博主简介:博主是一个大二学生,主攻人工智能领域研究。感谢缘分让我们在CSDN相遇,博主致力于在这里分享关于人工智能,C++,python,爬虫等方面的知识分享。如果有需要的小伙伴,可以关注博主,博主会继续更新的,如果有错误之处,大家可以指正。
专栏简介:本专栏致力于研究python爬虫的实战,涉及了所有的爬虫基础知识,以及爬虫在人工智能方面的应用。文章增加了JavaScript逆向,网站加密和混淆技术,AST还原混淆代码,WebAssembly,APP自动化爬取,Android逆向等相关技术。同时,为了迎合云原生发展,同时也增加了基于Kubernetes,Docker,Prometheus,Grafana等云原生技术的爬虫管理和运维解决方案。
博主分享:给大家分享一句我很喜欢的话:“每天多一点努力,不为别的,值为日后,能够多一些选择,选择舒心的日子,选择自己喜欢的人!”


爬虫基础
在写爬虫之前,我们需要先了解一些基础知识,如HTTP原理,网页的基础知识,爬虫的基本原理,Cookie的基本原理,多进程和多线程的基本原理等,了解这些有助于帮助我们更好的理解和编写网络爬虫相关的程序。
HTTP基本原理
URI和URL
URI的全称为(Uniform Resourse Identifier),即统一资源标志符;URL的全称是(Uniform Resourse Locator),即统一资源定位符。简而言之,就是我们在访问一个网站的时候,点开网站的链接,这个链接就是URL或URI。

根据图中所展示的URI和URL的关系,URL是URI的子集,这其中还包括了一个URN,URN全称 (Uniform Resourse Name),根据名字我们就可以知道,这只是一个资源命名,他不为资源做任何定位处理,你可以理解为一本书的编号,可以唯一标识这本书,但是却不能告诉我们怎么去买到它。在目前的互联网中,URN用的很少,几乎所有都是URI和URL,所以对于一般的网页链接,我们都可以称之为URI或URL,一般称为URL(博主习惯)。但是URL也有他的格式:
其中括号所代表的是非必要部分(https:baidu.com)。这里就简单的解释必要的部分的含义:
(1).schame:协议,一般是https,除了这个,其他常用的协议由http,ftp等,另外审查么也被称为protocol,二者都是代表协议的意思。
(2).hostname:主机地址,可以是域名或IP地址,
(3).parameters:参数,用来指定访问某个资源时的附加信息,但是现在用的很少,所以很多人都将parameters和query混用。
HTTP和HTTPS
