作者:@小萌新
专栏:@Linux
作者简介:大二学生 希望能和大家一起进步!
本篇博客简介:简单介绍linux中的多线程
线程概念
线程基本概念
一般在书上我们会这么介绍一个线程
线程是进程内部的一个执行流 他是进程的一部分 粒度要比进程更加细和轻量化
那么我们应该怎么理解呢? 下面是我的梳理思路
首先线程是进程的一个执行流的对吧 那么一个进程中是不是可能有很多的线程呢? 答案当然是肯定的
那么我们就可以推断 系统中一定存在着大量的线程
既然系统中存在着大量的线程 操作系统作为管理者就要想办法将这些线程管理起来
而根据我们管理的法则:先描述 再组织 操作系统会描述这些线程并且将它们进行组织(默认双链表)
那么操作系统要怎么描述这些线程呢? 答案和进程类似 用一个叫做TCB的结构体来描述
在windows操作系统中 操作系统管理线程就是按照我们上面的逻辑进行的
不过在我们的Linux系统中使用了一种更加巧妙的方法
Linux中的线程
之前在进程部分我们讲过 进程 = 程序 + PCB + mm_struct + 页表和mmu + 物理地址 如下图所示
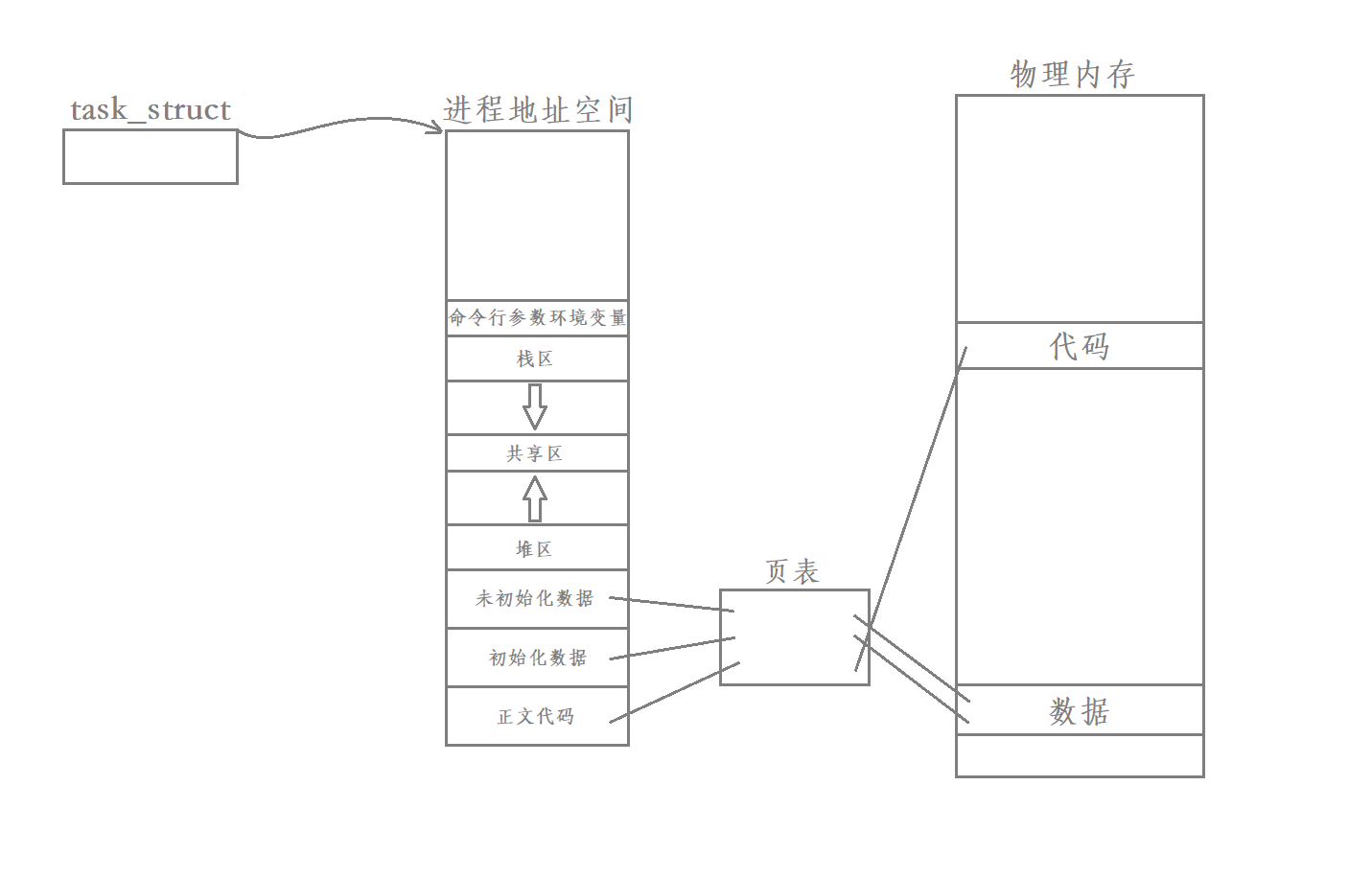
Linux在创造线程概念的时候并没有像上面我们所推断的一样创造TCB结构体来管理每一个线程 而是复用了进程的PCB结构体
