PyCorrector中文文本纠错实战
PyCorrector纠错工具实践和代码详解- 模型调参
demo
1. 简介
中文文本纠错工具。音似、形似错字(或变体字)纠正,可用于中文拼音、笔画输入法的错误纠正。python3.6开发。
pycorrector依据语言模型检测错别字位置,通过拼音音似特征、笔画五笔编辑距离特征及语言模型困惑度特征纠正错别字。
1.1 在线Demo
https://www.borntowin.cn/product/corrector
1.2 Question
中文文本纠错任务,常见错误类型包括:
- 谐音字词,如 配副眼睛-配副眼镜
- 混淆音字词,如 流浪织女-牛郎织女
- 字词顺序颠倒,如 伍迪艾伦-艾伦伍迪
- 字词补全,如 爱有天意-假如爱有天意
- 形似字错误,如 高梁-高粱
- 中文拼音全拼,如 xingfu-幸福
- 中文拼音缩写,如 sz-深圳
- 语法错误,如 想象难以-难以想象
当然,针对不同业务场景,这些问题并不一定全部存在,比如输入法中需要处理前四种,搜索引擎需要处理所有类型,语音识别后文本纠错只需要处理前两种,
其中’形似字错误’主要针对五笔或者笔画手写输入等。
1.3 Solution
1.3.1 规则的解决思路
- 中文纠错分为两步走,第一步是错误检测,第二步是错误纠正;
- 错误检测部分先通过结巴中文分词器切词,由于句子中含有错别字,所以切词结果往往会有切分错误的情况,这样从字粒度和词粒度两方面检测错误,
整合这两种粒度的疑似错误结果,形成疑似错误位置候选集; - 错误纠正部分,是遍历所有的疑似错误位置,并使用音似、形似词典替换错误位置的词,然后通过语言模型计算句子困惑度,对所有候选集结果比较并排序,得到最优纠正词。
1.3.2 深度模型的解决思路
- 端到端的深度模型可以避免人工提取特征,减少人工工作量,RNN序列模型对文本任务拟合能力强,rnn_attention在英文文本纠错比赛中取得第一名成绩,证明应用效果不错;
- CRF会计算全局最优输出节点的条件概率,对句子中特定错误类型的检测,会根据整句话判定该错误,阿里参赛2016中文语法纠错任务并取得第一名,证明应用效果不错;
- seq2seq模型是使用encoder-decoder结构解决序列转换问题,目前在序列转换任务中(如机器翻译、对话生成、文本摘要、图像描述)使用最广泛、效果最好的模型之一。
1.4 Feature
1.4.1 模型
- kenlm:kenlm统计语言模型工具
- rnn_attention模型:参考Stanford University的nlc模型,该模型是参加2014英文文本纠错比赛并取得第一名的方法
- rnn_crf模型:参考阿里巴巴2016参赛中文语法纠错比赛CGED2018并取得第一名的方法(整理中)
- seq2seq_attention模型:在seq2seq模型加上attention机制,对于长文本效果更好,模型更容易收敛,但容易过拟合
- transformer模型:全attention的结构代替了lstm用于解决sequence to sequence问题,语义特征提取效果更好
- bert模型:中文fine-tuned模型,使用MASK特征纠正错字
- conv_seq2seq模型:基于Facebook出品的fairseq,北京语言大学团队改进ConvS2S模型用于中文纠错,在NLPCC-2018的中文语法纠错比赛中,是唯一使用单模型并取得第三名的成绩
1.4.2 错误检测
- 字粒度:语言模型困惑度(ppl)检测某字的似然概率值低于句子文本平均值,则判定该字是疑似错别字的概率大。
- 词粒度:切词后不在词典中的词是疑似错词的概率大。
1.4.3 错误纠正
- 通过错误检测定位所有疑似错误后,取所有疑似错字的音似、形似候选词,
- 使用候选词替换,基于语言模型得到类似翻译模型的候选排序结果,得到最优纠正词。
1.4.4 思考
- 现在的处理手段,在词粒度的错误召回还不错,但错误纠正的准确率还有待提高,更多优质的纠错集及纠错词库会有提升,我更希望算法上有更大的突破。
- 另外,现在的文本错误不再局限于字词粒度上的拼写错误,需要提高中文语法错误检测(CGED, Chinese Grammar Error Diagnosis)及纠正能力,列在TODO中,后续调研。
2. 安装
作者开源代码中介绍有两种安装方式:
pip安装
pip install pycorrector
用户:适合做工程实践,不关心算法细节,直接调包使用。
- 源码安装
git clone https://github.com/shibing624/pycorrector.git
cd pycorrector
python setup.py install
用户:希望了解代码实现,做一些深层次修改。
2.1 源码安装步骤详解
我们详细讲解第二种-源码安装方式。除了完成上面源码安装步骤外,我们还需要安装一些必要的库。
2.1.1 安装必要的库
pip install -r requirements.txt
2.1.2 安装kenlm
kenlm是一个统计语言模型的开源工具,如图所示,代码96%都是C++实现的,所以效率极高,训练速度快,在GitHub上现有1.1K Star
pip安装kenlm
安装命令如下
pip install kenlm
- 笔者尝试直接
pip安装,报了如下错误,机器环境(MAC OS 10.15.4)。

若报错,则进行如下源码安装kenlm,安装成功则跳过该步骤。
源码安装kenlm
-
运行安装命令
python setup.py install
如下图所示,则已经安装成功。
3. 环境测试
3.1 源码结构
代码结构如下(clone时间2020/5/5):
.
├── LICENSE
├── README.md
├── _config.yml
├── build
│ ├── bdist.macosx-10.7-x86_64
│ └── lib
├── dist
│ └── pycorrector-0.2.7-py3.6.egg
├── docs
│ ├── git_image
│ ├── logo.svg
│ └── 基于深度学习的中文文本自动校对研究与实现.pdf
├── examples
│ ├── base_demo.py
│ ├── detect_demo.py
│ ├── disable_char_error.py
│ ├── en_correct_demo.py
│ ├── load_custom_language_model.py
│ ├── my_custom_confusion.txt
│ ├── traditional_simplified_chinese_demo.py
│ └── use_custom_confusion.py
├── pycorrector
│ ├── __init__.py
│ ├── __main__.py
│ ├── __pycache__
│ ├── bert
│ ├── config.py
│ ├── conv_seq2seq
│ ├── corrector.py
│ ├── data
│ ├── deep_context
│ ├── detector.py
│ ├── en_spell.py
│ ├── seq2seq_attention
│ ├── transformer
│ ├── utils
│ └── version.py
├── pycorrector.egg-info
│ ├── PKG-INFO
│ ├── SOURCES.txt
│ ├── dependency_links.txt
│ ├── not-zip-safe
│ ├── requires.txt
│ └── top_level.txt
├── requirements-dev.txt
├── requirements.txt
├── setup.py
└── tests
├── bert_corrector_test.py
├── char_error_test.py
├── confusion_test.py
├── conv_s2s_interactive_demo.py
├── corrector_test.py
├── detector_test.py
├── en_spell_test.py
├── error_correct_test.py
├── eval_test.py
├── file_correct_test.py
├── fix_bug.py
├── kenlm_test.py
├── memory_test.py
├── ner_error_test.py
├── ngram_words.txt
├── speed_test.py
├── test_file.txt
├── tokenizer_test.py
├── trigram_test.py
├── util_test.py
└── word_error_test.py
3.2 运行examples
源码中examples文件夹中放置了大量的demo,我们可以首先我们先运行几个demo测试下效果。
3.2.1 运行base_demo.py文件
代码很简单,调用了
pycorrector.correct方法进行纠错,入参是待纠错的语句,输出是原句和出错的词以及纠正的词,和具体位置。
import sys
sys.path.append("..")
import pycorrector
pycorrector.set_log_level('INFO')
if __name__ == '__main__':
corrected_sent, detail = pycorrector.correct('少先队员因该为老人让坐')
print(corrected_sent, detail)
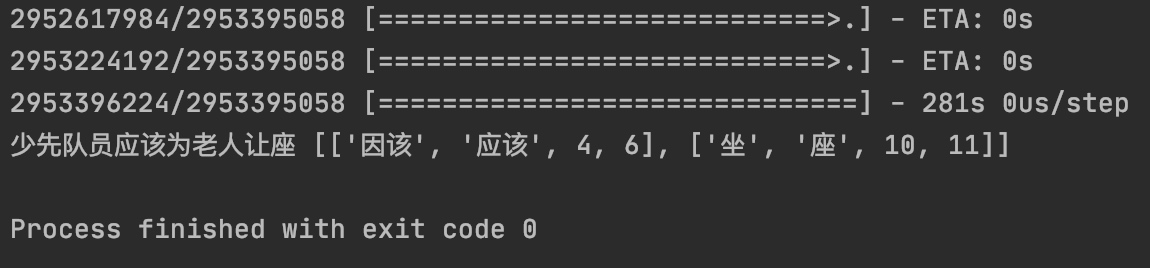
第一次运行,讲下载预设的语料,大概需要10分钟

下载完之后,讲可以进行语义纠错,如下图,
因该->应该,坐标在第4位到第6位,同理,另外一个坐->座,坐标在第10位到第11位。
接下来,读一读代码,理一理逻辑。
4. 代码详解:
项目源码位于pycorrector/pycorrector文件夹中
.
├── bert
├── config.py
├── conv_seq2seq
├── corrector.py
├── data
├── deep_context
├── detector.py
├── en_spell.py
├── seq2seq_attention
├── transformer
├── utils
└── version.py
4.1 传统规则模型
模型代码对应于如下三个文件:
.
