一 前言
作为严重影响 Android 口碑问题之一的 UI 流畅性差的问题,首先在 Android 4.1 版本中得到了有效处理。其解决方法即在 4.1 版本推出的 Project Butter。Project Butter 对 Android Display系统进行了重构,引入三个核心元素:VSYNC、Triple Buffer和 Choreographer。 其中,VSYNC 是理解 Project Buffer 的核心。VSYNC 是 Vertical Synchronization(垂直同步)的 缩写,是一种在 PC 上已经很早就广泛使用的技术,读者可简单地把它认为是一种定时中断。 Choreographer 起调度的作用,将绘制工作统一到 VSYNC 的某个时间点上,使应用的绘制工 作有序。接下来,本文将围绕 VSYNC 来介绍 Android Display 系统的工作方式。 在讲解刷新机制之前,先介绍几个名词以及 VSYNC 和 Choreographer 主要功能及工作方式。
**双缓冲:**显示内容的数据内存,为什么要用双缓冲,我们知道在 Linux 上通常使用 Framebuffer 来做显示输出,当用户进程更新 Framebuffer 中的数据后,显示驱动会把 Framebuffer 中每个像素点的值更新到屏幕,但这样会带来一个问题,如果上一帧的数据还 没有显示完,Framebuffer 中的数据又更新了,就会带来残影的问题,给用户直观的感觉就 会有闪烁感,所以普遍采用了双缓冲技术。双缓冲意味着要使用两个缓冲区(在 SharedBufferStack 中),其中一个称为 Front Buffer,另外一个称为 Back Buffer。UI 总是先在 Back Buffer 中绘制,后台绘制好,然后再和 Front Buffer 交换,渲染到显示设备中。即只有 当另一个 buffer 的数据准备好后,通过 io_ctrl 来通知显示设备切换 Buffer
**VSYNC:**从前面的双缓冲介绍中可以了解到,只有当另一个 buffer 准备好后,才能 通知刷新,这就需要 CPU 以主动查询的方式来保证数据是否准备好,因为这种机制效率很 低,所以引入了 VSYNC。VSYNC 是 Vertical Synchronization(垂直同步)的缩写,可以简单地 把它认为是一种定时中断,一旦收到 VSYNC 中断,CPU 就开始处理各帧数据。
**Choreographer:**收到 VSYNC 信号时,调用用户设置的回调函数。一共有以下三种类型 的回调:
·CALLBACK_INPUT:优先级最高,与输入事件有关。
·CALLBACK_ANIMATION:第二优先级,与动画有关。 ·CALLBACK_TRAVERSAL:最低优先级,与 UI 控件绘制有关。
接下来通过时序图来分析刷新的过程,这些时序图是 Google 在 2012 Google I/O 讲解新 的显示系统提供的,图 2-7 所示的时序图有三个元素:Display(显示设备),CPU-CPU 准备 数据,GPU-GPU 准备数据。最下面的时间为显示时间,根据理想的 60FPS,以 16ms 为一个 显示周期。
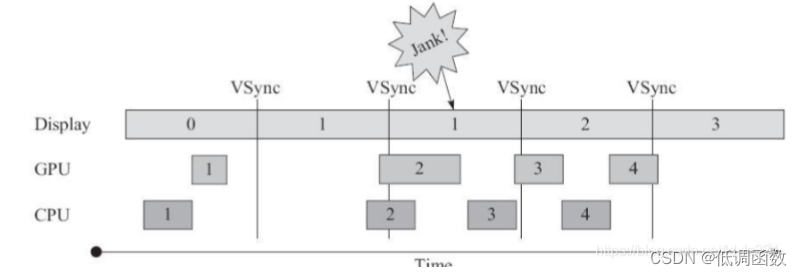
