RNN
实战
- 简单的单向RNN
# 将每个词变成长度为16的embedding向量
embedding_dim = 16
batch_size = 128
model = keras.models.Sequential([
# keras.layers.Embedding要做的几件事:
# 1.定义矩阵:[vocab_size, embedding_dim]
# 2.对于每一个句子/样本,如:[1,2,3,4...],都会去矩阵中查找对应的向量,最后变成成
# max_length * embeddding_dim的矩阵
# 3.最后输出的大小为一个三维矩阵:batch_size * max_length * embedding_dim
keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
# 对输出做合并
# 将三维矩阵变为:batch_size * embedding_dim
# return_sequences是指取得的是最后一步输出还是前面的输出,False表示最后一步输出
keras.layers.SimpleRNN(units=64, return_sequences=False),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dense(1, activation='sigmoid'),
])
model.summary()
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 500, 16) 160000
_________________________________________________________________
simple_rnn (SimpleRNN) (None, 64) 5184
_________________________________________________________________
dense (Dense) (None, 64) 4160
_________________________________________________________________
dense_1 (Dense) (None, 1) 65
=================================================================
Total params: 169,409
Trainable params: 169,409
Non-trainable params: 0
_________________________________________________________________
history_single_rnn = model.fit(train_data,
train_labels,
epochs=30,
batch_size=batch_size,
validation_split=0.2)
Train on 20000 samples, validate on 5000 samples
Epoch 1/30
20000/20000 [==============================] - 30s 2ms/sample - loss: 0.6951 - accuracy: 0.5008 - val_loss: 0.6976 - val_accuracy: 0.4958
Epoch 2/30
20000/20000 [==============================] - 30s 2ms/sample - loss: 0.6996 - accuracy: 0.4978 - val_loss: 0.7436 - val_accuracy: 0.4900
Epoch 3/30
20000/20000 [==============================] - 34s 2ms/sample - loss: 0.6964 - accuracy: 0.4949 - val_loss: 0.6936 - val_accuracy: 0.5096
Epoch 4/30
20000/20000 [==============================] - 38s 2ms/sample - loss: 0.6951 - accuracy: 0.5015 - val_loss: 0.6927 - val_accuracy: 0.5124
Epoch 5/30
20000/20000 [==============================] - 34s 2ms/sample - loss: 0.6943 - accuracy: 0.5066 - val_loss: 0.6981 - val_accuracy: 0.5104
Epoch 6/30
20000/20000 [==============================] - 34s 2ms/sample - loss: 0.6955 - accuracy: 0.4987 - val_loss: 0.6944 - val_accuracy: 0.5106
Epoch 7/30
20000/20000 [==============================] - 39s 2ms/sample - loss: 0.6940 - accuracy: 0.5071 - val_loss: 0.6932 - val_accuracy: 0.5098
Epoch 8/30
20000/20000 [==============================] - 39s 2ms/sample - loss: 0.6951 - accuracy: 0.5116 - val_loss: 0.6943 - val_accuracy: 0.4986
Epoch 9/30
20000/20000 [==============================] - 35s 2ms/sample - loss: 0.6958 - accuracy: 0.5059 - val_loss: 0.6928 - val_accuracy: 0.5152
Epoch 10/30
20000/20000 [==============================] - 39s 2ms/sample - loss: 0.6946 - accuracy: 0.5060 - val_loss: 0.6931 - val_accuracy: 0.5104
Epoch 11/30
20000/20000 [==============================] - 38s 2ms/sample - loss: 0.6932 - accuracy: 0.5015 - val_loss: 0.6931 - val_accuracy: 0.5060
Epoch 12/30
20000/20000 [==============================] - 35s 2ms/sample - loss: 0.6923 - accuracy: 0.5104 - val_loss: 0.6934 - val_accuracy: 0.5078
