提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
还是要多练习,用DCgan 生成人脸
数据集人脸库在这里:https://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
1. 原理和网络结构
原理将的人已经很多了,略过
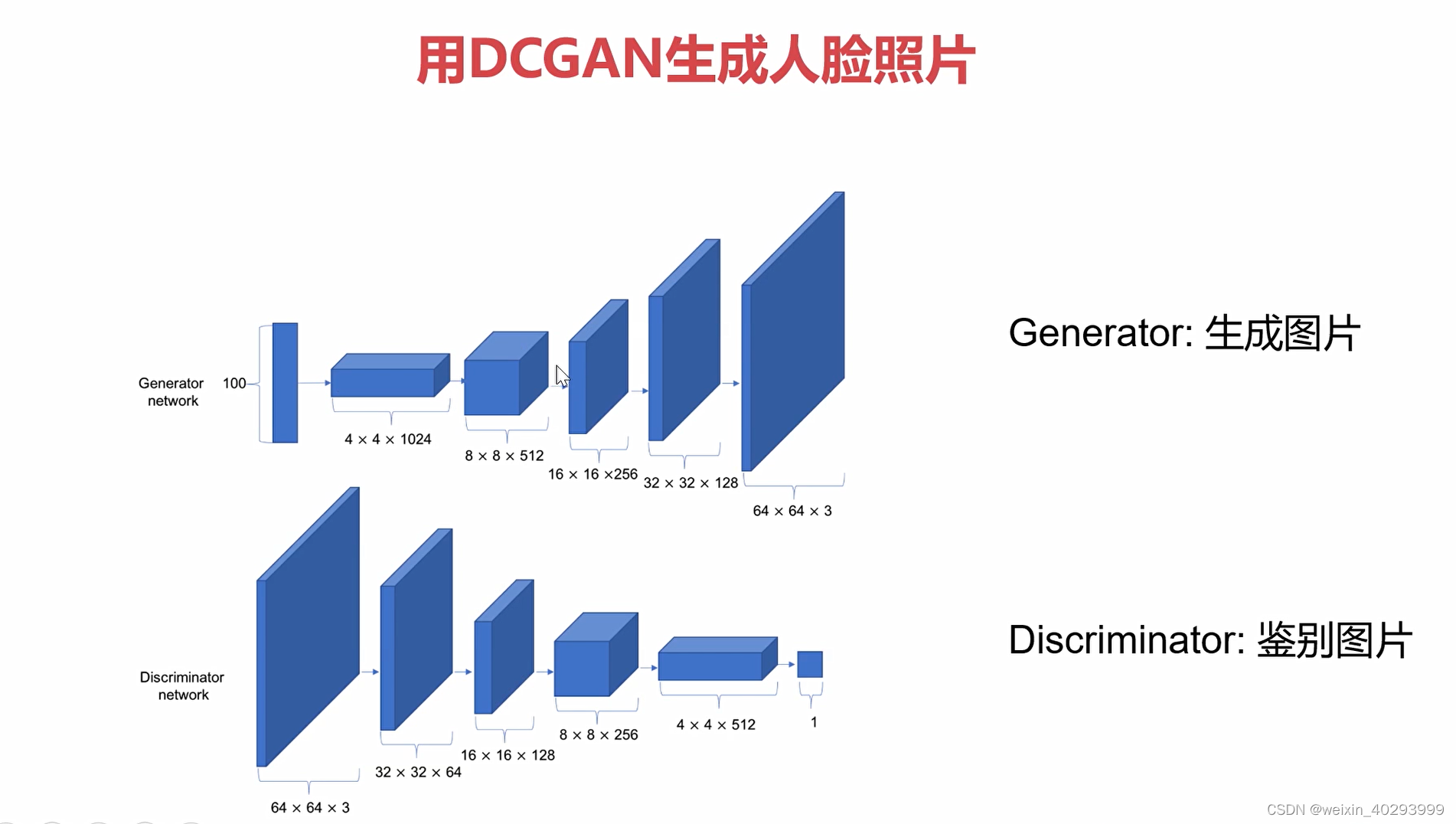
网络结构不负责,生成和鉴别两个网络是相反的。
生成:一个 linear 4个卷积
2.撸代码

一共6个文件,配置文件,数据文件,鉴别器,生成器,推理,训练
2.1 Conf
class Hyperparameters:
# data
device = "cuda"
data_root = r'D:\BaiduNetdiskDownload\CelebA\Img\img_align_celeba'
image_size = 64
seed = 1234
# model
z_dim = 100 # laten z dimension
data_channels = 3 #RGB face
# Exp
batch_size = 64
n_workers = 2
beta = 0.5
init_lr = 0.0002
epochs = 1000
verbose_step = 250 # evaluation: store image during training
save_step = 1000 # save model step
HP = Hyperparameters()
2.2 dataset_face
# only face images, no target / label
from config import HP
from torchvision import transforms
import torchvision.datasets as TD
from torch.utils.data import DataLoader
import os
from torchvision import transforms as T # torchaudio(speech) / torchtext(text)
