C++基础实用笔记
存储常识
一个字节(Byte)占8位(比特bit),也就是占8个二进制数,存储8位无符号数,储存的数值范围为0-255。
存储单位换算:
1B = 8b ; 1KB = 1024 B ; 1MB = 1024 KB ;1GB=1024MB ; 1024 = 2 10 \ 1024 = 2^{10}\, 1024=210。在计算机网络通信的传输速度概念中,通常用 1 0 3 \ 10^{3}\, 103来近似代替 2 10 \ 2^{10}\, 210
一个英文占一个字节 ,一个汉字占两个字节;
如果是32位的系统,CPU以32位为单元处理数据,则一个字是4个字节,如果是64位,则是8个字节,在汇编中一个字两字节;(此处的字不同于汉字)
int 占4个字节,32比特, 数据范围为 − 2 31 到 2 31 − 1 \ -2^{31}到2^{31}-1\, −231到231−1,取值范围是-2147483648(10位)——2147483647,如果超出最大值就会产生进位将符号位置1,变成负数。因此当数量很大时,常常需要对大质数 1 0 9 + 7 10^9 + 7 109+7取模%运算,使结果变小;
unsigned int 表示无符号整数,数据范围为0~ 2 32 − 1 \ 2^{32}-1\, 232−1
char字符型变量只占一个字节,取值范围为 -128 ~ +127( − 2 7 到 2 7 − 1 \ -2^{7}到2^{7}-1\, −27到27−1)
float类型占用4字节内存,表示小数,数据范围在 − 2 128 到 2 128 \ -2^{128}到2^{128}\, −2128到2128 之间。
ASCII码中字符对应的二进制bin为8位,对应256个字符。通常用到低7位,因此通常说的ASCII码包含128个字符。其中,前32个字符(0-31)是不能用于打印控制的编码,而是用于控制像打印机一样的外围设备。32是空格, 48~57为0到9十个阿拉伯数字,65~90为26个大写英文字母,97~122号为26个小写英文字母。第127个字符表示的是键盘上的删除命令。
但是目前许多基于x86的系统都支持使用扩展(高)ASCII码,因为扩展ASCII码用到了第8位,因此后128 个被称为扩展ASCII码。
char和int之间的转换:
注意:不能随便用C语言的强制类型转换,容易乱码。
①char转为int
char类型直接转换成int类型对应的是ASCII码对应的十进制数值,
阿拉伯数字字符对应的十进制数与字符的关系满足:i = int( ch )-48
比如 char ch = ‘0’;
正确的转换方式为 int i = ch-‘0’;
容易错的写法为 int i = int(ch); //得到了ASCII码中字符0对应的十进制数48
②int转为char
int类型转换成char类型需找到阿拉伯数字字符对应的十进制数,然后用类型强制转换符:ch=char( ‘0’ + i )
比如 int i = 0;
正确的写法为 char ch = i +‘0’;
容易错的写法为 char ch = char(i); //二进制重解释,得到了ASCII码中十进制0对应的字符(此处为NUL空字符)
头文件基础
C++头文件加.h与不加.h,以及<>与""有什么区别?