爬虫中爬取的网页一般都是基于http或https协议的,因此我们的所有示例均是以以http或https协议为基础的网页链接。
HTTP的全称是Hypertext Transfer Protocol,中文名为超文本传输协议,其作用是把超文本数据从网络传输到本地浏览器,能够保证高效而准确的传输超文本文档。HTTP是由万维网协会(Word Wide Web Consortium)和Internet工作小组IEFT(Internet Engineering Task Force)合作制定的规范。
HTTPS的全称是Hypertext Transfer Protocol Secure Socket Layer,是以安全为目标的HTTP通道,简单来讲就是HTTP的安全版,即在HTTP下加入SSL层,简称HTTPS。
注:HTTP和HTTPS协议都属于计算机网络中的应用层协议,其下层是基于TCP协议实现的,TCP协议属于计算机网络中的传输层协议。本专栏的目的是为了讲解爬虫知识,因此这里就不对TCP,IP等类容进行深入讲解,如果感兴趣的话,博主推荐两本书《计算机网络》和《图解HTTP》。
HTTP请求过程
在浏览器地址栏中输入一个URL,按下回车,便可观察到对应的页面信息。实际上,这个过程是浏览器先向网站所在的服务为器发送一个请求,网站服务器接收到请求后对其进行处理和解析,然后返回对应的相应,接着传回浏览器。浏览器再对传回的响应包中的页面源代码进行解析。

为了更直观的说明上述情况,这里用Chorme浏览器开发者模式下的NetWork监听组件来做一下演示。
打开chorme浏览器,访问百度,这时候单击鼠标右键并选择“检查”(或者按F12)。如图:
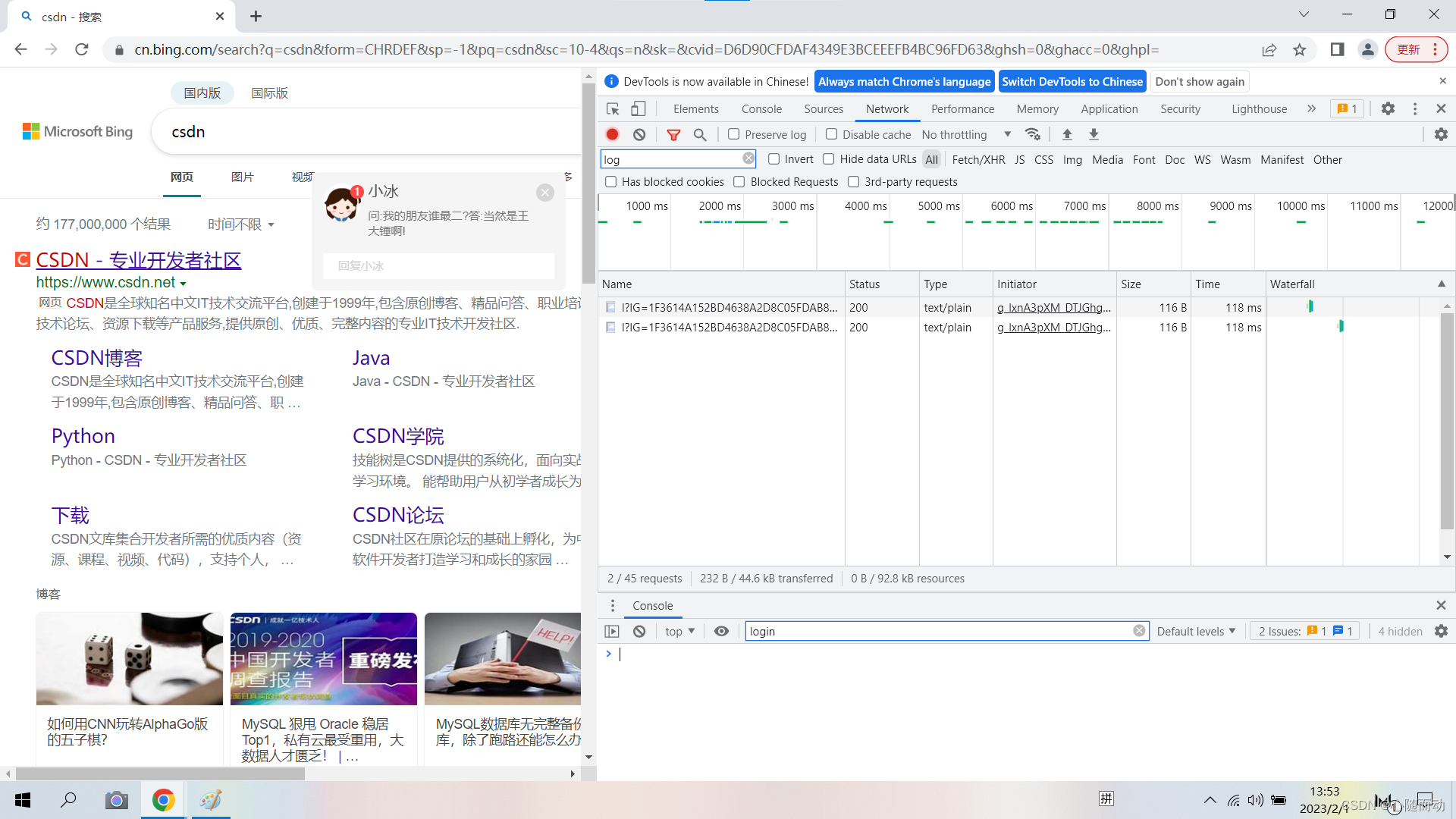
右边的显示就是Network组件,我们没刷新一次,就会看到Network中多几个条目,其中一个条目就代表一次发送请求和接收响应的过程。
现在,我们来分析一下各列的意义:
(1)第一列Name:请求的名称,一般会用URL的最后一部分类容作为名称。
(2)第二列Status:响应的状态码。这里显示200,代表响应正常。通过状态码,我们就可以判断发送请求之后是否得到了正常的响应。
(3)第三列Protocol:请求的协议类型。h1代表HTTP1.1版本,h2表示HTTP2版本。
(4)第四列Type:请求的文档类型,这里显示的是text,表示是text类型,document则代表HTML文档。
(5)第五列Initiator:请球源。用来标记请求是由哪个对象或进程发起的。