# os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # openKMP cause unexpected error
# apply a label to corresponding
data_face = TD.ImageFolder(HP.data_root,transform=T.Compose(
[
T.Resize(HP.image_size), # 64X64X3
T.CenterCrop(HP.image_size), # Resize之后取中间是否有意义?? @todo
T.ToTensor(), # to [0,1]
T.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
# cannt apply ImageNet statistic
]
))
face_loader = DataLoader(data_face,batch_size=HP.batch_size,shuffle=True,num_workers=HP.n_workers)
# normalize: x_norm = (x - x_avg) / std de-normalize: x_denorm = (x_norm * std) + x_avg
# 反归一化,要不然图片都黑了,因为normalize了
invTrans = T.Compose(
[
T.Normalize(mean=[0.,0.,0.], std=[1/0.5, 1/0.5,1/0.5]),
T.Normalize(mean=[-0.5, -0.5, -0.5], std=[1., 1., 1.])
]
)
if __name__ == '__main__':
import matplotlib.pyplot as plt
import torchvision.utils as vutils
print(len(face_loader))
for data, _ in face_loader:
print(data.size()) # NCHW
grid = vutils.make_grid(data, nrow=8)
print(grid)
plt.imshow(invTrans(grid).permute(1,2,0)) # NHWC
plt.show()
break
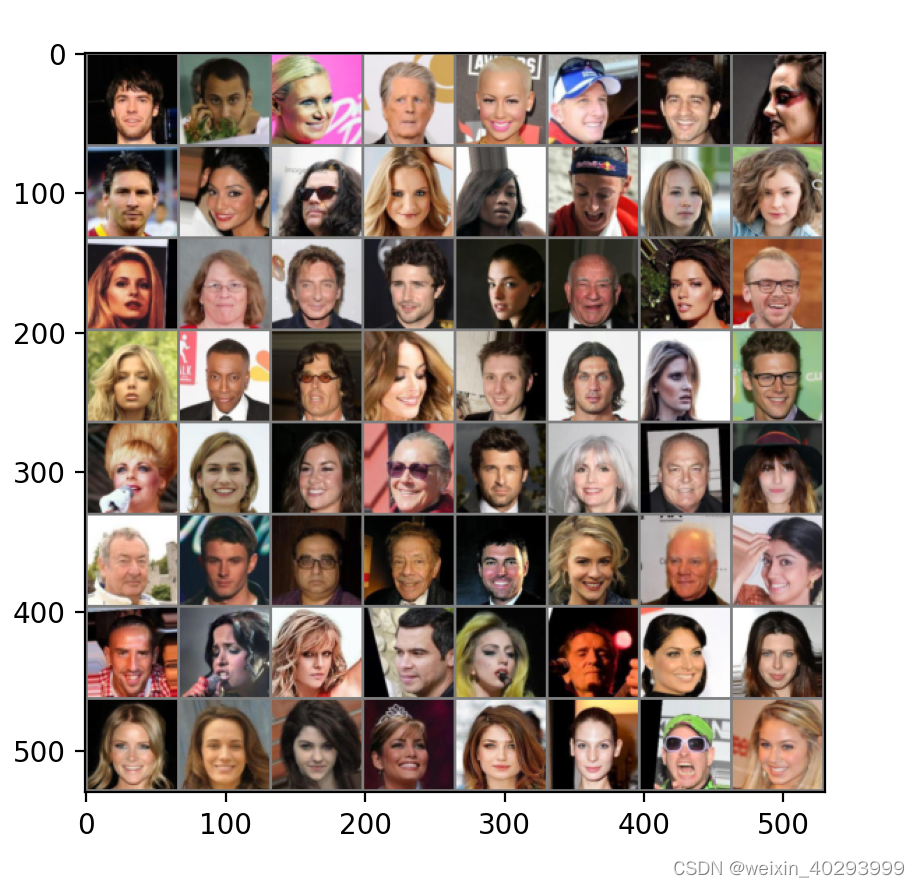
因为是对抗生成式模型,所以没有label,没有训练集,测试集那一说,只有一堆图片. 也要生成和他们一样的图片.
