接前一篇文章:论文译读 —— STUN: Reinforcement-Learning-Based Optimization of Kernel Scheduler Parameters 5(1)
5. 评估
5.2 学习迭代次数
为了根据学习迭代次数来确认STUN的正确性,我们在一台120核机器上更改了片段计数和步进函数执行计数的值,并对结果进行了分析。为了提高分析的准确性,评估使用了所有参数下测试工作量结果的记录文件,以避免工作量结果的波动。
首先,为了确认片段数的效果,步骤的数量固定为500,片段数设置为25、50或100。然后,我们分析了参数状态变化和Sysbench的性能。图4显示了每个评估过程的图形表示。对于图4A、B,片段数为25;对于图4C、D,为50;对于图4E、F,为100。每张图的x轴是学习迭代次数,图4A、C、E的y轴表示Sysbench的性能(事件总数);图4B、D、F的y轴表示每个参数的状态值。
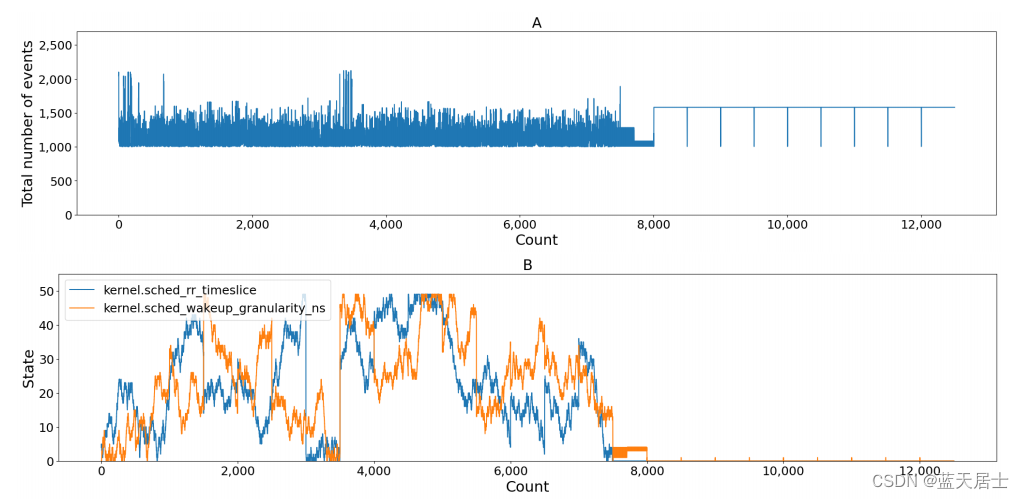



结果表明,如果片段次数不够,则学习无法找到最优值。 在图4A,B中,当迭代次数约为8000时,参数会收敛,但并没有显示出最佳性能。另一方面,在图4E中,如果事件数量过大,则当训练迭代次数约为45000次时,学习可以找到最佳性能。然而,图4F显示,由于过度拟合问题,参数值不会收敛。当片段数过多时,奖励会围绕最佳值累积,因此结果变得不稳定。因此,必须将片段数设置为适当的值,以找到最佳和稳定的参数值,如图4C,D所示。
图5显示了对通过固定片段数(50)获得的参数变化的分析,同时将Sysbench的步数更改为200、500或1000。x轴和y轴意义与图4中的相同。对于图5A、B,步数为200;对于图5C、D,步数为500;对于图5E、F,步数为1000。

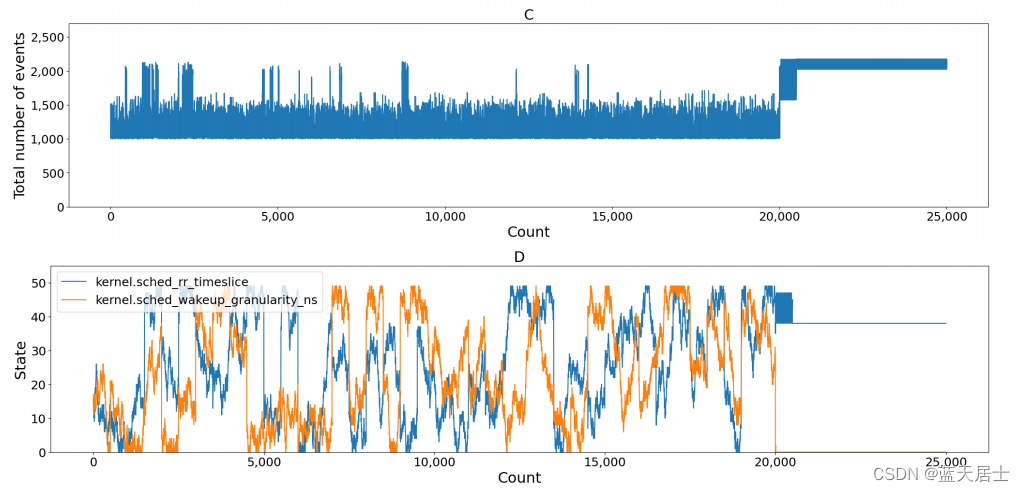
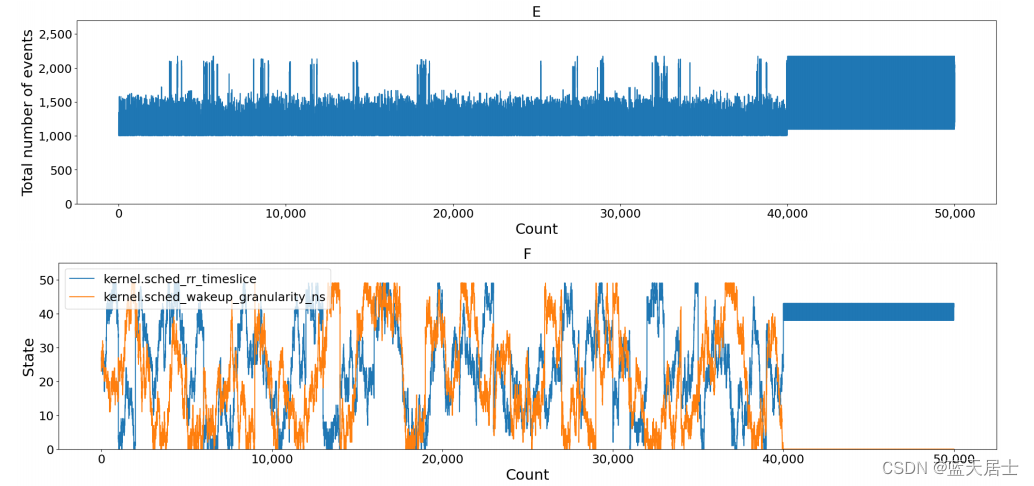

分析结果与改变片段数的分析结果相似。我们确认,如果步数小于200,则表示学习不足,如果步数超过1000,则该模型训练过度。基于这些评估结果,我们在所有后续评估中使用了片段数为50和步数为500。