A题:
Hacker Zhorik wants to decipher two secret messages he intercepted yesterday. Yeah message is a sequence of encrypted blocks, each of them consists of several bytes of information.
Zhorik knows that each of the messages is an archive containing one or more files. Zhorik knows how each of these archives was transferred through the network: if an archive consists of k files of sizes l1, l2, ..., lk bytes, then the i-th file is split to one or more blocks bi, 1, bi, 2, ..., bi, mi (here the total length of the blocks bi, 1 + bi, 2 + ... + bi, mi is equal to the length of the file li), and after that all blocks are transferred through the network, maintaining the order of files in the archive.
Zhorik thinks that the two messages contain the same archive, because their total lengths are equal. However, each file can be split in blocks in different ways in the two messages.
You are given the lengths of blocks in each of the two messages. Help Zhorik to determine what is the maximum number of files could be in the archive, if the Zhorik's assumption is correct.
Input
The first line contains two integers n, m (1 ≤ n, m ≤ 105) — the number of blocks in the first and in the second messages.
The second line contains n integers x1, x2, ..., xn (1 ≤ xi ≤ 106) — the length of the blocks that form the first message.
The third line contains m integers y1, y2, ..., ym (1 ≤ yi ≤ 106) — the length of the blocks that form the second message.
It is guaranteed that x1 + ... + xn = y1 + ... + ym. Also, it is guaranteed that x1 + ... + xn ≤ 106.
OutputPrint the maximum number of files the intercepted array could consist of.

7 6 2 5 3 1 11 4 4 7 8 2 4 1 8
3
3 3 1 10 100 1 100 10
2
1 4 4 1 1 1 1
1
In the first example the maximum number of files in the archive is 3. For example, it is possible that in the archive are three files of sizes 2 + 5 = 7, 15 = 3 + 1 + 11 = 8 + 2 + 4 + 1 and 4 + 4 = 8.
In the second example it is possible that the archive contains two files of sizes 1 and 110 = 10 + 100 = 100 + 10. Note that the order of files is kept while transferring archives through the network, so we can't say that there are three files of sizes 1, 10 and 100.
In the third example the only possibility is that the archive contains a single file of size 4.
题目大意:
给定两个数列,已知这两个数列总和相同,然后让你分别划分这两个数组,使得第一个数组的第一个子区间和第二个数组的子区间相同(每个区间内数字的个数没有要求必须相同),按照这个规律一直到结束,判断可以划分区间的最大个数。
用到一点动态规划的方法,就是需要记录一下前缀的和
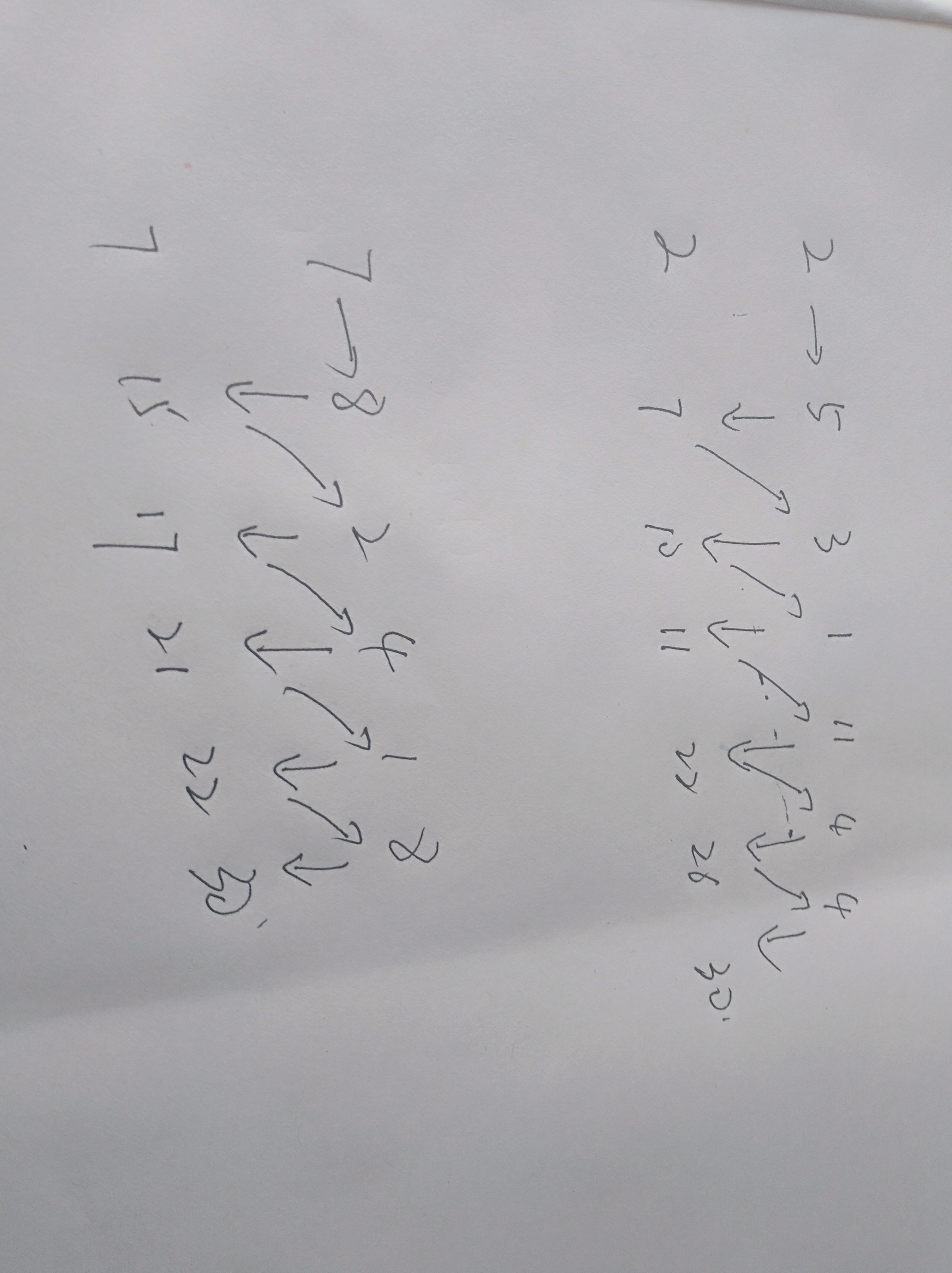
然后在判断一下两个数组的前缀和中相等的有多少,直接输出就可以了。