1.1 没有 VSync 信号同步
我们以 16ms 为单位来进行分析:
- 从第一个 16ms 开始看,Display 显示第 0 帧,CPU 处理完第一帧后,GPU 紧接其后 处理继续第一帧。三者都在正常工作。
- 时间进入第二个 16ms:因为在上一个 16ms 时间内,第 1 帧已经由 CPU、GPU 处 理完毕。所以 Display可以正常显示第 1 帧。显示没有问题,但在本 16ms 期间,CPU 和 GPU 并未及时绘制第 2帧数据(前面的空白区在忙别事情去了),而是在本周期快结束时, CPU/GPU 才去处理第 2 帧数据。
- 时间进入第 3 个 16ms,此时 Display 应该显示第 2 帧数据,但由于 CPU 和 GPU 还 没有处理完第 2 帧数据,故 Display 只能继续显示第一帧的数据,结果使得第 1 帧多画了一 次(对应时间段上标注了一个 Jank),这就导致错过了显示第二帧。通过上述分析可知,在第二个 16ms 时,发生 Jank 的关键问题在于,为何在第 1 个 16ms 段内,CPU/GPU没有及时处理第 2 帧数据?从第二个 16ms 开始有一段空白的时间,可以说 明原因所在,那就是 CPU可能是在忙别的事情,不知道该到处理 UI 绘制的时间了。可 CPU 一旦想起来要去处理第 2帧数据,时间又错过了。为解决这个问题,4.1 版本推出了 Project Butter,核心目的就是解决刷新不同步的问题。
1.2 有 VSync 信号同步
加入 VSync 后,从下图可以看到,一旦收到 VSync 中断,CPU 就开始处理各帧的数 据。大部分的 Android 显示设备刷新率是 60Hz,这也就意味着 每一帧最多只能有 1/60=16ms 左右的准备时间。假如 CPU/GPU 的 FPS 高于这个值,显示效 果将更好。但是,这时又出现了一个新问题:CPU 和 GPU 处理数据的速度都能在 16ms 内完 成,而且还有时间空余,但必须等到 VSYNC 信号到来后,才处理下一帧数据,因此 CPU/GPU 的 FPS 被拉低到与 Display 的 FPS 相同。
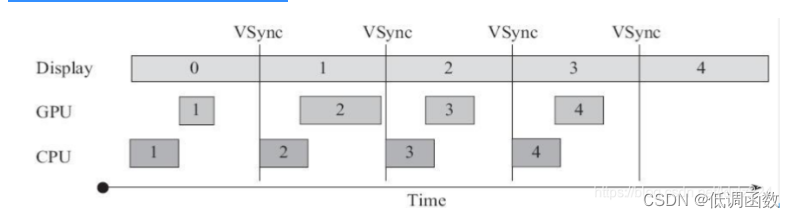
从下图采用双缓冲区的显示效果来看:在双缓冲下,CPU/GPU FPS 大于刷新频率同 时采用了双缓冲技术以及 VSync,可以看到整个过程还是相当不错的,虽然 CPU/GPU 处理所 用的时间时短时长,但总体来说都在 16ms 以内,因而不影响显示效果。A 和 B 分别代表两 个缓冲区,它们不断交换来正确显示画面。
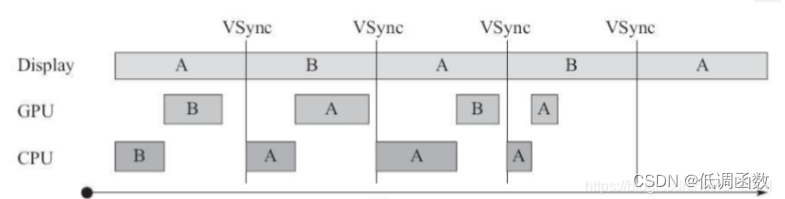
但如果 CPU/GPU 的 FPS 小于 Display 的 FPS,情况又不同了,如下图所示。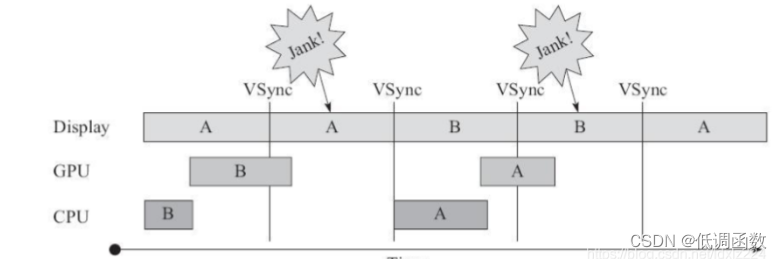
从上图可以看到,当 CPU/GPU 的处理时间超过 16ms 时,第一个 VSync 就已经到来, 但缓冲区 B 中的数据却还没有准备好,这样就只能继续显示之前 A 缓冲区中的内容。而后 面 B 完成后,又因为还没有 VSync 信号,CPU/GPU 这个时候只能等待下一个 VSync 的来临才 开始处理下一帧数据。因此在整个过程中,有一大段时间被浪费。总结这段话就是:
