
获取结构化的人类知识是设计高级人工智能的重要基础。为此,早期研究者做了大量工作以从不同数据源中自动提取可以提供有用信息(事实)的数据模式;进一步地,学者的研究兴趣转向自动构建概念化的结构良好的知识图谱,而非仅提供信息的数据。
近年来,新的研究挑战亦开始深入多样化的复杂大数据环境中的知识工程。在上述具有历史意义的研究活动中涌现了大量具有开创性的重要知识图谱构建方法、新研究范式以及挑战。鉴于此,本综述对358篇相关文献进行了系统调研,对了知识图谱构建这一重要主题进行了详细总结。
本文全面阐释了知识图谱构建的主要3个阶段,包括知识获取、知识精炼、知识演化。具体地,本文按照数据环境、设计动机与模型架构三个方向,对处理上述各阶段中子任务的方法模型进行了比较、探讨。同时,为力求综述的全面性,本文也对图谱构建前的数据预处理与知识图谱构建后存储的相关方法进行了简介。
同时,本文简要回顾了重要的现有知识图谱成果(数据集)与处理知识图谱构建的各类先成工具。最后,本综述对10个具有重要现实意义的未来研究方向与挑战进行了讨论。
1.引言
知识图谱技术将可实现“赋能”的结构良好支撑知识提供给其下游人工智能应用,例如:搜索引擎[1]、推荐系统[2]和智能问答[3]。大量众所周知的大型知识图谱系统通过知识众包进行构建,如Freebase[4]和Wikidata[5]。然而该手工过程异常艰辛繁琐。因此,实现从非结构化或半结构化数据中自动构建知识图谱的系统方案将为知识图谱构建过程提供巨大帮助。
知识图谱为一个具有语义的图结构,其由描述真实世界对象知识的边和节点组成。在这些结构中,知识元组是承载知识的最小单位,其由表示概念的两个(实体)节点与连接二者表示关系的边连接。
因此,构建知识图谱的任务旨在从特定域或开放域数据中发现可构成知识图谱的合适元素并将其组合。在早期研究中,研究人员主要集中于从半结构化或非结构化文本数据中笼统地提取事实元组(仅由字符串构成、形似知识元组的模式结构)。
具有代表性的早期信息提取系统,例如:TextRunner[6]和Knownitall[7]为自动知识图构建的里程碑,其基于特点的规则或聚类方法进行构建、提取。然而,这些设计没有充分考虑背景知识,因此存在两个主要缺陷:
1)缺乏实质性,传统信息提取系统无法从不同的表达中创建或区分概念化的实体,其阻碍了整合知识的语义计算任务的进行;
2) 缺乏深层信息,传统信息提取系统仅从句法结构中提取信息,无法理解自然语言表达中的深层语义。此外,传统的基于规则的信息提取系统还需要大量的特征工程和额外的专家知识以完善。
著名数据科学家吴信东研究团队[8]指出,如果知识图谱系统不能结合有关概念实体的背景知识来组织图中节点和边,那么这样的“知识图谱”仅仅是一个数据图。
鉴于此,研究学者尝试将知识图谱构建任务划分为多个子任务以有效地组织语义知识结构。其中的经典的范式是首先进行实体识别,而后处理共指消解问题,然后提取实体间关系的知识获取过程。
在该过程完成后,对于粗加工的知识图谱进行知识精炼,其主要包括知识补全与知识融合两个过程。针对精炼后的知识图谱,成熟的知识图谱系统将对其已有的结构化数据进行知识演化分析,其主要包括:时序知识图谱与条件知识图谱的构建与完善。
本文总结的知识图谱构建一般过程如图1所示。与此同时,深度学习方法取得的进展为知识图谱构建任务提供了新的思路。针对知识获取任务中具体挑战,许多深度学习模型在诸如命名实体识别[9][10]、实体细分类[11][12]、实体链接[13][14]、共指消解[15]、关系抽取[16][17]等任务中都取得了良好的效果。
针对知识精炼任务,基于深度学习的方法亦在知识补全与针对不同规模知识图谱的知识融合任务中有明显的突破。此外,研究者也对时序知识图谱、条件知识图谱进行了进一步深入研究。目前,许多知识图谱项目TransOMCS[18]、ASER[19]和华谱系统[20]等亦将基于深度学习的高效自动知识图谱构建方法付诸与工程实践中。

图1:知识图谱构建的流程范式.