├── corrector.py
├── detector.py
└── en_spell.py
| 文件名 | 作用 |
|---|---|
corrector.py |
拼写和笔画纠正 |
detector.py |
错误词检测器 |
en_spell.py |
英语纠正 |
4.1.1 错误词检测器(Detector)
4.1.1.1 代码结构介绍
detector.py中包含一个Detector类,通过初始化这个类,来获得实例,进行错误词的检测。如图所示,初始化的时候,我们可以设置很多配置文件的路径,比如停用词文件(stopwords_path)和自定义词频文件(custom_word_freq_path)等。
Detector类的基础关系如下图所示:
其中Object是基类,提供常用的类方法:
Detector继承了Object类,并且实现了错词检测的基本方法,如下图所示:
4.1.1.2 错词检测类实例化
当去实例化Detector类的时候,只会保存一些基本诸如文件路径和配置参数的值,并不会立即加载模型进行初始化。
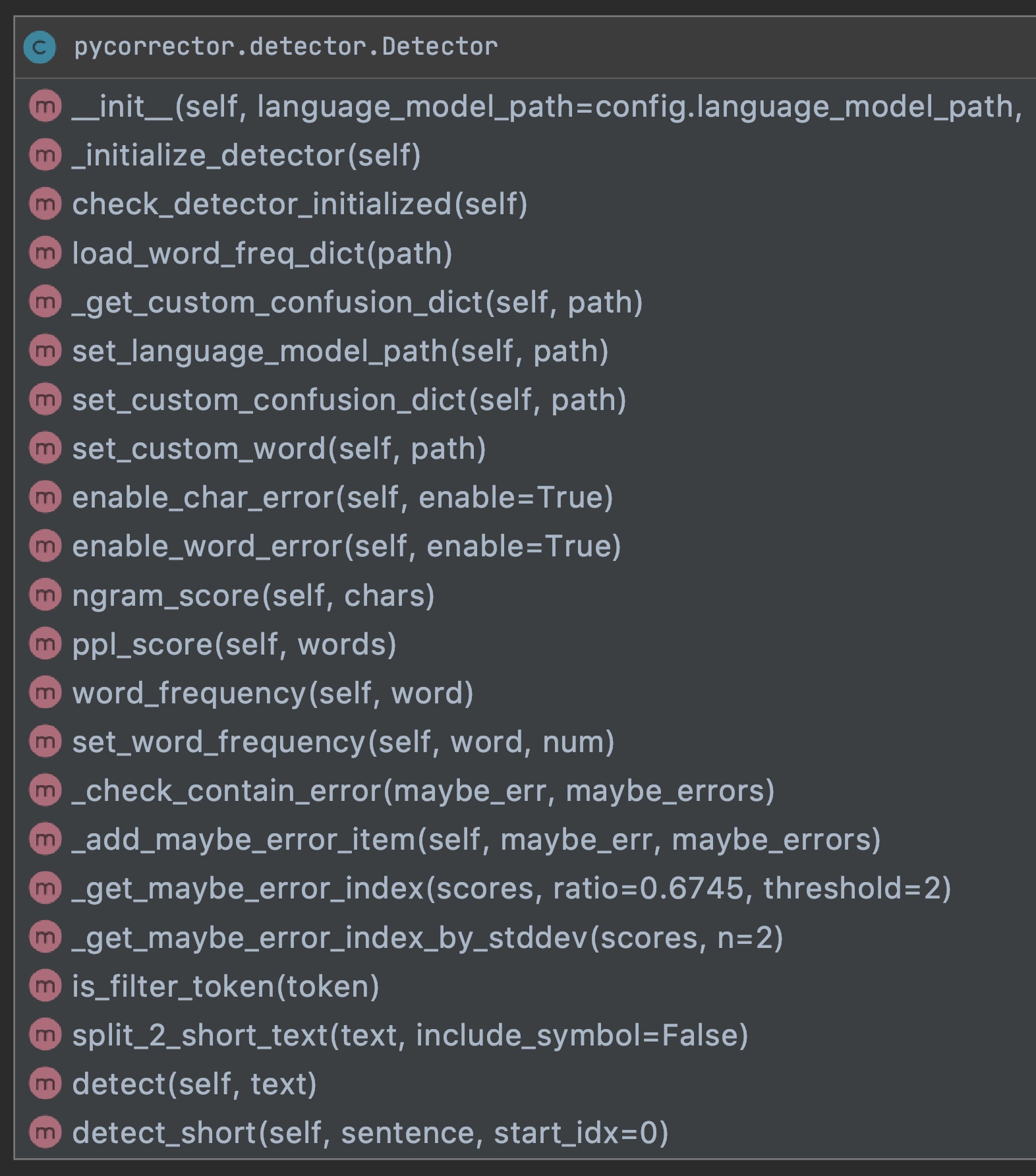
class Detector(object):
pre_trained_language_models = {
# 语言模型 2.95GB
'zh_giga.no_cna_cmn.prune01244.klm': 'https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm',
# 人民日报训练语言模型 20MB
'people_chars_lm.klm': 'https://www.borntowin.cn/mm/emb_models/people_chars_lm.klm'
}
def __init__(self, language_model_path=config.language_model_path,
word_freq_path=config.word_freq_path,
custom_word_freq_path=config.custom_word_freq_path,
custom_confusion_path=config.custom_confusion_path,
person_name_path=config.person_name_path,
place_name_path=config.place_name_path,
stopwords_path=config.stopwords_path):