2.3 generator
import torch
from torch import nn
from config import HP
class Generator(nn.Module):
def __init__(self) -> None:
super().__init__()
self.projection_layer = nn.Linear(HP.z_dim, 4*4*1024)
# 1.feature/data
# transform 2.shape transform
self.generator = nn.Sequential(
# TransposeConv layer:1
nn.ConvTranspose2d(
in_channels=1024,
out_channels=512,
kernel_size=(4,4),
stride=(2,2),
padding=(1,1),
bias=False),
nn.BatchNorm2d(512),
nn.ReLU(),
# TransposeConv layer:2
nn.ConvTranspose2d(
in_channels=512,
out_channels=256,
kernel_size=(4,4),
stride=(2,2),
padding=(1,1),
bias=False),
nn.BatchNorm2d(256),
nn.ReLU(),
# TransposeConv layer:3
nn.ConvTranspose2d(
in_channels=256,
out_channels=128,
kernel_size=(4,4),
stride=(2,2),
padding=(1,1),
bias=False),
nn.BatchNorm2d(128),
nn.ReLU(),
# TransposeConv layer:final
nn.ConvTranspose2d(
in_channels=128,
out_channels=HP.data_channels, # 3
kernel_size=(4,4),
stride=(2,2),
padding=(1,1),
bias=False),
nn.Tanh(),
)
def forward(self, latent_Z): # latent space (Ramdon Input / Noise) : [N, 100]
z = self.projection_layer(latent_Z) #[N, 4*4*1024]
z_projected = z.view(-1, 1024, 4, 4) # [N, 1024, 4, 4]:NCHW
return self.generator(z_projected)
@staticmethod
def weights_init(layer):
layer_class_name = layer.__class__.__name__
if 'Conv' in layer_class_name:
nn.init.normal_(layer.weight.data, 0.0, 0.02)
elif 'BatchNorm' in layer_class_name:
nn.init.normal_(layer.weight.data, 1.0,0.02)
nn.init.normal_(layer.bias.data,0.)
