目录
项目介绍
- 当前项目是实现一个高并发的内存池,他的原型是google的一个开源项目tcmalloc,tcmalloc全称Thread-Caching Malloc,即线程缓存的malloc,实现了高效的多线程内存管理,用于替代系统的内存分配相关的函数(malloc、free)。
- 这个项目是把tcmalloc最核心的框架简化后拿出来,模拟实现出一个自己的高并发内存池,目的就是学习tcamlloc的精华,这个项目用到了C/C++、数据结构(链表、哈希桶)、操作系统内存管理、单例模式、多线程、互斥锁等等方面的知识,过程虽然很难但是收获和成长也是在这个过程中同步上升。
先了解内存池的一些概念
- 池化技术
所谓“池化技术”,就是程序先向系统申请过量的资源,然后自己管理,以备不时之需。之所以要申请过
量的资源,是因为每次申请该资源都有较大的开销,不如提前申请好了,这样使用时就会变得非常快
捷,大大提高程序运行效率。
在计算机中,有很多使用“池”这种技术的地方,除了内存池,还有连接池、线程池、对象池等。以服务
器上的线程池为例,它的主要思想是:先启动若干数量的线程,让它们处于睡眠状态,当接收到客户端
的请求时,唤醒池中某个睡眠的线程,让它来处理客户端的请求,当处理完这个请求,线程又进入睡眠
状态。 - 内存池
内存池是指程序预先从操作系统申请一块足够大内存,此后,当程序中需要申请内存的时候,不是直接
向操作系统申请,而是直接从内存池中获取;同理,当程序释放内存的时候,并不真正将内存返回给操
作系统,而是返回内存池。当程序退出(或者特定时间)时,内存池才将之前申请的内存真正释放。 - 内存池主要解决的问题
内存池主要解决的当然是效率的问题,其次如果作为系统的内存分配器的角度,还需要解决一下内存碎
片的问题。那么什么是内存碎片呢?
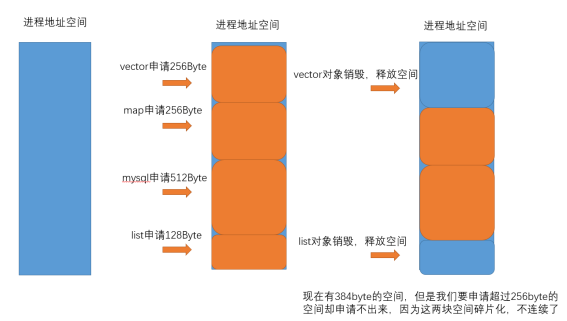
- 内存碎片分为外碎片和内碎片,上面图示讲的是外碎片问题。外部碎片是一些空闲的连续内存区域太小,这些内存空间不连续,以至于合计的内存足够,但是不能满足一些的内存分配申请需求。内部碎片是由于一些对齐的需求,导致分配出去的空间中一些内存无法被利用。比如结构体的内存对齐,有时就会产生内碎片 结构体对齐详解转链接
先设计一个简单的定长内存池
#pragma once
#include<stdlib.h>
#include<assert.h>
#include<time.h>
#include<iostream>
#include<vector>
#include<windows.h>
using std::cout;
using std::endl;
// 直接去堆上按页申请空间
inline static void* SystemAlloc(size_t kpage)
{
#ifdef _WIN32
void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else
// linux下brk mmap等
#endif
if (ptr == nullptr)
throw std::bad_alloc();
return ptr;
}
// 固定内存长度的内存块
template<class T>
class ObjectPool
{
public:
T* New()
{
T* obj = nullptr;
//优先把还回来内存块对象,再次重复利用
if (_freelist != nullptr)
{
// 头删
obj = (T*)_freelist;
_freelist = (*(void**)_freelist);
}
else
{
if (_remainBytes < sizeof(T))
{
// 每次需要申请的大块内存字节数
size_t SizeBytes = 1024 * 128;
//_memory = (char*)malloc(SizeBytes);
_memory = (char*)SystemAlloc(SizeBytes >> 13);
if (_memory == nullptr)
{
throw std::bad_alloc();
}
_remainBytes = SizeBytes;
}
obj = (T*)_memory;
// 注意: 当T类型小于4/8字节时的问题
size_t ObjSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);
_memory += ObjSize;
_remainBytes -= ObjSize;
}
// 定位new, 显示调用T的构造函数初始化
new(obj)T;
return obj;
}
void Delete(T* obj)
{
// 显示调用析构函数清理对象
obj->~T();
// 头插
(*(void**)obj) = _freelist;
_freelist = obj;
}
private:
char* _memory = nullptr; // 预先申请的一块大的内存
void* _freelist = nullptr; // 自由链表, 管理释放的内存快
size_t _remainBytes = 0;
};