self.name = 'detector'
self.language_model_path = language_model_path
self.word_freq_path = word_freq_path
self.custom_word_freq_path = custom_word_freq_path
self.custom_confusion_path = custom_confusion_path
self.person_name_path = person_name_path
self.place_name_path = place_name_path
self.stopwords_path = stopwords_path
self.is_char_error_detect = True
self.is_word_error_detect = True
self.initialized_detector = False
self.lm = None
self.word_freq = None
self.custom_confusion = None
self.custom_word_freq = None
self.person_names = None
self.place_names = None
self.stopwords = None
self.tokenizer = None
4.1.1.2 错词检测类初始化
初始化操作被放到_initialize_detector函数中,通过check_detector_initialized来判断是否需要进行初始化。
def _initialize_detector(self):
t1 = time.time()
try:
import kenlm
except ImportError:
raise ImportError('pycorrector dependencies are not fully installed, '
'they are required for statistical language model.'
'Please use "pip install kenlm" to install it.'
'if you are Win, Please install kenlm in cgwin.')
if not os.path.exists(self.language_model_path):
filename = self.pre_trained_language_models.get(self.language_model_path,
'zh_giga.no_cna_cmn.prune01244.klm')
url = self.pre_trained_language_models.get(filename)
get_file(
filename, url, extract=True,
cache_dir=config.USER_DIR,
cache_subdir=config.USER_DATA_DIR,
verbose=1
)
self.lm = kenlm.Model(self.language_model_path)
t2 = time.time()
logger.debug('Loaded language model: %s, spend: %.3f s.' % (self.language_model_path, t2 - t1))
# 词、频数dict
self.word_freq = self.load_word_freq_dict(self.word_freq_path)
# 自定义混淆集
self.custom_confusion = self._get_custom_confusion_dict(self.custom_confusion_path)
# 自定义切词词典
self.custom_word_freq = self.load_word_freq_dict(self.custom_word_freq_path)
self.person_names = self.load_word_freq_dict(self.person_name_path)
self.place_names = self.load_word_freq_dict(self.place_name_path)
self.stopwords = self.load_word_freq_dict(self.stopwords_path)
# 合并切词词典及自定义词典
self.custom_word_freq.update(self.person_names)
self.custom_word_freq.update(self.place_names)
self.custom_word_freq.update(self.stopwords)
self.word_freq.update(self.custom_word_freq)
self.tokenizer = Tokenizer(dict_path=self.word_freq_path, custom_word_freq_dict=self.custom_word_freq,
