ControlNet是一种图像生成AI技术,可以在保持输入图像结构不变的情况下,将输入图像转换为另一幅图像,例如可以使用ControlNet来生成通过使用简笔画等3D模型来实现具有指定人物姿势和构图的插图。
在这个过程中ControlNet可以从输入图像中提取轮廓、深度和分割等信息,并根据指令创建图像。因此可以使用ControlNet来将一张人物照片转换为一张美丽的插图,而不会改变人物的结构和特征。
工作原理大致如下:
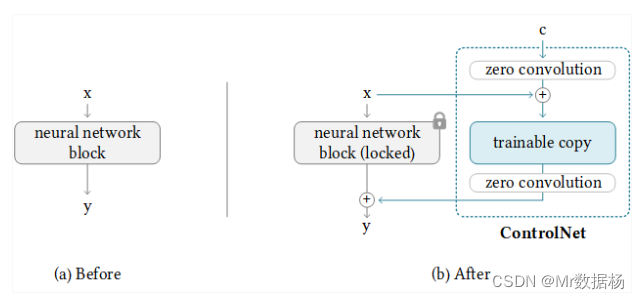
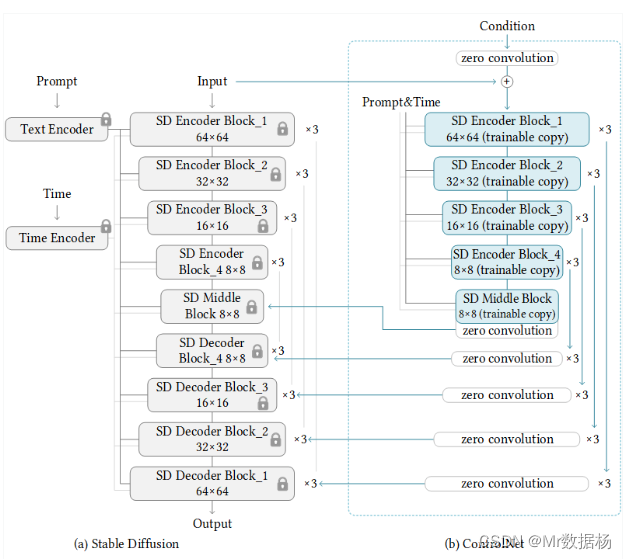
ControlNet是一种可以控制大型预训练扩散模型以适应额外输入条件的技术。如上图所示,扩散模型的神经网络分为两种:固定权重的模型(locked)和复制权重的可训练模型(trainable copy)。
