基础
[pytorch中文文档] torch.nn - pytorch中文网 (ptorch.com)
numpy
- Deep Learning with PyTorch: A 60 Minute Blitz — PyTorch Tutorials 2.0.0+cu117 documentation
- Python Numpy Tutorial (with Jupyter and Colab)
Tensor基础(类似于numpy)
参考:Pytorch之Tensor大详解 - 知乎 (zhihu.com)
Tensor是PyTorch中重要的数据结构,可认为是一个高维数组。它可以是一个数(标量)、一维数组(向量)、二维数组(矩阵)以及更高维的数组。Tensor和Numpy的ndarrays类似,但Tensor可以使用GPU进行加速。Tensor的使用和Numpy及Matlab的接口十分相似,下面通过几个例子来看看Tensor的基本使用。
基本方法
# 构建 5x3 矩阵,只是分配了空间,未初始化
x = t.Tensor(5, 3)
x = t.Tensor([[1,2],[3,4]])
x
# 使用 [0,1]均匀分布随机初始化二维数组
x = t.rand(5, 3)
x
print(x.size()) # 查看x的形状
x.size()[1], x.size(1) # 查看列的个数, 两种写法等价
# 加法的第二种写法
t.add(x, y)
# 加法的第三种写法:指定加法结果的输出目标为result
result = t.Tensor(5, 3) # 预先分配空间
t.add(x, y, out=result) # 输入到result
result
@ 注意,函数名后面带下划线**_** 的函数会修改Tensor本身。例如,x.add_(y)和x.t_()会改变 x,但x.add(y)和x.t()返回一个新的Tensor, 而x不变。
# Tensor的选取操作与Numpy
类似x[:, 1]这是一种选取操作,表示从Tensor x中选择所有行的第二列数据。类似于Numpy中的语法,可以对Tensor进行切片、选取等操作(与numpy类似)。其中“:”表示所有行,“1”表示第二列。
Tensor加速
- Tensor可通过`.cuda` 方法转为GPU的Tensor,从而享受GPU带来的加速运算。
# 在不支持CUDA的机器下,下一步还是在CPU上运行
device = t.device("cuda:0" if t.cuda.is_available() else "cpu")
x = x.to(device)
y = y.to(x.device)
z = x+y
- 此外,还可以使用
tensor.cuda()的方式将tensor拷贝到gpu上,但是这种方式不太推荐。
此处可能发现GPU运算的速度并未提升太多,这是因为x和y太小且运算也较为简单,而且将数据从内存转移到显存还需要花费额外的开销。GPU的优势需在大规模数据和复杂运算下才能体现出来。前面有介绍gpu的如何选择
autograd: 自动微分
深度学习的算法本质上是通过反向传播求导数,而PyTorch的**`autograd`**模块则实现了此功能。在Tensor上的所有操作,autograd都能为它们自动提供微分,避免了手动计算导数的复杂过程。
反向传播(Backpropagation)是一种用于计算神经网络中 各层权重梯度的方法,因此它是 求导数的一种方式。
具体来说,在反向传播过程中,先通过前向传播计算出网络输出值与标签之间的误差,并在每层记录下这个误差对相应权重和偏置的导数值。然后,在反向传播过程中,从输出层开始,将误差进行反向传播,并利用链式法则依次计算每一层上的梯度,直至计算到输入层得到所有参数的梯度。
总之,反向传播的本质就是基于 梯度下降优化算法,在神经网络中计算每个参数对于损失函数的梯度,通过优化求解最优参数以达到损失最小的目的。
自动微分(Automatic Differentiation, AD)是一种计算偏导数或梯度的数值方法。