custom_confusion_dict=self.custom_confusion)
t3 = time.time()
logger.debug('Loaded dict file, spend: %.3f s.' % (t3 - t2))
self.initialized_detector = True
def check_detector_initialized(self):
if not self.initialized_detector:
self._initialize_detector()
4.1.1.3 初始化调用
当进行模型或者自定义词表等设置的开头,都会调用check_detector_initialized进行初始化设置的检测,进行配置文件的加载。
在进行n元文分数计算和词频统计时候,也先检测是否初始化。
另外在核心功能,错词检测的时候,均会进行初始化:
4.1.1.4 错词检测
当进行错词检测的时候,先拿到实例化后的对象,然后调用detect类方法进行检测。
detect类方法中,入参为待检测文本,然后将依次序进行如下处理:
- 空字符判断
- 初始化
- 编码统一
- 文本归一化
- 长句切分为短句
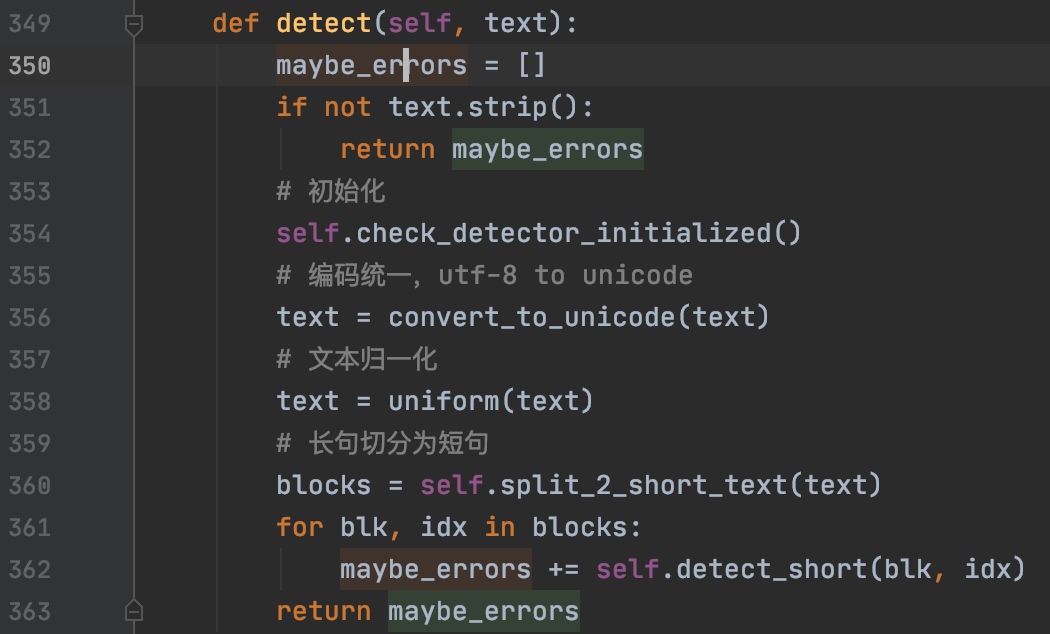
然后对于每个短句,调用detect_short方法进行错词检测,然后会依次对短文本进行错词搜索。
搜索分3种,依次进行。
- 混淆集匹配
- 词级别搜索
- 字级别搜索
混淆集匹配
直接在句子中遍历是否在混淆集中有出现,出现则直接添加到错误列表中。严格的匹配逻辑,可以通过修改混淆集文件,进行词的添加删除。
词级别搜索
依次进行切词,然后遍历每个词,若词不在词典中,也认为是错误。这类词包括一些实体,一些错词,一些没有在词典中出现过,但是是正确的词等。这条规则比较严格,错词不放过,但是也错杀了一些其他正确词。但是优点同第一,可以灵活修改词典。因此,这步需要一个好的预先构造的词典。
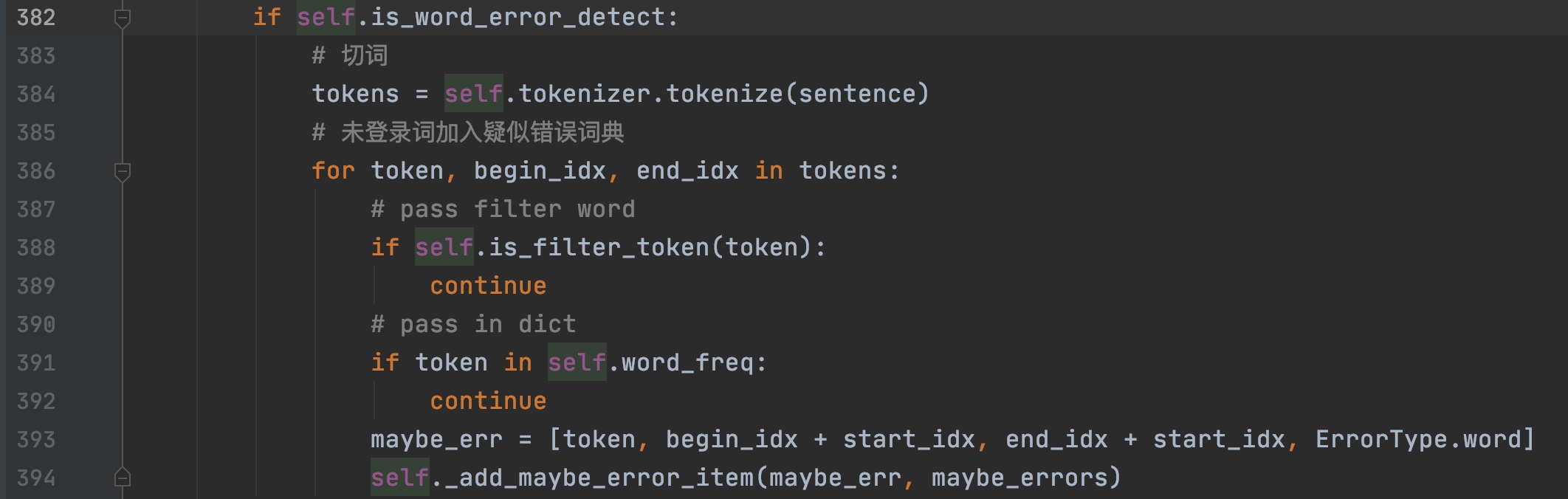
字级别搜索
与词级别搜索不同,字级别不需要进行切词,依次进行打分。分数由一个基于人民日报语料预训练好的语言模型得出。
具体计算步骤如下:
- 计算基于字的2-gram和3-gram的得分列表,二者取平均得到sent的每个字的分数。
- 根据每个字的平均得分列表,找到可能的错误字的位置。
根据每个字的平均得分列表,找到可能的错误字的位置(self._get_maybe_error_index);因此,这里要考虑找错的具体逻辑。代码中的实现是基于类似平均绝对离差(MAD)的统计概念,这里也是一个策略上的改进的方向,甚至多种策略的共同组合判断。
