hfai心法
章节肆 / hfai datasets

数据如兵,操纵随心
幻方 AI 在不久前发布了沉淀多年的深度学习套件 hfai ,集成了幻方对集群性能及易用性提升进行的大量开发。整个套件的功能较多,而熟悉掌握了这套规则,就能够轻松地调用起平台的算力资源,高效完成训练任务。
为此,我们专门创建了 “hfai 使用心法”系列专辑,分集陆续为大家介绍 hfai 一些功能的设计思路和原理,帮助大家更好更快地习得心法,带着 hfai 这套“神功”游刃有余的应对深度学习作业的各项挑战,举重若轻、例不虚发。
前三个招式分别为大家介绍了 hfai workspace、 hfai venv和 hfai python, 其可以帮助用户快速同步本地工程目录代码和环境到远程萤火超算中并进行任务的执行。一切准备就绪,就差训练数据了。对于大规模的训练数据,上传、管理和部署都是不小的挑战,幻方 AI 研发提供了一套专门为数据集量身定制的“神功”,帮助大家更好的运行大规模的数据,训练出惊艳的模型。
Studio数据管理页
在萤火集群上的训练数据集,我们都可以通过 Studio 数据管理页 进行浏览与使用。如下图所示:

可以看到,幻方 AI 收纳整理了数十种常用的大规模公开数据集,并持续更新中。如果您所需要的数据集在其中,通过 hfai.datasets 方法就可以轻松获取高性能存储支持下的训练数据,进行快速训练。
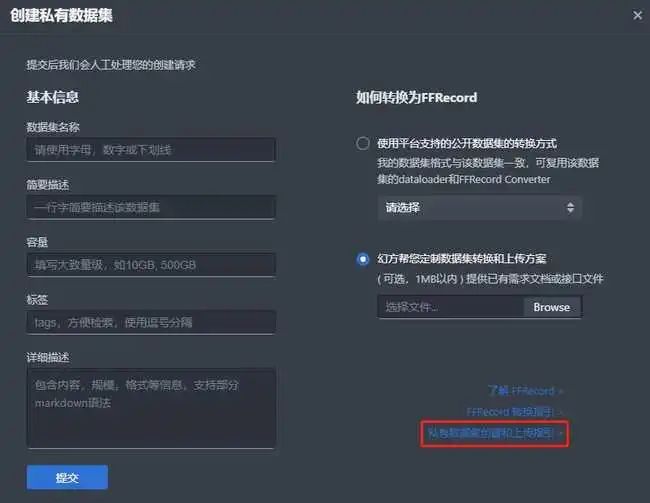
当然,这些数据不可能满足所有的研究场景。如果您需要上传您自己的数据,可以点击 创建私有数据集。

私有数据集
私有数据集在幻方萤火集群中进行账号级的隔离,您的数据只有您的账号下可以进行访问。
上传的数据需要满足如下条件:
每个文件不小于 256MB (512 x 512KB)
满足前述条件的情况下,文件数量尽可能大于100,小于200
这里需要特别注意的是,大量的小文件构成的数据集会对集群存储性能造成严重影响,因此,如果您的数据是这种大量的小文件,我们建议您将数据转化为幻方 AI 自研的 ffrecord 数据格式。
为什么要转换为 ffrecord ?
幻方 AI 自研了一套适合深度学习模型训练场景的文件读写系统 3FS,和一般的文件系统不同,3FS 文件系统有如下的一些特点:
-
大量打开、关闭小文件的开销比较大
-
支持高吞吐的随机批量读取
ffrecord 能够充分利用 3FS 文件系统的高效读取性能,其包括如下优势:
-
合并多个小文件,减少了训练时打开大量小文件的开销,对存储后端更加友好
-
支持随机批量读取,提升读取速度
-
包含数据校验,保证读取的数据完整可靠
因此,我们建议用户将训练数据尽可能都转换成 ffrecord 格式,以利用萤火集群的高性能存储,获得极致的训练加速体验。转换指引和案例代码可以阅读这里。
数据上传
| 用户上传数据的完整流程如下: |
|
| 1 |
在 Studio 中点击 【创建私有数据集】,填写数据信息; |
| 2 |
幻方管理员沟通,审核数据内容; |
| 3 |
审核通过,点击 【更新授权】 获取上传 token; |
| 4 |
使用阿里云OSS工具,通过授权 token,将符合条件的数据上传; |
| 5 |
幻方管理员审核,数据流转到萤火集群; |
| 6 |
数据准备完成后,用户可以在 Studio 中获得数据在集群中的地址。 |
更详细的操作请阅读 Studio 中的私有数据集创建指引。
由上述过程描述中可以了解到,用户数据到萤火集群采用如下方式流转:
用户端 —> 阿里云对象存储 —> 萤火集群
幻方 AI 采用特定的阿里云对象存储(OSS)进行用户数据上传的中转,其上传速度取决于用户自己的网络环境。萤火集群和 OSS 之间有专线连接,保证数据的快速流转。
如果您的数据规模巨大,或网络条件有限,可以联系幻方管理员采用其他方式来上传。
本章结束
High-Flyer AI
我们希望让更多“想象力”和“创造力”生长。期待与各方科学家及开发者们一同共建AI时代。
点击下方链接 进一步了解