文章目录
1 什么是hash
1.1 问题产生
问题产生:学习Redis,redis中value的数据类型中有个hash类型,那么什么是hash?
1.2 问题分析
按照本人好久之前数据结构课程记忆:hash是一个相当于key—value形式,这样的一个数据结构。
1.3 问题解决
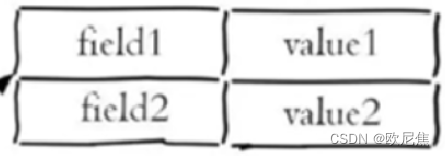
1.3.1 关键码(key)值(value)
哈希表
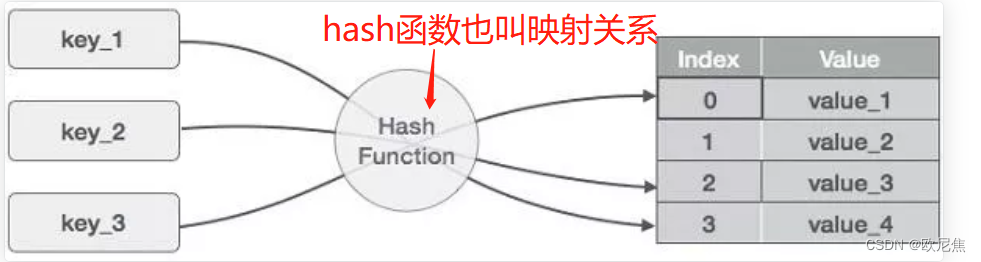
- 哈希表(Hash table,也叫散列表),是根据
关键码值(Key value)直接进行访问的数据结构。- 通过把
关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
1.3.2 底层数组实现
- Hash表的底层通过数组实现的。
- 数组有个特点就是:必须在初始化时候指定长度。
所以当Hash表中的数据填满之后想继续向里面放数据的话就必须再创建一个容量更大的数组,然后将之前数组中的数数据copy到新数组中。这个过程耗费性能,因此在使用Hash表之前要估算下数据容量,尽量避免扩容操作。
1.3.3 hash表中的问题:hash冲突即解决
由于通过关键码(key)值(value)映射表中一个位置来访问数据,这个映射关系(hash函数)可能会得出相同结果,这时候就发生hash冲突问题,这种冲突是不可以避免的。
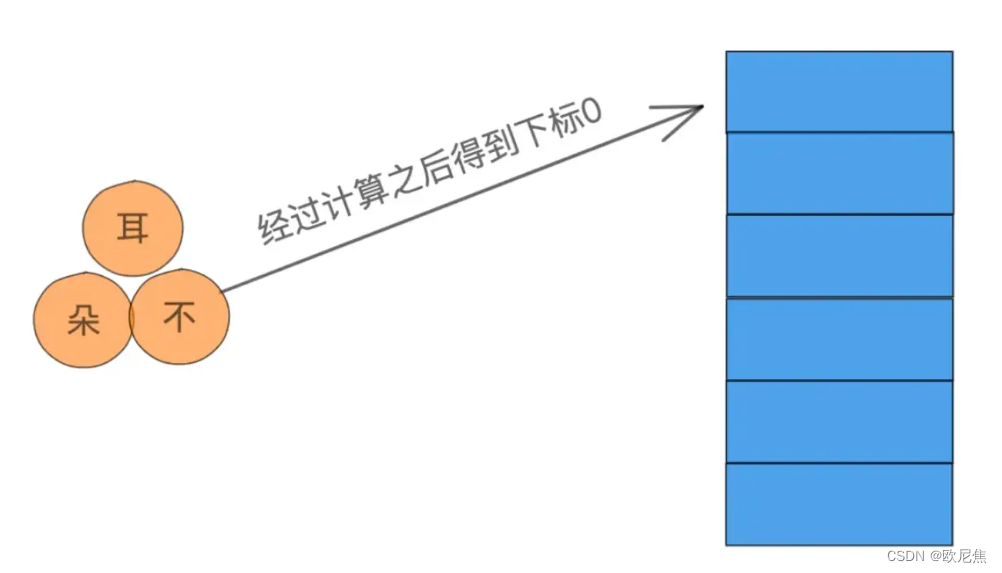
hash冲突的解决方法:开放地址法和拉链法。
1.3.3.1 冲突解决 — 拉链法
核心思想是:当hash表中某个位置发生了hash冲突(也就是说将要插入的元素放到数组中某个位置时,这个位置已有元素),那么将这些元素以链表的形式存放。
那么这会带来一个问题:如果hash表中某个位置发生的hash冲突过多,那么就会形成一个很长的链表,最终会影响查询性能。
JDK8中针对上述问题又做了优化,也就是红黑树 ,即:当链表长度达到8时,自动将链表转换成红黑树,查询效率较高(红黑树是一种自平衡的二叉查找树)。