1)在第二个 16ms 时间段内,Display 本应显示 B 帧,但因为 GPU 还在处理 B 帧,导 致 A 帧被重复显示。
2)同理,在第二个 16ms 时间段内,CPU 无所事事,因为 A Buffer 由 Display 在使用。 B Buffer 由 GPU 使用。注意,一旦过了 VSYNC 时间点,CPU 就不能被触发以及处理绘制工作 了。 为什么 CPU 不能在第二个 16ms 处即 VSync 到来就开始工作呢?很明显,原因就是只 有两个Buffer。如果有第三个Buffer存在,CPU就可以开始工作,而不至于空闲。于是在Andoird 4.1 以后,引出了第三个缓冲区:Triple Buffer。
Triple Buffer 利用 CPU/GPU 的空闲等待时间 提前准备好数据,并不一定会使用。 [注意 在大部分情况下,只使用到双缓存,只有在需要时,才会用三缓冲来增强,这时可以把输入的延迟降到最少,保持画面的流畅。
引入 Triple Buffer 后的刷新时序如下图所示。

在第二个 16ms 时间段,CPU 使用 C Buffer 绘图。虽然还是会多显示一次 A 帧,但后续 显示就比较顺畅了。是不是 Buffer 越多越好呢?回答是否定的。由图 2-11 可知,在第二个 时间段内,CPU 绘制的第 C 帧数据要到第四个 16ms 才能显示,这比双缓存情况多了 16ms批注 [KG1]: CPU 的第三个 A->B 延迟。所以缓冲区不是越多越好,要做到平衡到最佳效果。
二 Android UI的刷新机制
我们带着问题去了解android的UI刷新机制:
- 丢帧一般是什么原因引起的
- Android 刷新频率 60帧/S,每隔 16ms 调 onDraw() 绘制一次么?
- onDraw() 完成之后会马上刷新么?
- 如果界面没有重绘,还会每隔 16ms 刷新屏幕么?
- 如果在屏幕快要刷新的时候才去 onDraw() 绘制会丢帧么?
根据前言
应用从系统服务申请 buffer ,系统服务返回给应用 buffer,应用拿到 buffer 之后进行绘制,绘制完成后交给系统服务。系统服务会将 buffer 写到缓冲区里面,屏幕会有一定的帧率刷新,每次刷新会从缓冲区中取出 buffer 然后显示出来。如果没有新的数据可以取就一直从老的数据,这样看起来屏幕就一直没有变,这就是基本的显示原理,如下图
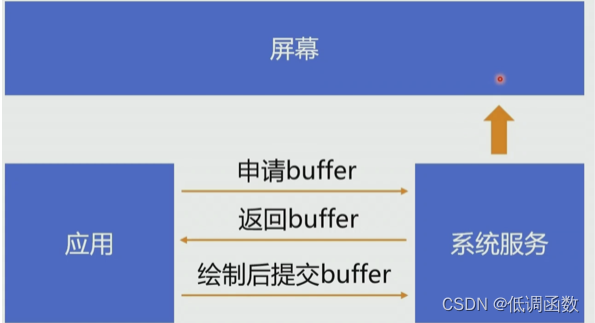
那么屏幕的图像缓存是啥样的呢?
系统服务并没有用一个缓存,因为如果屏幕正在读缓存,这时候正好又写缓存,可能导致屏幕显示的东西不正常,所以用的是两个缓存,一个读一个写,如果要显示下一帧,将两个缓存交换就行了。
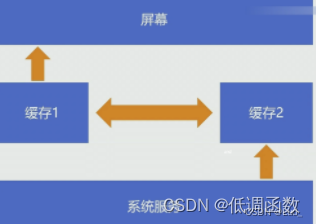
应用端是从什么时候开始绘制的?
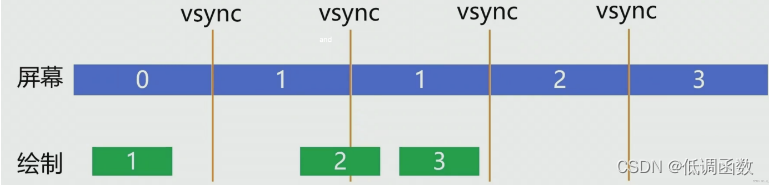
屏幕是根据 vsync 信号周期性的刷新的,vsync 信号是一个固定频率的脉冲信号,屏幕每次收到 vsync 信号就会去缓冲区取出一帧信号进行显示。这种绘制是由客户端随时发起的,这样有什么弊端呢?