ControlNet可以通过仅在可训练模型上学习附加条件,即使是小数据集也可以高效且有效地进行学习。此外,为了稳定学习并加快学习速度,ControlNet还可以通过向可训练模型添加一个称为零卷积的块,将卷积层的权重初始化为 0。
ControlNet端的神经网络(Unet)的encoder部分被变成了可训练的副本。在输入前,Unet的decoder部分被替换成了零卷积,并与Stable Diffusion端的Unet(固定权重模型)相连接。
安装 Controlnet
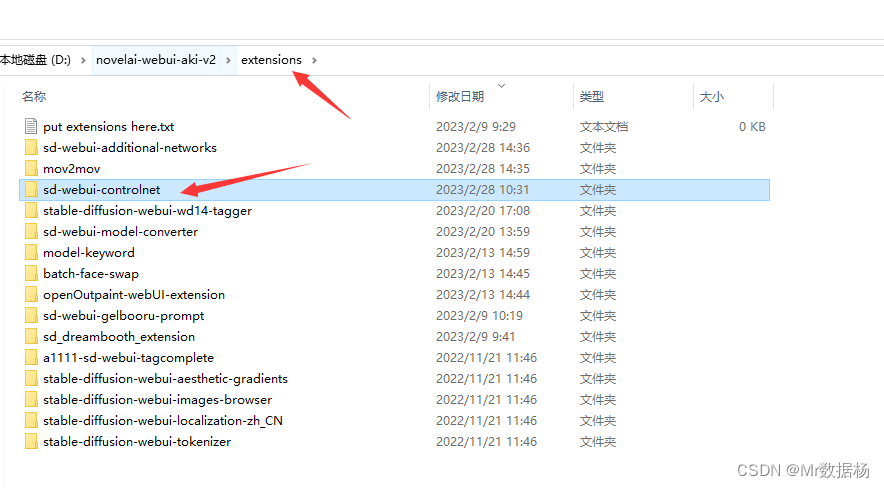
确保自己已经有Stable Diffusion的Web UI版本,在扩展页面进行选择安装即可。点击安装,我这里是安装好的所以会显示installed。

如果自己不是一键集成的Stable Diffusion需要自己在git上进行下载后把项目放入extensions目录下,或者直接执行下面的命令也可以。