if __name__ == '__main__':
z = torch.randn(size=(64,100))
G = Generator()
g_out = G(z) # generator output
print(g_out.size())
import matplotlib.pyplot as plt
import torchvision.utils as vutils
from dataset_face import invTrans
grid = vutils.make_grid(g_out, nrow=8)
print(grid)
plt.imshow(invTrans(grid).permute(1,2,0)) # NHWC
plt.show()
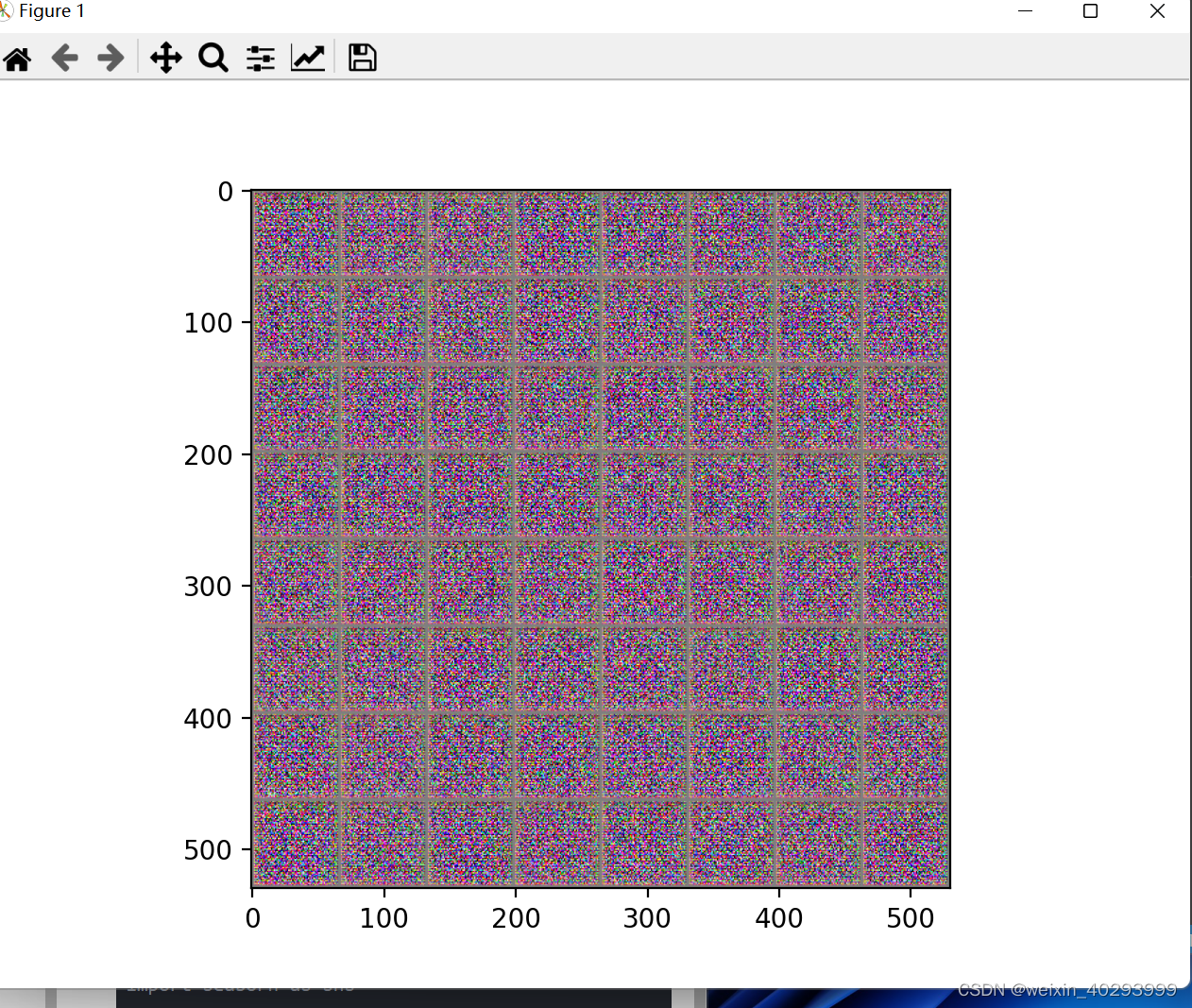
还没训练,所以看到的是噪音图片
2.4 discriminator
# Discriminator : Binary classification model
import torch
from torch import nn
from config import HP
class Discriminator(nn.Module):
def __init__(self) -> None:
super().__init__()
self.discriminator = nn.Sequential( # 1. shape transform 2. use conv layer as "feature extraction"
# conv layer: 1
nn.Conv2d(in_channels=HP.data_channels, #[N. 16, 32, 32]
out_channels= 16,
kernel_size=(3,3),
stride=(2,2),
padding=(1,1),
bias= False
),
nn.LeakyReLU(0.2),
# conv layer : 2
nn.Conv2d(in_channels=16, #[N. 32, 16, 16]
out_channels= 32,
kernel_size=(3,3),
stride=(2,2),
padding=(1,1),
bias= False
),
nn.BatchNorm2d(32),
nn.LeakyReLU(0.2),
# conv layer : 3
nn.Conv2d(in_channels=32, #[N. 64, 8, 8]
out_channels= 64,
kernel_size=(3,3),
stride=(2,2),
padding=(1,1),
bias= False
),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2),
# conv layer : 4
nn.Conv2d(in_channels=64, # [N, 128, 4, 4]
out_channels=128,
kernel_size=(3, 3),
stride=(2, 2),
padding=(1, 1),
bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
# conv layer : 5
nn.Conv2d(in_channels=128, # [N, 256, 2, 2]
out_channels=256,
kernel_size=(3, 3),
stride=(2, 2),
padding=(1, 1),
bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
)
self.linear = nn.Linear(256*2*2, 1)
self.out_ac = nn.Sigmoid()
def forward(self, image):
out_d = self.discriminator(image) # image [N, 3, 64, 64] -> [N, 256, 2, 2]
out_d = out_d.view(-1, 256*2*2) # tensor flatten
return self.out_ac(self.linear(out_d))
@staticmethod
def weights_init(layer):
layer_class_name = layer.__class__.__name__
if 'Conv' in layer_class_name:
nn.init.normal_(layer.weight.data, 0.0, 0.02)
elif 'BatchNorm' in layer_class_name:
nn.init.normal_(layer.weight.data, 1.0, 0.02)
nn.init.normal_(layer.bias.data, 0.)