具体原理:因为题目要求判断相等片段中数目最多的一种,前提是两个数组中总和是相同的,所以可以从第一个开始判断,逐渐往后累加就可以了。
这个是代码:
#include<iostream>
#include<map>
using namespace std;
map<int,int >wakaka;
int main()
{
ios::sync_with_stdio(false);
int n,m;
while( cin>>n>>m)
{
int ans=0;
int tempsave=0;
int tempsum=0;
int temp;
for(int i=1; i<=n; i++)
{
cin>>temp;
tempsum+=temp;
wakaka[tempsum]=1;
}
tempsum=0;
for(int j=1; j<=m; j++)
{
int point=1;
cin>>temp;
tempsum+=temp;
if(wakaka[tempsum]==1)
ans++;
}
cout<<ans<<endl;
}
return 0;
}
但是这个代码交上去超时,具体原因就是每一次输入的时候,数组a都会从头再找一遍,这个是浪费时间的,,,可以学一下数据结构中的map,map的初级使用学起来不算难(高级的我也不会,真的),这个好用。
ac代码:
#include<iostream>
#include<map>
using namespace std;
int main()
{
ios::sync_with_stdio(false);
int n,m;
while(cin>>n>>m)
{
int ans=0;
int tempsave=0;
int tempsum=0;
int temp;
map<int,int >wakaka;
for(int i=1; i<=n; i++)
{
cin>>temp;
tempsum+=temp;
wakaka[tempsum]=1;
}
tempsum=0;
for(int j=1; j<=m; j++)
{
int point=1;
cin>>temp;
tempsum+=temp;
if(wakaka[tempsum]==1)
ans++;
}
cout<<ans<<endl;
}
return 0;
}
B题:
There are some beautiful girls in Arpa’s land as mentioned before.
Once Arpa came up with an obvious problem:
Given an array and a number x, count the number of pairs of indices i, j (1 ≤ i < j ≤ n) such that , where
is bitwise xor operation (see notes for explanation).
Immediately, Mehrdad discovered a terrible solution that nobody trusted. Now Arpa needs your help to implement the solution to that problem.
Input
First line contains two integers n and x (1 ≤ n ≤ 105, 0 ≤ x ≤ 105) — the number of elements in the array and the integer x.
Second line contains n integers a1, a2, ..., an (1 ≤ ai ≤ 105) — the elements of the array.
OutputPrint a single integer: the answer to the problem.
Examples2 3 1 2
1
6 1 5 1 2 3 4 1
2
大意:一开始给定两个数,第一个数是代表接下来要输入的数的个数,第二个数x代表是符合条件的数。这个符合条件的数指的是
满足 a(i)^a(j)=x这个条件的数。注意这个地方,"^"并不是次方的意思,这个是二进制中的一个运算符,叫异或运算符(刚百度的)。
运行原理如下:
第一组样例: 1 和2,1的二进制是00001,2的二进制是00010,那么这个运算符的作用就是,从最后一位开始比,只要相比的两位数中不全为零,这一位数运算后的结果就是一,也就是说满足两个数最后一位分别是0和1,或者是1和0,那么0^1的结果就是1。
多举几个例子:0^1=1,1^1=0,2^1=11(2的二进制是00010,一的二进制是00001,从最后一位开始比,就是00011),3^4=111。前面的0无所谓的,只要后面的数能对起来就行。
再拓展一下:存在a,b,c,使得a=b^c成立,那么就会有b=a^c成立,这个大家可以自己推一下,能推出来的。
然后再说一下这个题的做题思路:输入一个数后,然后再寻找是否有满足题目条件的数,如果有就算上一个,然后循环就可以了。
ac代码:
#include<iostream>
#include<map>
using namespace std;
int main()
{
int n,m;
while(cin>>n>>m)
{
map<long long,long long >wakaka;
int temp1,temp2;
int cnt=0;
for(int i=1; i<=n; i++)
{
cin>>temp1;
cnt+=wakaka[temp1];
wakaka[temp1^m]++;
}
cout<<cnt<<endl;
}
return 0;
}