Epoch 13/30
20000/20000 [==============================] - 37s 2ms/sample - loss: 0.6914 - accuracy: 0.5142 - val_loss: 0.6946 - val_accuracy: 0.5088
Epoch 14/30
20000/20000 [==============================] - 36s 2ms/sample - loss: 0.6897 - accuracy: 0.5168 - val_loss: 0.6940 - val_accuracy: 0.5086
Epoch 15/30
20000/20000 [==============================] - 40s 2ms/sample - loss: 0.6880 - accuracy: 0.5103 - val_loss: 0.6922 - val_accuracy: 0.5118
Epoch 16/30
20000/20000 [==============================] - 45s 2ms/sample - loss: 0.6839 - accuracy: 0.5140 - val_loss: 0.6958 - val_accuracy: 0.4976
Epoch 17/30
20000/20000 [==============================] - 41s 2ms/sample - loss: 0.6778 - accuracy: 0.5301 - val_loss: 0.6960 - val_accuracy: 0.4976
Epoch 18/30
20000/20000 [==============================] - 41s 2ms/sample - loss: 0.6735 - accuracy: 0.5292 - val_loss: 0.6973 - val_accuracy: 0.5108
Epoch 19/30
20000/20000 [==============================] - 44s 2ms/sample - loss: 0.6692 - accuracy: 0.5237 - val_loss: 0.7005 - val_accuracy: 0.5008
Epoch 20/30
20000/20000 [==============================] - 42s 2ms/sample - loss: 0.6647 - accuracy: 0.5257 - val_loss: 0.6975 - val_accuracy: 0.5128
Epoch 21/30
20000/20000 [==============================] - 41s 2ms/sample - loss: 0.6600 - accuracy: 0.5326 - val_loss: 0.6997 - val_accuracy: 0.5162
Epoch 22/30
20000/20000 [==============================] - 42s 2ms/sample - loss: 0.6561 - accuracy: 0.5372 - val_loss: 0.7061 - val_accuracy: 0.5046
Epoch 23/30
20000/20000 [==============================] - 37s 2ms/sample - loss: 0.6510 - accuracy: 0.5394 - val_loss: 0.7188 - val_accuracy: 0.5146
Epoch 24/30
20000/20000 [==============================] - 46s 2ms/sample - loss: 0.6505 - accuracy: 0.5332 - val_loss: 0.7248 - val_accuracy: 0.5054
Epoch 25/30
20000/20000 [==============================] - 44s 2ms/sample - loss: 0.6441 - accuracy: 0.5408 - val_loss: 0.7282 - val_accuracy: 0.5204
Epoch 26/30
20000/20000 [==============================] - 40s 2ms/sample - loss: 0.6414 - accuracy: 0.5408 - val_loss: 0.7345 - val_accuracy: 0.5074
Epoch 27/30
20000/20000 [==============================] - 43s 2ms/sample - loss: 0.6395 - accuracy: 0.5421 - val_loss: 0.7596 - val_accuracy: 0.5080
Epoch 28/30
20000/20000 [==============================] - 36s 2ms/sample - loss: 0.6439 - accuracy: 0.5407 - val_loss: 0.7333 - val_accuracy: 0.5154
Epoch 29/30
20000/20000 [==============================] - 38s 2ms/sample - loss: 0.6414 - accuracy: 0.5411 - val_loss: 0.7403 - val_accuracy: 0.5182
Epoch 30/30
20000/20000 [==============================] - 41s 2ms/sample - loss: 0.6392 - accuracy: 0.5417 - val_loss: 0.7484 - val_accuracy: 0.5182
def plot_learning_curves(history, label, epochs, min_value, max_value):
data = {}
data[label] = history.history[label]
data['val_' + label] = history.history['val_' + label]
pd.DataFrame(data).plot(figsize=(8, 5))
plt.grid(True)
plt.axis([0, epochs, min_value, max_value])
plt.show()
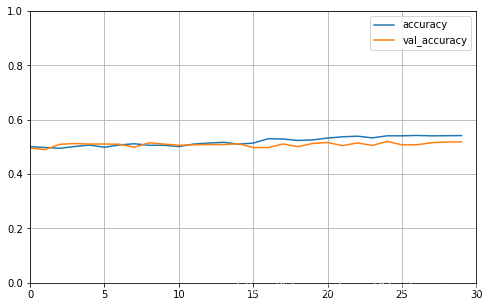
plot_learning_curves(history_single_rnn, 'accuracy', 30, 0, 1)