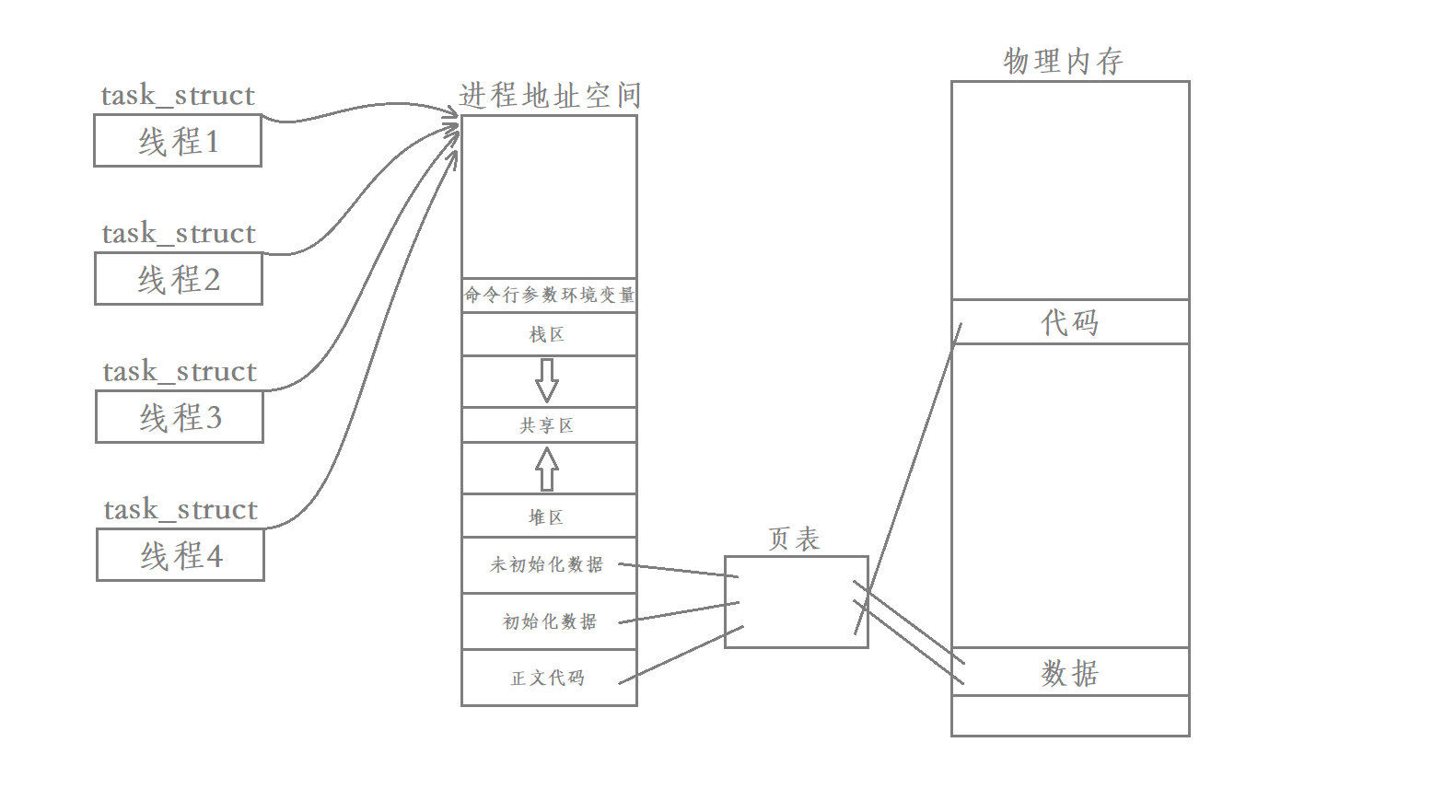
这些线程的PCB和进程PCB共享一个进程地址空间 它们每个线程都会分走一点代码和数据
在cpu看来此时的PCB是要小于等于我们之前讲解的PCB概念的
可是cpu不关心这些 它认为一个PCB就是一个执行流 它只管执行就好
这里我们就能得出一个重要的结论
Linux中没有为线程专门设计TCB 而是使用进程PCB模拟线程
这样子设计的优点是什么呢?
最直观的优点 我们不必去设计线程TCB了 这代表着我们节省了大量时间去设计数据结构和算法
与此同时 操作系统也只需要聚焦在线程间的资源分配上就好了
进程线程再理解
我们在博客的开篇就提到过了书上有这么一个概念
线程是进程内部的一个执行流 他是进程的一部分 粒度要比进程更加细和轻量化
我们应该怎么理解上面的这句话
- 内部: 表示线程在进程的虚拟地址空间中
- 执行流:CPU在调度的时候只看PCB 所以说PCB中曾经指定的方法和数据CPU都可以直接的调度
那么为什么线程是进程的一部分呢? 要回答这个问题 我们需要再深入了解下进程
进程 = 程序 + PCB + mm_struct + 页表和mmu + 物理地址