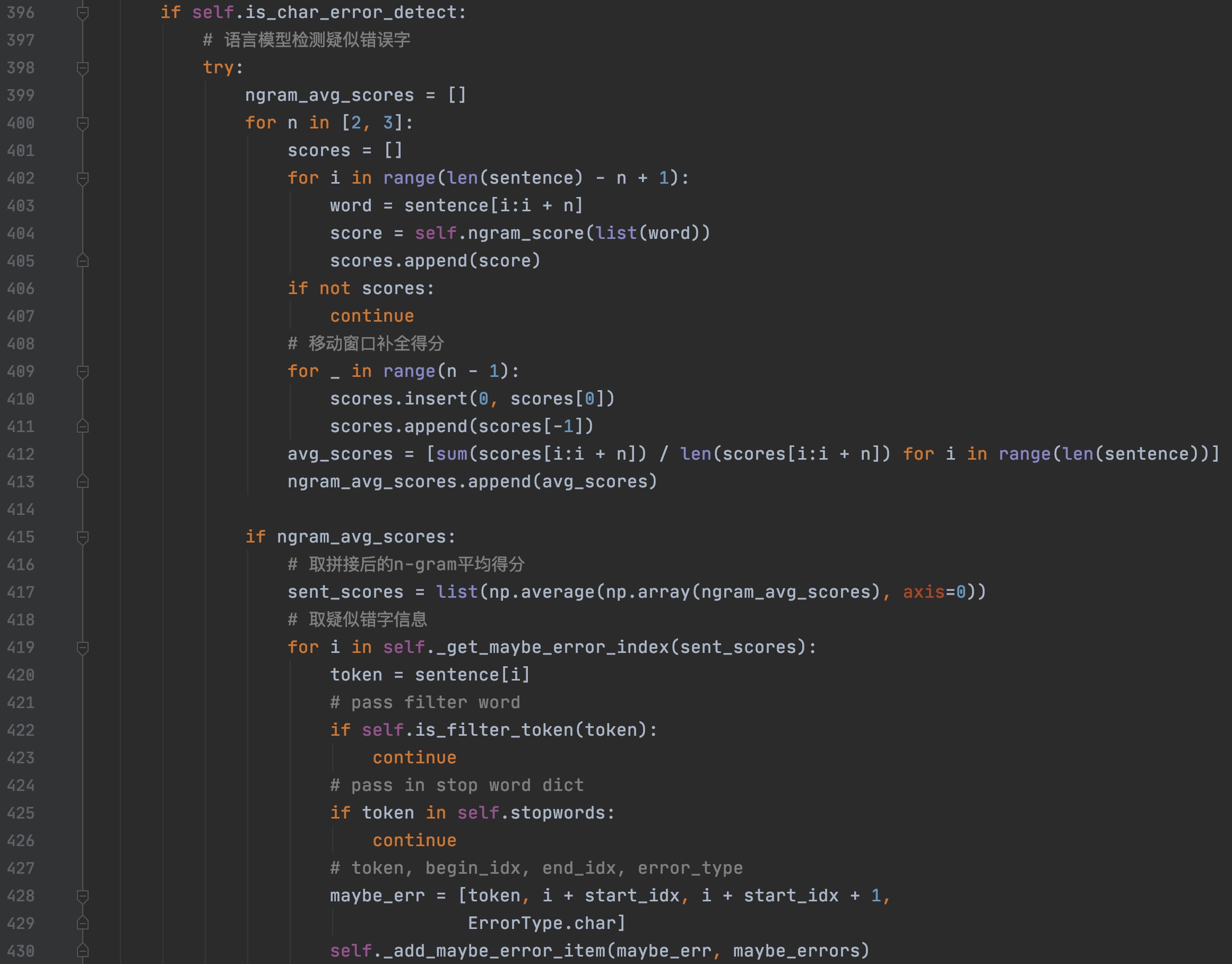
其中MAD的计算如下:
代码中的实际计算不同与上述方式,以代码实现为主。这里可以抽象出的一个问题是:输入是一个得分列表,输出是错误位置。能否通过learning的方式获得一个最优策略。
最后的结果是上述三种情况的并集。
接下来就是候选集的构造了(self.generate_items)。分情况讨论如下:
第一种情况:confusion,如果是自定义混淆集中的错误,直接修改为对应的正确的值就可以了。
第二种情况:对于word和char两种情况,没有对应的正确的值,就需要通过语言模型来从候选集中找了。
候选集的构造逻辑如下,输入是item,也就是检错阶段得到的可能的错误词。首先,同音字和形近字表共同可以构建一个基于字的混淆集(confusion_char_set)。其次,借助于常用字表和item之间的编辑距离,可以构建一个比较粗的候选词集,通过常用词表可以做一个过滤,最后加上同音的限制条件,可以得到一个更小的基于词的混淆集(confusion_word_set)。最后,还有一个自定义的混淆集(confusion_custom _set)。
有了上述的表,就可以构建候选集了。通过候选词的长度来分情况讨论:
第一:长度为1。直接利用基于字的混淆集来替换。
第二:长度为2。分别替换每一个字。
第三:长度为3。同上。
最后,合并所有的候选集。那么通过上述的构造过程,可能导致一些无效词或者字的出现,因此要做一些过滤处理,最后按照选出一些候选集的子集来处理。代码中的规则是基于词频来处理,选择topk个词作为候选集。
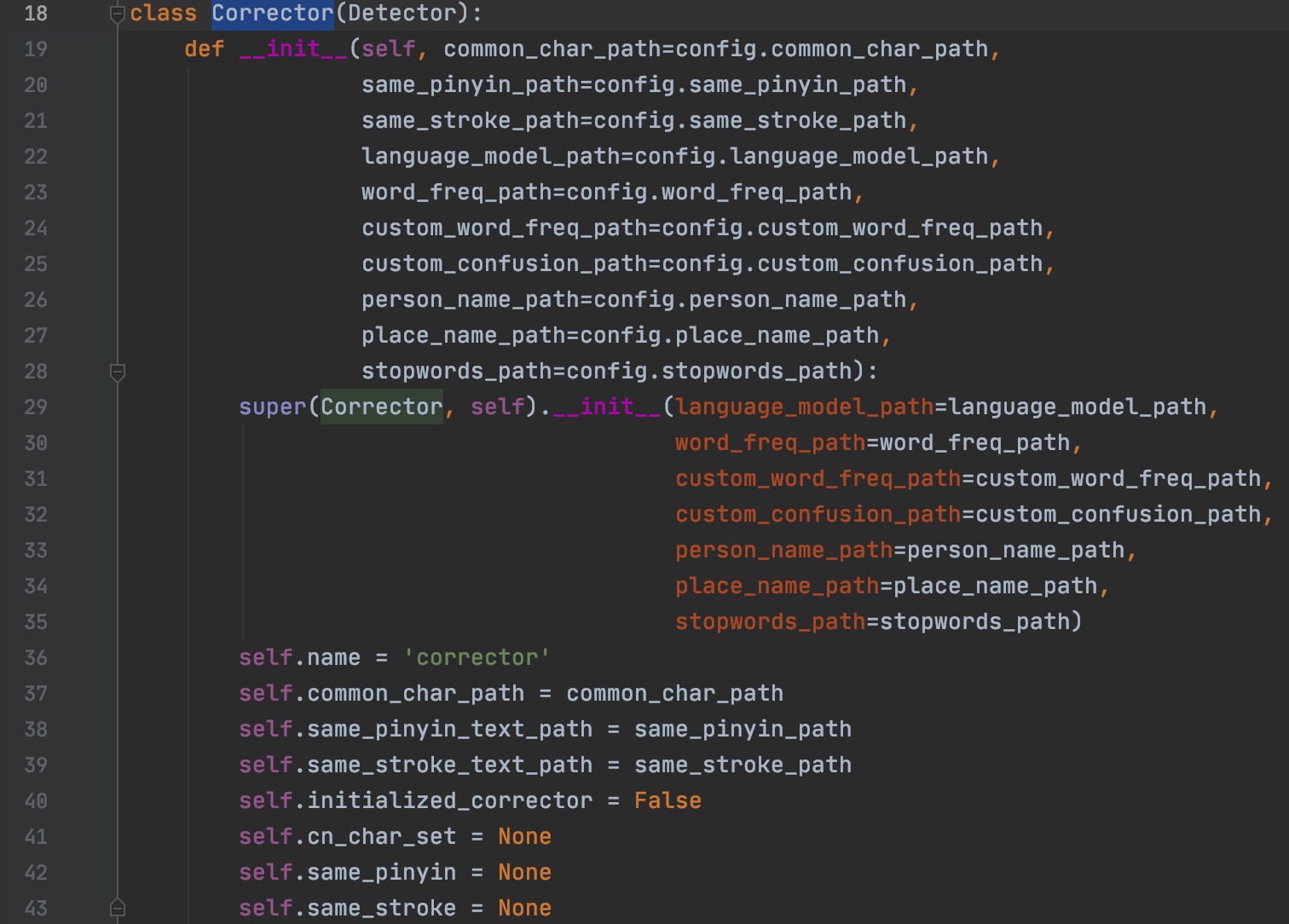
4.1.2 拼写和笔画纠正(Corrector)
源码中通过corrector.py中定义的Corrector类来完成拼写纠错,通过初始化这个类,来获得实例,进行纠正。如图所示,初始化的时候,我们可以设置很多配置文件的路径,比如停用词文件(stopwords_path)和自定义词频文件(custom_word_freq_path)等。
类初始化
同样,
Corrector类实例化的时候,也可以自定义词频文件,停用词等基本信息,通过修改这些配置文件,来适应自己的业务场景。
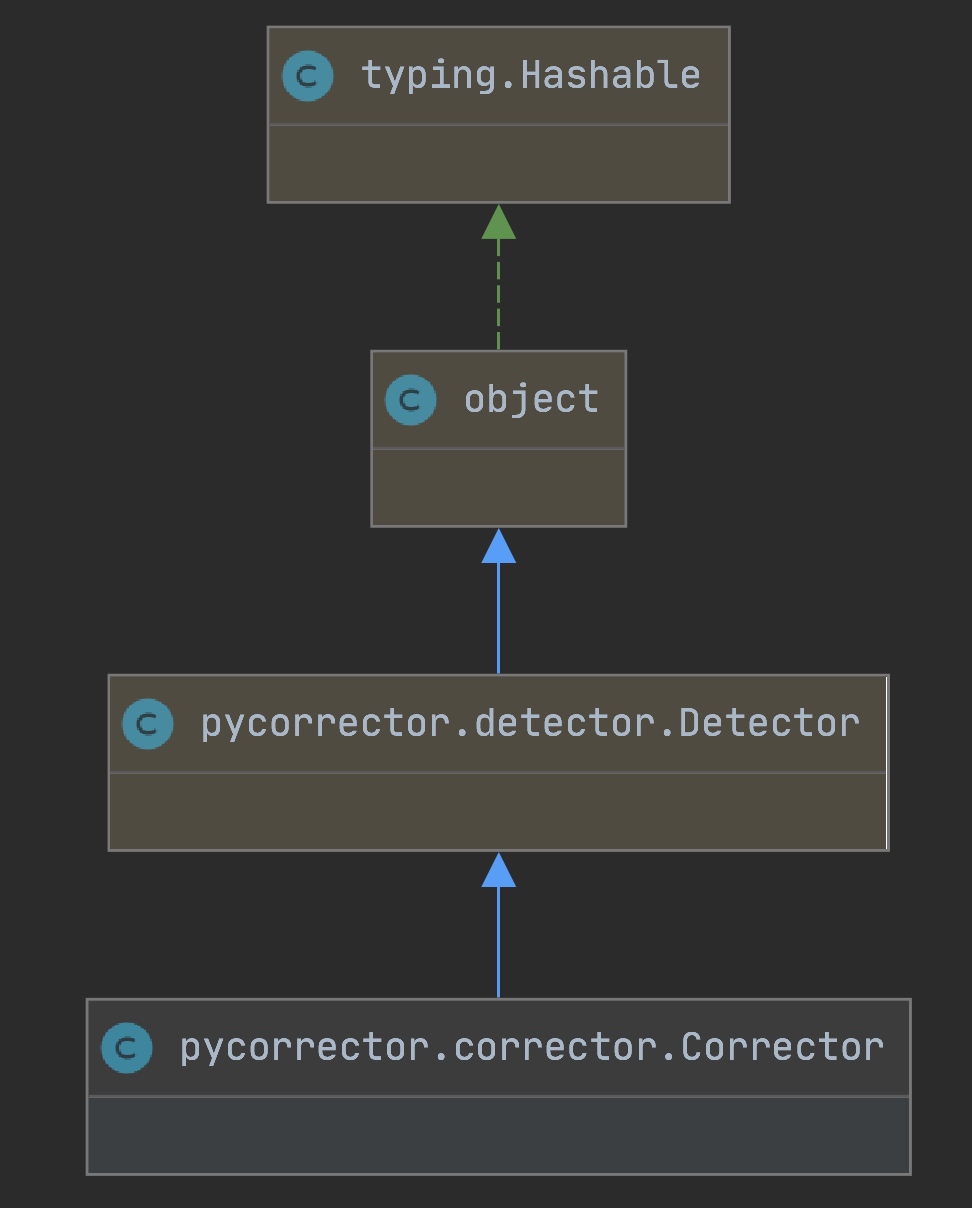
继承关系
Corrector的集成关系如下图,Corrector继承了上文中介绍的Detector类,能够完成一些基本的长句切分,错词检测功能。