高并发内存池整体框架设计
多核多线程,在申请内存的场景下,必然存在激烈的锁竞争问题。TCMalloc是用于优化C++写的多线程应用,比glibc 2.3的malloc快。这个模块可以用来让MySQL在高并发下内存占用更加稳定。
内存池需要考虑以下几方面的问题:
- 性能问题。
- 多线程环境下,锁竞争问题。
- 内存碎片问题
并发内存池主要由以下3个部分构成:
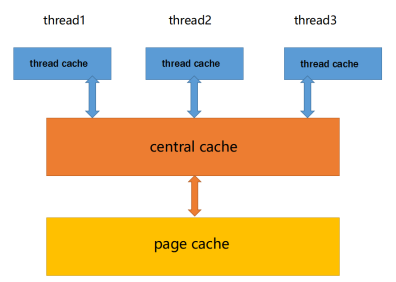
- thread cache:线程缓存是每个线程独有的,用于小于256KB的内存的分配,线程从这里申请内存不需要加锁,每个线程独享一个cache,这也就是这个并发线程池高效的地方。
- central cache:中心缓存是所有线程所共享,thread cache是按需从central cache中获取的对象。central cache合适的时机回收thread cache中的对象,避免一个线程占用了太多的内存,而其他线程的内存吃紧,达到内存分配在多个线程中更均衡的按需调度的目的。central cache是存在竞争的,所以从这里取内存对象是需要加锁,首先这里用的是桶锁,其次只有thread cache的没有内存对象时才会找central cache,所以这里竞争不会很激烈。
- page cache:页缓存是在central cache缓存上面的一层缓存,存储的内存是以页为单位存储及分配的,central cache没有内存对象时,从page cache分配出一定数量的page,并切割成定长大小的小块内存,分配给central cache。当一个span的几个跨度页的对象都回收以后,page cache会回收central cache满足条件的span对象,并且合并相邻的页,组成更大的页,缓解内存碎片的问题。
thread cache
thread cache是哈希桶结构,每个桶是一个按桶位置映射大小的内存块对象的自由链表。每个线程都会
有一个thread cache对象,这样每个线程在这里获取对象和释放对象时是无锁的。
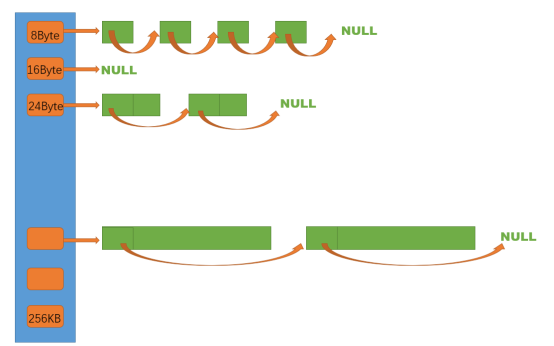
申请内存:
- 当内存申请size<=256KB,先获取到线程本地存储的thread cache对象,计算size映射的哈希桶自由链表下标i。
- 如果自由链表_freeLists[i]中有对象,则直接Pop一个内存对象返回。
- 如果_freeLists[i]中没有对象时,则批量从central cache中获取一定数量的对象,插入到自由链表并返回一个对象。
释放内存: - 当释放内存小于256k时将内存释放回thread cache,计算size映射自由链表桶位置i,将对象Push
到_freeLists[i]。 - 当链表的长度过长,则回收一部分内存对象到central cache