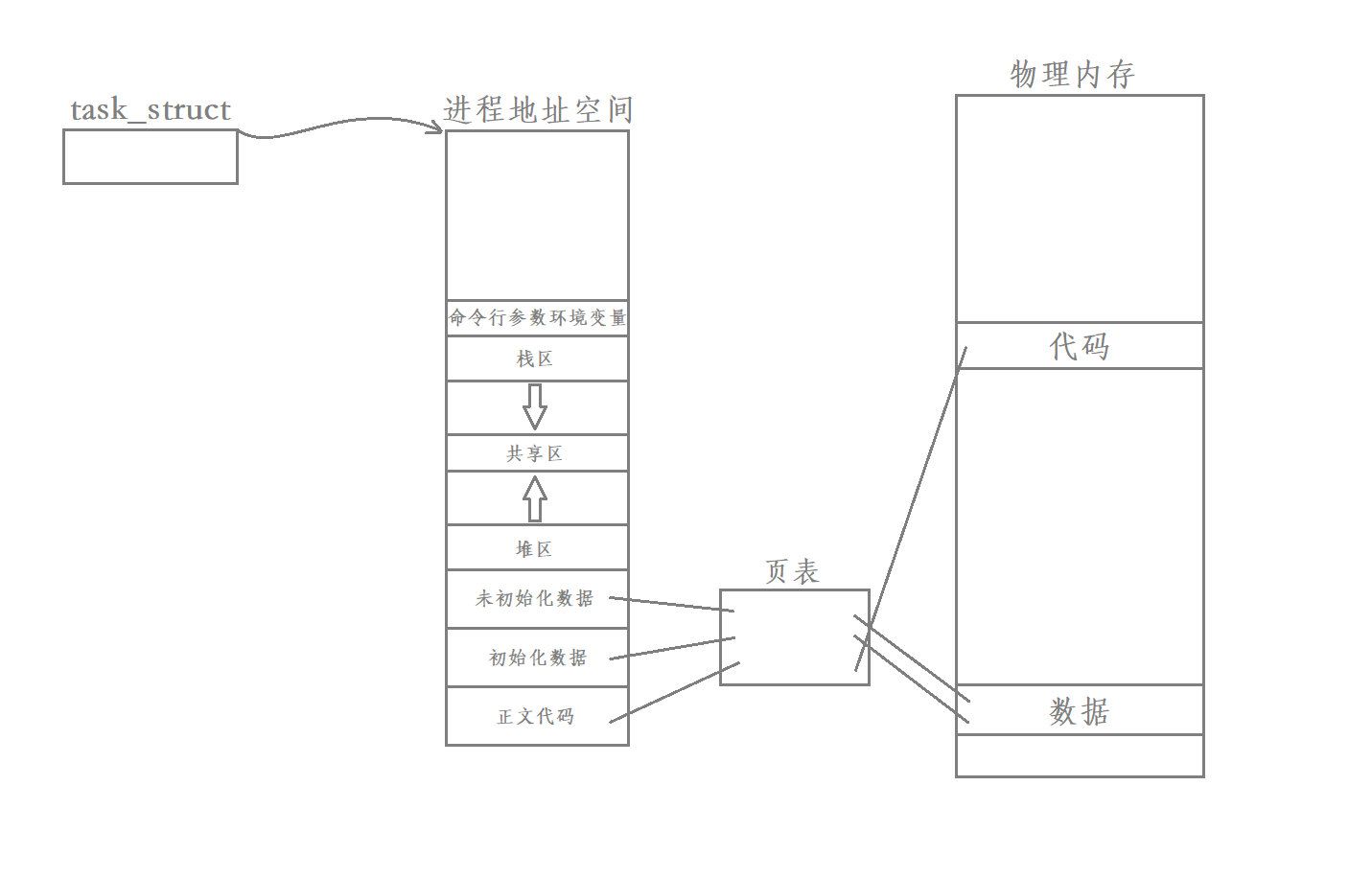
在我们之前的学习过程中 进程默认是只有一个执行流的
而在今天的学习之后 进程是可能会有多个执行流的
我们要明确一点 创建进程的代价是非常大的 这里的代价包括时间+空间
- 时间: cpu处理并创建PCB进程地址空间等资源的时间
- 空间:创建的PCB和进程地址空间等占用的空间
所以说在内核视角中 进程是承担分配系统资源的基本实体
而线程只需要创建一个PCB和获取一点进程的资源所以说在内核视角中线程是CPU调度的基本单位 承担进程资源的一部分基本实体
Linux线程和接口的认识
在Linux中线程是用进程模拟实现的 所以说Linux中不会给我们提供线程的操作接口 (这里解释下 其实Linux不是没有能力去提供这些操作接口 而是它想要保持一个相对自由的状态给用户) 而是给我们提供了一个在同一个进程地址空间中创建PCB的方法 分配给资源指定的PCB
但是作为一个用户来说 使用这种方法的学习成本太高了 我们更需要一个完整的线程库
所以说一些应用级的开发工程师就在应用层对于轻量级的Linux接口进行封装成为了我们经常使用的原生线程库
Linux线程与进程区别
我们在创建进程的时候通常会为进程创建一个独立的程序地址空间来保证它的独立性而线程则恰恰相反它们只创建PCB共用一个进程地址空间