进一步地,随着互联网数据规模的急剧扩大,复杂、异构大数据环境为知识图谱构建带来挑战的同时也伴随着突破性的转机,例如:基于大数据集的预训练模型(以BERT[21]为代表)、建模复杂特征的大规模图卷积网络(GCN)模型。
结合上述新成果,学者亦开始攻克具有长上下文[22]、数据噪声 [23]与低资源特征[24]的复杂数据环境中知识图谱构建子任务以及提出基于联合学习的高效模型并寻求具有可解释性的高效机器学习方法。同时,针对跨语言数据中的知识获取与融合的研究也方兴未艾。
目前,对于涉及知识演化问题的时序知识图谱分析[25]与条件知识图谱分析[26]也有成果不断涌现。此外,针对自治知识社区(自发产生个性化数据的社区),主动学习方法[27]也为上述情景提供了人机交互的灵活知识获取策略。著名数据科学家吴信东研究团队[28]总结:上述大数据环境的特征符合HACE定理(异构、自治、复杂、演化)。在图2中,本文以HACE定理的视角总结了大数据背景下知识图谱构建任务的具体挑战。
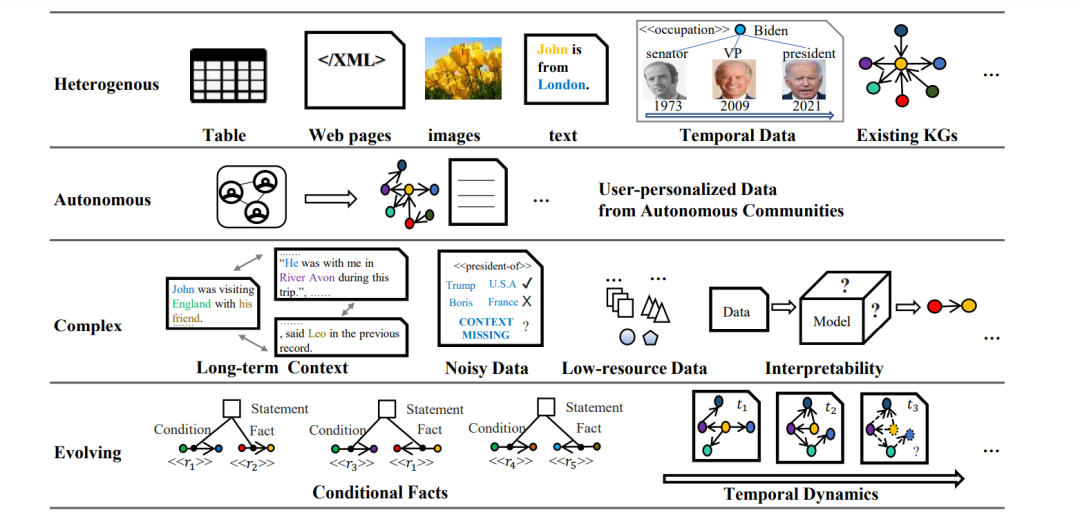
图2:在HACE定理视角下知识图谱构建任务在大数据环境中面临的挑战.