git clone https://github.com/Mikubill/sd-webui-controlnet.git
安装好了之后直接重启你的WebUI。
下载 Models
只安装了插件之后是无法直接使用的,需要自己下载对应的插件和模型。下载地址在
下载 annotator/ckpts 下的文件,并放入指定的文件夹,切记别放错了。
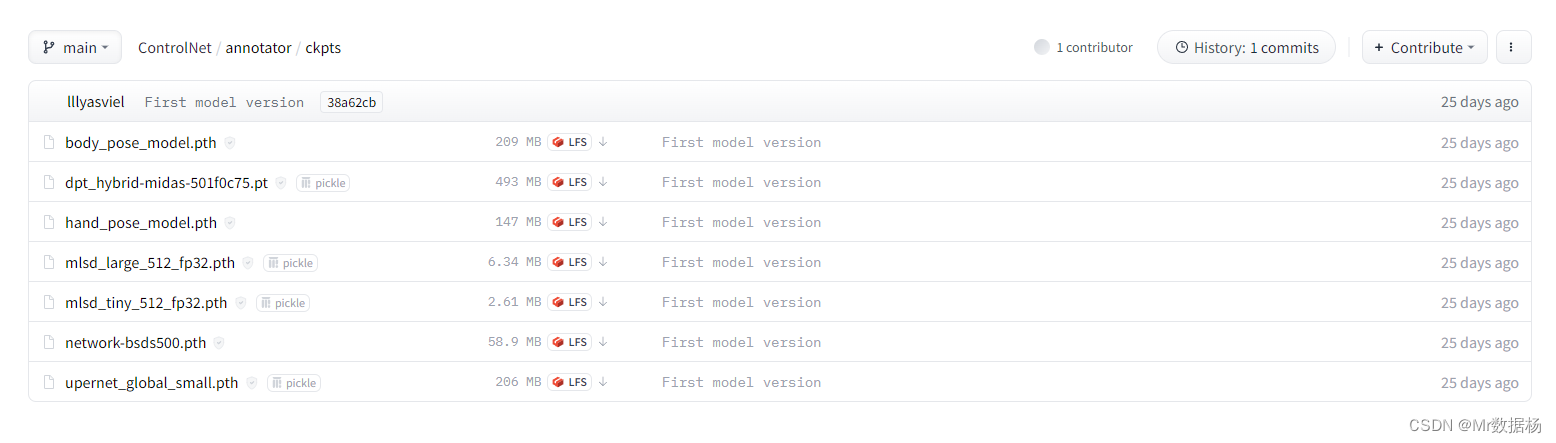
- body_pose_model.pth 放入 …\sd-webui-controlnet\annotator\openpose
- dpt_hybrid-midas-501f0c75.pt 放入 …\sd-webui-controlnet\annotator\midas
- hand_pose_model.pth 放入 …\sd-webui-controlnet\annotator\openpose
- mlsd_large_512_fp32.pth 放入 …\sd-webui-controlnet\annotator\mlsd