但是同样的进程间为了通信或者是其他目的也会选择性的共用一块公共资源而线程为了保证自己能够正确运行也会有一些独立的资源
- 进程具有独立性 但是一部分资源是可以共享的(管道 ipc等)
- 线程大部分资源是共享的 但是一部分资源是私有的 (PCB 栈 上下文等)
线程私有的数据
- 线程ID 这个很好理解 因为我们要使用线程ID来区分每个线程
- 一组寄存器 这组寄存器用来保存线程的上下文信息
- 栈 每个线程都有临时的数据需要压栈 如果不区分那数据就全乱了
- 信号屏蔽字
- 调度优先级
线程公有的数据
因为多个线程是在同一个进程地址空间中 所以说进程地址空间的代码段和数据段都是共享的
- 如果定义一个函数 在各线程中都可以调用
- 如果定义一个全局变量 在各线程中都可以访问到
除此之外 各线程还共享以下进程资源和环境
- 文件描述符表 (进程打开一个文件后其他线程也能够看到)
- 每种信号的处理方式(SIG_IGN、SIG_DFL或者自定义的信号处理函数)
- 当前工作目录(cwd)
- 用户ID和组ID等等
进程和线程的关系
如果我们把国家比作一个操作系统 那么国家中的每个家庭就是一个进程
每个家庭之间是相互独立的 不可能说今天另外一个家庭的人不经过你的同意就住进你家里