细节:
thread cache代码框架:
class ThreadCache
{
public:
// 申请和释放内存对象
void* Allocate(size_t bytes);
void Deallocate(void* ptr, size_t size);
// 从中心缓存获取对象
void* FetchFromCentralCache(size_t index, size_t size);
private:
// 哈希桶,存放自由链表
FreeList _freeLists[NFREELIST];
};
// TLS thread local storage (线程局部存储)
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;
如何使用TLS:
每一个线程都会调用SameAlloc函数来创建ThreadCache对象,并调用Allocate来申请空间
static void* SameAlloc(size_t size)
{
// 通过TLS 每个线程无锁的获取自己的专属的ThreadCache对象
if (pTLSThreadCache == nullptr)
{
pTLSThreadCache = new ThreadCache;
}
return pTLSThreadCache->Allocate(size);
}
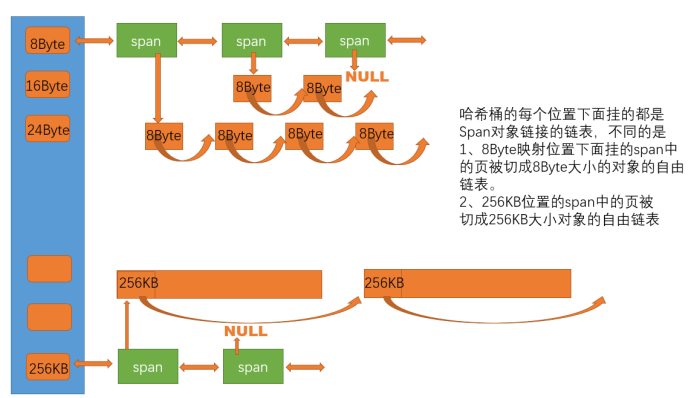
central cache
central cache也是一个哈希桶结构,他的哈希桶的映射关系跟thread cache是一样的。不同的是他的每个哈希桶位置挂是SpanList链表结构,不过每个映射桶下面的span中的大内存块被按映射关系切成了一个个小内存块对象挂在span的自由链表中。
// 单例模式
class CentralCache
{
public:
static CentralCache* GetInstance()
{
return &_sInst;
}
// 获取一个非空的span
Span* GetOneSpan(SpanList& list, size_t byte_size);
// 从中心缓存获取一定数量的对象给thread cache
size_t FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size);
// 将一定数量的对象释放到span跨度
void ReleaseListToSpans(void* start, size_t byte_size);
private:
SpanList _spanLists[NFREELIST];
private:
CentralCache()
{
}
CentralCache(const CentralCache&) = delete;
static CentralCache _sInst;
};
申请内存:
- 当thread cache中没有内存时,就会批量向central cache申请一些内存对象,这里的批量获取对象的数量使用了类似网络tcp协议拥塞控制的慢开始算法;central cache也有一个哈希映射的spanlist,spanlist中挂着span,从span中取出对象给thread cache,这个过程是需要加锁的,不过这里使用的是一个桶锁,尽可能提高效率。
- central cache映射的spanlist中所有span的都没有内存以后,则需要向page cache申请一个新的span对象,拿到span以后将span管理的内存按大小切好作为自由链表链接到一起。然后从span中取对象给thread cache。
- central cache的中挂的span中use_count记录分配了多少个对象出去,分配一个对象给threadcache,就++use_count
释放内存:

- 当thread_cache过长或者线程销毁,则会将内存释放回central cache中的,释放回来时–use_count。当use_count减到0时则表示所有对象都回到了span,则将span释放回page cache,page cache中会对前后相邻的空闲页进行合并。

page cache
class PageCache
{
public:
static PageCache* GetInstance()
{
return &_sInst;
}
// 获取从对象到span的映射
Span* MapObjectToSpan(void* obj);
// 释放空闲span回到Pagecache,并合并相邻的span
void ReleaseSpanToPageCache(Span* span);
// 获取一个K页的span
Span* NewSpan(size_t k);
std::mutex _pageMtx;
private:
SpanList _spanLists[NPAGES];
ObjectPool<Span> _spanPool;
//std::unordered_map<PAGE_ID, Span*> _idSpanMap;
std::map<PAGE_ID, Span*> _idSpanMap;
PageCache()
{
}
PageCache(const PageCache&) = delete;
static PageCache _sInst;
};
申请内存:
- 当central cache向page cache申请内存时,page cache先检查对应位置有没有span,如果没有则向更大页寻找一个span,如果找到则分裂成两个。比如:申请的是4页page,4页page后面没有挂span,则向后面寻找更大的span,假设在10页page位置找到一个span,则将10页pagespan分裂为一个4页page span和一个6页page span。
- 如果找到_spanList[128]都没有合适的span,则向系统使用mmap、brk或者是VirtualAlloc等方式申请128页page span挂在自由链表中,再重复1中的过程。
- 需要注意的是central cache和page cache 的核心结构都是spanlist的哈希桶,但是他们是有本质区别的,central cache中哈希桶,是按跟thread cache一样的大小对齐关系映射的,他的spanlist中挂的span中的内存都被按映射关系切好链接成小块内存的自由链表。而page cache 中的spanlist则是按下标桶号映射的,也就是说第i号桶中挂的span都是i页内存。
释放内存:
- 如果central cache释放回一个span,则依次寻找span的前后page id的没有在使用的空闲span,看是否可以合并,如果合并继续向前寻找。这样就可以将切小的内存合并收缩成大的span,减少内存碎片。