- mlsd_tiny_512_fp32.pth 放入 …\sd-webui-controlnet\annotator\mlsd
- network-bsds500.pth 放入 …\sd-webui-controlnet\annotator\hed
- upernet_global_small.pth 放入 …\sd-webui-controlnet\annotator\uniformer
下载 models 下的文件,并放入 sd-webui-controlnet\models 目录下,可能会问有没有阉割版的,不建议使用,还是用原版的比较好一些。
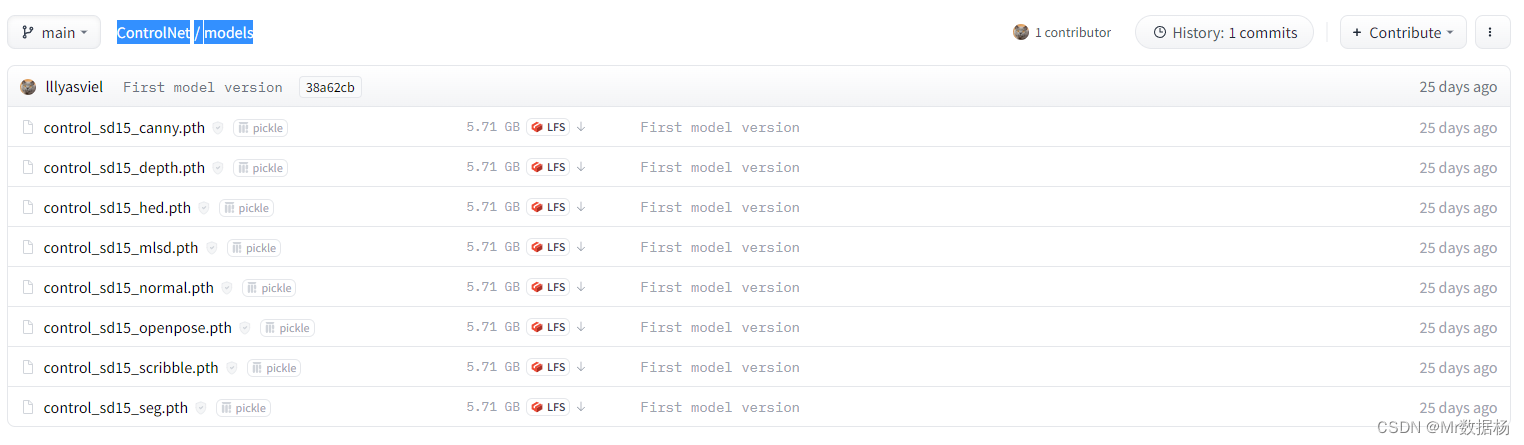
说明 Models
官网的说明机翻大致这样,其实新手看了跟没说一样,一脸懵。
- control_sd15_canny.pth:使用Canny边缘检测控制SD的ControlNet+SD1.5模型。