在常规的数值计算中,我们用数值逼近的方式求解函数的微分。自动微分采用的是一种类似于微分脚本的方式,通过向前模式和向后模式,将复合函数拆解出基本运算操作,并计算其相应导数,从而极大地简化了求解函数微分的过程。可以说自动微分就是一种高效、自动化的求解导数或梯度的方法,它将一个复合函数分成多个小部分,然后对每个小部分利用链式法则进行导数的计算。
自动微分与传统数值微分和符号微分的不同之处在于,它可以准确地计算有理函数的导数和任何一组输入参数的梯度。此外,自动微分也被应用广泛在深度学习等领域中,深度学习中的反向传播算法就是通过自动微分等计算手段实现对神经网络各层间参数的梯度求解。
~~`autograd.Variable`是Autograd中的核心类,它简单封装了Tensor,并支持几乎所有Tensor有的操作。Tensor在被封装为Variable之后,可以调用它的`.backward`实现反向传播,自动计算所有梯度~~~~Variable的数据结构如图2-6所示。~~

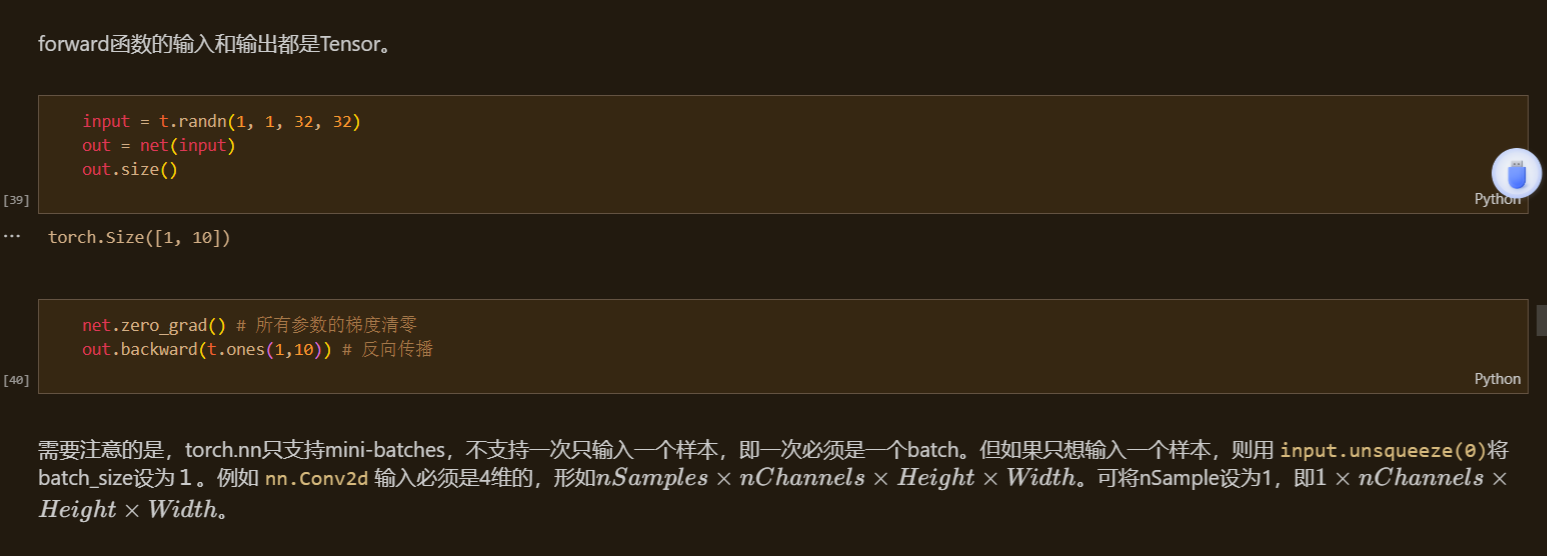
注意:`grad`在反向传播过程中是累加的(accumulated),这意味着每一次运行反向传播,梯度都会累加之前的梯度,所以反向传播之前需把梯度清零。
神经网络
Autograd实现了反向传播功能,但是直接用来写深度学习的代码在很多情况下还是稍显复杂,torch.nn是专门为神经网络设计的模块化接口。nn构建于 Autograd之上,可用来定义和运行神经网络。nn.Module是nn中最重要的类,可把它看成是一个网络的封装,包含网络各层定义以及forward方法,调用forward(input)方法,可返回前向传播的结果。下面就以最早的卷积神经网络:LeNet为例,来看看如何用`nn.Module`实现。LeNet的网络结构如图2-7所示

torch.nn
torch.nn是PyTorch中用于组建神经网络的包。它包含了许多预先定义好的层和函数,可以方便地构建各种类型的神经网络。
常见的层和函数有:
- 激活函数:ReLU、Sigmoid、Tanh等
- 池化函数:MaxPool、AvgPool等
- 卷积函数:Conv1d、Conv2d等
- 线性变换函数:Linear
- 循环神经网络函数:LSTM、GRU等
除了这些预定义的层和函数外,torch.nn还提供了Module类,该类作为一个基类,允许用户自定义自己的层和模型,并重写forward()函数实现前向传播过程。
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
# nn.Module子类的函数必须在构造函数中执行父类的构造函数
# 下式等价于nn.Module.__init__(self)
super(Net, self).__init__()
# 卷积层 '1'表示输入图片为单通道, '6'表示输出通道数,'5'表示卷积核为5*5
self.conv1 = nn.Conv2d(1, 6, 5)
# 卷积层
self.conv2 = nn.Conv2d(6, 16, 5)
# 仿射层/全连接层,y = Wx + b
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 卷积 -> 激活 -> 池化
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
# reshape,‘-1’表示自适应
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
print(net)只要在nn.Module的子类中定义了forward函数,backward函数就会自动被实现(利用`autograd`)。在`forward` 函数中可使用任何tensor支持的函数,还可以使用if、for循环、print、log等Python语法,写法和标准的Python写法一致。
网络的可学习参数通过`net.parameters()`返回,`net.named_parameters`可同时返回可学习的参数及名称。