示例代码
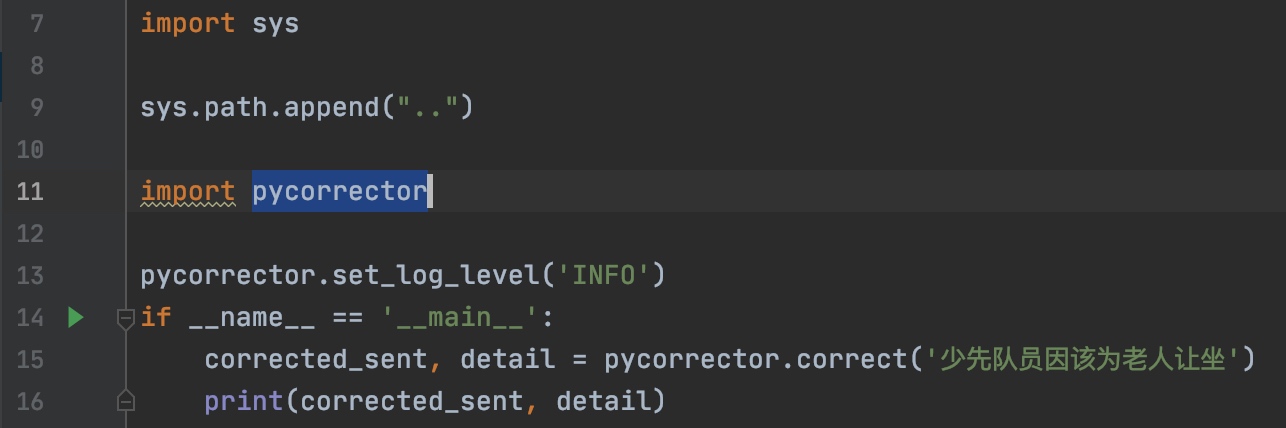
通过源码中给到的
Demo,我们来了解下该功能的调用。通过获取到Corrector示例,调用correct方法进行检测:
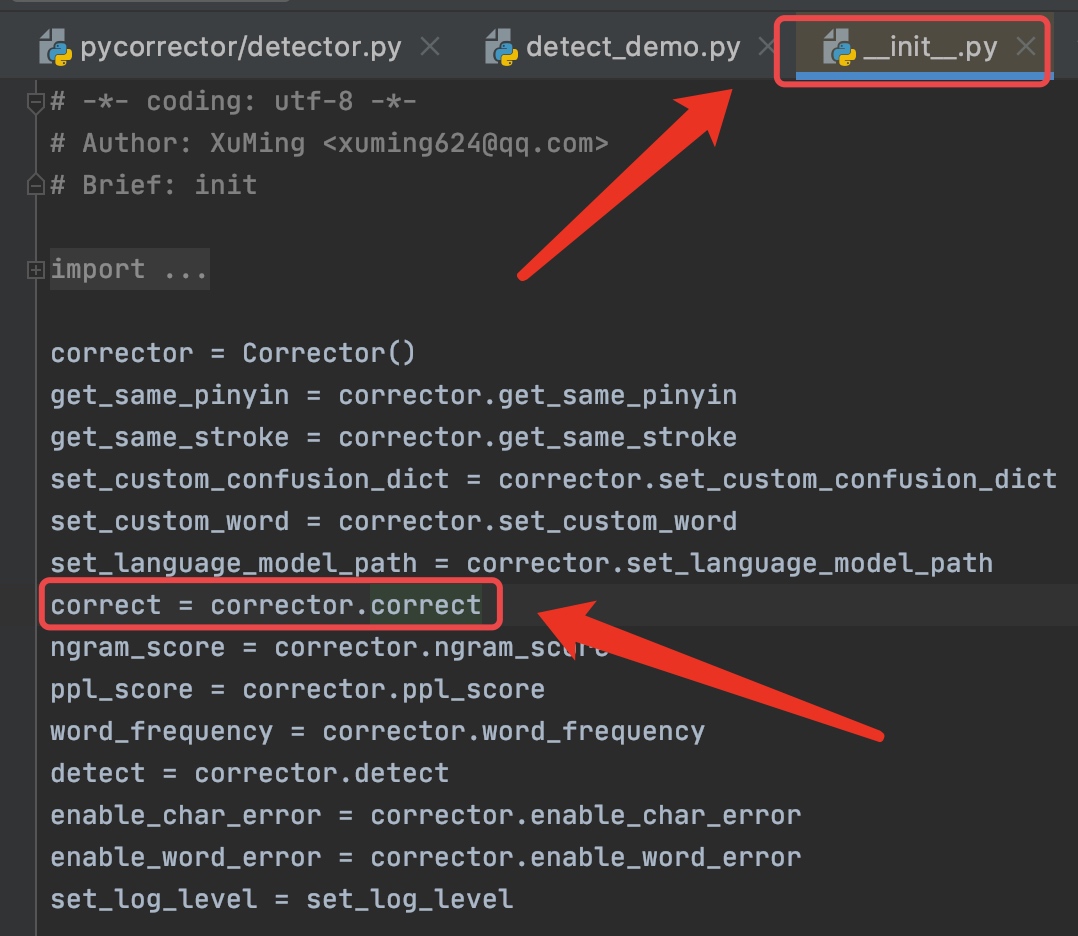
首先
import的时候会首先调用__ini__.py,在这个文件中会对必要的工具类进行初始化
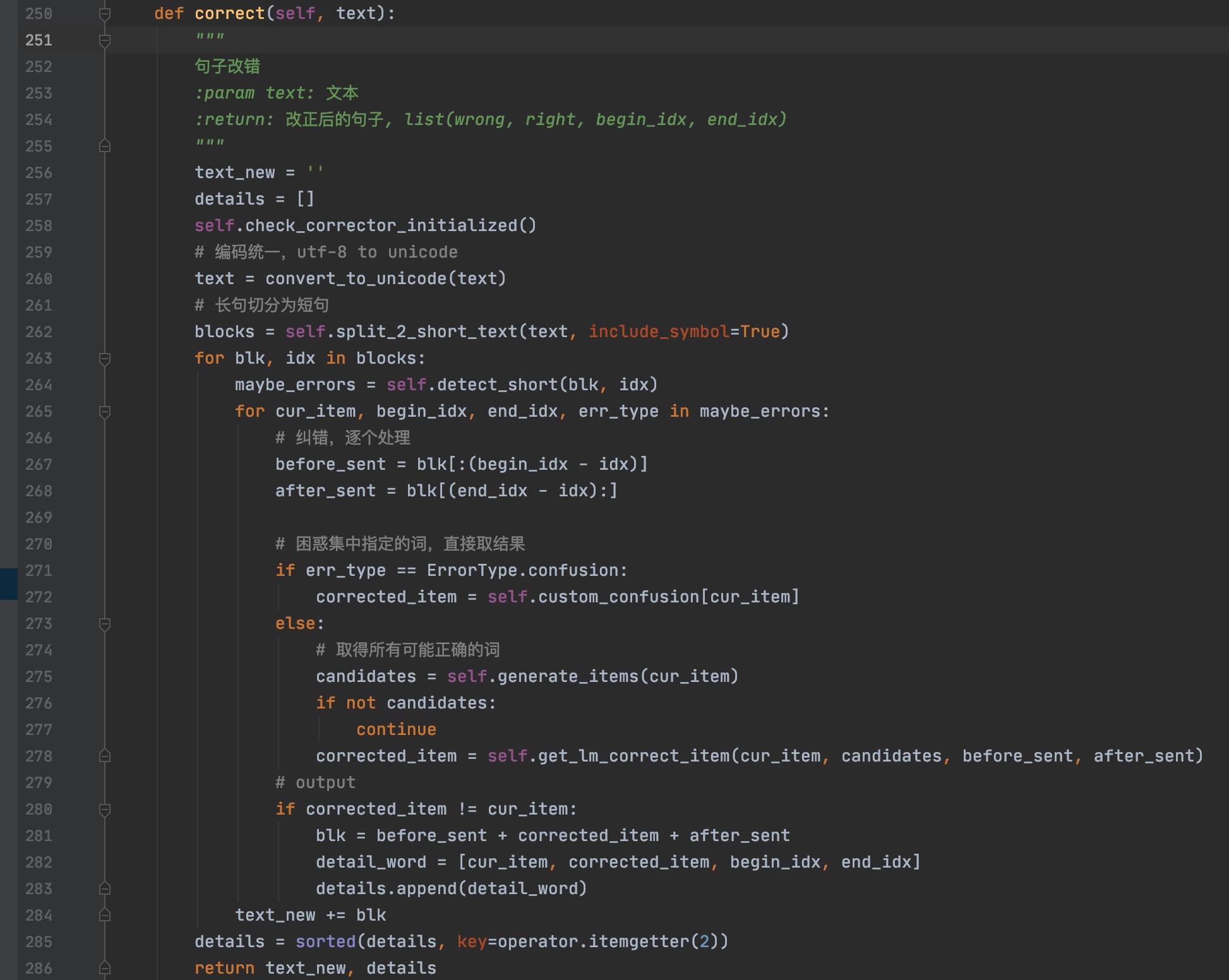
然后将调用
correct方法进行句子改错
4.1.3 英文检测
英文拼写纠错被作者发在了另外一个类中
EnSpell,通过加载一个很大的英文语料来进行英文纠错,具体细节将在下文阐述。
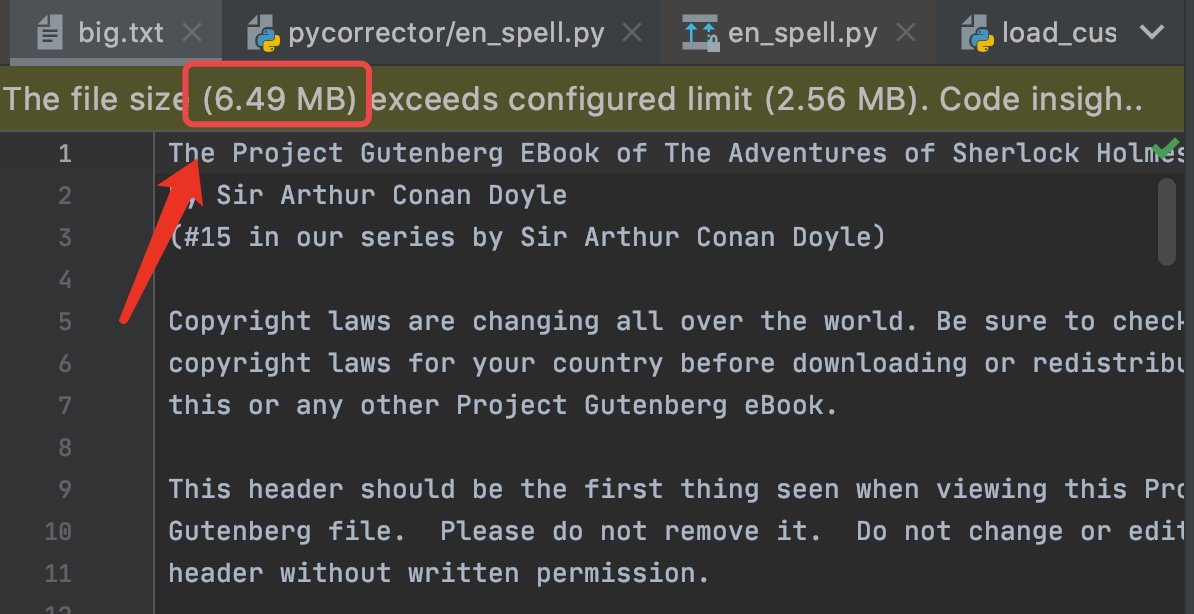
源码示例
首先,我们通过源码的例子来了解如何使用,如图所示,当我们实例化
EnSpell之后,直接调用en_correct方法即可对传入的单词进行纠错。
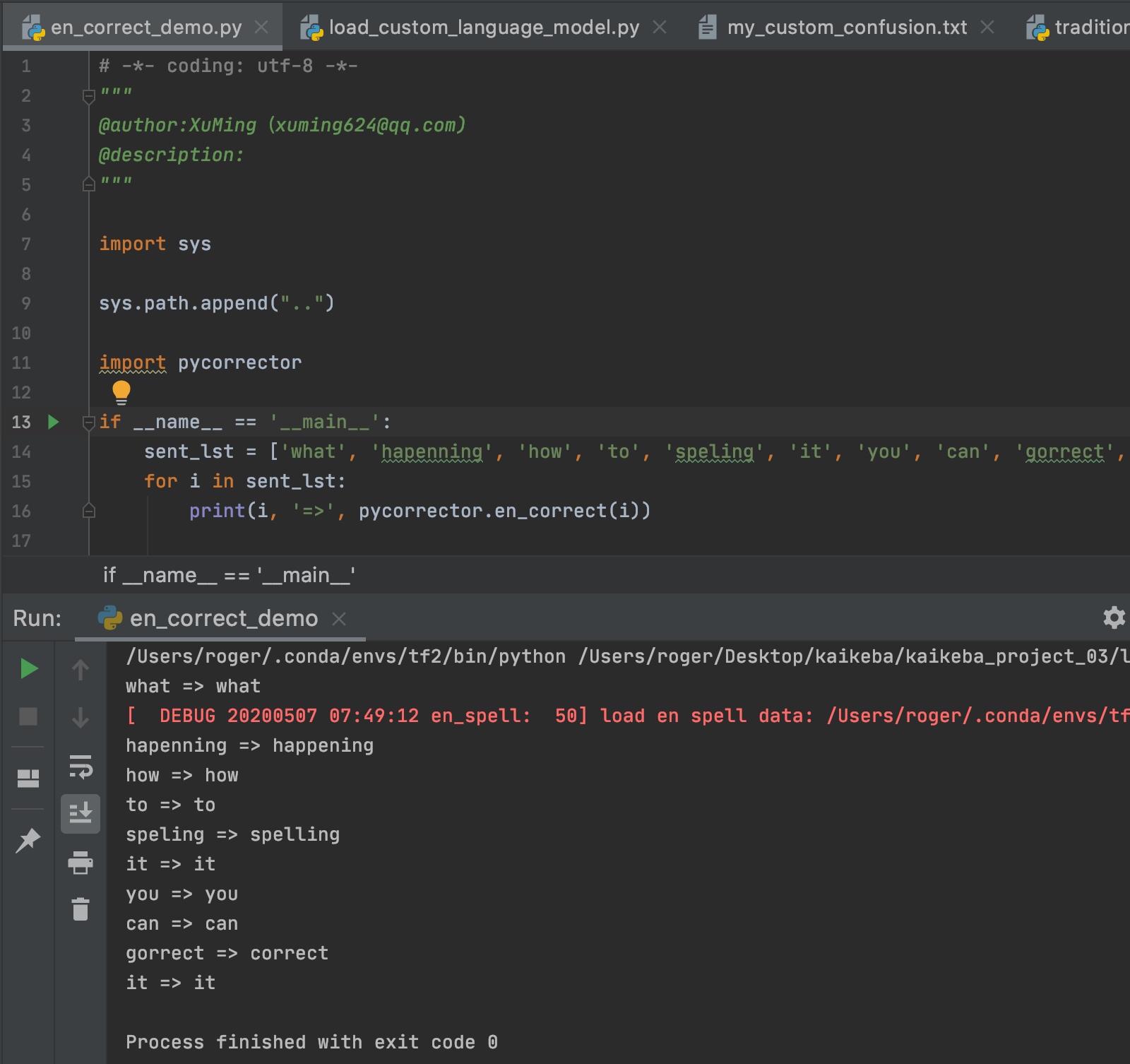
继承关系
从继承关系可以了解到,EnSpell并未和上文讲到的两个模块有任何关系,是一个独立的模块。
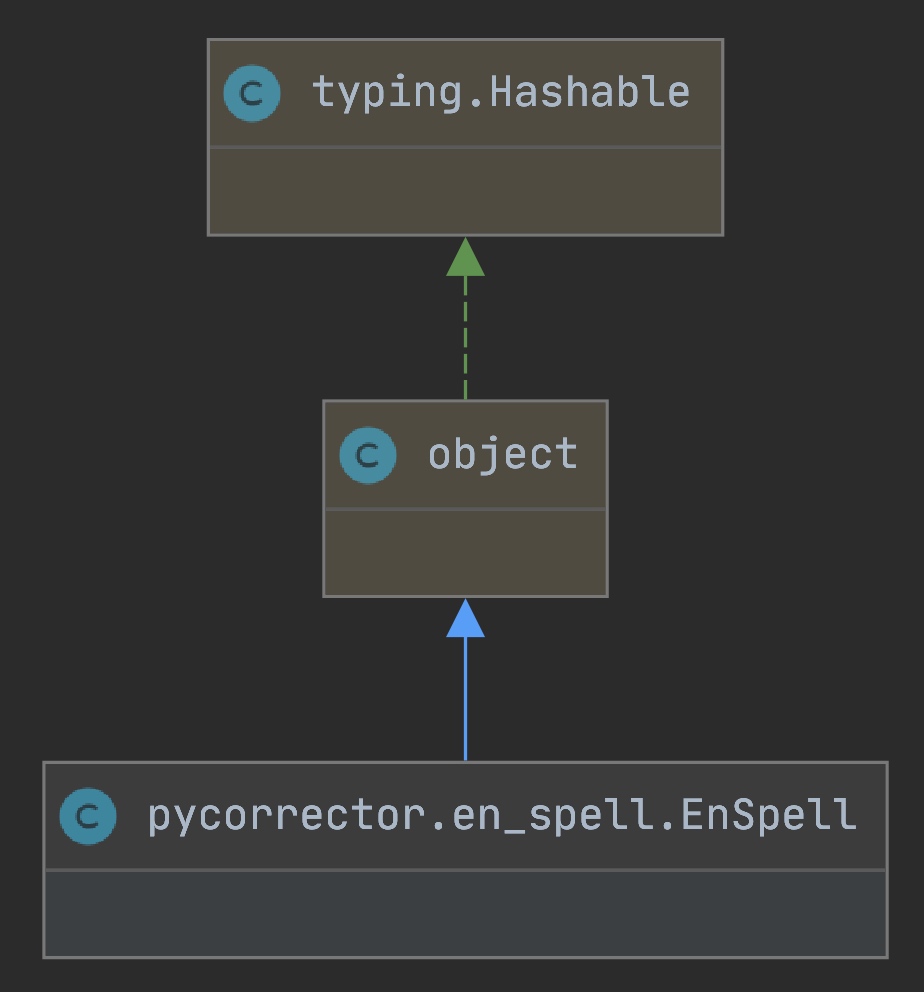
代码详解
纠错主入口是
correct方法,返回最大概率的候选.
问题来了:
- 候选值怎么确定?
- 概率怎么确定?
候选值生成
首先,通过candidates方法获得可能的正确地拼写词,获取编辑距离1,2内的候选值以及当前值和子集。
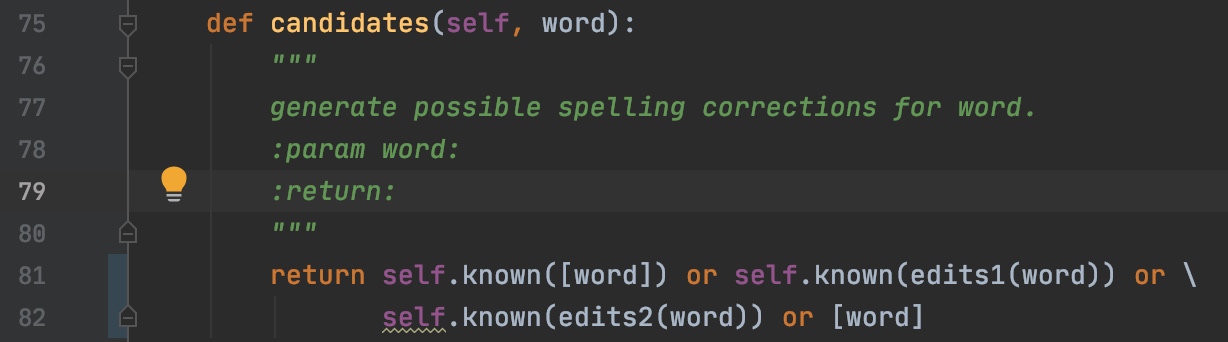
编辑距离词的构建方法以及词的过滤,可以参考作者的源码实现,这里将不再赘述。
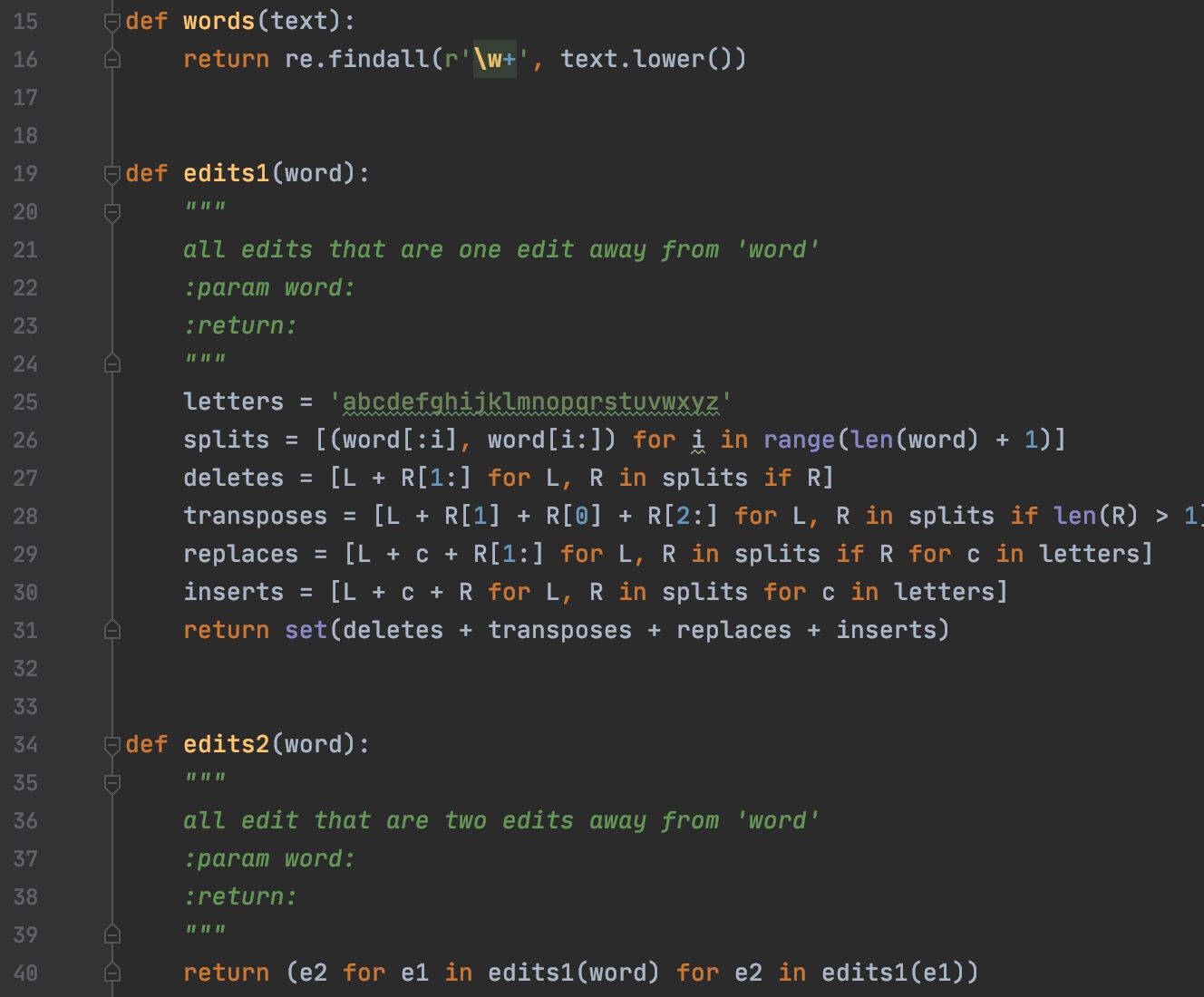
然后依次遍历单词中的每个字母,筛选出存在于WORDS字典中的词。
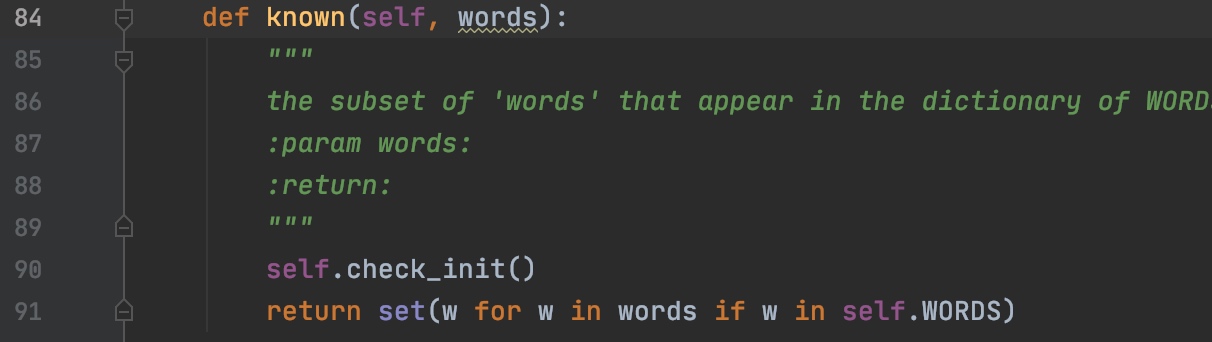
WORDS是我们开头讲到的那个超大英文语料的词频字典。

概率计算
概率计算通过调用probability方法进行计算,

计算方法是使用当前词的频率/总得词频数量,十分简单粗暴。
4.2 深度学习模型
4.2.1 Seq2Seq Attention模型
Seq2Seq基本结构
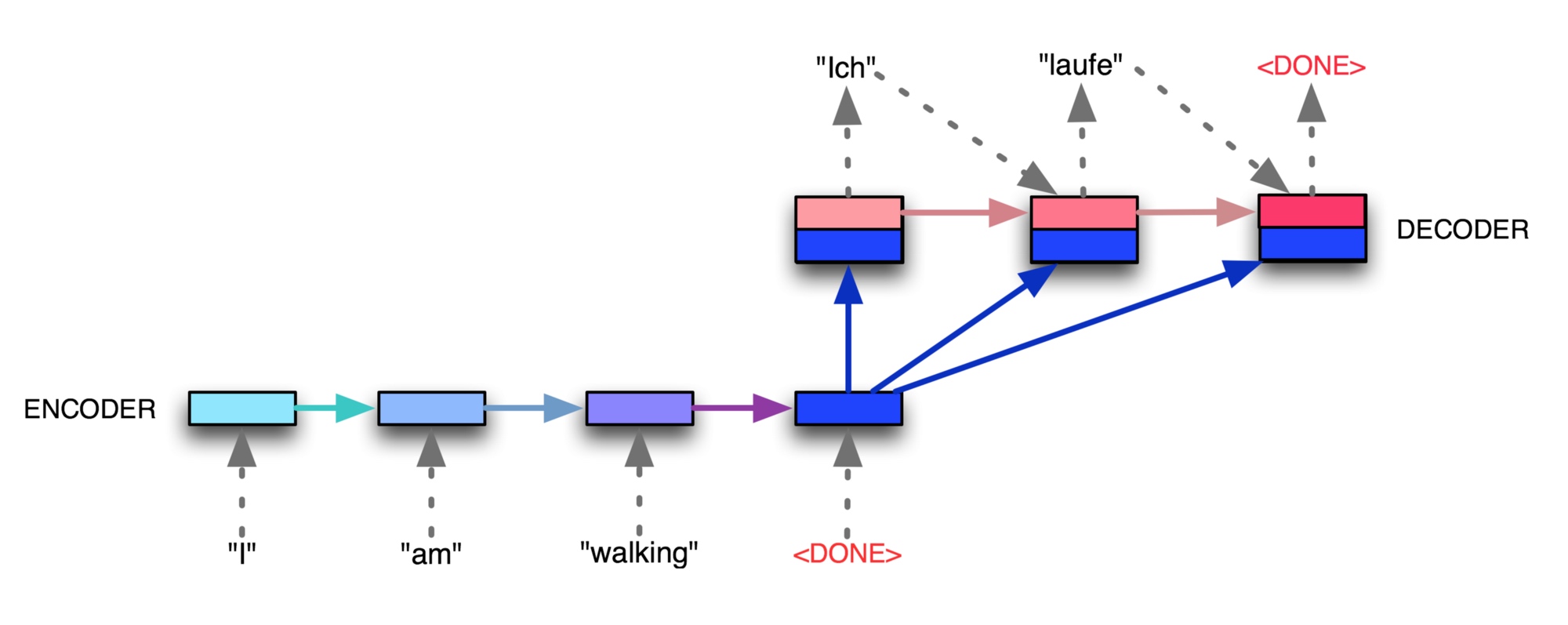
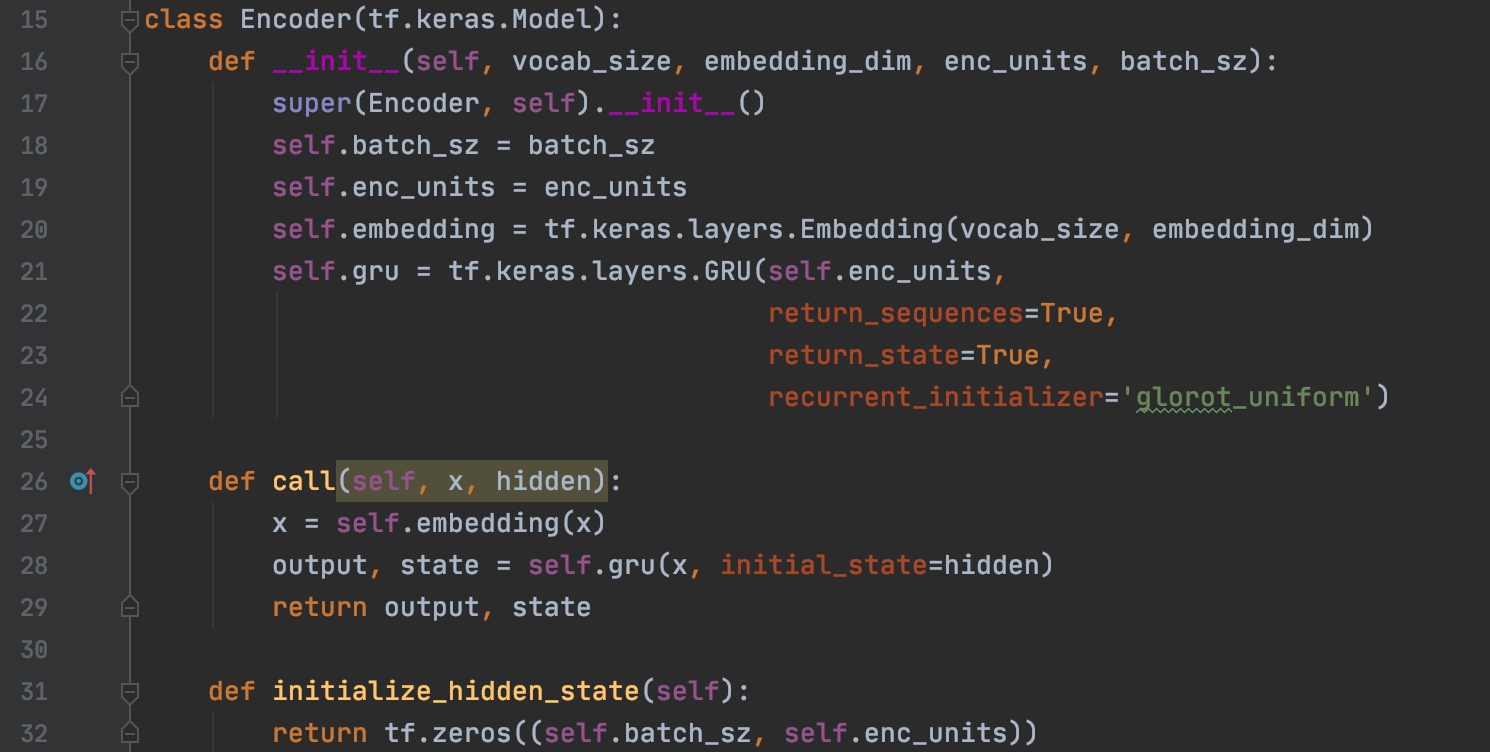
