳定性夹紧
log_std = self.log_std(z).clamp(-4, 15)
std = torch.exp(log_std)
return mean, std
def decode(self, state, z=None):
# 解码,返回结果值
# When sampling from the VAE, the latent vector is clipped to [-0.5, 0.5]
# 当从VAE采样时,潜在矢量被剪切到[-0.5,0.5]
if z is None:
z = torch.randn((state.shape[0], self.latent_dim)).to(self.device).clamp(-0.5, 0.5)
a = F.relu(self.d1(torch.cat([state, z], -1)))
a = F.relu(self.d2(a))
if self.max_action is not None:
return self.max_action * torch.tanh(self.d3(a))
else:
return self.d3(a)
代码部分 train_vae.py(主要就对vae.py的调用,然后打印跑代码的环境及各项结果)
前面就各种初始化啥的,可以直接跳过(打印跑代码的时间那块很有意思,之后可以借鉴)
import argparse
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import gym
from tqdm import tqdm
import os
from vae import VAE
import time
from coolname import generate_slug
import utils
import json
from log import Logger
import d4rl
from utils import get_lr
parser = argparse.ArgumentParser()
parser.add_argument('--seed', type=int, default=0)
# 数据集dataset
parser.add_argument('--env', type=str, default='hopper')
parser.add_argument('--dataset', type=str, default='medium') # medium, medium-replay, medium-expert, expert
parser.add_argument('--version', type=str, default='v2')
# 模型model
parser.add_argument('--model', default='VAE', type=str)
parser.add_argument('--hidden_dim', type=int, default=750)
parser.add_argument('--beta', type=float, default=0.5)
# 训练train
parser.add_argument('--num_iters', type=int, default=int(1e5))
parser.add_argument('--batch_size', type=int, default=256)
parser.add_argument('--lr', type=float, default=1e-3)
parser.add_argument('--weight_decay', default=0, type=float)
parser.add_argument('--scheduler', default=False, action='store_true')
parser.add_argument('--gamma', default=0.95, type=float)
parser.add_argument('--no_max_action', default=False, action='store_true')
parser.add_argument('--clip_to_eps', default=False, action='store_true')
parser.add_argument('--eps', default=1e-4, type=float)
parser.add_argument('--latent_dim', default=None, type=int, help="default: action_dim * 2")
parser.add_argument('--no_normalize', default=False, action='store_true', help="do not normalize states")
parser.add_argument('--eval_data', default=0.0, type=float, help="proportion of data used for validation, e.g. 0.05")
# 工作目录work dir
parser.add_argument('--work_dir', type=str, default='train_vae')
parser.add_argument('--notes', default=None, type=str)
args = parser.parse_args()
# 新建字典make directory,用来打印输出结果
base_dir = 'runs'
utils.make_dir(base_dir)
base_dir = os.path.join(base_dir, args.work_dir)
utils.make_dir(base_dir)
args.work_dir = os.path.join(base_dir, args.env + '_' + args.dataset)
utils.make_dir(args.work_dir)
# 打印跑代码的时间,真严谨且细节,以后代码也这样加一段hhh
ts = time.gmtime()
ts = time.strftime("%m-%d-%H:%M", ts)
exp_name = str(args.env) + '-' + str(args.dataset) + '-' + ts + '-bs' \
+ str(args.batch_size) + '-s' + str(args.seed) + '-b' + str(args.beta) + \
'-h' + str(args.hidden_dim) + '-lr' + str(args.lr) + '-wd' + str(args.weight_decay)
exp_name += '-' + generate_slug(2)
if args.notes is not None:
exp_name = args.notes + '_' + exp_name
args.work_dir = args.work_dir + '/' + exp_name
utils.make_dir(args.work_dir)
args.model_dir = os.path.join(args.work_dir, 'model')
utils.make_dir(args.model_dir)
with open(os.path.join(args.work_dir, 'args.json'), 'w') as f:
json.dump(vars(args), f, sort_keys=True, indent=4)
