Multi-scale Hierarchical Vision Transformer with Cascaded Attention Decoding for Medical Image Segmentation
摘要
- 多尺度vision transformer
- 级联注意解码
- 多阶段特征混合损失聚集方法
- 代码链接
方法
网络结构如下:
从骨干网的四个不同阶段提取层次特征,并将这些特征传递给各自的并行解码器
多尺度特征
将第一个骨干网的跳过连接添加到第二个骨干网的跳过连接
使用了最新的SOTA 之一MaxViT
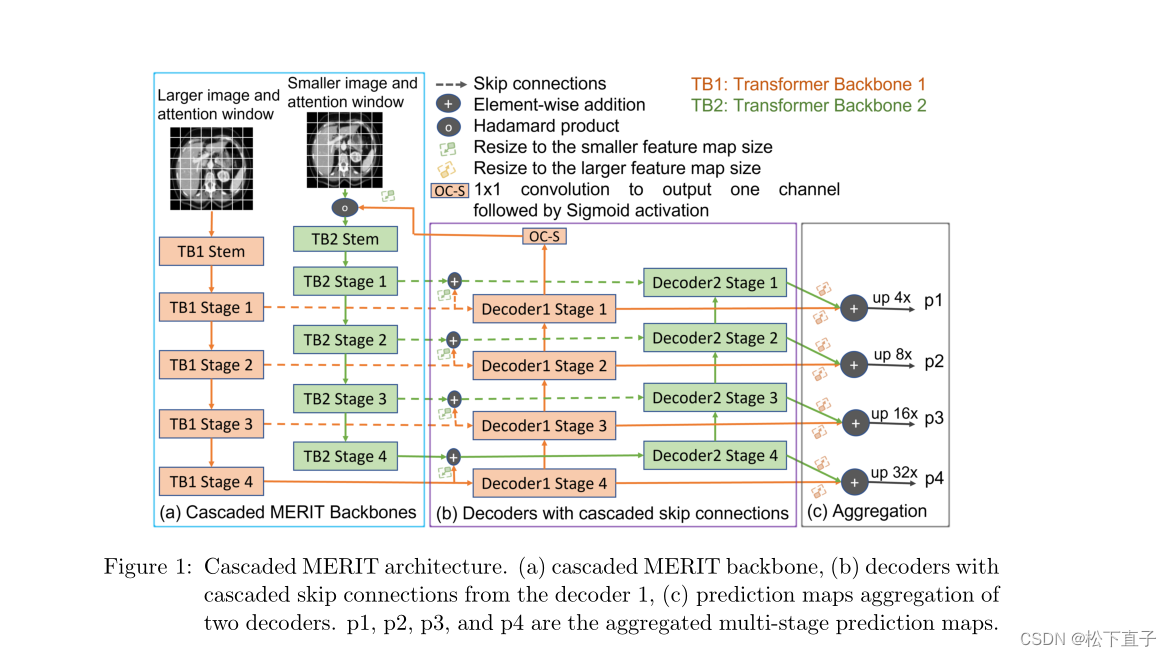
最终的结果:
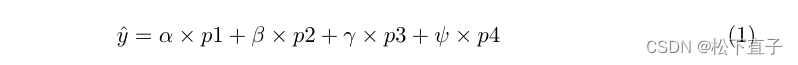
结合现有的预测图创建新的预测图。因此,我们将来自网络不同阶段的所有预测映射作为输入,并将使用n个预测映射的2的n次方−1个非空子集生成的预测映射的损失汇总。例如,如果一个网络产生4个预测图,我们的多阶段特征混合损失聚合总共产生2的4次方−1 = 15个预测图,其中包括4个原始图。这种混合策略很简单,它不需要额外的参数来计算,也不引入推理开销。由于其潜在的优势,该策略可以用于任何多级图像分割或密集预测网络。算法1给出了生成新的预测图和损失聚合的步骤

就是将特征图进行求和操作
求和的代码:
for i, val_sampled_batch in enumerate(valloader):
val_image_batch, val_label_batch = val_sampled_batch["image"], val_sampled_batch["label"]
val_image_batch, val_label_batch = val_image_batch.squeeze(0).cpu().detach().numpy(), val_label_batch.squeeze(0).cpu().detach().numpy()
x, y = val_image_batch.shape[0], val_image_batch.shape[1]
if x != args.img_size or y != args.img_size:
val_image_batch = zoom(val_image_batch, (args.img_size / x, args.img_size / y), order=3) # not for double_maxvits
val_image_batch = torch.from_numpy(val_image_batch).unsqueeze(0).unsqueeze(0).float().cuda()
P = net(val_image_batch)
#print(len(P))
val_outputs = 0.0
for idx in range(len(P)):
val_outputs += P[idx]
val_outputs = torch.softmax(val_outputs, dim=1)
val_outputs = torch.argmax(val_outputs, dim=1).squeeze(0)
val_outputs = val_outputs.cpu().detach().numpy()
if x != args.img_size or y != args.img_size:
val_outputs = zoom(val_outputs, (x / args.img_size, y / args.img_size), order=0)
else:
val_outputs = val_outputs
dc_sum+=dc(val_outputs,val_label_batch[:])
前向代码:
def forward(self, x):
# if grayscale input, convert to 3 channels
if x.size()[1] == 1:
x = self.conv(x)
#print(x.shape)
# transformer backbone as encoder
if(x.shape[2]%14!=0):
f1 = self.backbone1(F.interpolate(x, size=self.img_size_s1, mode=self.interpolation))
else:
f1 = self.backbone2(F.interpolate(x, size=self.img_size_s1, mode=self.interpolation))