if __name__ == '__main__':
g_z = torch.randn(size=(64, 3, 64, 64))
D = Discriminator()
d_out = D(g_z)
print(d_out.size())
2.5 trainer.py
训练过程:
# 1. trainer for DCGAN
# 2. GAN relative training skills & tips
import os
from argparse import ArgumentParser
import torch.optim as optim
import torch
import random
import numpy as np
import torch.nn as nn
from tensorboardX import SummaryWriter
from generator import Generator
from discriminator import Discriminator
import torchvision.utils as vutils
from config import HP
from dataset_face import face_loader, invTrans
logger = SummaryWriter('./log')
# seed init: Ensure Reproducible Result
torch.random.manual_seed(HP.seed)
torch.cuda.manual_seed(HP.seed)
random.seed(HP.seed)
np.random.seed(HP.seed)
def save_checkpoint(model_, epoch_, optm, checkpoint_path):
save_dict = {
'epoch': epoch_,
'model_state_dict': model_.state_dict(),
'optimizer_state_dict': optm.state_dict()
}
torch.save(save_dict, checkpoint_path)
def train():
parser = ArgumentParser(description='Model Training')
parser.add_argument(
'--c', # G and D checkpoint path: model_g_xxx.pth~model_d_xxx.pth
default=None,
type=str,
help='training from scratch or resume training'
)
args = parser.parse_args()
# model init
G = Generator() # new a generator model instance
G.apply(G.weights_init) # apply weight init for G
D = Discriminator() # new a discriminator model instance
D.apply(D.weights_init) # apply weight init for G
G.to(HP.device)
D.to(HP.device)
# loss criterion
criterion = nn.BCELoss() # binary classification loss
# optimizer
optimizer_g = optim.Adam(G.parameters(), lr=HP.init_lr, betas=(HP.beta, 0.999))
optimizer_d = optim.Adam(D.parameters(), lr=HP.init_lr, betas=(HP.beta, 0.999))
start_epoch, step = 0, 0 # start position
if args.c: # model_g_xxx.pth~model_d_xxx.pth
model_g_path = args.c.split('~')[0]
checkpoint_g = torch.load(model_g_path)
G.load_state_dict(checkpoint_g['model_state_dict'])
optimizer_g.load_state_dict(checkpoint_g['optimizer_state_dict'])
start_epoch_gc = checkpoint_g['epoch']
model_d_path = args.c.split('~')[1]
checkpoint_d = torch.load(model_d_path)
D.load_state_dict(checkpoint_d['model_state_dict'])
optimizer_d.load_state_dict(checkpoint_d['optimizer_state_dict'])
start_epoch_dc = checkpoint_d['epoch']
start_epoch = start_epoch_gc if start_epoch_dc > start_epoch_gc else start_epoch_dc
print('Resume Training From Epoch: %d' % start_epoch)
else:
print('Training From Scratch!')