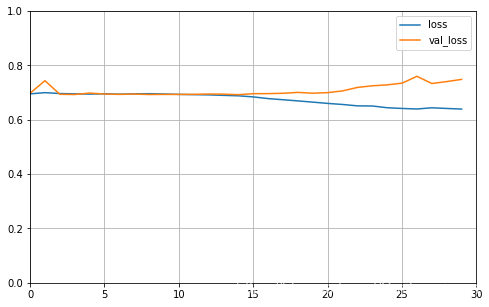
plot_learning_curves(history_single_rnn, 'loss', 30, 0, 1)
model.evaluate(
test_data, test_labels,
batch_size = batch_size)
25000/25000 [==============================] - 13s 519us/sample - loss: 0.7387 - accuracy: 0.5132
[0.7386957692718505, 0.5132]
可以看出训练基本没什么效果,说明单向RNN的能力有限,无法结合后面的神经元进行训练。
- 两个双向RNN的模型
embedding_dim = 16
batch_size = 128
model_1 = keras.models.Sequential([
keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
# 封装为双向RNN
keras.layers.Bidirectional(
keras.layers.SimpleRNN(
# 这里的应为True,因为下层也是序列
units=64, return_sequences=True)),
keras.layers.Bidirectional(
keras.layers.SimpleRNN(
units=64, return_sequences=False)),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dense(1, activation='sigmoid'),
])
model_1.summary()
model_1.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 500, 16) 160000
_________________________________________________________________
bidirectional (Bidirectional (None, 500, 128) 10368
_________________________________________________________________
bidirectional_1 (Bidirection (None, 128) 24704
_________________________________________________________________
dense_2 (Dense) (None, 64) 8256
_________________________________________________________________
dense_3 (Dense) (None, 1) 65
=================================================================
Total params: 203,393
Trainable params: 203,393
Non-trainable params: 0
_________________________________________________________________
history_1 = model_1.fit(train_data,
train_labels,
epochs=30,
batch_size=batch_size,
validation_split=0.2)
Train on 20000 samples, validate on 5000 samples
Epoch 1/30
20000/20000 [==============================] - 168s 8ms/sample - loss: 0.6978 - accuracy: 0.5059 - val_loss: 0.7007 - val_accuracy: 0.4900
Epoch 2/30
20000/20000 [==============================] - 171s 9ms/sample - loss: 0.6919 - accuracy: 0.5235 - val_loss: 0.6928 - val_accuracy: 0.5232
Epoch 3/30
20000/20000 [==============================] - 172s 9ms/sample - loss: 0.6526 - accuracy: 0.6152 - val_loss: 0.7167 - val_accuracy: 0.5330
Epoch 4/30
20000/20000 [==============================] - 180s 9ms/sample - loss: 0.5870 - accuracy: 0.6728 - val_loss: 0.6884 - val_accuracy: 0.5422
Epoch 5/30
20000/20000 [==============================] - 188s 9ms/sample - loss: 0.5882 - accuracy: 0.6913 - val_loss: 0.7509 - val_accuracy: 0.5498
Epoch 6/30
20000/20000 [==============================] - 173s 9ms/sample - loss: 0.5025 - accuracy: 0.7643 - val_loss: 0.8274 - val_accuracy: 0.5466
Epoch 7/30
20000/20000 [==============================] - 170s 9ms/sample - loss: 0.4354 - accuracy: 0.8116 - val_loss: 0.9211 - val_accuracy: 0.5430
Epoch 8/30
20000/20000 [==============================] - 163s 8ms/sample - loss: 0.3923 - accuracy: 0.8354 - val_loss: 0.9382 - val_accuracy: 0.5548
Epoch 9/30
20000/20000 [==============================] - 157s 8ms/sample - loss: 0.3507 - accuracy: 0.8588 - val_loss: 1.0652 - val_accuracy: 0.5402
Epoch 10/30
20000/20000 [==============================] - 166s 8ms/sample - loss: 0.3058 - accuracy: 0.8818 - val_loss: 1.0596 - val_accuracy: 0.5392