但是家庭与家庭之间也需要通信 可能周末会邀请关系好的邻居上你家客厅做客
家庭中的每个人就可以看作是线程 在这个家里大部分的资源是共享的
但是每个人也有自己的隐私 所以说一部分资源是私有的
代码验证
我们可以通过下面pthread_create函数来创建一个新的线程
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg);
返回值说明:
- 线程创建成功返回0 失败返回错误码
这里值得注意的是在线程库中 几乎所有的返回值都是成功返回0 失败返回错误码
参数说明:
- thread:获取创建成功的线程ID 该参数是一个输出型参数
- attr: 用于设置创建线程的属性 如果我们传入NULL则设置为默认属性
- start_routine:这是一个函数地址 传入我们想要这个线程执行的函数
- arg: 传给线程例程的参数 (默认是void* 类型 记得类型强转不然会报警告)
下面是代码示例
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <pthread.h>
4 #include <unistd.h>
5
6 void* run_thread(void* args)
7 {
8 char* msg = (char*)args;
9 while(1)
10 {
11 printf("im a thread my msg is:%s\n" , msg);
12 sleep(1);
13 }
14 }
15
16
17 int main()
18 {
19 pthread_t tid;
20 pthread_create(&tid ,NULL ,run_thread ,(void*)"thread 1");
21 while(1)
22 {
23 printf("im main thread\n");
24 sleep(1);
25 }
26 return 0;
27 }
上面代码的意思是我们创建一个子线程 这个线程不停的打印参数发送过去的消息 同时我们的主进程不停的打印另外的信息

但是这里我们发现我们进行编译之后会出现这样子的情况 这是因为我们找不到库文件所导致的
具体的原因可以参考我动静态库这篇博客
所以说我们想要编译成功这个文件需要先指令连接的库文件
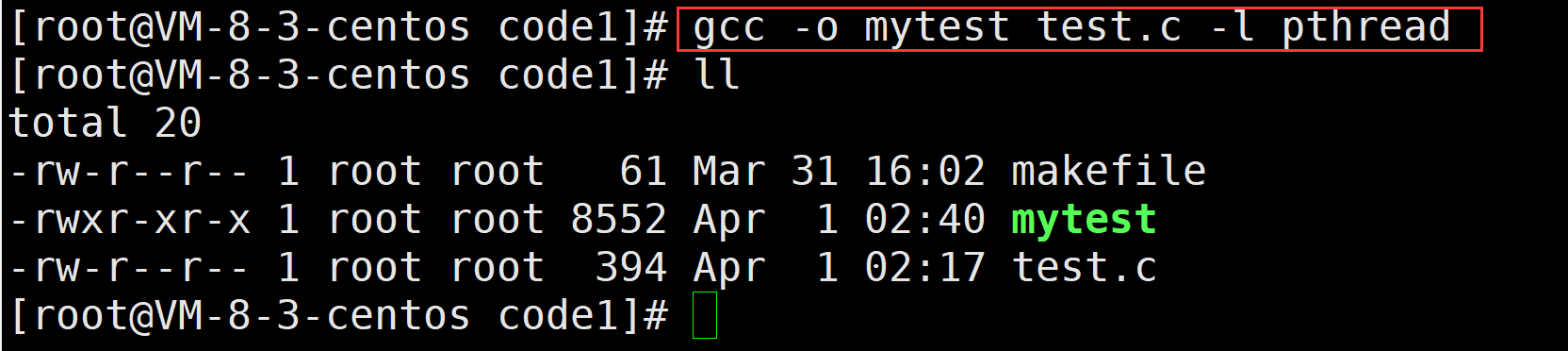
演示效果如下
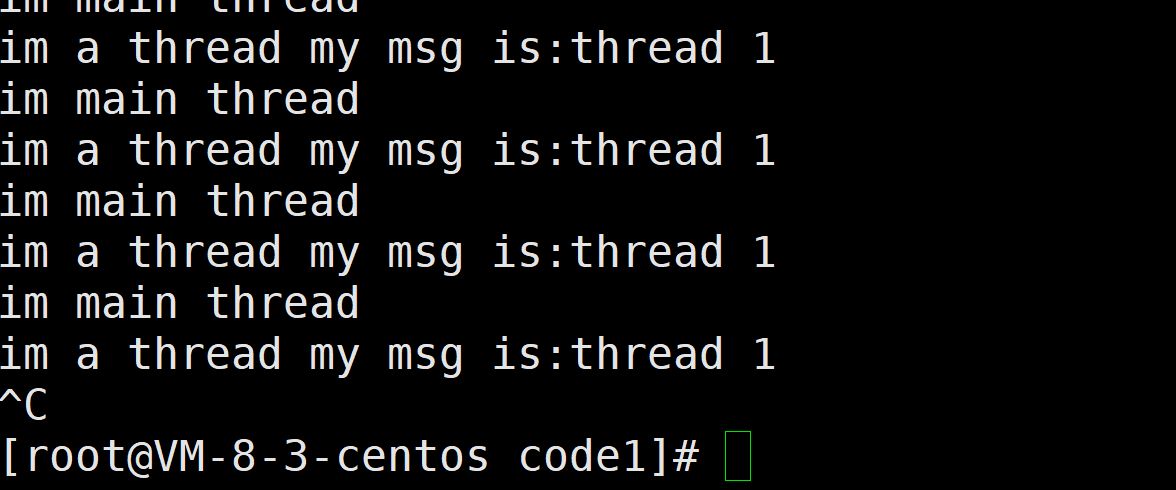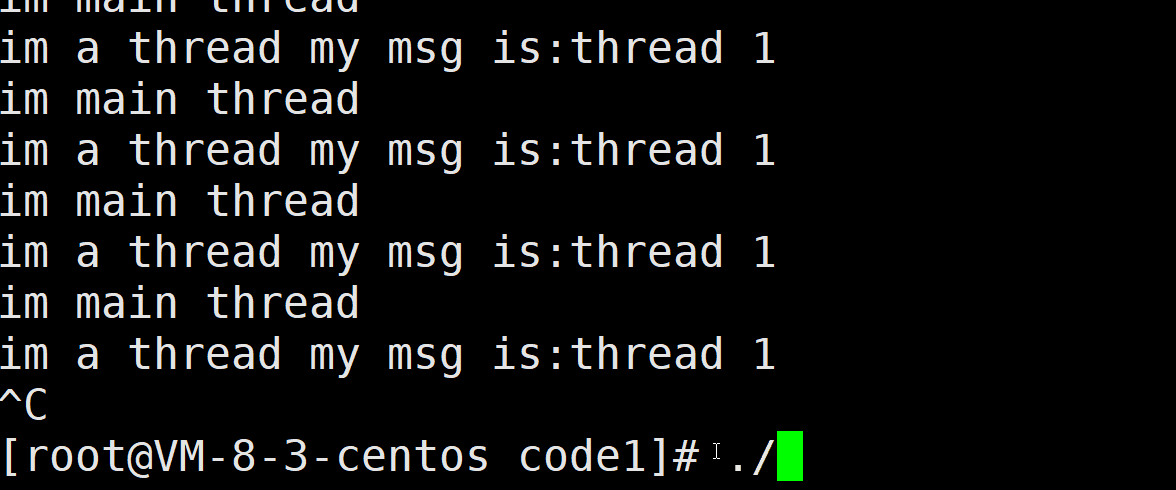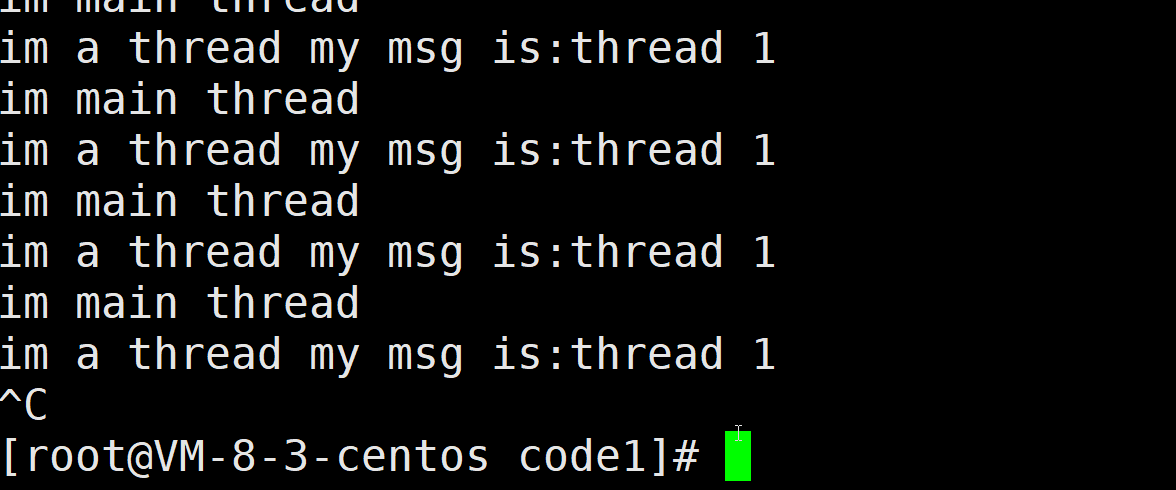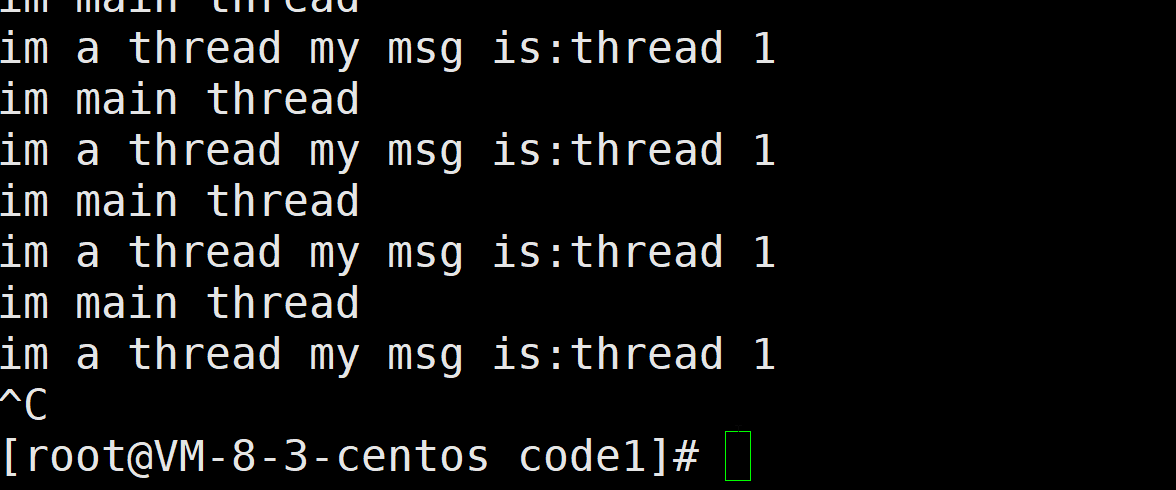