- control_sd15_depth.pth:使用 Midas 深度估计控制 SD 的 ControlNet+SD1.5 模型。
- control_sd15_hed.pth:ControlNet+SD1.5模型使用HED边缘检测(软边缘)来控制SD。
- control_sd15_mlsd.pth:使用 M-LSD 线检测控制 SD 的 ControlNet+SD1.5 模型(也将与传统霍夫变换一起使用)。
- control_sd15_normal.pth:ControlNet+SD1.5模型使用法线贴图控制SD。最好使用由该 Gradio应用程序生成的法线贴图。只要方向正确,其他法线贴图也可能有效(左边看起来是红色,右边看起来是蓝色,上面看起来是绿色,下面看起来是紫色)。
- control_sd15_openpose.pth:ControlNet+SD1.5模型使用OpenPose姿态检测控制SD。直接操纵姿势骨架也应该有效。
- control_sd15_scribble.pth:ControlNet+SD1.5模型,利用人类涂鸦来控制SD。该模型使用具有非常强数据增强的边界边缘进行训练,以模拟类似于人类绘制的边界线。
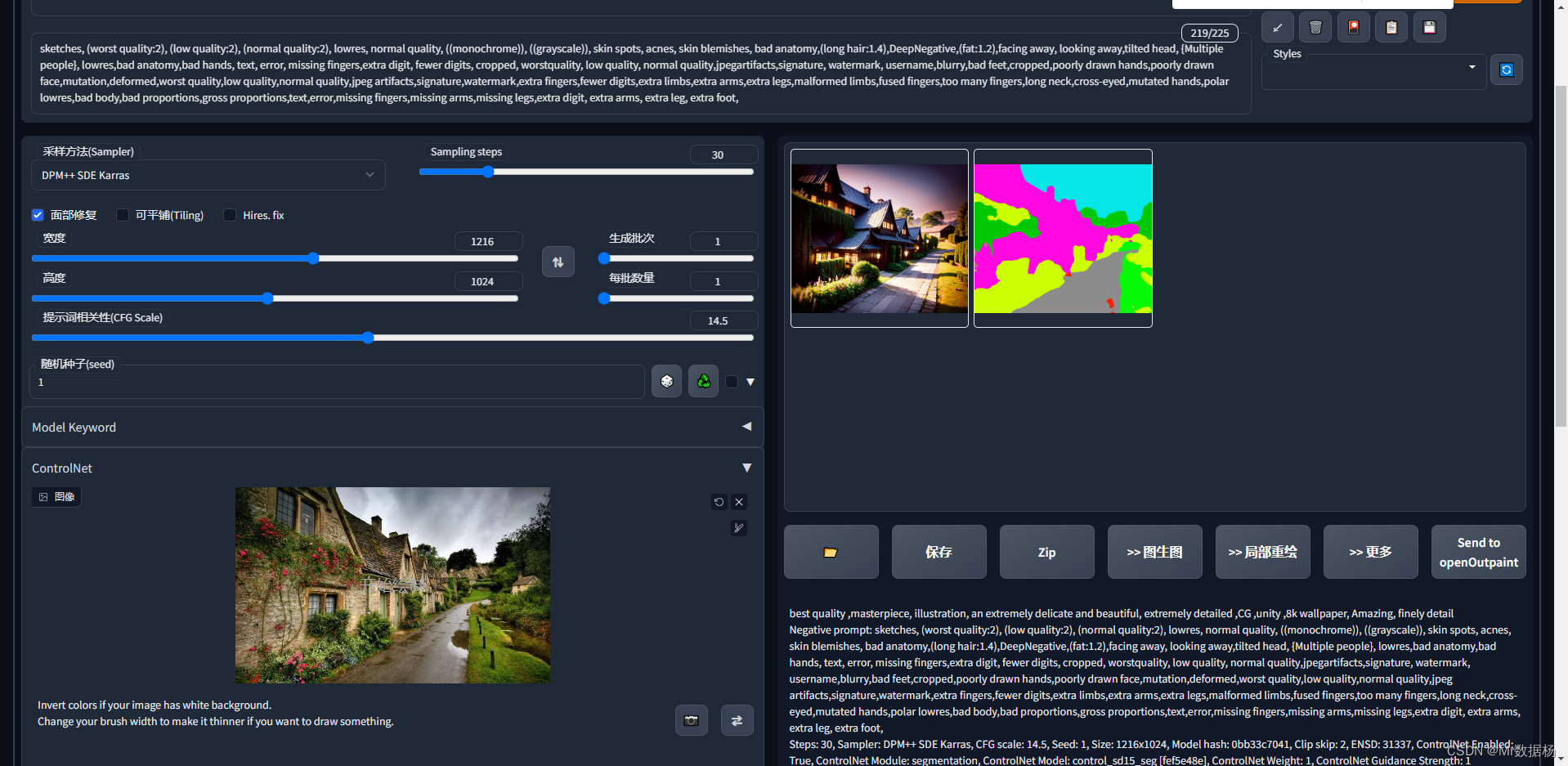
- control_sd15_seg.pth:ControlNet+SD1.5模型使用语义分割控制SD。协议是 ADE20k。
转换成人话之后大致这样,自己理解先,后面会每个举例说明。
| 类别 | 模型名称 |
|---|---|
| 线稿类 | control_sd15_canny |
| - | control_sd15_hed |
| - | control_sd15_scribble |
| - | control_sd15_mlsd |
| 动作类 | control_sd15_openpose |
| 深度类 | control_sd15_depth |