G.train() # set training flag
D.train() # set training flag
# fixed latent z for G logger
fixed_latent_z = torch.randn(size=(64, 100), device=HP.device)
# main loop
for epoch in range(start_epoch, HP.epochs):
print('Start Epoch: %d, Steps: %d' % (epoch, len(face_loader)))
for batch, _ in face_loader: # batch shape [N, 3, 64, 64]
# ################# D Update #########################
# log(D(x)) + log(1-D(G(z)))
# ################# D Update #########################
b_size = batch.size(0) # 64
optimizer_d.zero_grad() # gradient clean
# gt: ground truth: real data
# label smoothing: 0.85, 0.1 / softmax: logist output -> [0, 1] Temperature Softmax
# multi label: 1.jpg : cat and dog
labels_gt = torch.full(size=(b_size, ), fill_value=0.9, dtype=torch.float, device=HP.device)
predict_labels_gt = D(batch.to(HP.device)).squeeze() # [64, 1] -> [64,]
loss_d_of_gt = criterion(predict_labels_gt, labels_gt)
labels_fake = torch.full(size=(b_size, ), fill_value=0.1, dtype=torch.float, device=HP.device)
latent_z = torch.randn(size=(b_size, HP.z_dim), device=HP.device)
predict_labels_fake = D(G(latent_z)).squeeze() # [64, 1] - > [64,]
loss_d_of_fake = criterion(predict_labels_fake, labels_fake)
loss_D = loss_d_of_gt + loss_d_of_fake # add the two parts
loss_D.backward()
optimizer_d.step()
logger.add_scalar('Loss/Discriminator', loss_D.mean().item(), step)
# ################# G Update #########################
# log(1-D(G(z)))
# ################# G Update #########################
optimizer_g.zero_grad() # G gradient clean
latent_z = torch.randn(size=(b_size, HP.z_dim), device=HP.device)
labels_for_g = torch.full(size=(b_size, ), fill_value=0.9, dtype=torch.float, device=HP.device)
predict_labels_from_g = D(G(latent_z)).squeeze() # [N, ]
loss_G = criterion(predict_labels_from_g, labels_for_g)
loss_G.backward()
optimizer_g.step()
logger.add_scalar('Loss/Generator', loss_G.mean().item(), step)
if not step % HP.verbose_step:
with torch.no_grad():
fake_image_dev = G(fixed_latent_z)
logger.add_image('Generator Faces', invTrans(vutils.make_grid(fake_image_dev.detach().cpu(), nrow=8)), step)
if not step % HP.save_step: # save G and D
model_path = 'model_g_%d_%d.pth' % (epoch, step)
save_checkpoint(G, epoch,optimizer_g, os.path.join('model_save', model_path))
model_path = 'model_d_%d_%d.pth' % (epoch, step)
save_checkpoint(D, epoch, optimizer_d, os.path.join('model_save', model_path))
step += 1
logger.flush()
print('Epoch: [%d/%d], step: %d G loss: %.3f, D loss %.3f' %
(epoch, HP.epochs, step, loss_G.mean().item(), loss_D.mean().item()))
logger.close()
if __name__ == '__main__':
train()
2.6 inference 推理
# 1. how to use G?
import torch
from dataset_face import face_loader, invTrans
from generator import Generator
from config import HP
import matplotlib.pyplot as plt
import torchvision.utils as vutils
# new an generator model instance
G = Generator()
checkpoint = torch.load("./model_save/model_g_15_50000.pth", map_location='cpu')
G.load_state_dict(checkpoint['model_state_dict'])
G.to("cpu")
G.eval() # set evaluation model
while 1:
# 1. Disentangled representation: manual set Z: [0.3, 0, ]
# 2. any input: z: fuzzy image -> high resolution image / mel -> audio/speech(vocoder)
latent_z = torch.randn(size=(HP.batch_size, HP.z_dim), device="cpu")
fake_faces = G(latent_z)
grid = vutils.make_grid(fake_faces, nrow=8) # format into a "big" image
plt.imshow(invTrans(grid).permute(1, 2, 0)) # HWC
plt.show()
input()
epoch = 15的生成效果,已经看出人脸的样子了,但是因为训练时间太长,我就不等了.