c++中囊括了c,所以区分一下c和c++的语法很有必要,先上结论:
< >:表示引用标准头文件,头文件是系统路径,编译器会先在系统目录下搜索;
" ":表示使用自己写的头文件,编译器会先在用户目录下搜索,找不到再从系统库环境中找
不加 .h :如果使用的是新的C++标准库,不加 .h。例如#include <iostream>,编程时要加上命名空间
加 .h :如果是自己写的头文件,是必须加.h的。编程时不用再加命名空间
此外C++可以兼容使用C语言的库,这里有两种情况:
——第一种是仍旧使用原来C语言的库,可以加 .h,如#include<string.h>
——第二种是对C的库改进成C++的库,不加.h,但是在库名字前加c,表示来自与C语言。例如#include <cstring>
解释:
iostream是C++的头文件,iostream.h是C的头文件,即标准的C++头文件没有.h扩展名,将以前的C的头文件转化为C++的头文件后,有时加上c的前缀表示来自于c,例如cmath就是由math.h变来的。
iostream.h里面定义的所有类以及对象都是在全局空间里,所以可以直接用cout 。但在iostream里面,它所定义的东西都在名字空间std里面,所以必须加上 using namespace std才能使用cout 。
一般一个C++的老的带“.h”扩展名的库文件,比如iostream.h,在新标准后的标准库中都有一个不带“.h”扩展名的相对应,区别除了后者的好多改进之外,还有一点就是后者的东东都塞进了“std”名字空间中。 但唯独string特别。 问题在于C++要兼容C的标准库,而C的标准库里碰巧也已经有一个名字叫做“string.h”的头文件,包含一些常用的C字符串处理函数,比如strcmp。 这个头文件跟C++的string类半点关系也没有,所以并非的“升级版本”,他们是毫无关系的两个头文件。
C语言中#include <stdlib.h>表示标准库头文件,在C++中也可以使用#include <stdlib.h>,因为C++兼容了C语言中的操作。不过一般更推荐使用C++风格的头文件,即#include 。cstdlib实现了stdlib.h中的所有功能,不过是按照C++的方式写的,所以与C++语言可以更好的配合。
常用C++头文件
#include "bits/stdc++.h"//C++万能头文件
#include <iostream>
#include <cstdio> // 带缓冲的标准输入输出。stdio是标准IO函数,比如printf和scanf函数
#include <cstdlib> //标准库头文件。stdlib里的是常用系统函数,跟系统调用相关的,比如内存申请malloc和释放free,以及随机数rand()
#include <algorithm> //排序、全排列、reverse反转、max_element最大元素等
#include <vector> //向量
#include <string> //字符串
#include <stack> //栈
#include <map> //默认使用key键的升序来排序的键值对关联容器
#include <unordered_map> //哈希表
#include <set> //根据元素键值自动排序的不重复集合
#include <unordered_set> //哈希集合
#include <queue> //队列、优先级队列
#include <deque> //双端队列
#include <iterator> //迭代器
#include <utility> //pair对
#include <list> //列表,双向链表
#include <cmath> //数学运算
#include <climits> //INT_MAX最大整型与INT_MIN最小整型
#include <functional> //用于greater<int>()降序排列与less<int>()升序排列
#include <numeric> //accumulate()累加函数
Visual Studio 中如何同时注释多行和取消注释多行?
注释多行:先按 Ctrl - K 组合键,再按 Ctrl - C 组合键
取消注释多行:先按 Ctrl - K 组合键,再按 Ctrl - U 组合键
编程细节
①整型除法与类型转换:
int a =5/2;, 则得到a=2,小数点之后是截断机制,会被直接舍弃。
利用强制类型转换float a =5/float(2);则可以得到保留小数点的结果a=2.5。
C++内置类型的自动转换规则:
按照从高到低的顺序给各种数据类型分等级,依次为:long double, double, float, unsigned long long, long long, unsigned long, long, unsigned int 和 int。在任何涉及两种数据类型的操作中,它们之间等级较低的类型会被转换成等级较高的类型。
此外,在赋值语句中,= 右边的值在赋予 = 左边的变量之前,首先要将右边的值的数据类型转换成左边变量的类型。也就是说,左边变量是什么数据类型,右边的值就要转换成什么数据类型的值。这个过程可能导致右边的值的类型升级,也可能导致其类型降级(demotion)。所谓“降级”,是指等级较高的类型被转换成等级较低的类型。
【易错点】char与int的互相转换:
char类型直接转换成int类型对应的是ASCII码对应的十进制数值,