我们发现这里竟然有两个while循环在同时执行 这在我们以前单执行流的时候是不想象的
当这两个进程在运行的时候我们可以使用下面的指令来查看轻量级进程
ps -aL
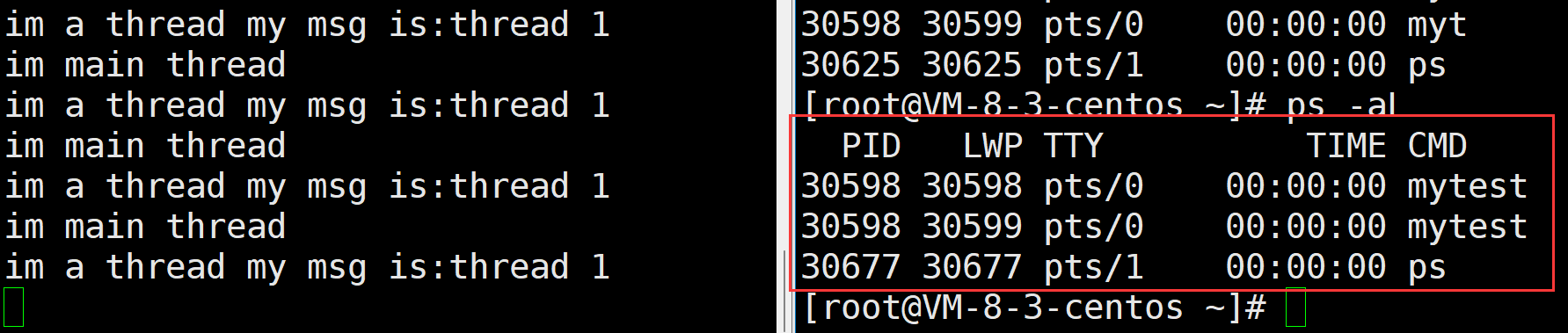
我们可以看到这里两个进程的PID都是一样的 但是他们的LWP却不同
所以这里我们就能很简单的推断出
操作系统调度的时候查看的是LWP
但是我们之前在进程部分讲过 操作系统调度的时候看的是进程PID 这句话错了吗?
实际上这句话放在我们之前的条件下是没错的 因为我们当时是单进程执行流 此时的进程PID就等于LWP 所以那么说也对
线程的优缺点
线程的优点
- 创建一个新线程的代价要比创建一个新进程小得多
- 与进程之间的切换相比 线程之间的切换需要操作系统做的工作要少很多
- 线程占用的资源要比进程少很多
- 能充分利用多处理器的可并行数量
- 在等待慢速IO操作结束的同时 程序可执行其他的计算任务
- 计算密集型应用 为了能在多处理器系统上运行 将计算分解到多个线程中实现
- IO密集型应用 为了提高性能 将IO操作重叠 线程可以同时等待不同的IO操作
