

Yes, this function is hard to understand, until you get the point.
In its simplest form, it is similar to tf.gather. It returns the elements of params according to the indexes specified by ids.
For example (assuming you are inside tf.InteractiveSession())
params = tf.constant([10,20,30,40])
ids = tf.constant([0,1,2,3])
print tf.nn.embedding_lookup(params,ids).eval()
would return [10 20 30 40], because the first element (index 0) of params is 10, the second element of params (index 1) is 20, etc.
Similarly,
params = tf.constant([10,20,30,40])
ids = tf.constant([1,1,3])
print tf.nn.embedding_lookup(params,ids).eval()
would return [20 20 40].
But embedding_lookup is more than that. The params argument can be a list of tensors, rather than a single tensor.
params1 = tf.constant([1,2])
params2 = tf.constant([10,20])
ids = tf.constant([2,0,2,1,2,3])
result = tf.nn.embedding_lookup([params1, params2], ids)
In such a case, the indexes, specified in ids, correspond to elements of tensors according to a partition strategy, where the default partition strategy is 'mod'.
In the 'mod' strategy, index 0 corresponds to the first element of the first tensor in the list. Index 1 corresponds to the first element of the second tensor. Index 2 corresponds to the first element of the third tensor, and so on. Simply index i corresponds to the first element of the (i+1)th tensor , for all the indexes 0..(n-1), assuming params is a list of n tensors.
Now, index n cannot correspond to tensor n+1, because the list params contains only n tensors. So index n corresponds to the second element of the first tensor. Similarly, index n+1corresponds to the second element of the second tensor, etc.
So, in the code
params1 = tf.constant([1,2])
params2 = tf.constant([10,20])
ids = tf.constant([2,0,2,1,2,3])
result = tf.nn.embedding_lookup([params1, params2], ids)
index 0 corresponds to the first element of the first tensor: 1
index 1 corresponds to the first element of the second tensor: 10
index 2 corresponds to the second element of the first tensor: 2
index 3 corresponds to the second element of the second tensor: 20
Thus, the result would be:
[ 2 1 2 10 2 20]从id类特征(category类)使用embedding_lookup的角度来讲:
1、onehot编码神经网络处理不来。embedding_lookup虽然是随机化地映射成向量,看起来信息量相同,但其实却更加超平面可分。
2、embedding_lookup不是简单的查表,id对应的向量是可以训练的,训练参数个数应该是 category num*embedding size,也就是说lookup是一种全连接层。详见 brain of mat kelcey
