- 批量梯度下降(Batch Gradient Descent,BGD)
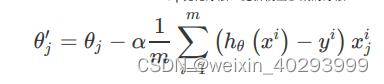
这个方法是当所有的数据都经过了计算之后再整体除以它,即把所有样本的误差做平均。这里我想提醒你,在实际的开发中,往往有百万甚至千万数量级的样本,那这个更新的量就很恐怖了。所以就需要另一个办法,随机梯度下降法。 - 随机梯度下降(Stochastic Gradient Descent,SGD)
随机梯度下降法的特点是,每计算一个样本之后就要更新一次参数,这样参数更新的频率
就变高了。
想想看,每训练一条数据就更新一条参数,会有什么好处呢?对,有的时候,我们只需要
训练集中的一部分数据,就可以实现接近于使用全部数据训练的效果,训练速度也大大提
升。
然而,鱼和熊掌不可兼得,SGD 虽然快,也会存在一些问题。就比如,训练数据中肯定会
存在一些错误样本或者噪声数据,那么在一次用到该数据的迭代中,优化的方向肯定不是
朝着最理想的方向前进的,也就会导致训练效果(比如准确率)的下降。最极端的情况
下,就会导致模型无法得到全局最优,而是陷入到局部最优。 - 小批量梯度下降(Mini-Batch Gradient Descent, MBGD)
Mini-batch 的方法是目前主流使用最多的一种方式,它每次使用一个固定数量的数据进行
优化。
这个固定数量,我们称它为 batch size。batch size 较为常见的数量一般是 2 的 n 次方,
比如 32、128、512 等,越小的 batch size 对应的更新速度就越快,反之则越慢,但是更
新速度慢就不容易陷入局部最优。
基于随机梯度下降法,人们又提出了包括 momentum、nesterov momentum 等方法,这部分知识同学们有兴趣点击这里可以自行查阅。
梯度下降的min-batch越大越好么? - batch_size越大显存占用会越多,可能会造成内存溢出问题,此外由于一次读取太多的
样本,可能会造成迭代速度慢的问题。 - batch_size较大容易使模型收敛在局部最优点
- 此外过大的batch_size的可能会导致模型泛化能力较差的问题
batch size太小的话,那么每个batch之间的差异就会很大,迭代的时候梯度震荡就会严重,不利
于收敛。
batch size越大,那么batch之间的差异越小,梯度震荡小,利于模型收敛。
但是凡事有个限度,如果batch size太大了,训练过程就会一直沿着一个方向走,从而陷入局部最
优。
【深度学习】常见的梯度下降的方法
猜你喜欢
转载自blog.csdn.net/weixin_40293999/article/details/129752133
今日推荐
周排行