大量已有调研工作[29-37]已针对知识图谱本身及其各类构建的一般过程或具体层面进行了调研,然而这些工作尚未对大数据环境下知识图谱构建的新进展与应对大数据挑战的特有范式进行系统性地总结。
因此,不同于已有调研,本文根据知识图谱构建不同阶段与大数据环境HACE特征的不同层面深入阐述近年来知识图谱构建方法模型的特点与范式,然后从具有前景的模型设计理念出发,展望未来的挑战和方向。
此外,本文也提供实用的数据集与知识图谱工具信息供读者参考。本文的贡献总结如下:
丰富的资源信息:系统性地介绍了知识图谱构建的完整过程与最新进展,并对知识图谱及其构建过程给出了正式的定义和分类。本文还提供丰富的知识图谱构建资源,包括实用知识图谱项目和构建工具,其中包括出版年份、引文和访问链接,供读者比较参考。
全面的总结、分类:根据知识图谱构建任务各阶段的任务背景、目标和挑战,详细阐述不同场景下的知识图谱构建模型–从知识获取到知识精炼。本文分析了经典模型与最新模型的设计特点与动机,结合大数据环境特征,根据他们的架构及改进点,总结出了其具有的新范式。
大数据背景下的新视野:我们讨论了具有特征HACE大数据环境中的知识图谱构建任务,包括处理噪音数据、文档级数据(长上下文)和低资源数据。然后我们回顾、概括了针对知识演化分析任务与模型可解释性问题所取得的成果。最后,我们总结了对知识图谱构建任务具有深远影响的重要方向和挑战。
本综述(完整内容请参看:https://arxiv.org/abs/2302.05019)将主要围绕下述五个部分介绍知识图谱构建全过程,即数据预处理、知识获取、知识精炼、知识演化、知识图谱存储。
A.数据预处理
海量大数据环境中异构数据常包含无关的碎片噪音(例如:网页中广告、页面布局)以及半结构化的数据(例如:关系表格)。在进行知识获取前,应去除噪音以避免干扰,同时解析半结构化数据以提高效率。上述目标将在数据预处理过程实现。本节将简述数据清洗的常见方法与半结构化表格数据的解析方法。
B.知识获取
知识获取为知识图谱构建最为重要的过程,其为知识图谱系统提供可分析的结构化原材料,实现从非结构化数据中构建粗加工的知识图谱。其主要包括:实体识别、共指消解、关系抽取。
具体地,本节介绍实体识别的三个子任务,包括:命名实体识别、实体细分类、实体链接;然后介绍处理共指消解任务基于统计学方法与基于深度学习方法的两类模型。
最后,介绍各类情景中的关系抽取任务:开放关系抽取、封闭领域关系抽取、远程监督的关系抽取、小样本关系抽取、联合关系抽取、文档级关系抽取。本节将系统全面地介绍适用于非结构化文本与半结构化表格、网页的知识获取方法,包括:传统方法(基于统计学、聚类、SVM等)、早期深度学习方法(基于CNN、LSTM等方法)、高性能深度学习方法(基于预训练模型与GCN模型等方法)。
C.知识精炼
知识精炼任务针对结构化数据(已有知识图谱)进行进一步优化,实现从已有图谱中构建新图谱。其包括知识精炼与知识融合两个部分。针对知识图谱补全,本节将介绍补全知识图谱的方法、各种场景中进行知识推理的方法、可解释的知识推理模型。其主要包括各类嵌入学习方法与深度学习神经网络方法。针对知识融合任务,本节介绍适用于不同规模知识图谱的融合方法。其主要包括各类嵌入学习方法(大规模图)与基于统计学方法(小规模图)。
D.知识演化
针对已完善的知识图谱,知识演化分析知识图谱随时间演化的规律与演化的一般条件结构,将高级语义特征引入知识图谱。本节概述时序知识图谱与条件知识图谱的研究进展。这些成果主要基于各类深度神经网络。
E.知识图谱存储
在图谱构建过程完成后,大规模知识图谱的高性能存储是一个重要的主题。本节简介知识图谱存储的技术方案,主要包括:关系型数据库、键值对数据库、图数据。读者可以根据具体运用场景,选择高性能、易于实现的方案。
(参考文献详见Arxiv上预印本:https://arxiv.org/abs/2302.05019)