utils.snapshot_src('.', os.path.join(args.work_dir, 'src'), '.gitignore')
logger = Logger(args.work_dir, use_tb=True)
utils.set_seed_everywhere(args.seed)
device = 'cuda'
# 加载数据load data
env_name = f"{
args.env}-{
args.dataset}-{
args.version}"
env = gym.make(env_name)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[0])
if args.no_max_action:
max_action = None
print(state_dim, action_dim, max_action)
latent_dim = action_dim * 2
if args.latent_dim is not None:
latent_dim = args.latent_dim
replay_buffer = utils.ReplayBuffer(state_dim, action_dim)
replay_buffer.convert_D4RL(d4rl.qlearning_dataset(env))
if not args.no_normalize:
mean, std = replay_buffer.normalize_states()
else:
print("No normalize")
if args.clip_to_eps:
replay_buffer.clip_to_eps(args.eps)
states = replay_buffer.state
actions = replay_buffer.action
if args.eval_data:
eval_size = int(states.shape[0] * args.eval_data)
eval_idx = np.random.choice(states.shape[0], eval_size, replace=False)
train_idx = np.setdiff1d(np.arange(states.shape[0]), eval_idx)
eval_states = states[eval_idx]
eval_actions = actions[eval_idx]
states = states[train_idx]
actions = actions[train_idx]
else:
eval_states = None
eval_actions = None
训练和评估部分(好吧这部分也没啥,主要就调用vae.py,然后计算loss并打印到日志中)
# 训练train
if args.model == 'VAE':
vae = VAE(state_dim, action_dim, latent_dim, max_action, hidden_dim=args.hidden_dim).to(device)
else:
raise NotImplementedError
optimizer = torch.optim.Adam(vae.parameters(), lr=args.lr, weight_decay=args.weight_decay)
if args.scheduler:
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer=optimizer, gamma=args.gamma)
total_size = states.shape[0]
batch_size = args.batch_size
for step in tqdm(range(args.num_iters + 1), desc='train'):
idx = np.random.choice(total_size, batch_size)
train_states = torch.from_numpy(states[idx]).to(device)
train_actions = torch.from_numpy(actions[idx]).to(device)
# Variational Auto-Encoder Training
# 变分自动编码器VAE训练
recon, mean, std = vae(train_states, train_actions)
recon_loss = F.mse_loss(recon, train_actions)
KL_loss = -0.5 * (1 + torch.log(std.pow(2)) - mean.pow(2) - std.pow(2)).mean()
vae_loss = recon_loss + args.beta * KL_loss
# 将loss记录到日志中去
logger.log('train/recon_loss', recon_loss, step=step)
logger.log('train/KL_loss', KL_loss, step=step)
logger.log('train/vae_loss', vae_loss, step=step)
optimizer.zero_grad()
vae_loss.backward()
optimizer.step()
if step % 5000 == 0:
logger.dump(step)
torch.save(vae.state_dict(), '%s/vae_model_%s_%s_b%s_%s.pt' %
(args.model_dir, args.env, args.dataset, str(args.beta), step))
if eval_states is not None and eval_actions is not None:
vae.eval()
with torch.no_grad():
eval_states_tensor = torch.from_numpy(eval_states).to(device)
eval_actions_tensor = torch.from_numpy(eval_actions).to(device)
# Variational Auto-Encoder Evaluation
# 变分自动编码器VAE评估
recon, mean, std = vae(eval_states_tensor, eval_actions_tensor)
recon_loss = F.mse_loss(recon, eval_actions_tensor)
KL_loss = -0.5 * (1 + torch.log(std.pow(2)) - mean.pow(2) - std.pow(2)).mean()
vae_loss = recon_loss + args.beta * KL_loss
logger.log('eval/recon_loss', recon_loss, step=step)
logger.log('eval/KL_loss', KL_loss, step=step)
logger.log('eval/vae_loss', vae_loss, step=step)
vae.train()
if args.scheduler and (step + 1) % 10000 == 0:
logger.log('train/lr', get_lr(optimizer), step=step)
scheduler.step()
logger._sw.close()