(6)第六列Size:从服务器下载的文件或请求的资源大小。如果资源是从缓存中取得的,则该列显示from cache。
(7)第七列Time:从发起到获取响应所花费的时间。
(8)第八列Waterfall:网络请求的可视化瀑布流。
上面展示的图示和解释有所差别,这是因为博主只是点开了一个搜索网页,大家点开了子网页,就会出现完整的Network组件监听:
单击条目,就可以获得具体信息:
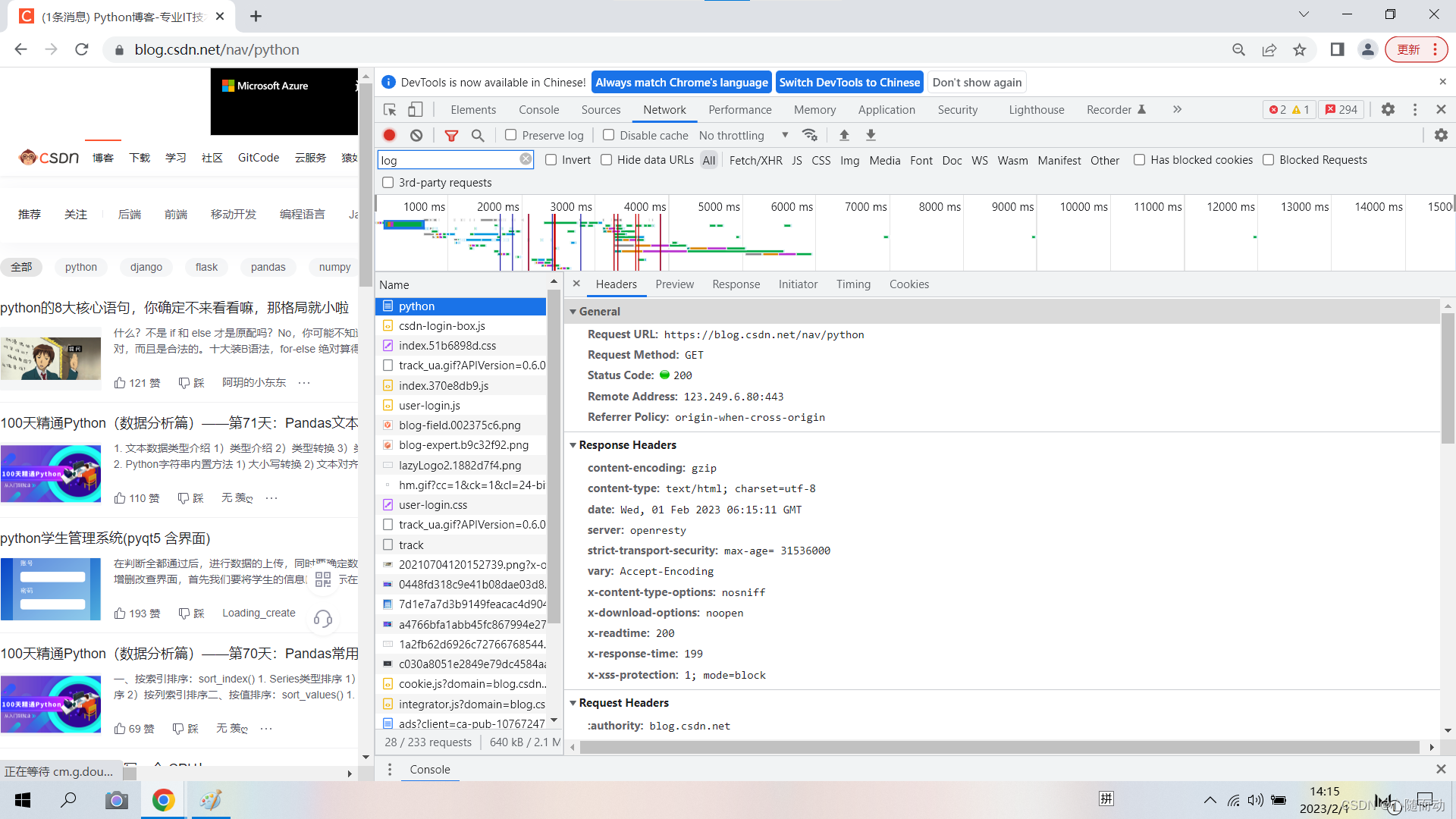
我们后续的文章中在进行爬虫的时候,就会根据这其中的信息进行操作。
首先General部分,其中Requests URL为请求的URL,Requests Method为请求的方法,Status Code为响应状态码,Remote Address 为远程服务器的地址和端口,Refer热热 Policy为Referrer判别策略。
请求
请求,英文为Request,由客户端发往服务器,分为四部分内容:请求方法(Request Method),请求的网址(Request URL),请求头(Request Headers),请求体(Request Body)。
⚪请求方法:
在浏览器中输入一个网址URL,点击回车,这个时候一般是发送GET请求,请求的参数会包含到URL中。POST请求一般则是在提交表单的时候,例如,你在登陆的时候,填好密码,用户名,点击登陆的时候,这时候就是POST请求。
二者的区别:
①GET请求的参数包含在URL中,数据可以在URL中看到,POST请求的URL中则不会包含这些数据,数据都是以表单形式传输,会包含在请求体中。
②GET请求提交的数据最多为1024字节,而POST则没有限制。
当然,除了这些的请求方式,还有其他的请求方式,例如HEAD,PUT,DELETE,CONNECT,OPTIONS,TRACE等。
| 方法 | 描述 |
|---|---|
| GET | 请求页面,并返回页面内容 |
| POST | 大多数用于提交表格或上传文件,数据包含在请求体中 |
| PUT | 用客户端传向服务器的数据取代指定文档中的内容 |
| DELETE | 请求服务器删除指定的页面 |
| CONNECT |
把服务器当作跳板,让服务器当作客户端访问其他页面 |
| OPTIONS | 允许客户端查看服务器的性能 |
| TRACE | 回显服务器收到的请求,主要用于测试和诊断 |
| HEAD | 和GET请求相似,但是返回的响应没有具体的内容,用于获取报头 |
请求的网址
①请求头
用来说明服务器要使用的附加信息。