阿拉伯数字字符对应的十进制数与字符的关系满足:i = int( ch )-48
比如 char ch = ‘0’;
正确的转换方式为 int i = ch-‘0’;
容易错的写法为 int i = int(ch); //得到了ASCII码中字符0对应的十进制数48
int类型转换成char类型需找到阿拉伯数字字符对应的十进制数,然后用类型强制转换符:ch=char( ‘0’ + i )
比如 int i = 0;
正确的写法为 char ch = i +‘0’;
容易错的写法为 char ch = char(i); //二进制重解释,得到了ASCII码中十进制0对应的字符(此处为NUL空字符)
②变量在while循环之内定义的话,每次执行while循环时都会被重置初始化。除非加上static关键字。
比如变量i是在for循环中定义的,作用域在for循环以内,出了该范围则无效。
③关于指针,容易出错的几个点:
ListNode* now,*nex,*p; //每个都要加* , *是跟在变量前的。
ListNode *head = new ListNode();
TreeNode *node = new TreeNode(nums[i]);
queue<TreeNode*> myQueue; //元素为指针类型
stack<TreeNode*> mystack;
1)指针变量的定义形式:
类型说明符 *指针变量名;
例如: float *p1, *p2;
2)指针变量的引用
有两个与指针有关的运算符: &和 *
&是取地址运算符,获取变量所占用的存储单元的首地址。在利用指针变量进行间接访问之前,一般都必须使用该运算符将某变量的地址赋给相应的指针变量。
*是间接访问运算符,通过指针变量来间接访问它所指向的变量
比如:
int a ;
int *p = &a;//地址 &a 是赋值给 p 而不是 *p 的
*p = 3; //将3存入整型变量a中
等价于
int a ;
int* p;
p = &a;//地址 &a 是赋值给 p 而不是 *p 的
*p = 3; //将3存入整型变量a中
int a = 3;
int *p = a;//必须要加取地址符&
④ int main()函数最后容易忘记return 0;
⑤ 做题涉及到求和或者数据偏大时,用long long 数据类型来存贮结果和中间运行过程会好于int ,否则会因为精度卡通过样例。
⑥ 函数参数为字符串时,即使不改变字符串的内容,也最好加个&取地址符,这样可以直接将字符串传递进函数,而不用调用字符串拷贝,节省时间。
同样,需要在函数体内对指针root、vector等参数作出改变时,函数参数也不要忘记加&。
同样,有的编程题还会卡cin>>x>>ch;与scanf("%d%c",&x,&ch);、cout<<x<<ch;与printf("%d、%c\n",x,ch);的时间差。
#include <stdio.h>
int main()
{
char ch = 'A';
char str[20] = "www.runoob.com";
float flt = 10.234;
int no = 150;
double dbl = 20.123456;
printf("字符为 %c \n", ch);
printf("字符串为 %s \n" , str);
printf("浮点数为 %f \n", flt);
printf("整数为 %d\n" , no);
printf("双精度值为 %lf \n", dbl);
printf("八进制值为 %o \n", no);
printf("十六进制值为 %x \n", no);
return 0;
}
输出为:
字符为 A
字符串为 www.runoob.com
浮点数为 10.234000
整数为 150
双精度值为 20.123456
八进制值为 226
十六进制值为 96
printf("%.8d\n",1000); //不足指定宽度补前导0,效果等同于%06d
printf("%.8f\n",1000.123456789);//超过精度,截断
printf("%.8f\n",1000.123456); //不足精度,补后置0
printf("%.8g\n",1000.123456); //最大有效数字为8位
printf("%.8s\n","abcdefghij"); //超过指定长度截断
输出:
00001000
1000.12345679
1000.12345600
1000.1235
abcdefgh
标志:
printf("%5d\n",1000); //默认右对齐,左边补空格
printf("%-5d\n",1000); //左对齐,右边补空格
printf("%+d %+d\n",1000,-1000); //输出正负号
printf("% d % d\n",1000,-1000); //正号用空格替代,负号输出
printf("%x %#x\n",1000,1000); //输出0x
printf("%.0f %#.0f\n",1000.0,1000.0)//当小数点后不输出值时依然输出小数点
printf("%g %#g\n",1000.0,1000.0); //保留小数点后后的0
printf("%05d\n",1000); //前面补0
输出:
1000
1000
+1000 -1000
1000 -1000
3e8 0x3e8
1000 1000.