| - | control_sd15_normal |
| 色块类 | control_sd15_seg |
应用模型
这里简单操作一下就是关键词对应的操作方法演示,具体细节自行调试吧。
统一操作
进入WebUI后,打开Control选项卡,按照实例图片拖动到对应位置即可。
对于新手有用的是Preprocessor(图像预处理)和模型,这里建议使用同样的配置,如果有特殊需求在理解完整体使用之后再自行尝试。
如果你显存8G一下记得要点上 Low VRAM。
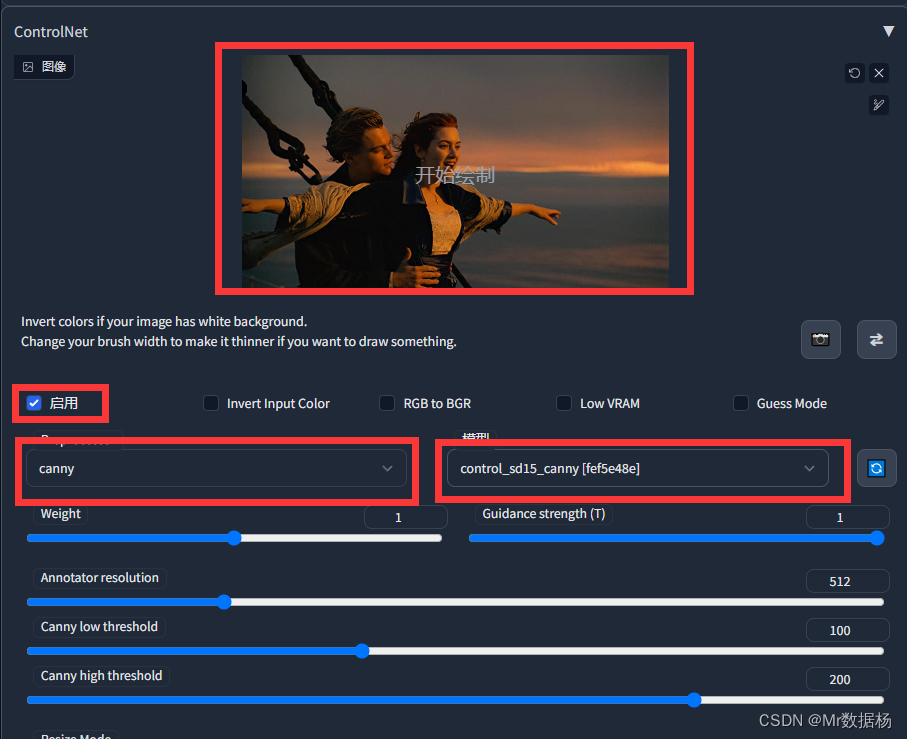
线稿类
control_sd15_canny 边缘线几乎不做改变,适用于局部颜色更改,细致线稿上色。

control_sd15_hed 边缘线轻微变化,算法辅助修形,适用于轻微改图。
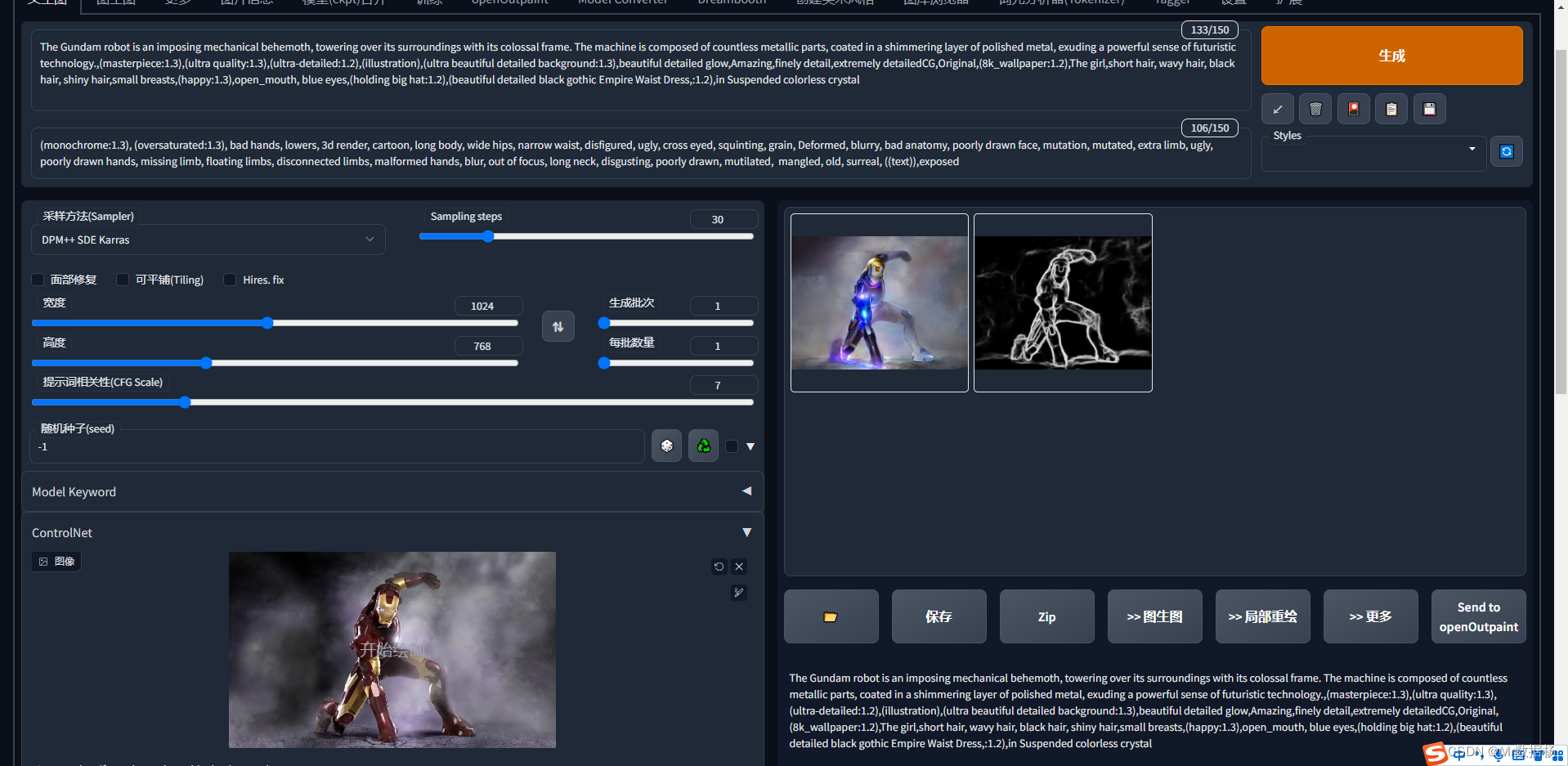