(1)Accept:请求报头域,用于指定客户端可以就收哪些类型的信息。
(2)Accept-Language:用于指定客户端可以接受的语言类型。
(3)Accept-Encoding:用于指定客户端可以使用的编码类型
(4)Host:用于指定请求的客户端的IP和端口号,其内容为请求URL的原始服务器或网关的位置。
(5)Cookie:也常用复数形式Cookies,这是网站为了辨别用户,进行会话跟踪而存储在用户本地的数据。
(6)referer:用于标识请求是从哪个页面发来的,服务器可以根据这一信息并作出相应的处理,如做来源统计,防盗链处理等。
(7)User-Agent:简称UA,这是一个特殊的字符串头,可以使服务器识别客户端使用的操作系统及版本,浏览器版本等信息。做爬虫时可以加上此信息,可以伪装成浏览器,如果不加,很容易被识别出来。
(8)Content-Type:也叫互联网媒体类型(Internet Media Type)或者MIME类型,在HTTP协议消息头中,它用来表示具体请求中的媒体类型信息。例如,text/html代表html格式,image/gif代表GIF图片,application代表JSON类型。
②请求体
请求体一般承载的内容为POST请求中的表单数据,对于GET请求,为空。
响应
响应,即Response,由服务器返回给客户端,可以分为三部分:响应状态码(Response Status Code),响应头(Response Headers)和响应体(Response Body)。
响应状态码表示服务器响应的状态,200表示正常,404表示页面没有找到,500代表服务器内部发生错误。
①响应头
响应头,包含了服务器对请求的应答信息,如Content-Type,Server,Set-Cookie等。这里就不过多介绍了。
②响应体
响应体是最为重要的,响应的所有正文数据都存在响应体中,例如,请求网页时,响应体就是HTML代码。

Web网页基础
我们用浏览器访问不同的页面的时候,所呈现的页面都有所不同,你有没有想过为什么会这样?本节我们就了解一下网页的组成,结构和节点等内容。由于博主不是主攻前端,所以这里只能简单的介绍。
网页的组成
网页可以分为三大部分——HTML,CSS,javaScript。如果把网页比作一个人,那么HTML就相当于骨架,CSS为皮肤,JavaScript相当于肌肉。这三者结合起来就能杏形成网页。‘
HTML
HTML(Hypertext Markup Language)中文翻译为超文本标记语言。但是一般称为HTML。