3、word embedding其实是有了一个距离的定义,即出现在同一上下文的词的词向量距离应该小,这样生成向量比较容易理解。autoencode、pca等做一组基变换,也是假设原始特征值越接近越相似。但id值的embedding应该是没有距离可以定义,没有物理意义,只是一种特殊的全连接层。
4、用embedding_lookup做id类特征embedding由google的deep&wide提出,但隐藏了具体实现细节。阿里 第七章 人工智能,7.6 DNN在搜索场景中的应用(作者:仁重) 中提下了面对的困难,主要是参数数量过多(引入紫色编码层)和要使用针对稀疏编码特别优化过的全连接层( Sparse Inner Product Layer )等。
5、在分类模型中用这种id类特征,主要是希望模型把这个商品记住。但id类特征维度太高,同一个商品的数据量也不大,因此也常常用i2i算法产出的item embedding来替代id特征。
embedding_lookup
import tensorflow as tf
embedding = tf.get_variable("embedding", initializer=tf.ones(shape=[10, 5]))
look_uop = tf.nn.embedding_lookup(embedding, [1, 2, 3, 4])
# embedding_lookup就像是给 其它行的变量加上了stop_gradient
w1 = tf.get_variable("w", shape=[5, 1])
z = tf.matmul(look_uop, w1)
opt = tf.train.GradientDescentOptimizer(0.1)
#梯度的计算和更新依旧和之前一样,没有需要注意的
gradients = tf.gradients(z, xs=[embedding])
train = opt.apply_gradients([(gradients[0],embedding)])
#print(gradients[4])
with tf.Session() as sess:
tf.global_variables_initializer().run()
print(sess.run(train))
print(sess.run(embedding))[[ 1. 1. 1. 1. 1. ]
[ 0.90580809 1.0156796 0.96294552 1.01720285 1.08395708]
[ 0.90580809 1.0156796 0.96294552 1.01720285 1.08395708]
[ 0.90580809 1.0156796 0.96294552 1.01720285 1.08395708]
[ 0.90580809 1.0156796 0.96294552 1.01720285 1.08395708]
[ 1. 1. 1. 1. 1. ]
[ 1. 1. 1. 1. 1. ]
[ 1. 1. 1. 1. 1. ]
[ 1. 1. 1. 1. 1. ]
[ 1. 1. 1. 1. 1. ]]Embedding原理
应用中一般将物体嵌入到一个低维空间 ,只需要再compose上一个从
到
的线性映射就好了。每一个
的矩阵
都定义了
到
的一个线性映射:
。当
是一个标准基向量的时候,
对应矩阵
中的一列,这就是对应id的向量表示。这个概念用神经网络图来表示如下:
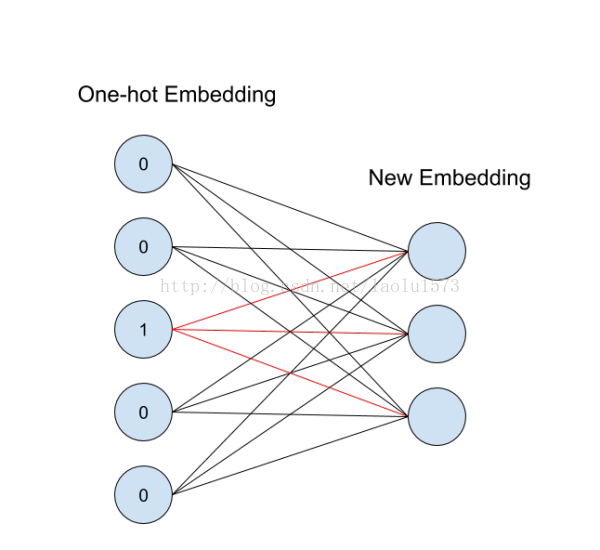
从id(索引)找到对应的One-hot encoding,然后红色的weight就直接对应了输出节点的值(注意这里没有activation function),也就是对应的embedding向量。
tf.nn.embedding_lookup:
tf.nn.embedding_lookup()就是根据input_ids中的id,寻找embeddings中的第id行。比如input_ids=[1,3,5],则找出embeddings中第1,3,5行,组成一个tensor返回。
embedding_lookup不是简单的查表,id对应的向量是可以训练的,训练参数个数应该是 category num*embedding size,也就是说lookup是一种全连接层。
看一段代码:
#!/usr/bin/env/python # coding=utf-8 import tensorflow as tf import numpy as np # 定义一个未知变量input_ids用于存储索引 input_ids = tf.placeholder(dtype=tf.int32, shape=[None]) # 定义一个已知变量embedding,是一个5*5的对角矩阵 # embedding = tf.Variable(np.identity(5, dtype=np.int32)) # 或者随机一个矩阵 embedding = a = np.asarray([[0.1, 0.2, 0.3], [1.1, 1.2, 1.3], [2.1, 2.2, 2.3], [3.1, 3.2, 3.3], [4.1, 4.2, 4.3]]) # 根据input_ids中的id,查找embedding中对应的元素 input_embedding = tf.nn.embedding_lookup(embedding, input_ids) sess = tf.InteractiveSession() sess.run(tf.global_variables_initializer()) # print(embedding.eval()) print(sess.run(input_embedding, feed_dict={input_ids: [1, 2, 3, 0, 3, 2, 1]}))