概念说明
计算密集型 执行流的大部分任务 主要以计算为主 比如加密解密 大数据查找等
O密集型 执行流的大部分任务 主要以IO为主 比如刷磁盘 访问数据库 访问网络等
线程的缺点
- 性能损失: 一个很少被外部事件阻塞的计算密集型线程往往无法与其他线程共享同一个处理器 如果计算密集型线程的数量比可用的处理器多 那么可能会有较大的性能损失 这里的性能损失指的是增加了额外的同步和调度开销 而可用的资源不变
- 健壮性降低: 编写多线程需要更全面更深入的考虑 在一个多线程程序里 因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的 换句话说 线程之间是缺乏保护的
- 缺乏访问控制: 进程是访问控制的基本粒度 在一个线程中调用某些OS函数会对整个进程造成影响
- 编程难度提高: 编写与调试一个多线程程序比单线程程序困难得多
线程异常
如果单个线程出现异常 比如说出现除零错误等 有可能会导致整个进程崩溃
造成这样子的原因是 操作系统发送信号是向进程发送的
线程用途
- 合理的使用多线程 能提高CPU密集型程序的执行效率
- 合理的使用多线程 能提高IO密集型程序的用户体验(如生活中我们一边写代码一边下载开发工具 就是多线程运行的一种表现)