HTML是一种用来描述网页的语言。网页包括图片,文字,视频,按钮等复杂元素。网页通过不同类型的标签来表示不同类型的元素,如用img标签表示图片,用video表示视频,用p标签表示段落,这些标签之间的布局常由布局标签div嵌套组合而成。各种标签通过不同的排列和嵌套形成最终的网页框架。

打开浏览器开发者工具,点击Elements,这里显示就是HTML代码。
CSS
HTML定义了网页的骨架,但是只有HTML的页面布局并不完美,为了让网页看起来好看,就可以用CSS。
CSS,全称为Cascading Style Sheets,即层叠样式表。“层叠”是指当HTML中引用多个样式文件,并且样式发生重叠的时候,浏览器能够按照层叠顺序来处理这些样式。“样式”是指网页中文字大小,颜色,排列,间距等格式。CSS是目前唯一的网页页面排版样式标准。
style中的就是CSS样式。
JavaScript
javaScript简称js,是一种脚本语言,HTML和CSS组合使用,提供给用户的只是一种静态信息,缺乏交互性。我们在网页中还可以看到交互和动画效果,例如进度条,提示框,轮播图等。这就是JavaScript的功能。
JavaScript一般也是以单独的文件来运行加载,后缀为.js,在HTML中通过script标签即可引入:
<script src='jquery-2.1.0.js></script>
这里的标签格式要记住,后面的爬虫会用到。
网页的具体知识这里就不做介绍,感兴趣的小伙伴可以去搜索相关知识。
爬虫的基本原理
我们把互联网比作一个大的蜘蛛网,那么爬虫就是蜘蛛网上的蜘蛛,没爬寻一个节点,就相当于访问了一个页面,获取了信息。顺着节点连线连续爬行,到达下一个节点,意味着爬虫可以通过网页之间的链接关系继续获取后续的网页,当整个网页涉及的页面被爬取下来,数据也就保存下来了。
简单来讲,爬虫就是获取网页并提取和保存信息的自动化程序。
1.获取网页
2.提取信息
3.保存数据
4.自动化程序
代理的基本概念
由于爬虫的访问频率很快,现在的服务器都会由反爬虫机制,一旦你访问频率过快,就会被锁IP,也会发生报错。于是,python推出了IP代理。
基本原理
代理实质就是代理服务器。我们不是用IP代理爬虫的时候,我们会向服务器发送请求,服务器返回响应。设置服务器代理,就相当于在客户端和服务器之间搭一座桥,此时,我们发送请求的时候先向伪代理器发送请求,伪代理器再将请求发送到网页服务器,同理,返回的响应也要经过伪代理器。而这个过程中,Web服务器识别的IP不再是客户端的IP,成功实现了IP伪装,这就是代理的基本原理。
爬虫代理