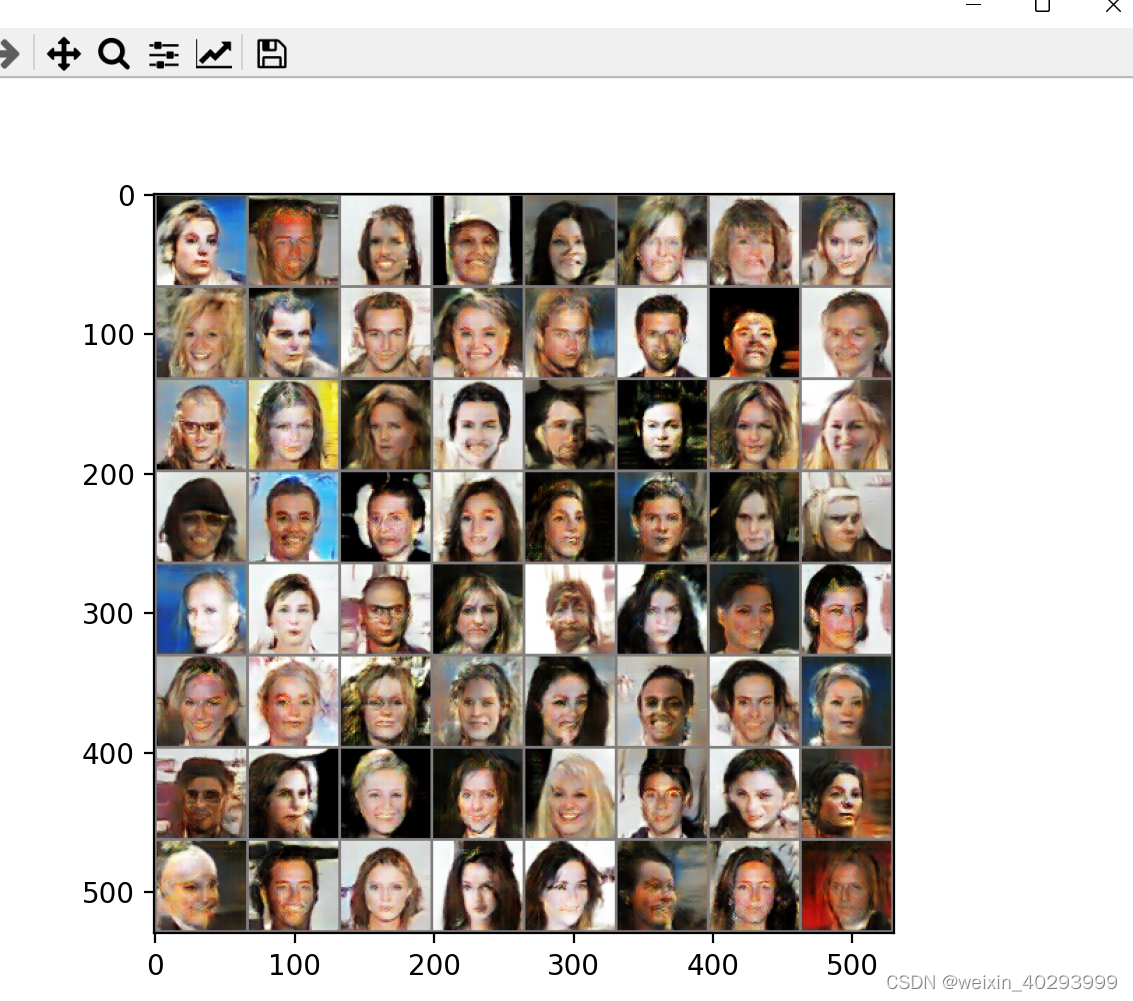
总结
终于完成了from scratch的训练的干,上次干这活儿是2年前,那是是研二的作业.
体会如下:
- 生成器的模型权重才值得保留, 鉴别器其实是不需要的.
- 生成器更加难以训练.
- loss 比较主观,主要看人看起来是否顺眼. loss 只能说明生成器和鉴别器要共同进步,不能有一方奔溃.