1000 1000.00
01000
⑦ C++标准输出流换向(cout打印到文件)
cpp中有io流的概念可以采用重定向的方式直接将cout的标准输出重定向到文件中
不常用函数
一些不常用,但是面试比较容易出现的函数:
① explict函数
只能作用于单个参数的构造函数。不能让构造函数传进来的参数发生隐式转换。
进制与位运算
①关于八进制、十进制、十六进制整型常量的一些基础知识:
1,八进制整常数
八进制整常数必须以0开头,即以0作为八进制数的前缀。数码取值为0~7。八进制数通常是无符号数。
以下各数是合法的八进制数: 015(十进制为13) 0101(十进制为65) 0177777(十进制为65535)
以下各数不是合法的八进制数: 256(无前缀0) 03A2(包含了非八进制数码) -0127(出现了负号)
2,十六进制整常数
十六进制整常数的前缀为0X或0x。其数码取值为0-9,A-F或a~f。
以下各数是合法的十六进制整常数: 0X2A(十进制为42) 0XA0 (十进制为160) 0XFFFF (十进制为65535)
以下各数不是合法的十六进制整常数: 5A (无前缀0X) 0X3H (含有非十六进制数码)
3,十进制整常数
十进制整常数没有前缀。其数码为0~9。
以下各数是合法的十进制整常数:237 -568 65535 1627
以下各数不是合法的十进制整常数:023 (不能有前导0) 23D (含有非十进制数码)
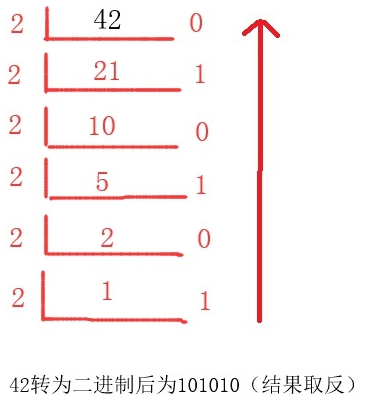
②整数十进制转二进制方法: 除2取余,逆序排列
1.首先用2整除一个十进制整数,得到一个商和余数
2.然后再用2去除得到的商,又会得到一个商和余数
3.重复操作,一直到商为小于1时为止
4.然后将得到的所有余数全部排列起来,再将它反过来(逆序排列),切记一定要反过来!
③二进制减法:1-0=1、10-1=1、101-11=10、1100-111=101

④移位操作
左移一位为乘2: x<<1; //x*2
右移一位为除以2: x>>1 //x/2
移位操作比乘除法更快,需要注意的是移位运算符优先级低,一般需要加括号。
比较常用的是在二分查找中计算中位数:int mid = ((r-l)>>1)+l;
还有就是通过n & (1 << i)是否为1来判断一个数 n 的第 i 位是否为1
举个例子:
1<<20是把1,位左移20位(按二进制来移动)
在32位机中,十进制的1就是 00000000 00000000 00000000 00000001,
位左移20位就是 00000000 00010000 00000000 00000000,也就是十进制的1048576
(1 << 20) – 1是20个1
比如:
unordered_map<char, int> bin = {
{
'A', 0}, {
'C', 1}, {
'G', 2}, {
'T', 3}};
int x = 0;
x = (x << 2) | bin[s[i]]; // bin[ch] 为字符 ch 的对应二进制,与运算
typedef 、#define 、const、static、extern
可以使用 typedef 声明为一个已有的类型取一个新的名字。
typedef int feet;
feet distance;
定义常量:
在 C++ 中,有两种简单的定义常量的方式:
• 使用 #define 预处理器。#define LENGTH 10
• 使用 const 关键字声明指定类型的常量。const int LENGTH = 10;
static 存储类:
static 存储类指示编译器在程序的生命周期内保持局部变量的存在,而不需要在每次它进入和离开作用域时进行创建和销毁。因此,使用 static 修饰局部变量可以在函数调用之间保持局部变量的值。
static int i = 5; // 局部静态变量
static与const的区别:
在类中的static成员变量属于整个类所拥有,对类的所有对象只有一份拷贝;
在类中的static成员函数属于整个类所拥有,这个函数不接收this指针,因而只能访问类的static成员变量。
Static与Const的区别 - 代码驿站 - 博客园
extern 存储类:
extern 是用来在另一个文件中声明一个全局变量或函数。extern 修饰符通常用于当有两个或多个文件共享相同的全局变量或函数的时候,
int count ;
extern int count;
第二个文件中的 extern 关键字用于声明已经在第一个文件 main.cpp 中定义的 count。
ifndef/define/endif的用法与实例分析
用法:
.h文件,如下:
#ifndef XX_H
#define XX_H
……
#endif
这样如果有两个地方都包含这个头文件,就不会出现两次包含的情况,因为在第二次包含时XX_H已经有定义了,所以就不再 include了。
把头文件的内容都放在#ifndef和#endif中吧。不管你的头文件会不会被多个文件引用,你都要加上这个。一般格式是这样的:
#ifndef <标识>
#define <标识>
.....