项目改进
完全脱离使用malloc
问题:
在内存池自身的数据结构的管理当中,比如spanlist中的Span结构还是使用new Span的操作完成,而new的底层就是malloc。
解决:
项目中增加一个定长的ObjectPool的对象池,对象池的内存直接使用brk,virtuallAlloc向系统内存申请,new Span替换成对象池申请内存。
free时不再传入对象大小
问题:
释放内存时只需要传入起始地址即可,但是自己的tcmalloc释放时会传入对象大小
解决:
通过起始地址在Map中找到对应的span, 通过span获取对象大小
当对象大于256KB时
申请:
将对象按照一页对齐,对齐后直接向PageCache申请,获取一个span,将内存块的起始地址返回
释放:
直接调用PageCache的释放函数(传入span即可,span可以通过起始地址转换为起始页,再通过map<id, Span*>即可)
平台及兼容性
问题:
windows和Linux下直接去堆上按页申请空间方式不一样
解决:
条件编译
// 直接去堆上按页申请空间
inline static void* SystemAlloc(size_t kpage)
{
#ifdef _WIN32
void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else
// linux下brk mmap等
#endif
if (ptr == nullptr)
throw std::bad_alloc();
return ptr;
}
inline static void SystemFree(void* ptr)
{
#ifdef _WIN32
VirtualFree(ptr, 0, MEM_RELEASE);
#else
// sbrk unmmap等
#endif
}

#ifdef _WIN64
typedef unsigned long long PAGE_ID;
#elif _WIN32
typedef size_t PAGE_ID;
#else
// linux
#endif
替换系统的malloc和free
实际中我们测试了,当前实现的并发内存池比malloc/free是更加高效的,那么我们能否替换到系统调用malloc呢?实际上是可以的。
- 不同平台替换方式不同。 基于unix的系统上的glibc,使用了weak alias的方式替换。具体来说是因为这些入口函数都被定义成了weak symbols,再加上gcc支持 alias attribute,所以替换就变成了这种通用形式:
void* malloc(size_t size) THROW attribute__ ((alias (tc_malloc)))
因此所有malloc的调用都跳转到了tc_malloc的实现
具体参考这里:GCC attribute 之weak,alias属性
有些平台不支持这样的东西,需要使用hook的钩子技术来做。
关于hook请看这里:hook
使用基数提高效率

参考资料
C/C++中我们要动态申请内存都是通过malloc去申请内存,但是我们要知道,实际我们不是直接去堆获取内存的,而malloc就是一个内存池。malloc() 相当于向操作系统“批发”了一块较大的内存空间,然后“零售”给程序用。当全部“售完”或程序有大量的内存需求时,再根据实际需求向操作系统“进货”。malloc的实现方式有很多种,一般不同编译器平台用的都是不同的。比如windows的vs系列用的微软自己写的一套,linux gcc用的glibc中的ptmalloc。
一文了解,Linux内存管理,malloc、free 实现原理
malloc()背后的实现原理——内存池
malloc的底层实现(ptmalloc)
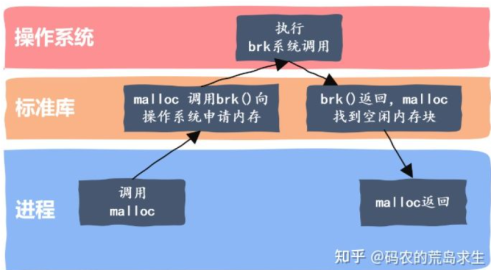
windows和Linux下如何直接向堆申请页为单位的大块内存:
VirtualAlloc
brk和mmap
TLS–thread local storage:
linux gcc下 tls
参考资料:
几个内存池库的对比
tcmalloc源码学习
TCMALLOC 源码阅读
如何设计内存池? - 码农的荒岛求生的回答 - 知乎
tcmalloc源代码