如果我们平凡的去访问一个网页,那么此网站就会让我们输入验证码或者锁IP,爬虫就不能继续正常运行,所以,我们就需要用代理隐藏真实的IP,这就叫做爬虫代理,也叫IP代理,我习惯叫做IP代理。
代理分类
对代理进行分类时,可以根据协议,也可以根据代理的匿名程度。
①根据协议区分
1.FTP代理服务器:主要用于访问FTP服务器,一般有上传,下载,以及缓存功能。端口一般为21,2121等。
2.HTTP代理服务:主要用于访问网页,一般有内容过滤和缓存功能,端口一般为80,8080,3128等。
3.SSL/TLS代理:主要用于访问加密网站,一般有SSL或TLS加密功能(最高支持128位加密强度),端口一般为443.
4.RTSP代理:主要用于Realplayer访问Real流媒体服务器,一般有缓存功能,端口一般为554.
5.Telnet代理:主要用于Telnet远程控制(黑客入倾计算机时常用于身份隐藏),端口一般为23.
6.POP3/SMTP代理:主要用于以POP3/SMTP方式收发邮件,一般有缓存功能,端口为110/25.
7.SOCKS代理:只是单纯的传递数据包,不关心具体协议和用法,所以速度很快,一般有缓存功能能,端口一般为1080.SOCKS代理协议又分为SOCKS4和SOCKS5,SOCKS4协议只支持TCP,SOCLKS5则支持TCP和UDP,还支持各种身份验证机制,服务器端域名解析等。简单来说,SOCKS4能做到的SOCKS5能做到,SOCKS5能做到的SOCKS4不能做到。
②.根据匿名程度分
1.高度匿名代理:高度匿名代理会将数据包原封不动的转发,在服务端看来似乎真的是一个普通的客户端在访问,记录的IP则是代理服务器的IP。
2.普通匿名代理:普通匿名代理会对数据包进行一些改动,服务端可能会发现正在访问自己的是一个代理IP,并且有一定的概率去追查客户端真实的IP。这里的代理服务器通常会加入的HTTP头HTTP_VIA和HTTP_X_FORWARDED_FOR.
3.透明代理:透明代理不但改动了数据包,还告诉了服务器客户端真实的IP,这种技术可以提高浏览速度,和用内容过滤提高安全性,其他的没啥用处。
4.间谍代理:间谍代理是组织或个人创建的代理服务器,用于记录用户传输的数据,然后对记录的数据进行研究,监控等。
爬虫中还涉及了多线程和多进程的知识,他们我已经在前面的文章中介绍过了,这里就不过多解释了,后面实际操作中会进行介绍。
总结
本篇文章作为本专栏的第一篇文章,目的是了解一下爬虫的相关知识,为后面的爬虫学习打好基础。由于博主对前端知识不是很了解,文章中涉及的网页知识不够深入,如果有错误,敬请各位小伙伴指出。
开学了,预祝各位同学学习进步,生活安康,万事如意!