......
#endif
每个头文件的这个“标识”都应该是唯一的。如stdio.h
#ifndef _STDIO_H_
#define _STDIO_H_
......
#endif
假设你的工程里面有4个文件,分别是a.cpp,b.h,c.h,d.h
a.cpp的头部是:
#include "b.h "
#include "c.h "
b.h和c.h的头部都是:
#include "d.h "
而d.h里面有class D的定义。
这样一来, 编译器编译a.cpp的时候,先根据#include "b.h "去编译b.h文件,再根据 b.h里面的#include "d.h ",去编译d.h的这个文件,这样就把d.h里面的class D编译了;然后再根据a.cpp的第二句#include "c.h ",去编译c.h,最终还是会找到的d.h里面的class D,但是class D之前已经编译过了,所以就会报重定义错误。而加上ifndef/define/endif,就可以防止这种重定义错误。
? : 运算符、for遍历、if else
①条件运算符 ? :,可以用来替代 if…else 语句。
Exp1 ? Exp2 : Exp3;
如果 Exp1 为真,则计算 Exp2 的值
比如:
int x = i >= 0 ? num1[i] - '0' : 0;
②for(元素类型 遍历值:数组/容器)
for(auto a:b)中b为一个容器,效果是利用a遍历并获得b容器中的每一个值,但是a无法影响到b容器中的元素。
for(auto &a:b)中加了引用符号,可以对容器中的内容进行赋值,即可通过对a赋值来做到容器b的内容填充。
如果没有&,每次遍历都会给重新开辟空间存放遍历的值,空间复杂度是O(n),而使用引用的话,即使用同一块空间。同时,引用的情况下可以修改原来的值。比如 for(auto& count: counts)
auto可以改为int、iterator迭代器、[a,b]等类型,比如,遍历整个矩阵matrix:
for (const auto& row: matrix) {
for (int element: row) {
if (element == target) {
...
遍历哈希表:
unordered_map<char, int> mp;
string ret;
for (auto &[ch, num] : vec)
{
for (int i = 0; i < num; i++)
{
ret.push_back(ch);
}
通常我们遍历字符串数组用
for(int i=0;i<array.length;i++)
{
array[i];
}
事实上使用for(String c:valueArray)更加方便,当中valueArray为字符串的数组,c为数组中的每一个字符串变量,直接訪问就可以。
③多个if判断句是所有的if都会进行判断,而if … else if则是只要有满足条件的,就不再对之后的else if进行判断了。
比如:
int a = 2,c;
if(a==1) c=1;
if(a==2) c=2;
if(a%2==0) c=3;
最终结果是c=3
int a = 2,c;
if(a==1) c=1;
else if(a==2) c=2;
else if(a%2==0) c=3;
最终结果是c=2
那么else if与switch case之间的区别如何呢?
switch(a)
{
case 1:
case 2:
case 3:
break;
}
这样switch case就是if if 了,所有满足条件的case都会执行一次
switch(a)
{
case 1:
break;
case 2:
break;
case 3:
break;
}
这样就是else if了,只要满足条件就会跳出。