control_sd15_scribble 粗糙线稿(手绘、草稿)一键生图。
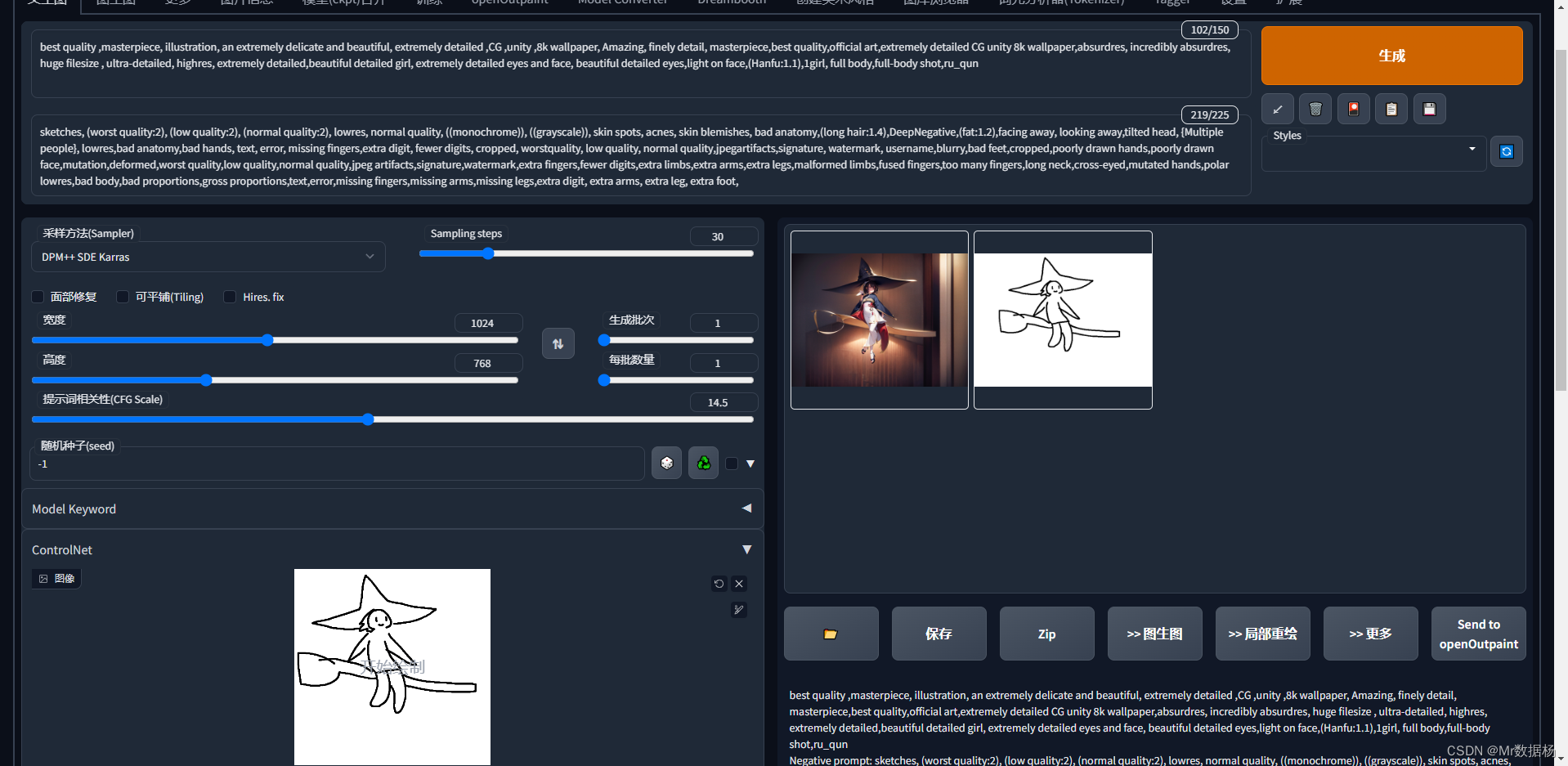

control_sd15_mlsd 直线边缘检测,适用于建筑、直线较多的场景。
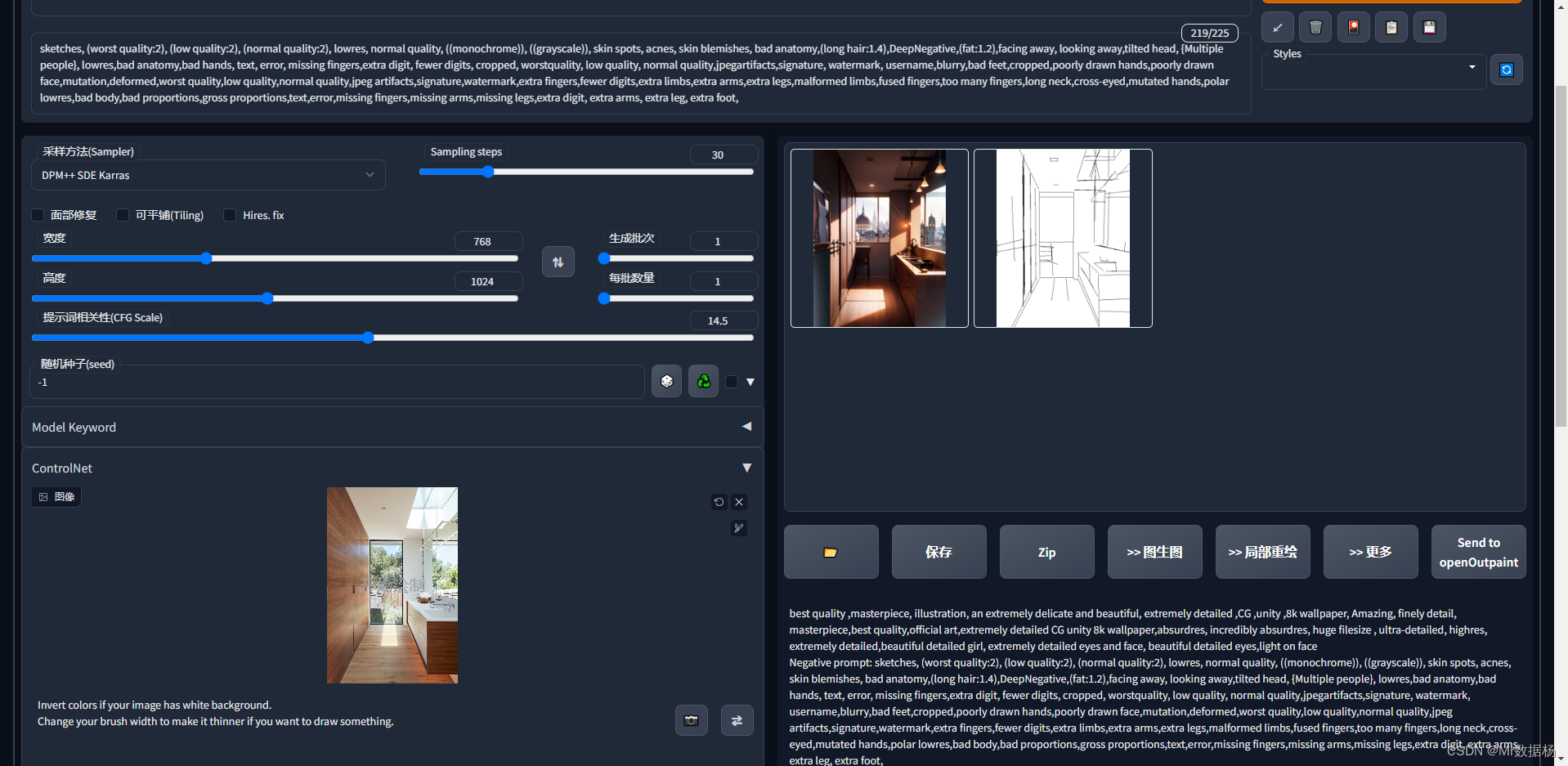

动作类
control_sd15_openpose 骨骼识别,可以设置多人骨骼动作。
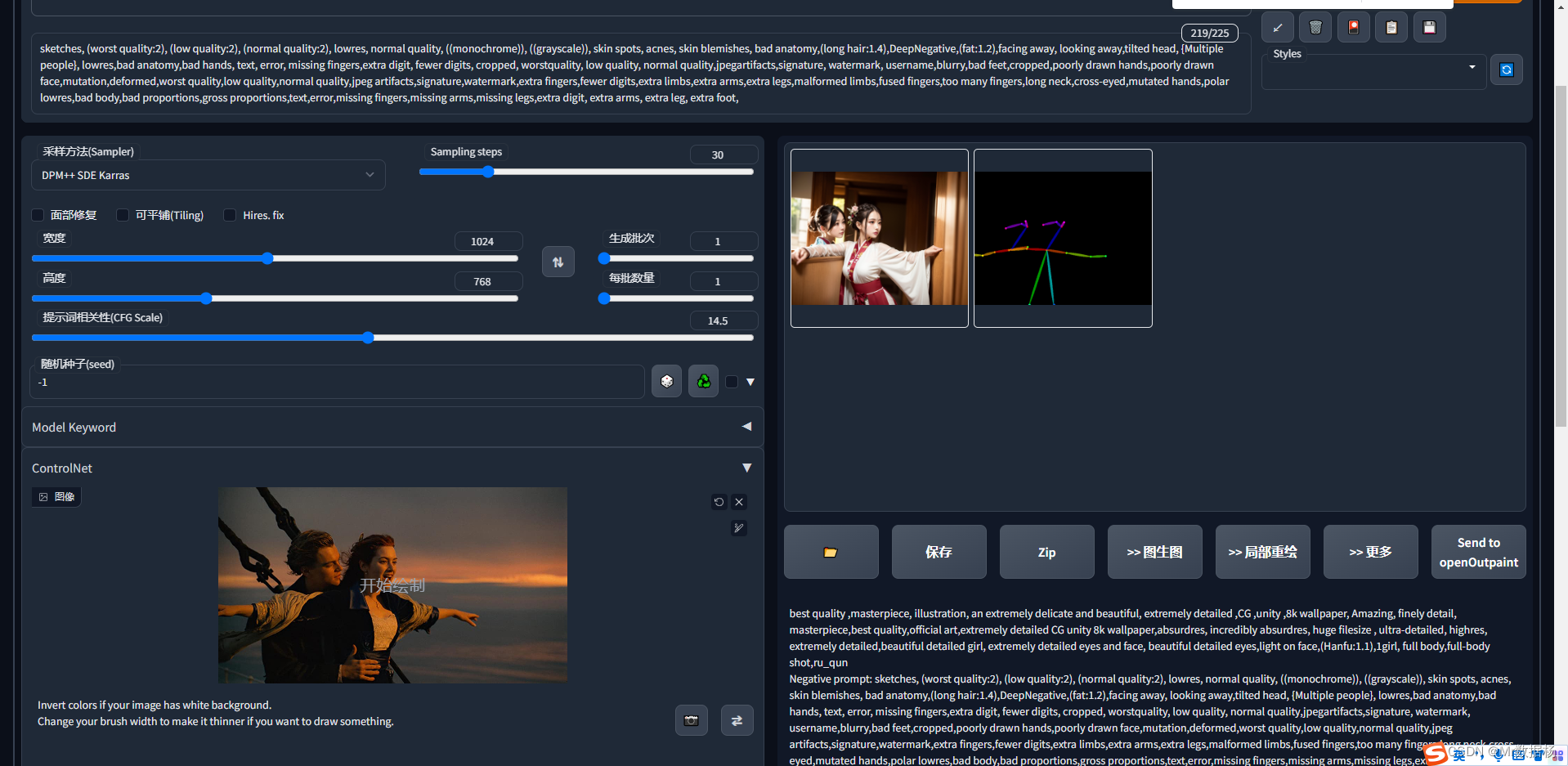

深度类
control_sd15_depth 场景复杂需要体现深度透视关系,用于多人复杂场景。
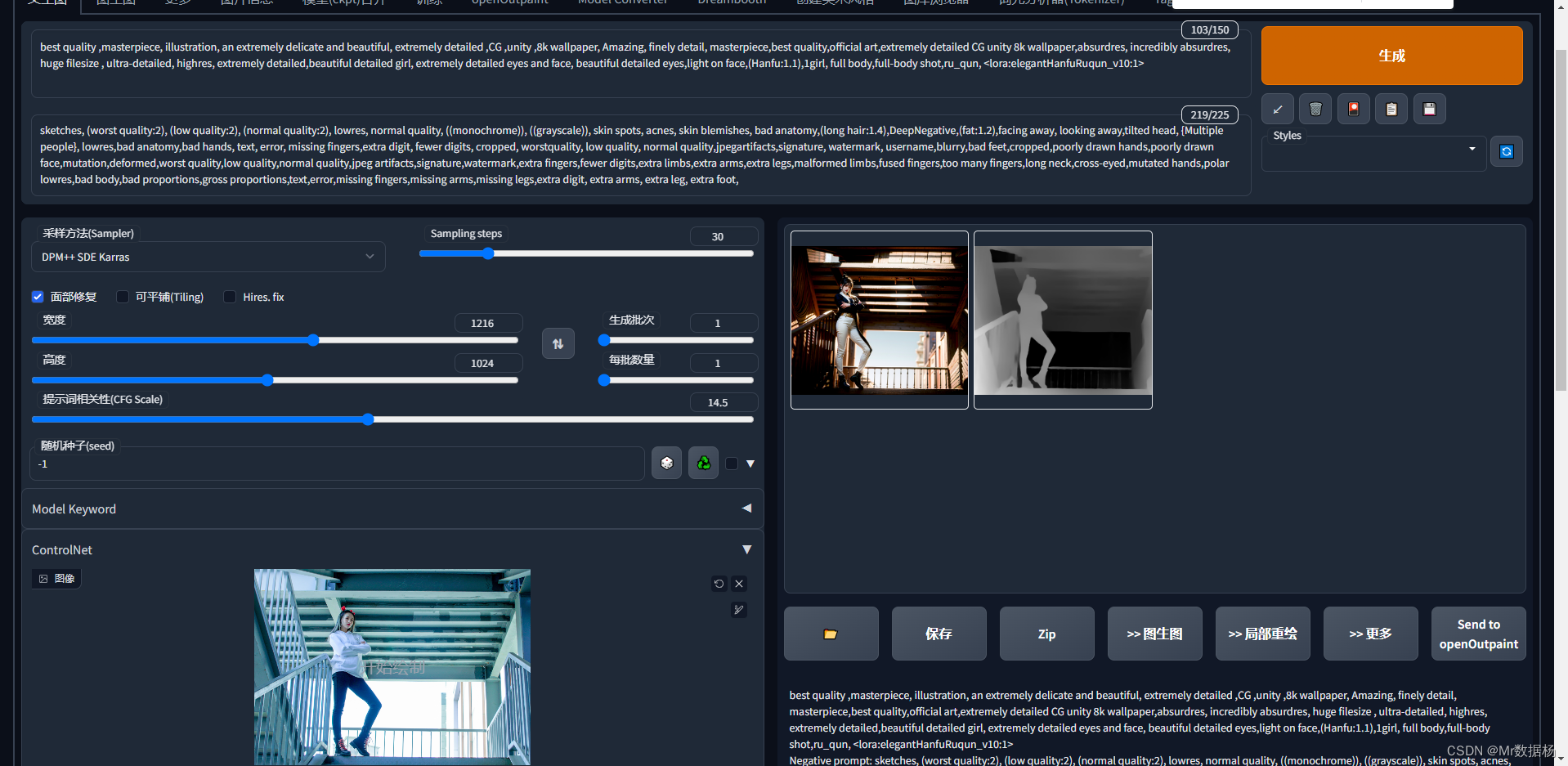

control_sd15_normal 场景简单突出个体使用。
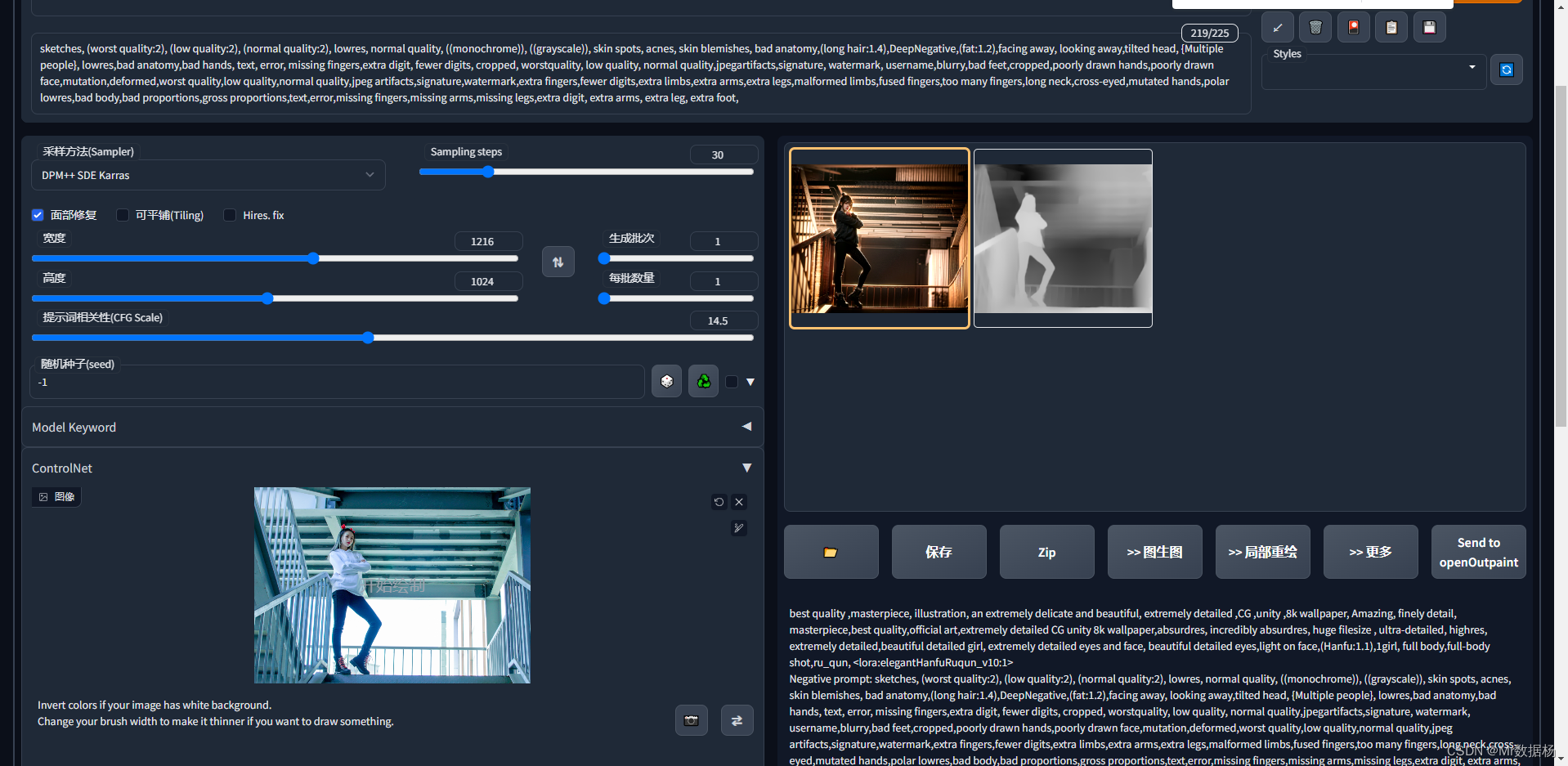

色块类
control_sd15_seg 用于区域标注使用。