#print([f[3].shape,f[2].shape,f[1].shape,f[0].shape])
# decoder
x11_o, x12_o, x13_o, x14_o = self.decoder(f1[3], [f1[2], f1[1], f1[0]])
# prediction heads
p11 = self.out_head1(x11_o)
p12 = self.out_head2(x12_o)
p13 = self.out_head3(x13_o)
p14 = self.out_head4(x14_o)
# calculate feedback from 1st decoder
p14_in = self.out_head4_in(x14_o)
p14_in = self.sigmoid(p14_in)
p11 = F.interpolate(p11, scale_factor=32, mode=self.interpolation)
p12 = F.interpolate(p12, scale_factor=16, mode=self.interpolation)
p13 = F.interpolate(p13, scale_factor=8, mode=self.interpolation)
p14 = F.interpolate(p14, scale_factor=4, mode=self.interpolation)
#print([p11.shape,p12.shape,p13.shape,p14.shape])
p14_in = F.interpolate(p14_in, scale_factor=4, mode=self.interpolation)
# apply feedback from 1st decoder to input
x_in = x * p14_in
if(x.shape[2]%14!=0):
f2 = self.backbone2(F.interpolate(x_in, size=self.img_size_s2, mode=self.interpolation))
else:
f2 = self.backbone1(F.interpolate(x_in, size=self.img_size_s2, mode=self.interpolation))
skip1_0 = F.interpolate(f1[0], size=(f2[0].shape[-2:]), mode=self.interpolation)
skip1_1 = F.interpolate(f1[1], size=(f2[1].shape[-2:]), mode=self.interpolation)
skip1_2 = F.interpolate(f1[2], size=(f2[2].shape[-2:]), mode=self.interpolation)
skip1_3 = F.interpolate(f1[3], size=(f2[3].shape[-2:]), mode=self.interpolation)
x21_o, x22_o, x23_o, x24_o = self.decoder(f2[3]+skip1_3, [f2[2]+skip1_2, f2[1]+skip1_1, f2[0]+skip1_0])
p21 = self.out_head1(x21_o)
p22 = self.out_head2(x22_o)
p23 = self.out_head3(x23_o)
p24 = self.out_head4(x24_o)
#print([p21.shape,p22.shape,p23.shape,p24.shape])
p21 = F.interpolate(p21, size=(p11.shape[-2:]), mode=self.interpolation)
p22 = F.interpolate(p22, size=(p12.shape[-2:]), mode=self.interpolation)
p23 = F.interpolate(p23, size=(p13.shape[-2:]), mode=self.interpolation)
p24 = F.interpolate(p24, size=(p14.shape[-2:]), mode=self.interpolation)
p1 = p11 + p21
p2 = p12 + p22
p3 = p13 + p23
p4 = p14 + p24
#print([p1.shape,p2.shape,p3.shape,p4.shape])
return p1, p2, p3, p4