Encoder代码实现
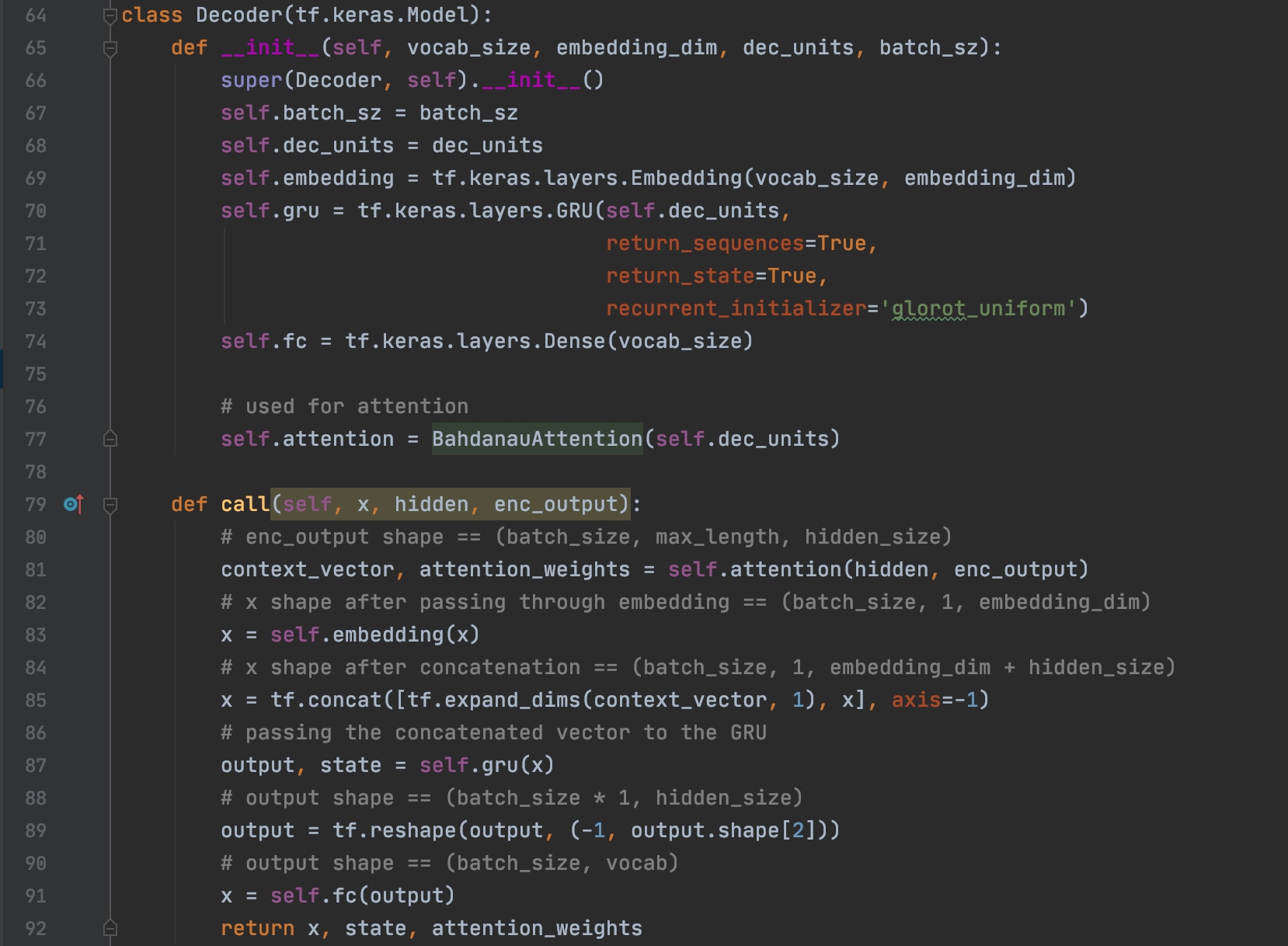
Decoder代码实现
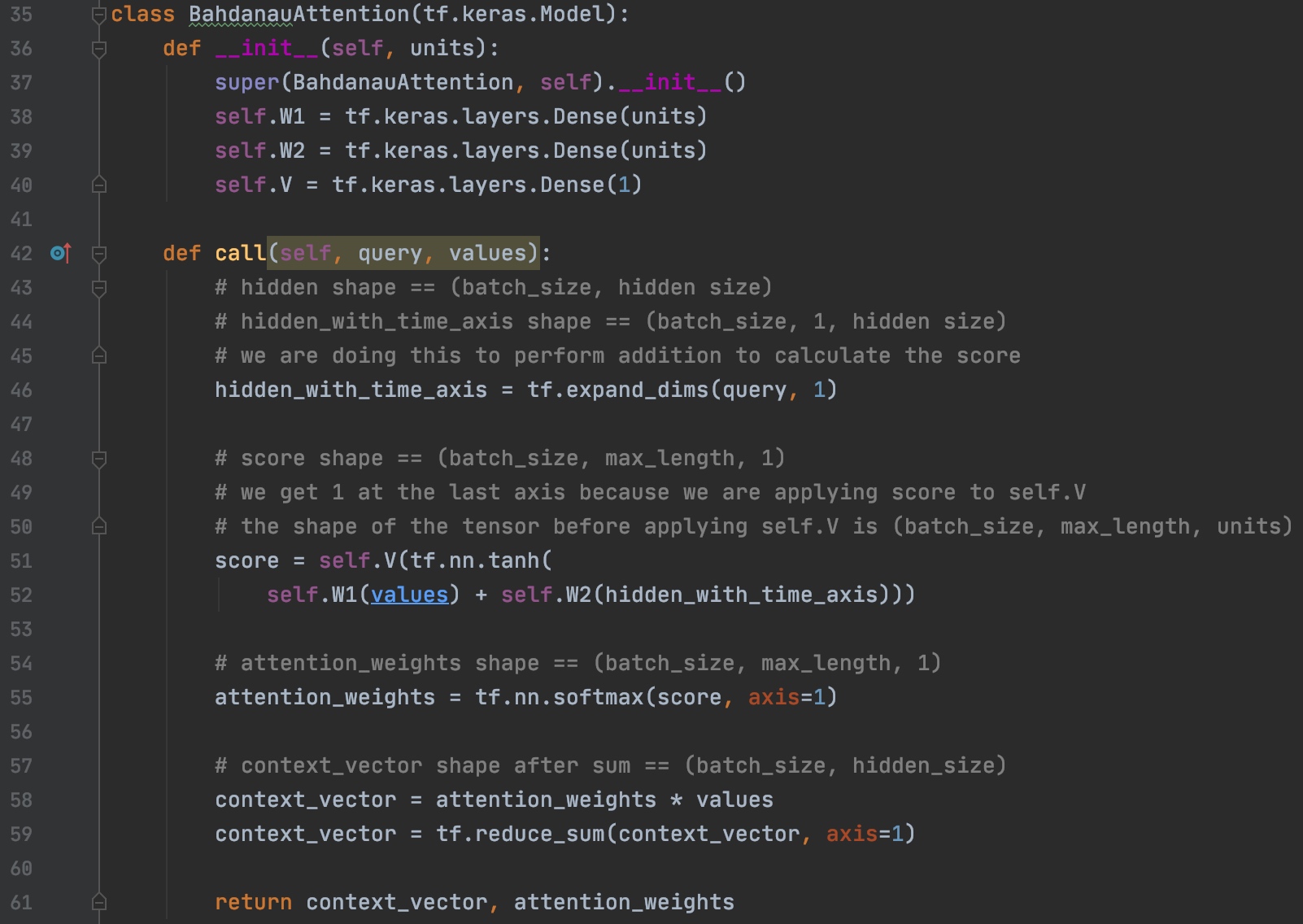
使用BahdanauAttention
下图是不同Attention的区别,还有很多种类的Attention,本文不再赘述

代码实现
Seq2Seq Attention训练
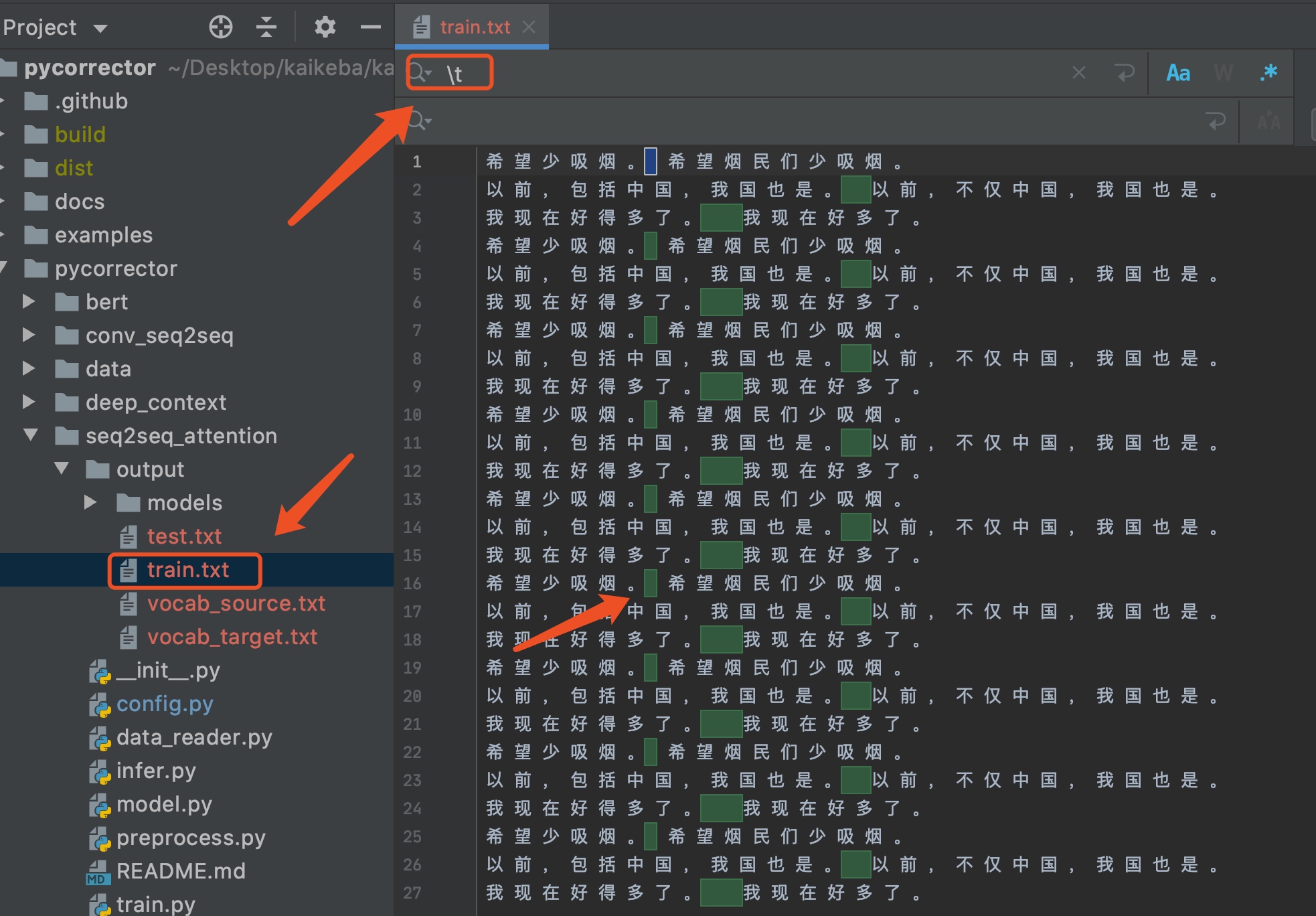
训练很简单,代码作者都已经写好,只需要按上面步骤安装好必要的环境,然后再seq2seq_attention路径下,创建output文件夹,然后将训练集命名为train.txt 、测试命名为test.txt。
数据集路径
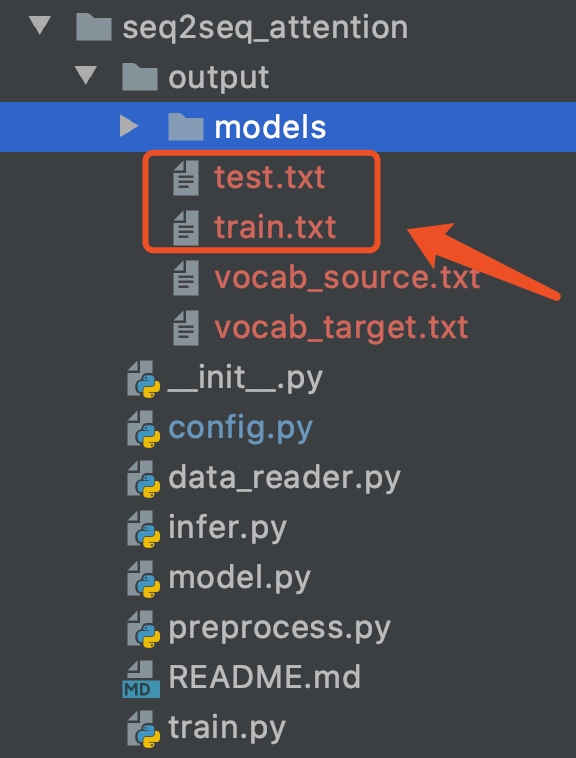
数据集结构
每一行包括一个样本信息,包括两部分信息,输入数据
X和标签Y,使用\t进行分割,X和Y均为切词后的句子,词之间用空格分隔。
训练
数据整理好后,之间运行
train.py即可进行训练
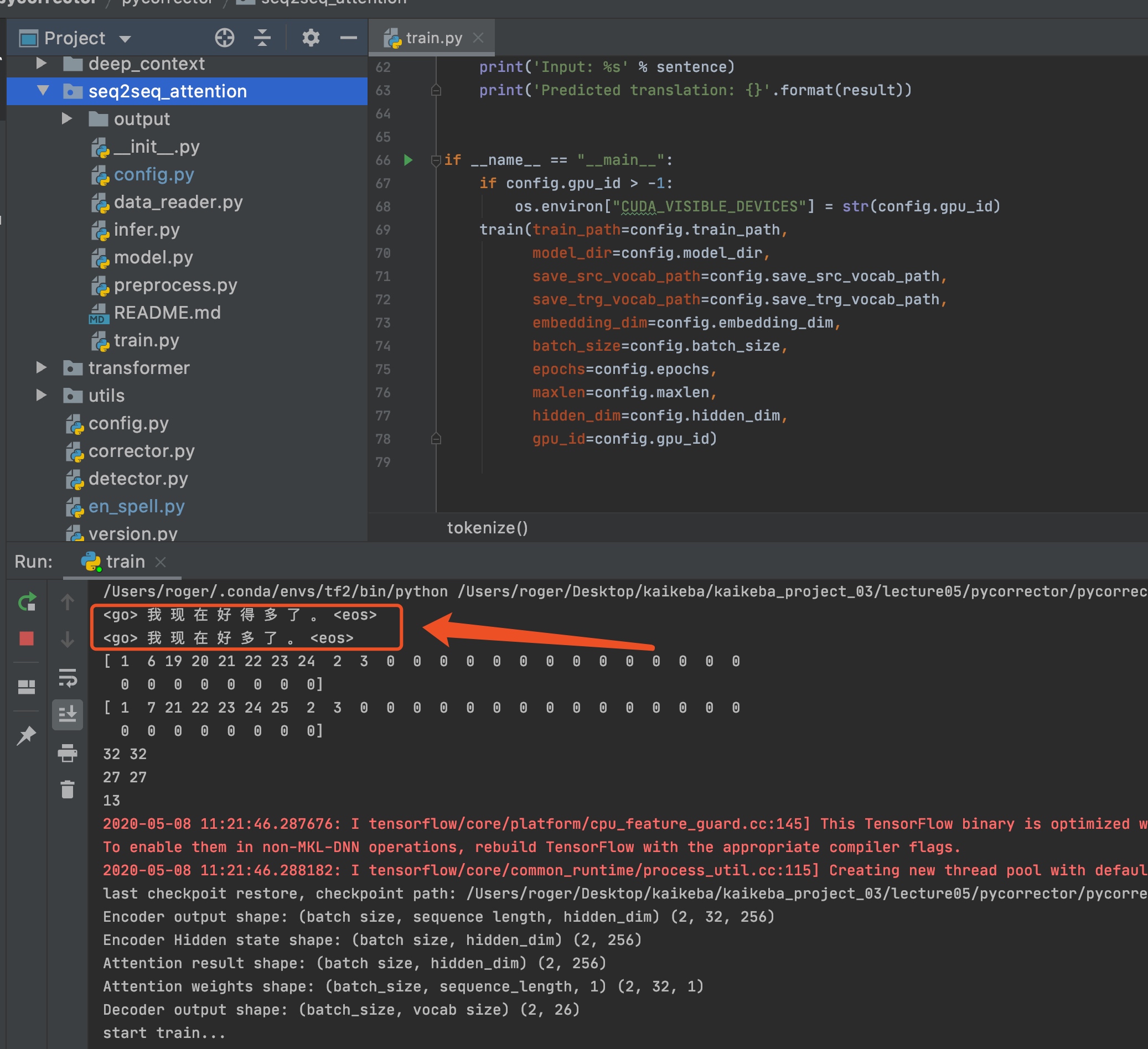
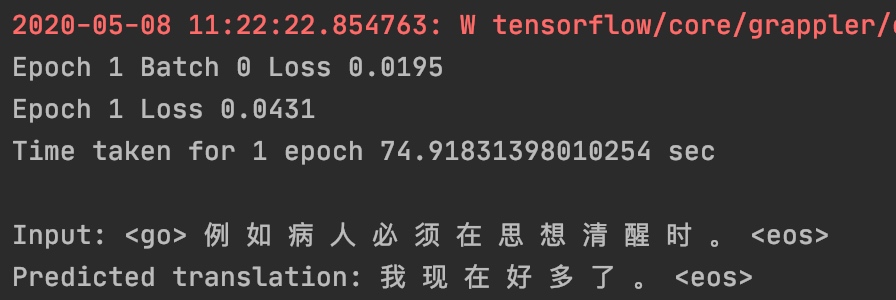
当模型训练完之后,会保存模型,并且进行预测。到这里,模型的训练就跑通了,若要使用该模型,只需要将测试数据处理成train.txt 和test.txt相同的格式,然后训练多轮,即可得到较好的结果。
4.2.2 transformer模型

同样,
transformer模型的使用也和上文Seq2Seq Attention类似。只是数据格式稍有变化。transformer本文将不再赘述,可以参考文后留下的参考资料。
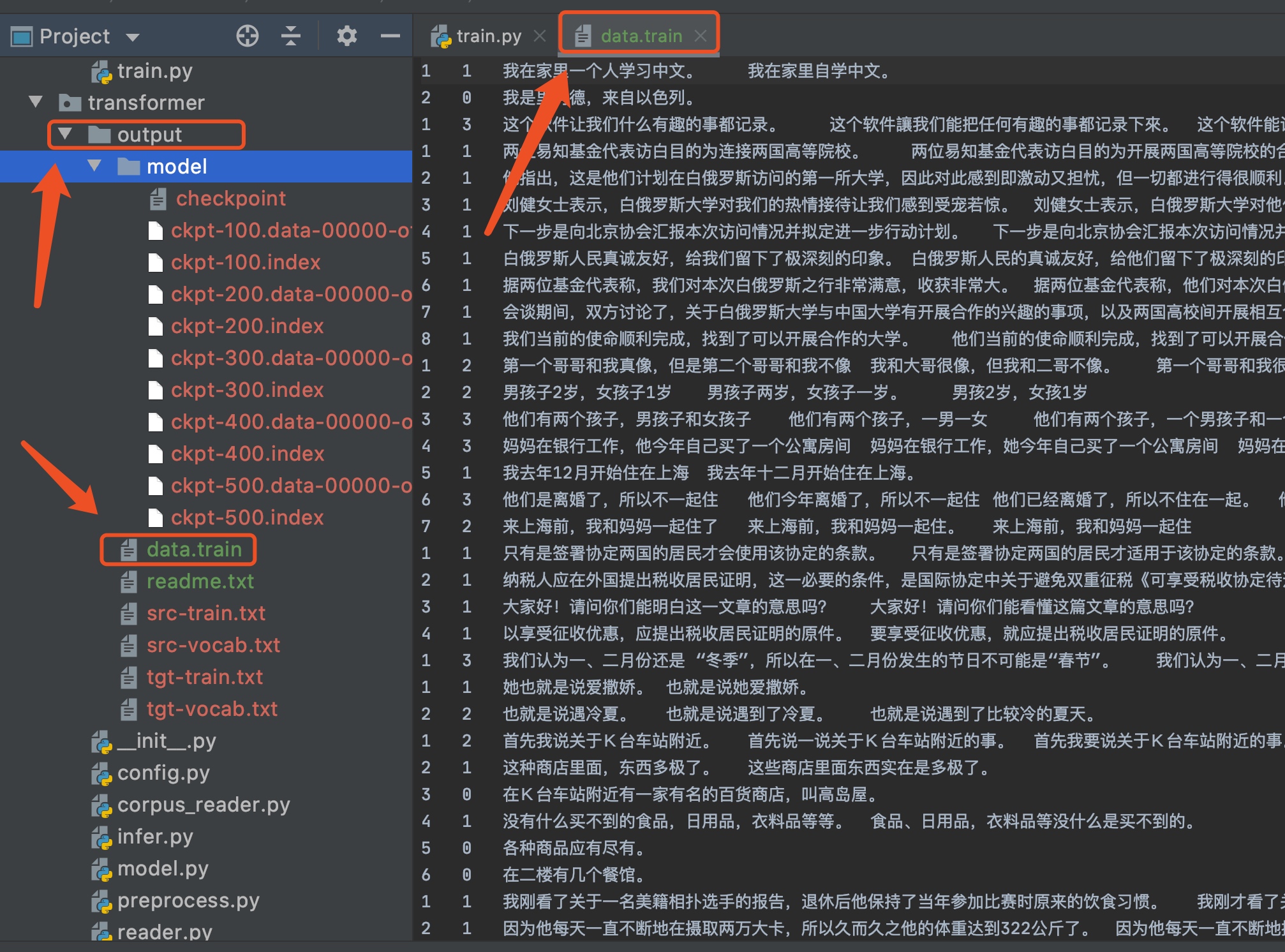
数据集结构
使用NLPCC2018比赛数据集进行训练,该数据格式是原始文本,未做切词处理。同样在路径下创建
output文件夹,命名为data.train,在运行train.py的时候,会自动去切分输入数据和标签数据,并且构建输入输出的vocab。
训练transformer
直接运行
train方法即可进行训练,训练过程较长。
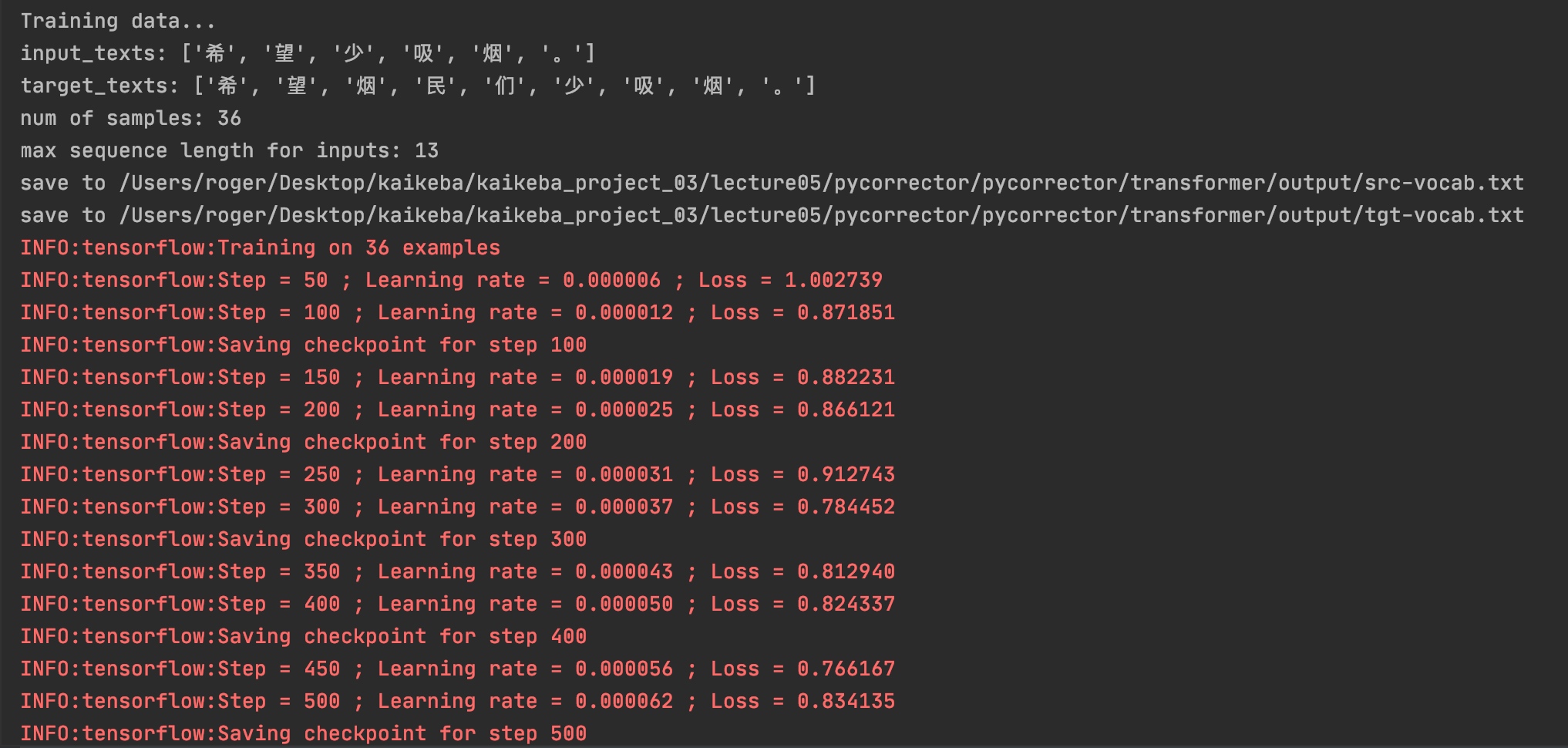
训练过程中,会打印
loss和学习率的变化,学习率会先增加,后减小,是由于transformer使用了变化的学习率,具体可以参考官网的示例。
作者还提供几个其他模型,使用方法类似,本文就不再赘述了。