上面这个图,第一个vsync 屏幕显示的是第 0 帧图像,第一个周期显示的是第 1 帧图像,因为第一帧在 Vsync 来的时候已经准备好了,第三个信号周期还是显示的是第一帧,原因是 vsync 信号来的时候,第二帧没有准备好(也有可能是vsync信号快来的时候才开始绘制,所以即准备时间短也有可能造成这种现象)如果这种现象经常发生的话用户就可以感觉得到页面会有一点卡顿。
但是如果绘制也能和 vsync 信号一致的话这种类型的问题就可以解决了如下图:

如果每一次信号来的时候,页面开始绘制,如果页面优化的非常好,每次都能在16ms内完成页面就可以非常流畅了。那么有个问题是requestLayout() 发起绘制是随时可以发起的,那么android系统是怎么做的才能达到这样的效果?Android 系统服务有一个类 Choreographer ,往其内部发送一个消息,这个消息最快也要等到下一个 vsync 信号来的时候才能触发,相当于UI绘制的节奏完全由 Choreographer 来控制。

三 Choreographer 实现原理
我们从客户端发起刷新 UI 重绘的方法 ViewRootImpl 的 requestLayout() 开始
@Override
public void requestLayout() {
// 检查线程
checkThread();
scheduleTraversals();
}
scheduleTraversals()
void scheduleTraversals() {
// 往线程的消息队列里面插入了一个 SyncBarrier 消息
// Barrier 是屏障的意思 消息队列中插入该屏障消息以后,普通消息就停止处理等待它处理完成。
// 但是屏障对异步消息是没有影响的
mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
// 往 mChoreographer 中插入了一个 postCallback
// mChoreographer = Choreographer.getInstance(); 他是从 sThreadInstance threadLocal 获取的 并不是单例模式,所以在不同的线程取出来的是不用的 mChoreographer 对象
// mChoreographer 是在 viewRootImpl 的构造器中创建的
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
}
上面方法先将线程的消息队列中插入一个屏障消息,让普通消息先停止,先执行屏障消息后在执行其他消息,然后通过 mChoreographer 发送了一个 callback 传入 mTraversalRunnable runnable 等待 async 信号来的时候执行
如果多次调用 requestLayout 会怎么样。?
void scheduleTraversals() {
if (!mTraversalScheduled) {
mTraversalScheduled = true;
// mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
// mChoreographer.postCallback(Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
}
}
首次调用后 mTraversalScheduled 会设置成 true ,防止多次调用。那么什么时候设置回 false 的呢,答案是在传入到 mChoreographer 的 runnable mTraversalRunnable中,也就是下一次信号来的时候执行 runnable 设置成 false。
final class TraversalRunnable implements Runnable {
@Override
public void run() {
doTraversal();
}
}
// 将 mTraversalScheduled = false; 设置成 false
void doTraversal() {
if (mTraversalScheduled) {
mTraversalScheduled = false;
mHandler.getLooper().getQueue().removeSyncBarrier(mTraversalBarrier);
performTraversals();
}
}
那么 mChoreographer.postCallback() 是怎么添加到 mChoreographer 中去的?
public void postCallback(int callbackType, Runnable action, Object token) {
postCallbackDelayed(callbackType, action, token, 0);
}
public void postCallbackDelayed(int callbackType,Runnable action, Object token, long delayMillis){
postCallbackDelayedInternal(callbackType, action, token, delayMillis);
}
// 最终调用了 postCallbackDelayedInternal 方法
private void postCallbackDelayedInternal(int callbackType,
Object action, Object token, long delayMillis) {
synchronized (mLock) {
final long now = SystemClock.uptimeMillis();
final long dueTime = now + delayMillis;
// 根据不同的 callbackType 插入到对应的单链表中,然后通过 dueTime 进行排序
mCallbackQueues[callbackType].addCallbackLocked(dueTime, action, token);
if (dueTime <= now) {
scheduleFrameLocked(now);
} else {
Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_CALLBACK, action);
msg.arg1 = callbackType;
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, dueTime);
}
}
}
scheduleFrameLocked(now);.