Epoch 11/30
20000/20000 [==============================] - 162s 8ms/sample - loss: 0.2636 - accuracy: 0.9028 - val_loss: 1.2205 - val_accuracy: 0.5404
Epoch 12/30
20000/20000 [==============================] - 176s 9ms/sample - loss: 0.2265 - accuracy: 0.9214 - val_loss: 1.4595 - val_accuracy: 0.5346
Epoch 13/30
20000/20000 [==============================] - 157s 8ms/sample - loss: 0.2072 - accuracy: 0.9298 - val_loss: 1.3241 - val_accuracy: 0.5366
Epoch 14/30
20000/20000 [==============================] - 162s 8ms/sample - loss: 0.1818 - accuracy: 0.9418 - val_loss: 1.3823 - val_accuracy: 0.5330
Epoch 15/30
20000/20000 [==============================] - 161s 8ms/sample - loss: 0.1698 - accuracy: 0.9451 - val_loss: 1.5354 - val_accuracy: 0.5388
Epoch 16/30
20000/20000 [==============================] - 160s 8ms/sample - loss: 0.1546 - accuracy: 0.9516 - val_loss: 1.4744 - val_accuracy: 0.5406
Epoch 17/30
20000/20000 [==============================] - 162s 8ms/sample - loss: 0.1437 - accuracy: 0.9567 - val_loss: 1.5701 - val_accuracy: 0.5388
Epoch 18/30
20000/20000 [==============================] - 171s 9ms/sample - loss: 0.1289 - accuracy: 0.9622 - val_loss: 1.5875 - val_accuracy: 0.5404
Epoch 19/30
20000/20000 [==============================] - 173s 9ms/sample - loss: 0.1241 - accuracy: 0.9627 - val_loss: 1.6246 - val_accuracy: 0.5360
Epoch 20/30
20000/20000 [==============================] - 154s 8ms/sample - loss: 0.1199 - accuracy: 0.9645 - val_loss: 1.9189 - val_accuracy: 0.5378
Epoch 21/30
20000/20000 [==============================] - 164s 8ms/sample - loss: 0.1215 - accuracy: 0.9645 - val_loss: 1.6664 - val_accuracy: 0.5422
Epoch 22/30
20000/20000 [==============================] - 163s 8ms/sample - loss: 0.1082 - accuracy: 0.9680 - val_loss: 1.5878 - val_accuracy: 0.5426
Epoch 23/30
20000/20000 [==============================] - 168s 8ms/sample - loss: 0.0917 - accuracy: 0.9753 - val_loss: 1.8180 - val_accuracy: 0.5360
Epoch 24/30
20000/20000 [==============================] - 161s 8ms/sample - loss: 0.0987 - accuracy: 0.9721 - val_loss: 1.6707 - val_accuracy: 0.5366
Epoch 25/30
20000/20000 [==============================] - 167s 8ms/sample - loss: 0.1117 - accuracy: 0.9663 - val_loss: 1.6564 - val_accuracy: 0.5402
Epoch 26/30
20000/20000 [==============================] - 166s 8ms/sample - loss: 0.1579 - accuracy: 0.9454 - val_loss: 1.2796 - val_accuracy: 0.5350
Epoch 27/30
20000/20000 [==============================] - 173s 9ms/sample - loss: 0.1547 - accuracy: 0.9489 - val_loss: 1.4764 - val_accuracy: 0.5392
Epoch 28/30
20000/20000 [==============================] - 171s 9ms/sample - loss: 0.2728 - accuracy: 0.8960 - val_loss: 1.6718 - val_accuracy: 0.5282
Epoch 29/30
20000/20000 [==============================] - 161s 8ms/sample - loss: 0.2078 - accuracy: 0.9259 - val_loss: 0.9639 - val_accuracy: 0.5344
Epoch 30/30
20000/20000 [==============================] - 159s 8ms/sample - loss: 0.1861 - accuracy: 0.9371 - val_loss: 1.5880 - val_accuracy: 0.5372
plot_learning_curves(history_1, 'accuracy', 30, 0, 1)