1.3.3.2 冲突解决 — 开放地址法
核心思想:当方式hash冲突是需要寻找其他位置来存放。
开放地址法中三种方式寻找其他的位置:线性探测、二次探测、再哈希法。
线性探测法:首先对要进行映射的位置进行判断,如果此位置无元素,就映射到此位置上,如果有元素,就添加到此位置的下一位置,如果还有继续下一个位置,直至映射成功。
1.4 参考资料
2 为什么不建议用Object接收 redis中返回值
2.1 问题引入
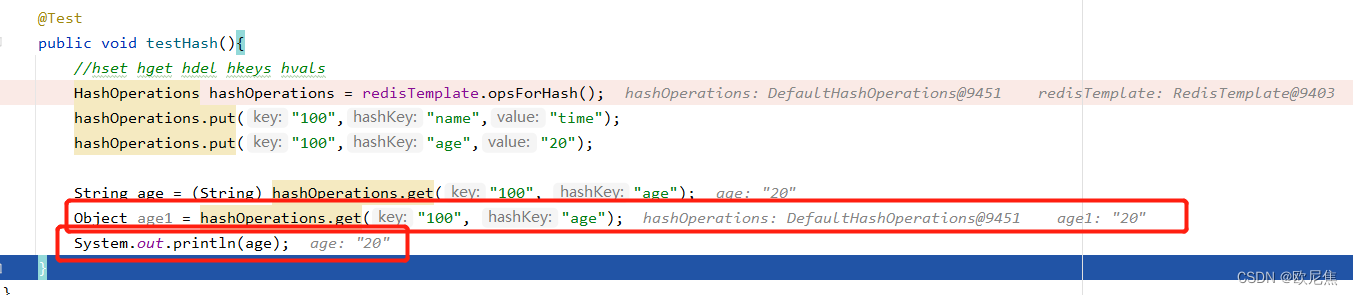
练习使用Java代码对Redis进行添加数据、读写操作;读写过程中,想到都是默认用
String类型接收返回的value值,这是因为在Redis中数据都是以字符串(string)类型存储的,那Object作为基本数据类型的父类,按道理说也能用,实测了下,推论无误。
2.2 问题分析
既然可以用Object类型接收Redis中的value。为什么还要强转,并用String类型接收返回值呢?(
Redis中数据都是以字符串(string)类型存储?),Object类型是所有基本类型的父类,当然他占用的内存也大,而Redis读取快的一个原因就是:其每种数据结构都是经过专门设计的,并都有一种或多种数据结构来支持
2.3 问题解决
redis的性能高的原因之一:
它每种数据结构都是经过专门设计,并都有一种或多种数据结构来支持,以此提升读取、写入的性能。
如果使用Object类型接收
- 会影响Redis的读取性能,甚至在系统运行后期,把服务器内存占满,因为一直在使用一个大的数据类型接收小的数据类型,总之使用小的合理,总没错。
- 还有一点,用object接收返回值,这样的话就无法使用string像相关方法。
| 类型 | 占用字节 |
|---|---|
| Object | 16或24 |
| string | 8或16 |
2.4 参考资料
redis学习技巧之Object详解
为什么不建议使用自定义Object作为HashMap的key?
面试官被欺负:new Object()到底占用几个字节?