private void scheduleFrameLocked(long now) {
// 如果当前线程就是 Choreographer 的工作线程,直接调用 scheduleVsyncLocked()
if (isRunningOnLooperThreadLocked()) {
scheduleVsyncLocked();
} else {
// 否则发送 mHandler 到Choreographer的工作线程的 queue 的最前面
Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_VSYNC);
// 设置成异步消息
msg.setAsynchronous(true);
// 设置到最前面,当信号来时第一个执行
mHandler.sendMessageAtFrontOfQueue(msg);
}
}
scheduleFrameLocked() 方法就是判断线程,如果当前就是 Choreographer 工作线程则直接 发送 mDisplayEventReceiver.scheduleVsync(); 如果不是则发送 Hander 到工作线程中。当 Vsync 信号来的时候 surfaceFlinger 第一时间通知 Choreographer 刷新。
surfaceFlinger 来的时候会回调到 DisplayEventReceiver 的 onVsync() 函数,它的实现类是 Choreographer. 的内部类,在 Choreographer. 的构造器中初始化的。
private final class FrameDisplayEventReceiver extends DisplayEventReceiver implements Runnable {
public FrameDisplayEventReceiver(Looper looper, int vsyncSource) {
super(looper, vsyncSource);
}
@Override
public void onVsync(long timestampNanos, int builtInDisplayId, int frame) {
// 。。。
mTimestampNanos = timestampNanos;
mFrame = frame;
// this 是把自己传进去了,到时候 mHandler 发送消息执行的 run 方法就是下面的 方法
Message msg = Message.obtain(mHandler, this);
msg.setAsynchronous(true);
// 发送时带上时间戳 到时间再执行 run()
mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS);
}
@Override
public void run() {
mHavePendingVsync = false;
doFrame(mTimestampNanos, mFrame);
}
}
doFrame()
void doFrame(long frameTimeNanos, int frame) {
// 第一阶段
long intendedFrameTimeNanos = frameTimeNanos;
startNanos = System.nanoTime();
// 计算一下晚了多久
final long jitterNanos = startNanos - frameTimeNanos;
// 如果晚的时间超过一定时间
if (jitterNanos >= mFrameIntervalNanos) {
// 计算一下晚了多少帧
final long skippedFrames = jitterNanos / mFrameIntervalNanos;
if (skippedFrames >= SKIPPED_FRAME_WARNING_LIMIT) {
// 打日志高速我们主线程执行太多的任务
Log.i(TAG, "Skipped " + skippedFrames + " frames! "
+ "The application may be doing too much work on its main thread.");
}
final long lastFrameOffset = jitterNanos % mFrameIntervalNanos;
frameTimeNanos = startNanos - lastFrameOffset;
}
// 第二阶段 处理 callback
try {
doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos);、
doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos);
}
}
上面第二阶段 执行 doCallbacks 根据不同类型,执行不同的 callback,callback 是有时间戳的 只有时间到了才会去回调。
void doCallbacks(int callbackType, long frameTimeNanos) {
CallbackRecord callbacks;
synchronized (mLock) {
final long now = System.nanoTime();
// 取出到了时间的 callback
callbacks = mCallbackQueues[callbackType].extractDueCallbacksLocked(
now / TimeUtils.NANOS_PER_MS);
if (callbacks == null) {
return;
}
// .....
}
try {
for (CallbackRecord c = callbacks; c != null; c = c.next) {
// 执行 run 方法
c.run(frameTimeNanos);
}
}
}
doCallbacks 就是根据类型取出到了时间的 callback ,然后执行它的 run 方法。之前讲过传入的 callback run 执行的是 doTraversal(); ,它内部执行了 performTraversals(); 函数,performTraversals(); 就是真正的执行绘制的方法。之后就是执行 performMeasure() ,performLayout() performDraw() 了。
四 总结
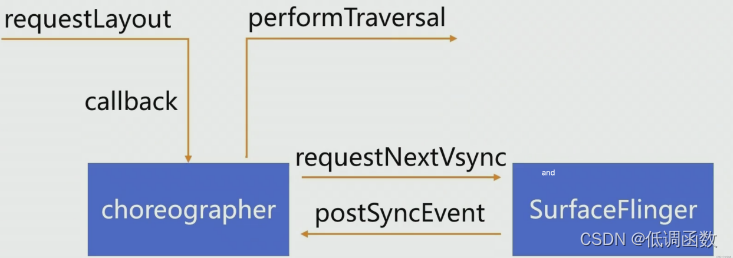
view调用了 requestLayout() 其实是在 choreographer 中添加了一个 callback 到队列中,choreographer 像 SurfaceFlinger 请求下一个 vsync 信号,当信号来了 SurfaceFlinger 通过 post 发送通知给 choreographer ,choreographer 在获取消息队列中的消息,执行 run 调用 performTraversal() 。
scheduleVsyncLocked(); 就是通知 SurfaceFlinger
private void scheduleVsyncLocked() {
// private static native void nativeScheduleVsync(long receiverPtr);
mDisplayEventReceiver.scheduleVsync();
}
这个方法执行到的是 native 层的 DisplayEventReceiver 的 scheduleVsync() 函数。
如果大家想更深层的了解UI刷新机制,比如SurfaceFlinger是什么?可以到这边博客了解