系列文章
- CSDN问答标签技能树(一) —— 基本框架的构建
- CSDN问答标签技能树(二) —— 效果优化
- CSDN问答标签技能树(三) —— Python技能树
- CSDN问答标签技能树(四) —— Java技能树
- CSDN问答标签技能树(五) —— 云原生技能树
团队博客: CSDN AI小组
1 问题定义
1.1 背景
当前CSDN问答模块中的提问只进行了简单的归类,例如:Python、Java、C语言等大类,而未将提问映射到大类中的具体知识点,例如在下图的例子中,该问题属于Python语言中的数据可视化问题。
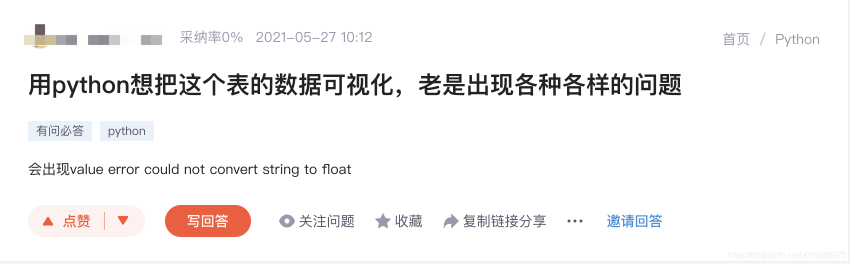
将问题进行细粒度的归类和划分,可以让提问者更清楚的了解自己所提的问题在知识体系中的位置,也便于系统更精准地推荐相关的资料给提问者进行学习和参考。
为了解决上述问题,本文首先针对每个大类构建编程语言技能树,然后再将以往已采纳的提问映射到技能树中具体的结点中,最后对于一个新来的提问,基于构建好的技能树,匹配到最相似的结点,并推荐该结点上的已采纳提问。
2 解决方案
2.1 知识搜集
要想构建编程技能树,首先需要搜集相关的知识,本文先以Python编程语言为例,进行具体的实现。
通过在网上的搜索和调研,总结出以下两个渠道:
-
从某东上爬去目录
- 按关键字"python"从某东上搜索,并按销量筛选出Top N的书籍
- 从详情页面中抽取目录字段的内容,获得未经处理的目录
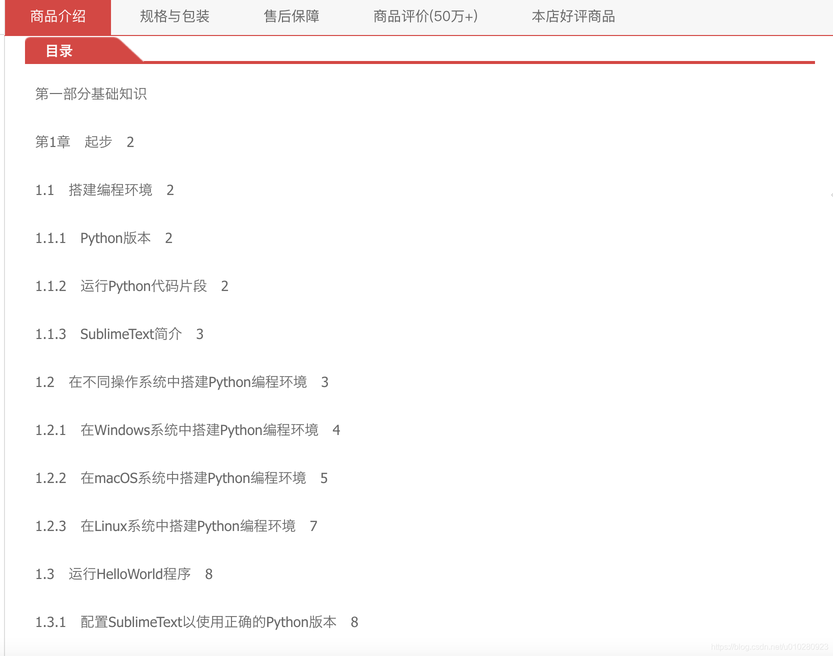
-
网站论坛上的学习路径:

2.2 技能树的构建
在获得相应的知识资源之后,需要将资源存储到树结构中,本文采用treelib包进行实现。
为了方便下一节中树的合并,本文将目录限制为4层结构:
- 大章标题。例如:第一部分
- 小章标题。例如:第1章
- 大节标题。例如:1.1
- 小节标题。例如:1.1.1
结构化之后的树结构如下图所示:

2.3 技能树的合并
基于不同来源的目录和知识体系资源构建好技能树之后,需要将多棵不同的技能树进行合并,形成一棵同一的Python技能树。
对于树的合并,本文主要考虑了以下几个方面:
- 从根节点开始按层进行合并
- 使用递归的方法将多棵树进行合并
- 同一层中相似的节点需要进行合并
- 使用启发式的聚类方法(不需要预先确定簇的个数),将节点划分到多个簇中
- 聚类时的相似度计算方法使用 最长公共子序列比+莱文斯坦比(编辑距离比) 的方法进行计算
- 合并后新的节点,使用多个句子的最长公共子序列代替,例如:3个结点 if语句使用、if语句处理列表设置、if语句的格式 的最长公共子序列为 if语句 ,最后使用 if语句 作为合并节点的值。
- 去掉无用的节点
- 使用树剪枝+词典的方法,去掉技能树中的无用节点,例如:本章小结、延伸阅读、项目等章节节点。
合并后的技能树如下图所示:

2.4 问题与技能树的匹配
技能树构建好之后,需要将Python领域所有已采纳的问题映射到相应的结点上,并且对于一个新来的提问,基于构建好的技能树,匹配到最相似的结点,并推荐该结点上的已采纳提问。
本文采用的匹配算法为莱文斯坦比(编辑距离比),通过计算提问与结点的莱文斯坦比值,确定提问最匹配的结点。
3 总结与下一步计划
总结
本文主要实现了编程语言技能树的构建与合并,以及提问与技能树中结点的匹配。现在只是实现了初步功能,效果还需要进一步优化。当前存在的问题主要包括:
- 无关节点的去除不够干净
- 聚类时的相似度计算方法,以及多个节点合并后的新结点使用最长公共子序列代替不合理,例如: Python版本运行 和 Python代码片段 被划分到同一个簇,并且合并后为 Python
- 提问和技能树中结点的描述风格相差较大,一个是提问,一个是知识点,在提问和结点匹配时使用 莱文斯坦比(编辑距离比) 的方法计算相似度不合理
- ……
下一步计划
针对当前存在的问题,下一步考虑:
- 进一步改进合成的技能树的质量
- 改进问题和树的匹配效果