plot_learning_curves(history_1, 'loss', 30, 0, 3.8)


可以看出过拟合现象很严重,第一说明了模型的强大,第二说明了模型设置的有点复杂
- 降低模型复杂度:一个双向RNN,神经元个数为32的模型
embedding_dim = 16
batch_size = 128
model_2 = keras.models.Sequential([
keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
# 封装为双向RNN
keras.layers.Bidirectional(
keras.layers.SimpleRNN(
units=32, return_sequences=False)),
keras.layers.Dense(32, activation='relu'),
keras.layers.Dense(1, activation='sigmoid'),
])
model_2.summary()
model_2.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_4 (Embedding) (None, 500, 16) 160000
_________________________________________________________________
bidirectional_5 (Bidirection (None, 64) 3136
_________________________________________________________________
dense_8 (Dense) (None, 32) 2080
_________________________________________________________________
dense_9 (Dense) (None, 1) 33
=================================================================
Total params: 165,249
Trainable params: 165,249
Non-trainable params: 0
_________________________________________________________________
history_2 = model_2.fit(train_data,
train_labels,
epochs=10,
batch_size=batch_size,
validation_split=0.2)
Train on 20000 samples, validate on 5000 samples
Epoch 1/10
20000/20000 [==============================] - 83s 4ms/sample - loss: 0.6745 - accuracy: 0.5544 - val_loss: 0.5762 - val_accuracy: 0.7058
Epoch 2/10
20000/20000 [==============================] - 89s 4ms/sample - loss: 0.4302 - accuracy: 0.8131 - val_loss: 0.4107 - val_accuracy: 0.8210
Epoch 3/10
20000/20000 [==============================] - 88s 4ms/sample - loss: 0.5001 - accuracy: 0.7404 - val_loss: 0.6005 - val_accuracy: 0.6690
Epoch 4/10
20000/20000 [==============================] - 88s 4ms/sample - loss: 0.3375 - accuracy: 0.8574 - val_loss: 0.4184 - val_accuracy: 0.8326
Epoch 5/10
20000/20000 [==============================] - 83s 4ms/sample - loss: 0.2070 - accuracy: 0.9226 - val_loss: 0.5412 - val_accuracy: 0.7658
Epoch 6/10
20000/20000 [==============================] - 83s 4ms/sample - loss: 0.1284 - accuracy: 0.9570 - val_loss: 0.5265 - val_accuracy: 0.8252
Epoch 7/10
20000/20000 [==============================] - 85s 4ms/sample - loss: 0.0699 - accuracy: 0.9794 - val_loss: 0.6316 - val_accuracy: 0.8304
Epoch 8/10
20000/20000 [==============================] - 85s 4ms/sample - loss: 0.0459 - accuracy: 0.9863 - val_loss: 0.6806 - val_accuracy: 0.8280
Epoch 9/10
20000/20000 [==============================] - 88s 4ms/sample - loss: 0.0362 - accuracy: 0.9891 - val_loss: 0.7738 - val_accuracy: 0.8224
Epoch 10/10
20000/20000 [==============================] - 87s 4ms/sample - loss: 0.0171 - accuracy: 0.9955 - val_loss: 0.8986 - val_accuracy: 0.8252
plot_learning_curves(history_2, 'accuracy', 10, 0, 1)
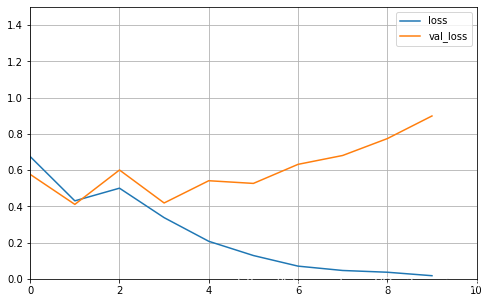
plot_learning_curves(history_2, 'loss', 10, 0, 1.5)

model_2.evaluate(
test_data, test_labels,
batch_size = batch_size)
25000/25000 [==============================] - 16s 654us/sample - loss: 0.9746 - accuracy: 0.8091
[0.9745925375175476, 0.80912]
可以看到仅仅训练了十次,训练效果已经很好了,过拟合现象明显减小。
